AI トレーニングでは、大量のデータを繰り返し読み取る必要があることが多く、これによりネットワークに大きなオーバーヘッドが発生し、トレーニング効率に影響を及ぼします。PAI では、Lingjun AI Computing Service 向けにローカルキャッシュ高速化機能を提供しています。この機能は、計算ノードのローカルにデータをキャッシュすることでネットワークオーバーヘッドを削減し、トレーニングスループットを向上させ、データ読み取り性能を改善します。これにより、AI トレーニングタスクが高速化されます。
技術的メリット
高速キャッシュ:計算ノードのメモリおよびローカルディスクを活用して、シングルノードおよび分散型読み取りキャッシュを構築します。これにより、データセットやチェックポイントへのアクセスが高速化され、データアクセスレイテンシが大幅に低減されます。
水平スケーリング:キャッシュスループットは計算ノード数に比例して線形にスケールします。数百ノードから数千ノード規模まで対応可能です。
P2P モデルディストリビューション:ピアツーピア (P2P) 技術により、大規模モデルの高同時実行数でのロードおよびディストリビューションをサポートします。GPU ノード間の高速ネットワークを活用して、ホットスポットデータの並列読み取りを高速化します。
サーバーレスで使いやすい:ワンクリックで有効化または無効化できます。コードの変更は不要です。この機能はご利用のプログラムに対して非侵入型であり、運用・メンテナンス (O&M) も不要です。
制限事項と注意事項
ストレージのサポート:OSS および Lingjun CPFS をサポートしています。
適用可能なリソース:現時点では Lingjun リソースのみをサポートしています。この機能を有効にすると、計算ノードの CPU およびメモリなどのリソースを一部消費することにご注意ください。
容量とポリシー:最大キャッシュ容量は Lingjun リソースの仕様によって異なります。立ち退きポリシーは Least Recently Used (LRU) です。
