このトピックでは、Platform for AI (PAI) が提供する大規模言語モデル (LLM) データ処理コンポーネントを使用して、GitHub のコードデータをクリーニングおよび処理する方法について説明します。このトピックでは、LLM データ処理コンポーネントを使用して、オープンソースプロジェクト RedPajama に保存されている少量の GitHub コードデータを処理します。
前提条件
ワークスペースが作成されていること。詳細については、「ワークスペースの作成」をご参照ください。
MaxCompute リソースがワークスペースに関連付けられていること。詳細については、「ワークスペースの管理」をご参照ください。
データセット
このトピックでは、オープンソースプロジェクト RedPajama の GitHub 生データから抽出された 5,000 件のサンプルデータレコードを使用します。
データ品質とモデルトレーニングの効果を向上させるために、「操作手順」で説明されている手順を実行して、データのクリーニングと処理を行うことができます。
操作手順
-
ビジュアルモデリングのページに移動します。
-
PAI コンソールにログインします。
-
左側のナビゲーションウィンドウで、[ワークスペース] をクリックします。[ワークスペース] ページで、管理するワークスペースの名前をクリックします。
-
左側のナビゲーションウィンドウで、 を選択します。
-
パイプラインを作成します。
「デザイナー」ページで、Preset Templates タブをクリックします。
[LLM] タブで、[LLM データ処理 - GitHub コード] エリアを探し、Create をクリックします。
Create Pipeline ダイアログボックスで、パラメーターを設定し、Confirm をクリックします。デフォルト設定を使用できます。
Data Storage パラメーターは、パイプラインによって生成されたデータを格納するための Object Storage Service (OSS) のバケットパスを指定します。
パイプラインリストで、作成したパイプラインをダブルクリックして開きます。
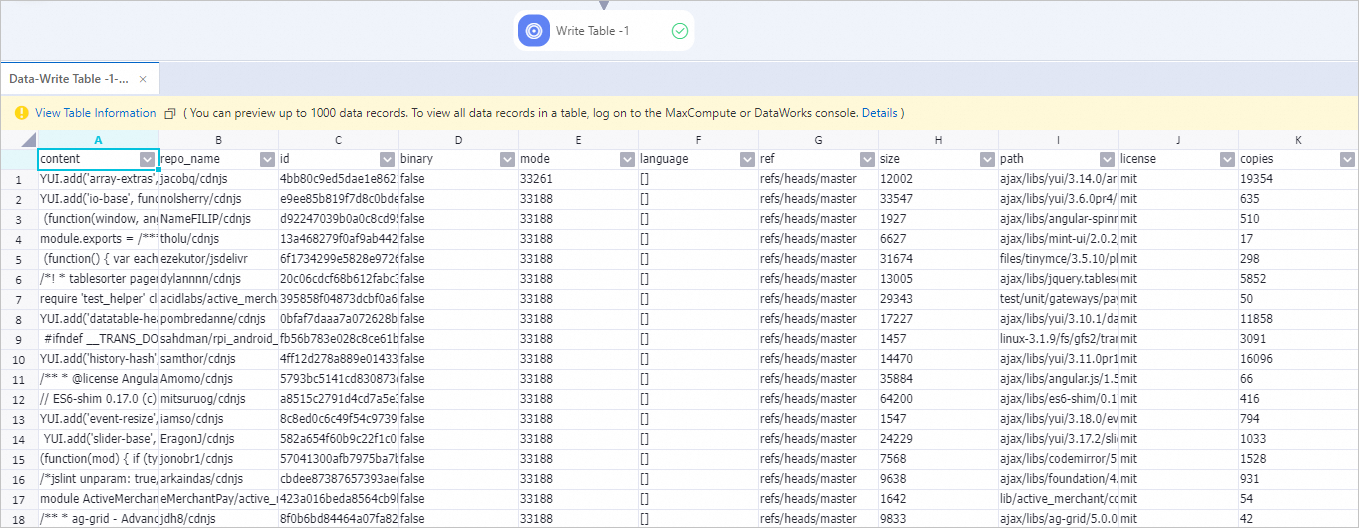
