このドキュメントでは、レコメンデーションシステムで一般的に使用される協調フィルタリングアルゴリズムである SimRank について説明します。その基本原則、パーソナライズドレコメンデーションシナリオ向けの最適化、および本番環境で SimRank++ アルゴリズムをデプロイする方法について解説します。
アルゴリズムの概要
SimRank は、構造的なコンテキストにおけるエンティティ間の類似度を測定するメソッドです。中心的な考え方は、2 つのオブジェクト a と b が他の 2 つのオブジェクト c と d に関連しており、c と d が類似していることがわかっている場合、a と b も類似していると見なされるというものです。任意のノードの自身に対する類似度は 1 です。SimRank は、一部のエンティティ間の既知の類似度を使用して、他の関連エンティティ間の類似度を推論します。
SimRank アルゴリズムは、シンプルで直感的なグラフ理論モデルに基づいています。オブジェクトとその関係を、有向グラフ G = (V, E) としてモデル化します。ここで、V はアプリケーションドメイン内のすべてのオブジェクトを表すノードのセット、E はオブジェクト間の関係を表すエッジのセットです。グラフ内のノード 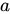 に対して、その入力近傍のセットは
に対して、その入力近傍のセットは 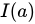 で示され、出力近傍のセットは
で示され、出力近傍のセットは 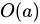 で示されます。オブジェクト
で示されます。オブジェクト 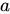 とオブジェクト
とオブジェクト 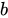 の間の類似度は
の間の類似度は 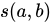 で表され、次のように計算されます。
で表され、次のように計算されます。
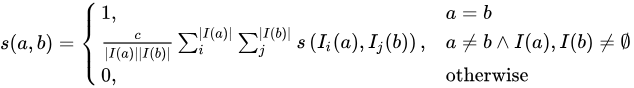
この数式は、エンティティ 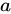 と
と 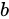 の間の類似度が、
の間の類似度が、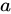 と
と 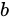 に接続されているすべてのノードの類似度に依存することを示しています。数式中の
に接続されているすべてのノードの類似度に依存することを示しています。数式中の 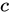 は定数の減衰係数です。
は定数の減衰係数です。
上記の数式は、行列形式でも表現できます。S を有向グラフ G の SimRank スコア行列とし、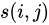 がオブジェクト
がオブジェクト 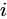 と
と  の間の類似度スコアを表すとします。P を G の隣接行列とし、
の間の類似度スコアを表すとします。P を G の隣接行列とし、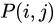 が頂点
が頂点 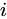 から頂点
から頂点 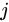 へのエッジの数を表すとします。その場合、次のようになります。
へのエッジの数を表すとします。その場合、次のようになります。
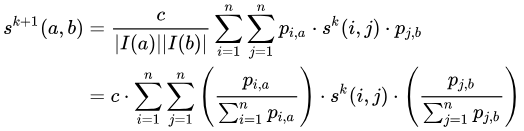
行列表記では、次のようになります。
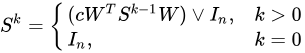
この数式では、行列 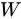 は列正規化された行列
は列正規化された行列 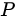 であり、
であり、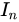 は
は  の単位行列です。
の単位行列です。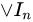 は、行列
は、行列 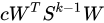 の主対角要素を 1 に設定します。
の主対角要素を 1 に設定します。
SimRank++ アルゴリズムは、SimRank アルゴリズムを拡張し、二部グラフ内のノード間の遷移確率を表す新しい関数 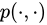 を導入します。