高速化対象:主な目的はデータ読み取り性能の向上です。書き込み操作はサポートされていません。
データの高可用性:高可用性は保証されません。ローカルキャッシュ内のデータは失われる可能性があります。重要なトレーニングデータは速やかにバックアップしてください。
仕組み:複数エポックのトレーニングにおいて、最初のエポックでは OSS や Lingjun CPFS などのストレージインスタンスからデータを読み取ります。この際のパフォーマンスは、ストレージインスタンスから直接読み取る場合と同等です。2 回目以降のエポックでは、ローカルキャッシュからデータを読み取ることで読み取り速度が向上します。
使用方法
リソースクォータに対してローカルキャッシュを有効にします。左側のナビゲーションウィンドウで、Resource Quota > Intelligent Computing LINGJUN Resources をクリックします。対象のリソースクォータを見つけ、その名前をクリックして管理ページを開きます。Enable Local Cache スイッチをオンにし、キャッシュするストレージパスを指定します。
ネストされたリソースクォータを使用している場合は、最上位レベルのリソースクォータでローカルキャッシュが有効になっていることを確認してください。
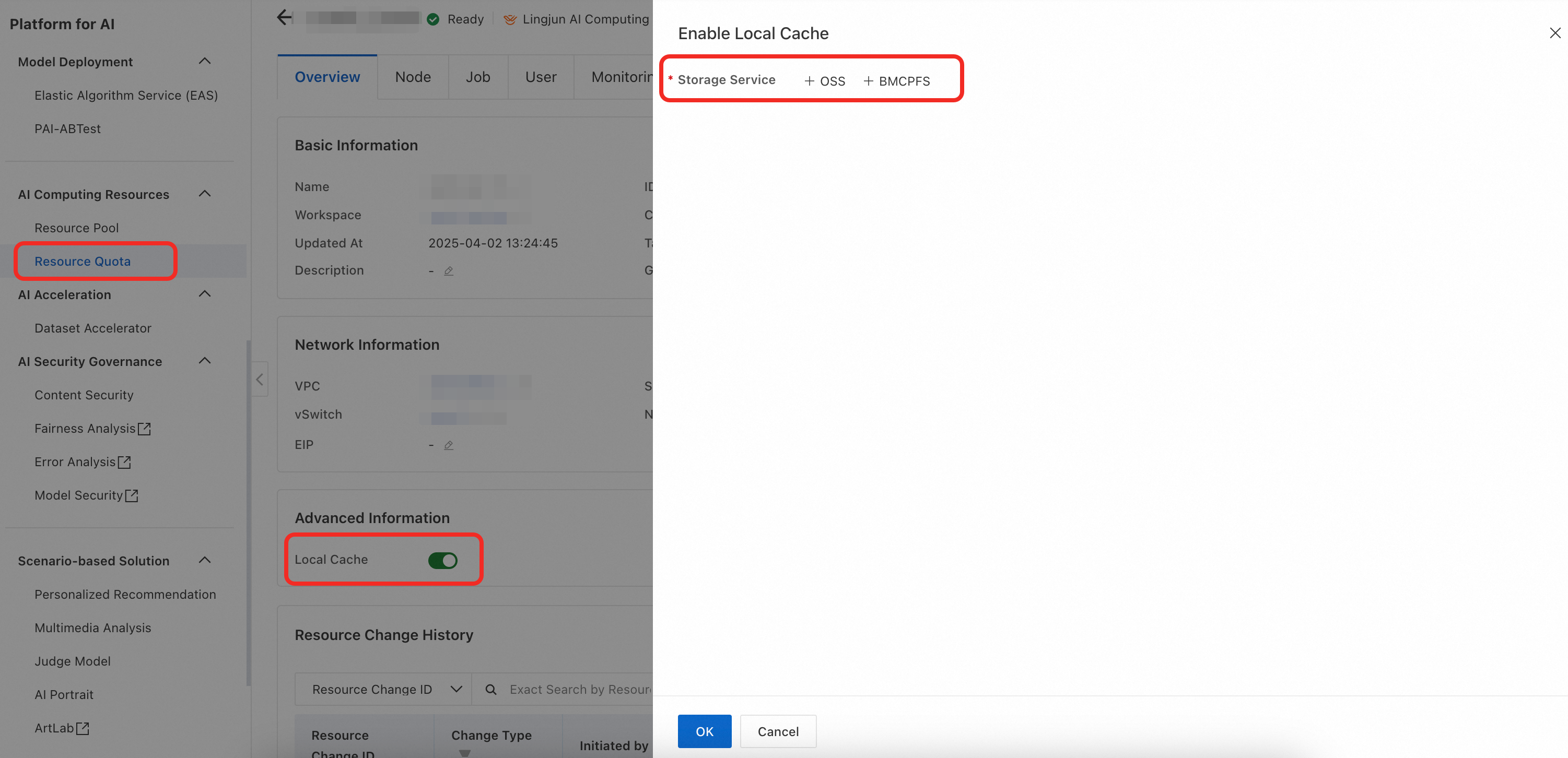
対象のリソースクォータに関連付けられた Lingjun AI Computing Service リソースを使用して DLC ジョブを作成します。ジョブ構成で、Use Cache を有効にします。マウントされたストレージパスが手順 1 で指定したキャッシュパスと一致する場合、データアクセスは自動的に高速化されます。ジョブ単位でこの機能を無効にすることも可能です。
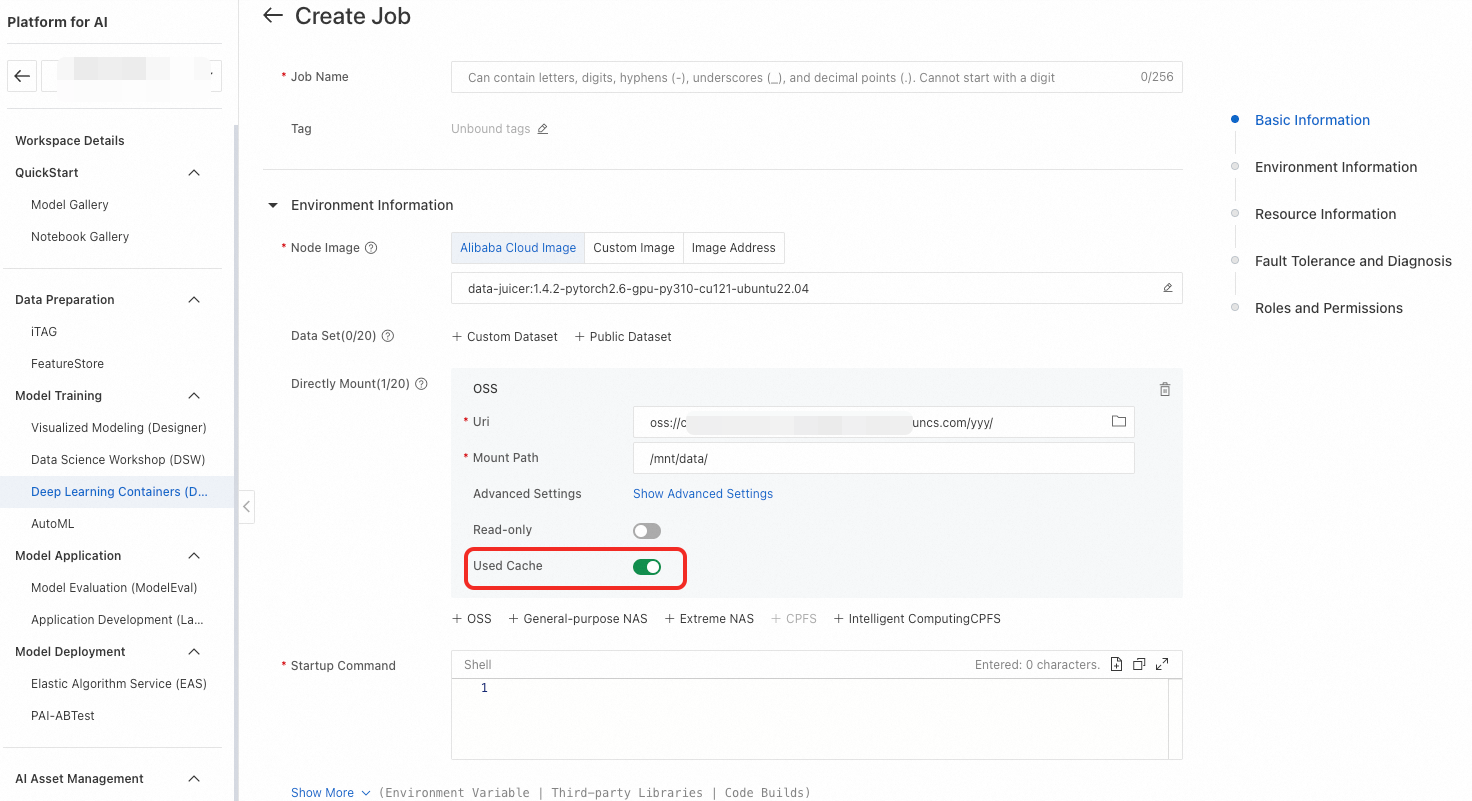