キャンバス上でパイプラインのコンポーネントを表示します (下図参照)。システムはプリセットテンプレートに基づいてパイプラインを自動的に作成します。
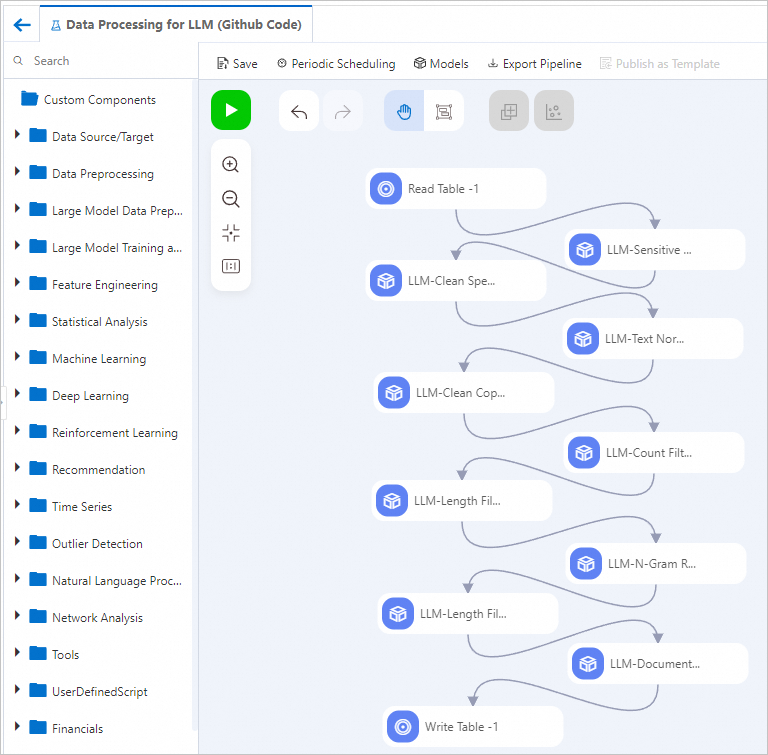
コンポーネント
説明
LLM-Sensitive Content Mask-1
機密情報をマスクします。例:
メールアドレスを
[EMAIL]に置き換えます。電話番号を
[TELEPHONE]または[MOBILEPHONE]に置き換えます。ID カード番号を
IDNUMに置き換えます。
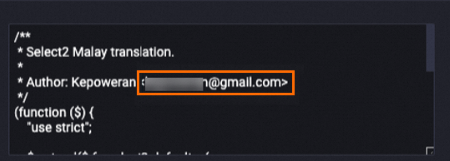
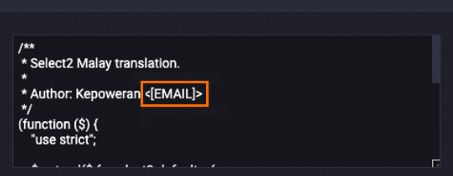
次の例は、処理後の content フィールドのデータを示しています。メールアドレスが
[EMAIL]に置き換えられています。処理前
処理後
LLM-Clean Special Content-1
content フィールドから URL を削除します。
次の例は、データ処理後の content フィールドのデータを示しています。URL が content フィールドから削除されています。
処理前
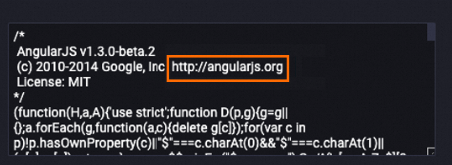
処理後
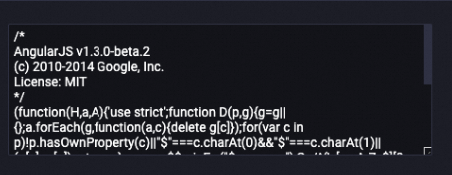
LLM-Text Normalizer-1
content フィールドのテキストを標準の Unicode フォーマットに正規化します。
次の例は、データ処理後の content フィールドのデータを示しています。関連するテキストが正規化されています。
LLM-Clean Copyright Information-1
content フィールドから著作権情報を削除します。
次の例は、データ処理後の content フィールドのデータを示しています。関連する著作権情報が content フィールドから削除されています。
処理前
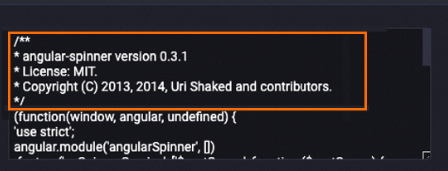
処理後
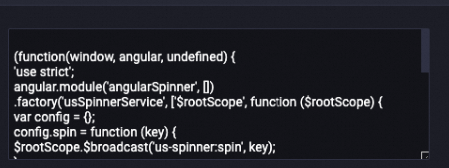
LLM-Count Filter-1
content フィールドから、英数字の比率が要件を満たさないサンプルデータを削除します。GitHub コードデータセットの文字のほとんどは英数字です。このコンポーネントは、特定のダーティデータを削除するために使用できます。