を導入します。
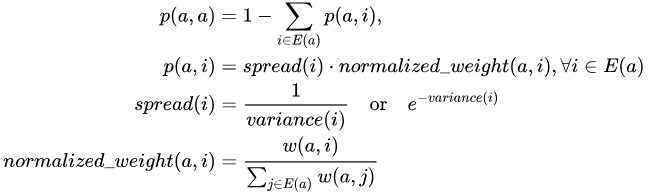
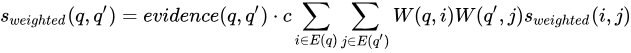
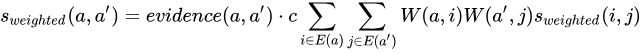
ここで、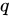 と
と  は任意の 2 つのクエリを表し、
は任意の 2 つのクエリを表し、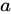 と
と 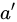 は任意の 2 つの広告を表します。係数
は任意の 2 つの広告を表します。係数 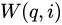 と
と 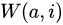 は次のように定義されます。
は次のように定義されます。
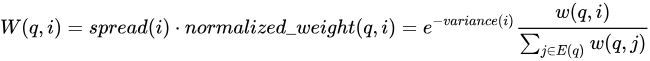
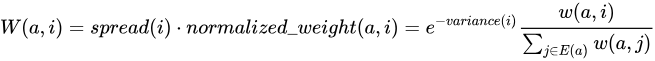
これら 2 つの拡張 (重みとエビデンス値を使用して元の結果を調整する) によって、SimRank++ アルゴリズムが構成されます。
Antonellis らは、2008 年にスポンサードサーチにおけるクエリ書き換えのために SimRank++ を提案しました。
レコメンデーションシステムでの応用
元の SimRank++ アルゴリズムは、計算広告におけるクエリ書き換えのために設計されており、通常は最近のタイムウィンドウからの累積クリックデータを使用して、クエリ間および広告間の関連性を計算します。
クエリによって表現される意図は短期的には安定しているため、複数日の行動データを使用して類似度を計算することは合理的です。
レコメンデーションシステムでは、通常、明確な意図を持つクエリはありません。代わりに、SimRank++ アルゴリズムは通常、ユーザーとアイテムのクリックやその他の行動の二部グラフを入力として使用します。
クエリの関連性という制約がないため、レコメンデーションシナリオにおけるユーザーの行動の意図はあまり明確ではありません。1 人のユーザーが同じ期間に複数の興味を持つことがあり、これらの興味は時間とともに変化する可能性があります。
さらに、数百万から数十億に及ぶユーザー数は、クエリの数よりもはるかに多いことがよくあります。これは、SimRank++ アルゴリズムの実装にとって大きなチャレンジとなります。
これらの理由から、セッションベースの行動二部グラフを使用してアイテム間の類似度を計算することを推奨します。単一のセッション内では、ユーザーの興味はより集中しており、通常は複数のカテゴリのアイテムにまたがることはありません。明示的なセッション ID がないシナリオでは、concat(user_id, date) をセッション ID として使用できます。
増分計算
セッション ID の量が膨大であることと計算上の制約から、複数日のデータを入力としてマージすることは推奨されません。
結果として生じるカバレッジの問題に対処するために、増分計算ソリューションを提案します。SimRank++ ツールキットは、複数日にわたるアイテム間類似度データを保持します。T 日目の類似度を計算する際、T-1 日目のアイテム類似度データでアイテム間類似度行列を初期化します。ツールキットはセッション間類似度データを保持しません。
最後に、複数日のアイテム類似度スコアが累積され、最終的なアイテム間 (i2i) 類似度スコア 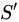 が生成されます。
が生成されます。
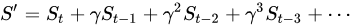
ここで、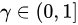 は割引係数です。過去の類似度スコアが現在時刻まで累積される際に、割引が適用されます。データが古いほど、割引は大きくなります。
は割引係数です。過去の類似度スコアが現在時刻まで累積される際に、割引が適用されます。データが古いほど、割引は大きくなります。
注意:累積された類似度スコアは正規化される保証はありません。正規化が必要な場合は、ご自身で実行する必要があります。
最適化 1:人気度の抑制
レコメンデーションシナリオでは、「ハリー・ポッター効果」が容易に発生する可能性があります。人気のあるアイテムはより多くの露出を受け、介入がなければ、アルゴリズムは人気のあるアイテムが他の多くのアイテムと類似していると結論付けるかもしれません。これにより、「富める者はますます富む」というマタイ効果が生じます。この問題を軽減するために、この SimRank ツールキットは人気度の抑制メカニズムを導入しています。
具体的には、まず入力二部グラフから各アイテムのエッジの重みを (合計して) 集計し、人気のあるアイテムを特定します。次に、アイテムの人気度 (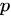 で示される) に
で示される) に z-score 変換を適用します:
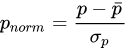
次に、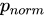 を値の範囲が (0, 1) の単調減少関数に変換します。
を値の範囲が (0, 1) の単調減少関数に変換します。
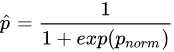
最後に、元のエッジの重みに 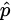 を乗じて新しい重みを取得します。これは、人気のあるアイテムへのランダムウォークの抵抗を増やすことと同じです。
を乗じて新しい重みを取得します。これは、人気のあるアイテムへのランダムウォークの抵抗を増やすことと同じです。
最適化 2:優先カテゴリによる重み付けの再設定
レコメンデーションシナリオでは、偶発的なクリックなど、ユーザーのクリック行動にノイズが含まれることがあります。ノイズを低減するために、アイテムカテゴリに対するユーザーのプリファレンスを計算して、二部グラフの重みを調整します。
特定のユーザーについて、カテゴリ 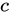 に対するプリファレンススコアは次のようになります。
に対するプリファレンススコアは次のようになります。
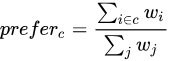
アイテム 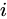 の重みは、元の
の重みは、元の 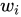 から
から 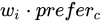 に調整されます。ここで、アイテム
に調整されます。ここで、アイテム 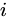 はカテゴリ
はカテゴリ 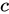 に属します。
に属します。
入出力フォーマット
入力テーブルはパーティションテーブルをサポートしており、4 つの列が含まれています。
-
user_id:ユーザー ID、session_id、クエリなど (任意の型)
-
item_id:アイテム ID (任意の型)
-
weight:倍精度浮動小数点数の重み
-
category:[オプション] アイテムのカテゴリ。このフィールドを設定すると、精度が向上する場合があります (任意の型)。
-
入力テーブルには、重複する
<user_id, item_id>のペアを含めることはできません。事前に重みをマージしてください。 -
カテゴリデータを使用してアルゴリズムのパフォーマンスを向上させる場合、このフィールドに null 値を持つレコードは削除されます。カテゴリ列に null 値がないか確認してください。
-
注意:同じクエリに対する重みの分散をコントロールする必要があります。分散が大きすぎると、重み遷移行列の要素がゼロになる可能性があり、再現率が大幅に低下します。
-
事前に重み列を正規化または標準化することを推奨します。たとえば、「min-max」、「z-score」、「log」、「sigmoid」変換を適用します。
-
input_weight_normalizerパラメーターを設定することもできます。
-
-
二部グラフのエッジに適切な重みを設定すると、アルゴリズムのパフォーマンスが大幅に向上します。
-
ctrを重みとして使用すると、CTR が高いレコードのインプレッション数 (PV) が低い可能性があるため、ノイズの多いデータが容易に導入される可能性があります。 -
log(1+click)をエッジの重みとして使用することを検討してください。
-
-
ノイズの多いデータをフィルタリングするために、データクレンジングを実行することを推奨します。
-
特定のクエリに対して、
click/sum(click) < thresholdとなるデータをフィルタリングできます。たとえば、threshold=3e-5 です。
-
アイテム類似度 (i2i) 出力テーブルのフォーマット (パーティション列をサポート):
-
item1:アイテム ID
-
item2:類似アイテム ID
-
cumulative_score:複数日のデータを使用して計算された累積類似度スコア。このフィールドを最終結果として使用します。
-
score:当日のデータから計算された類似度スコア。null の場合があります。
注意:
クエリ類似度 (q2q) 出力テーブルのフォーマット (パーティション列をサポート):
-
query1:元のクエリ
-
query2:類似クエリ
-
score:類似度スコア
ジョブの送信
-
simrank_plus_plus-1.3.jar アルゴリズムパッケージをダウンロードします。
-
パッケージをリソースとして MaxCompute プロジェクトにアップロードします。
[リソースの作成] ダイアログボックスで、[エンジンタイプ] を [MaxCompute] に、[リソースタイプ] を [JAR] に設定します。[ODPS リソースとしてアップロード] を選択し、お使いのコンピューターから