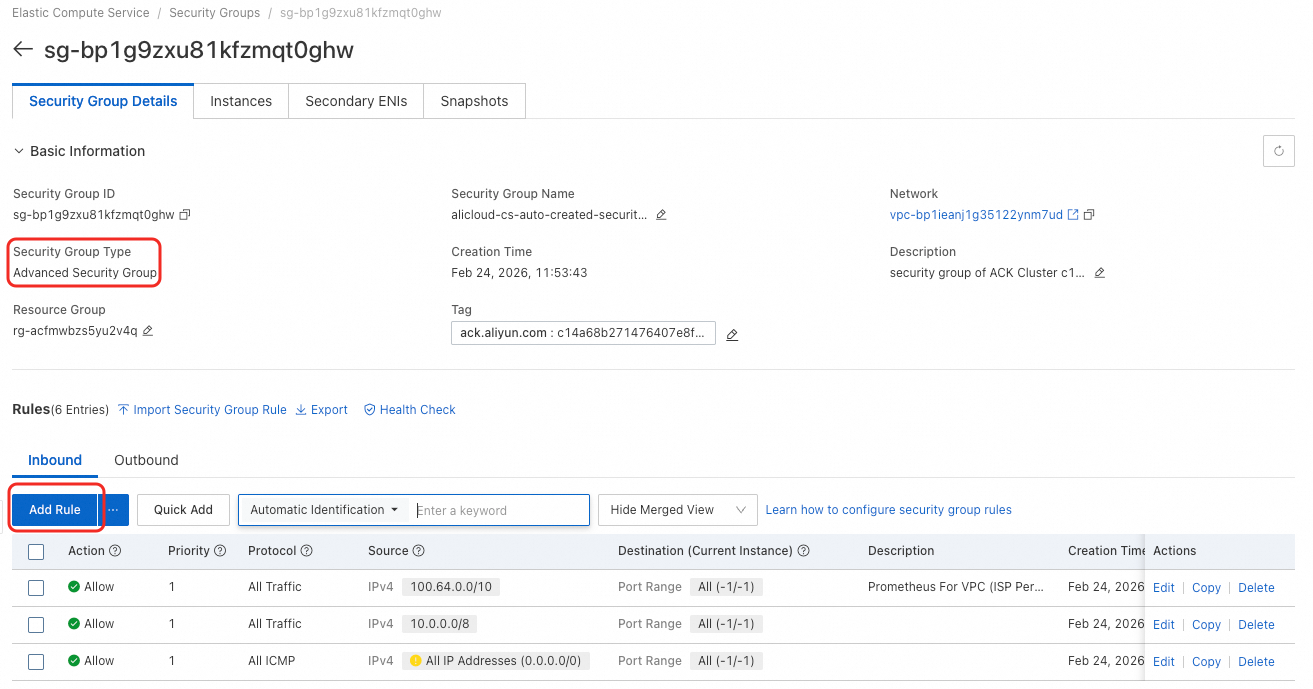
セキュリティグループのインバウンドルール
エンタープライズセキュリティグループを使用している場合は、Virtual Private Cloud (VPC) からのトラフィックを許可するための追加のインバウンドルールを設定する必要があります。
リソースクォータページの「ネットワーク情報」セクションで、設定済みのセキュリティグループを確認します。
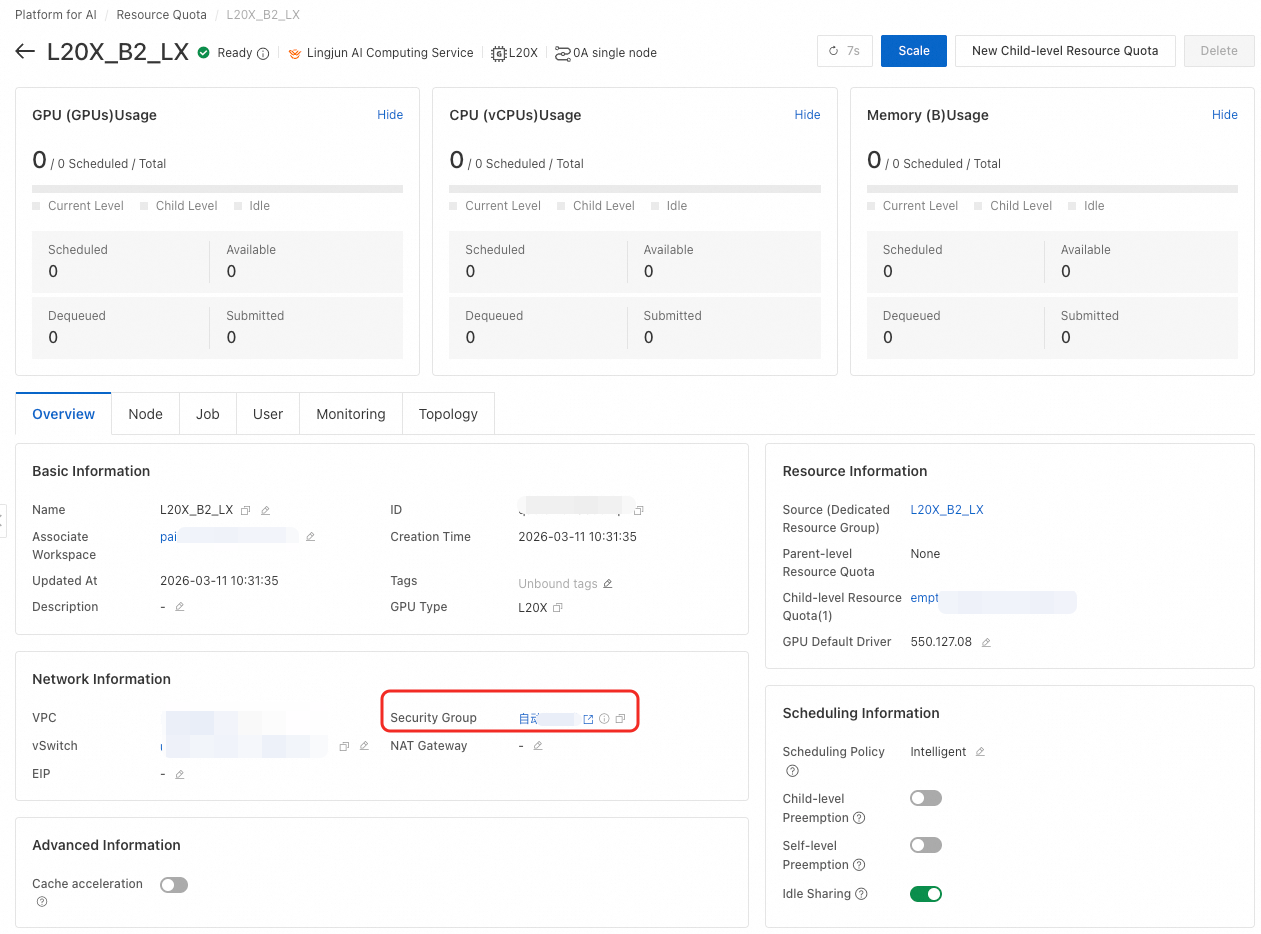
設定するインバウンドポートの数は、設定済みのストレージサービスの数と一致させる必要があります。ここでは、4 つのストレージサービスを設定しているものと仮定します。
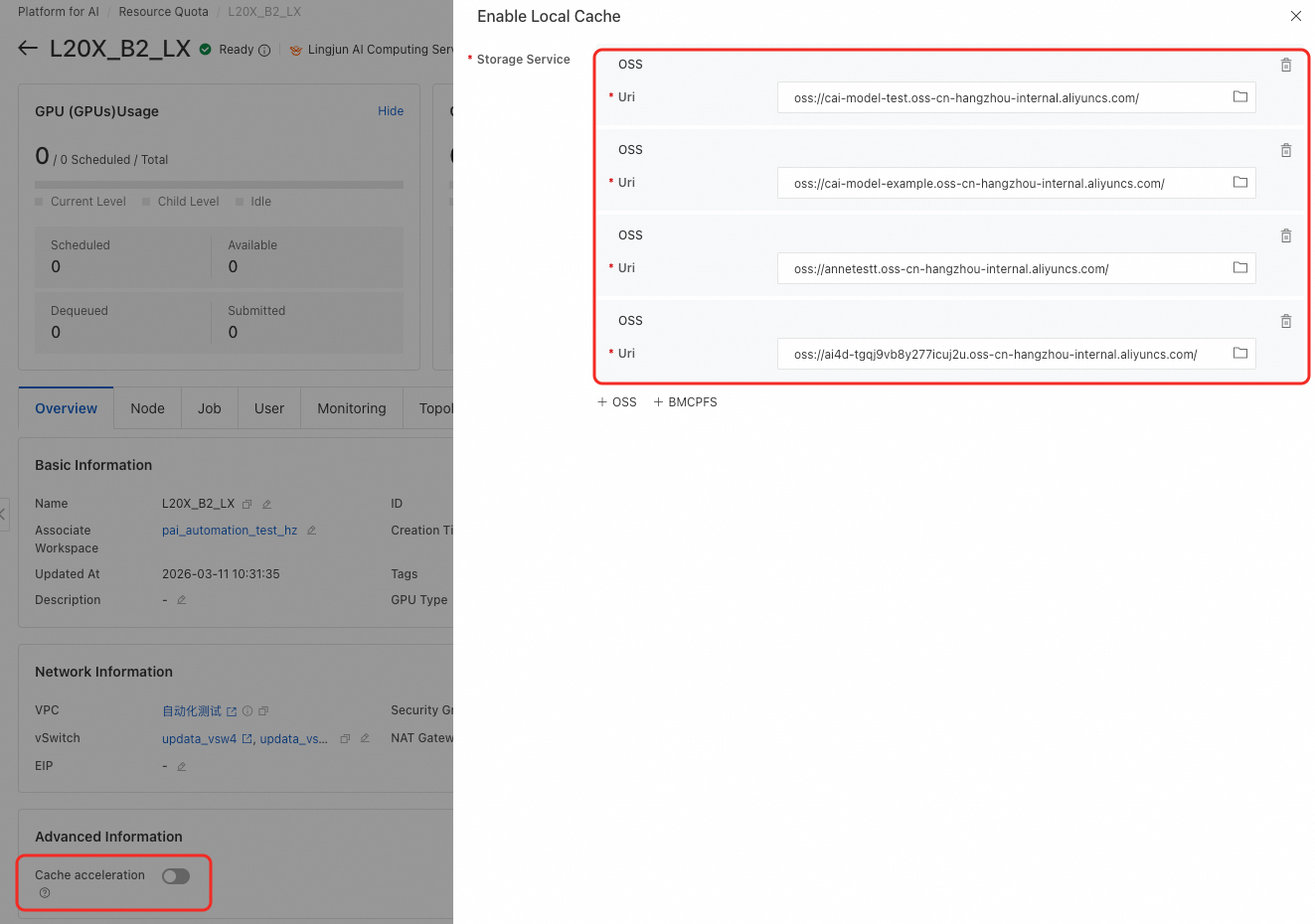
セキュリティグループページに移動します。セキュリティグループのタイプが「エンタープライズ」の場合、インバウンド ルールを追加する必要があります。