次の例は、削除された特定のデータのリストを示しています。ほとんどのダーティデータが削除されています。
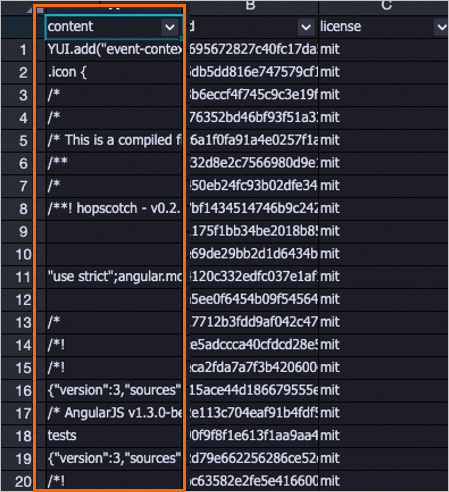
LLM-Length Filter-1
content フィールドの全体の長さ、平均の長さ、および最大行長に基づいてサンプルデータをフィルターします。データの平均の長さと最大行長を測定する前に、改行 ("\n") を使用してサンプルデータを分割します。
次の例は、データセットから削除された特定のデータのリストを示しています。極端に短い、または極端に長いダーティデータが削除されます。
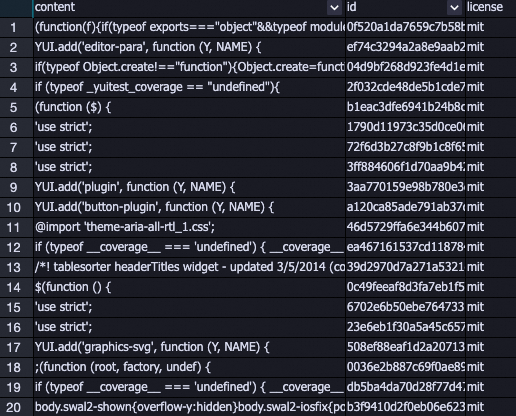
LLM-N-Gram Repetition Filter-1
content フィールドの文字レベルおよび単語レベルの N-Gram 繰り返し率に基づいてサンプルデータをフィルターします。
このコンポーネントは、サイズ N のスライディングウィンドウを使用して、文字または単語のセグメントのシーケンスを作成します。各セグメントはグラムと呼ばれます。コンポーネントはすべてのグラムの出現回数をカウントします。繰り返し率は、
複数回出現するグラムの総数 / すべてのグラムの総数として計算されます。サンプルは、この比率に基づいてフィルターされます。説明単語レベルの統計では、繰り返し率を計算する前に、すべての単語が小文字に変換されます。
LLM-Length Filter-2
スペースに基づいてサンプルデータを単語のリストに分割し、リストの長さに応じてサンプルデータをフィルターします。サンプルデータは単語数に基づいてフィルターされます。
LLM-MinHash Deduplicator (MaxCompute)-1
類似したテキストを削除します。
キャンバスの上部にある
 をクリックして、パイプラインを実行します。
をクリックして、パイプラインを実行します。パイプラインが正常に実行された後、[Write Table-1] コンポーネントを右クリックし、 を選択します。
出力サンプルデータは、前の表で説明したすべての処理コンポーネントによってフィルターおよび処理された後に得られるサンプルデータです。