simrank_plus_plus-1.3.jarファイルをアップロードしてから、[作成] をクリックします。 -
DataWorks で、ODPS MR ノードを作成し (ODPS SQL ノードを使用するとエラーが発生する場合があります)、次のコマンドでジョブを送信します。
--@resource_reference{"simrank_plus_plus-1.3.jar"} jar -resources simrank_plus_plus-1.3.jar -classpath simrank_plus_plus-1.3.jar com.aliyun.pai.simrank.SimRankDriver -project ${max_compute_project} -end_point http://service.cn-hangzhou.maxcompute.aliyun.com/api -access_id ${access_id} -access_key ${access_key} -input_table simrank_i2i_input -input_table_partition ds=${bizdate} -output_table simrank_i2i_output -output_table_partition ds=${bizdate} -init_partition ds=${yesterday} -session_column device_id -item_column item_id -category_column cate_lv3_id -num_matmul_reducer 2000 ;
パラメーター
|
パラメーター |
型 |
説明 |
デフォルト |
|
access_id |
string |
ご利用の Alibaba Cloud アカウントの AccessKey ID。 |
なし |
|
access_key |
string |
ご利用の Alibaba Cloud アカウントの AccessKey Secret。 |
なし |
|
sts_token |
string |
ご利用の Alibaba Cloud アカウントのセキュリティトークン。 |
なし |
|
end_point |
string |
MaxCompute サービスのエンドポイント。パブリッククラウドについては、「エンドポイント」をご参照ください。 |
なし |
|
project |
string |
デフォルトの MaxCompute プロジェクト。 |
なし |
|
input_table |
string |
入力テーブルの名前。 |
なし |
|
input_table_partition |
string |
入力テーブルのパーティション。 |
なし |
|
init_partition |
string |
初期化に使用されるアイテム類似度出力テーブルのパーティション。 |
なし。通常、前日のパーティションが使用されます。 |
|
output_table |
string |
アイテム類似度出力テーブル。 |
なし |
|
output_table_partition |
string |
出力テーブルのパーティション。 |
なし |
|
session_output_table |
string |
クエリ類似度出力テーブル。 |
なし |
|
session_output_table_partition |
string |
クエリ類似度出力テーブルのパーティション。 |
なし |
|
session_column |
string |
クエリを表す入力テーブルの列名。 |
user_id |
|
item_column |
string |
アイテムを表す入力テーブルの列名。 |
item_id |
|
category_column |
string |
アイテムカテゴリを表す入力テーブルの列名。 |
なし |
|
job_name |
string |
ジョブの名前と中間テーブルのプレフィックス。中断されたジョブを再開するには、このパラメーターを設定します。名前は、異なるジョブ間で一意である必要があります。 |
UUID が自動的に生成されます。 |
|
debug |
bool |
デバッグモードを有効にするかどうかを指定します。 |
false |
|
iter_times |
int |
SimRank アルゴリズムの反復回数。 |
3 |
|
decay_factor |
float |
SimRank アルゴリズムの減衰係数 C。値の範囲:(0, 1)。 |
0.8 |
|
discount_factor |
float |
類似度スコアの時間減衰係数。このパラメーターは増分計算にのみ使用されます。値の範囲:(0, 1]。 |
0.95 |
|
sim_threshold |
float |
SimRank アルゴリズムの反復中に使用される類似度フィルタリングのしきい値。 |
0.000001 |
|
weight_threshold |
float |
二部グラフのエッジの重みに対するフィルタリングのしきい値。 |
1e-6 |
|
input_weight_normalizer |