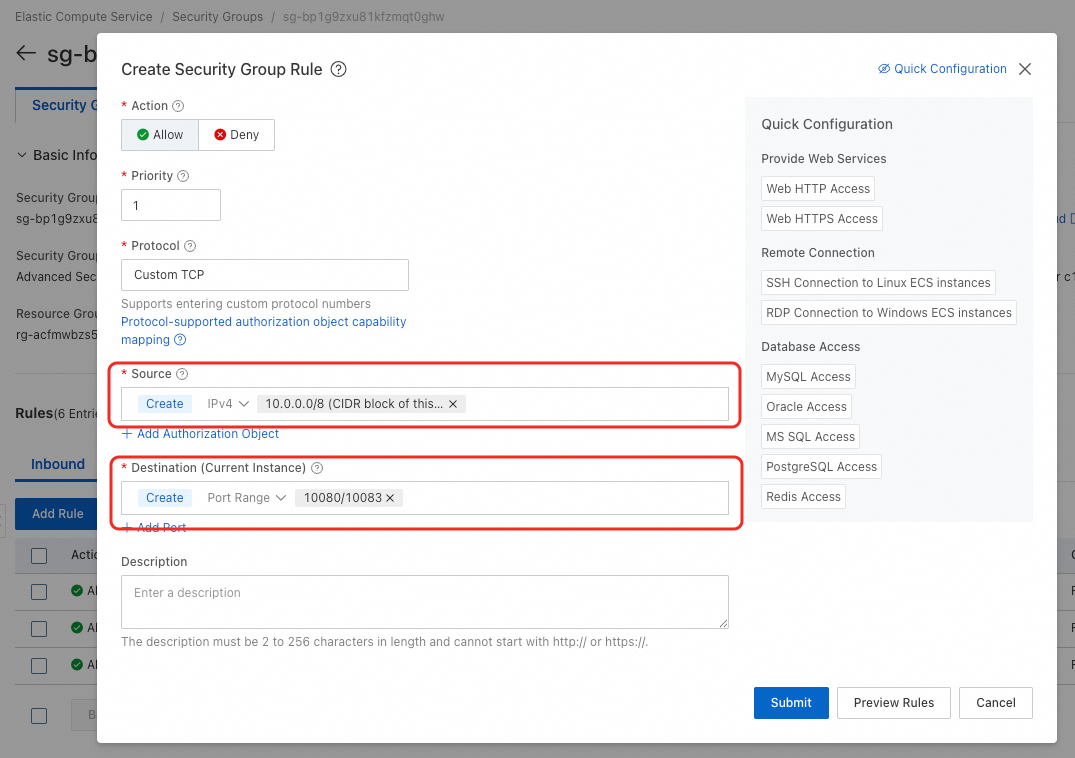 送信元 には、ご利用のリソースクォータで使用している VSwitch の CIDR ブロックを入力します。送信先 にはポート範囲を設定する必要があります。ポート数はキャッシュ対象のストレージサービスの数と等しくなければなりません。ストレージサービスが n 個ある場合、ポート範囲は
送信元 には、ご利用のリソースクォータで使用している VSwitch の CIDR ブロックを入力します。送信先 にはポート範囲を設定する必要があります。ポート数はキャッシュ対象のストレージサービスの数と等しくなければなりません。ストレージサービスが n 個ある場合、ポート範囲は 10080/10080+n-1と設定してください(ただし n ≤ 10)。これはポート範囲10080~10080+n-1を表します。たとえば、4 つのサービスがある場合、値は10080/10083となります。