string |
入力の重みの正規化関数。例: |
なし |
|
zero_spread_weight_cnt |
int |
重み遷移行列スコアにおけるゼロ値のエラーしきい値。ゼロ値は、入力の重みの分散が大きすぎることを示します。 |
100 |
|
default_evidence |
float |
SimRank++ アルゴリズムで使用されるデフォルトのエビデンスの重み。値の範囲:(0, 0.5)。 |
0.25 |
|
evidence_amplifier |
float |
エビデンスの重みの増幅係数。増幅されたエビデンスの範囲は [default_evidence, evidence_amplifier] です。 |
1/decay_factor |
|
anti_popular |
bool |
「ハリー・ポッター効果」に対処するために人気度の抑制を有効にするかどうかを指定します。 |
true |
|
item_block_size |
int |
アイテム行列ブロックのサイズ。このパラメーターはパフォーマンスに関連しており、変更しないことを推奨します。小規模な入力データセットでは、行列ブロッキングはトリガーされません。 |
50000 |
|
session_block_size |
int |
クエリ行列ブロックのサイズ。このパラメーターはパフォーマンスに関連しており、変更しないことを推奨します。小規模な入力データセットでは、行列ブロッキングはトリガーされません。 |
50000 |
|
matmul_strategy |
int |
行列ブロックの乗算戦略。有効な値:2、3、4。小規模な入力データセットでは、行列ブロッキングはトリガーされません。 |
4 |
|
matmul_reducer_memory |
int |
行列乗算ジョブ 1 の Reducer のメモリ (MB)。 |
行列ブロッキングがトリガーされた場合は 12288、それ以外の場合は 3072。 |
|
matmul_split_size |
int |
行列乗算の Mapper のスライスサイズ (MB)。 |
行列ブロッキングがトリガーされた場合は 16、それ以外の場合は 256。 |
|
num_matmul_reducer |
int |
行列乗算ジョブ 1 の Reducer の数。 |
行列ブロッキングがトリガーされた場合は自動的に計算されます。それ以外の場合は該当なし。 |
|
num_matmul_reducer2 |
int |
行列乗算ジョブ 2 の Reducer の数。ブロッキングがトリガーされない場合は不要です。 |
なし |
|
evidence_split_size |
int |
エビデンス行列を計算するための Mapper のスライスサイズ (MB)。 |
16 |
|
num_evidence_reducer1 |
int |
エビデンス行列計算ジョブ 1 の Reducer の数。 |
なし |
|
num_evidence_reducer2 |
int |
エビデンス行列計算ジョブ 2 の Reducer の数。 |
なし |
|
priority |
int |
ジョブの優先度。 |
1 |
クエリ書き換えなどの検索シナリオでは、anti_popular を false に設定します。レコメンデーションシナリオでは、true に設定します。
ケーススタディ
検索シナリオでは、入力データは約 1,700 万行で構成され、120 万のクエリと 150 万のアイテムが含まれています。以下のパラメーターを使用すると、パイプライン全体が約 87 分で完了します。
--@resource_reference{"simrank_plus_plus-1.3.jar"}
jar -resources simrank_plus_plus-1.3.jar
-classpath simrank_plus_plus-1.3.jar
com.aliyun.pai.simrank.SimRankDriver
-project ${project}
-end_point http://service.cn-shanghai.maxcompute.aliyun.com/api
-access_id ${access_id}
-access_key ${access_key}
-input_table ${input_table}
-input_table_partition dt=20240512
-output_table simrank_i2i_score
-output_table_partition dt=20240512
-session_output_table simrank_q2q_score
-session_output_table_partition dt=20240512
-output_table_lifecycle 7
-session_column query_word
-item_column item_id
-category_column category
-anti_popular false
-num_matmul_reducer 2000
-num_evidence_reducer1 1000
-num_evidence_reducer2 200