このトピックでは、ユーザーとアイテムの機能に基づいて製品レコメンデーションモデルを作成する方法について説明します。
前提条件
ワークスペースが作成済み。 詳細については、「ワークスペースの作成」をご参照ください。
背景情報
このサンプルパイプラインでは、4月と5月の実際のeコマースデータを使用してモデルをトレーニングし、6月のデータを使用してモデルを評価します。 モデルのパフォーマンスが検証された後、モデルはオンラインサービスとしてElastic Algorithm Service (EAS) にデプロイされます。
サンプルパイプラインは、eコマースプラットフォームからの匿名化された実データを使用します。 データは商用目的ではありません。
サンプルパイプラインと関連データは、Machine Learning Designerが提供するプリセットテンプレートに含まれています。 テンプレート内のコンポーネントをドラッグして、協調フィルタリングに基づいて推奨モデルを作成できます。 次に、Machine Learning Designerでトレーニングしたモデルを数回クリックするだけでEASにデプロイできます。
一般的なワークフロー

MaxComputeにデータをインポートして、教師付き構造化データを生成します。
データの前処理やフィーチャの派生などのフィーチャエンジニアリング操作を実行します。 機能派生は、ビジネス固有の特性をより適切にキャプチャするために、既存のデータから新しいデータを生成します。
データを2つのデータセットに分割します。 1つのデータセットを使用して、バイナリ分類モデルをトレーニングします。 他のデータセットを使用して、モデルのパフォーマンスを評価します。
モデルのパフォーマンスを評価します。
データセット
サンプルパイプラインでは、Tianchi Big Data Competitionのデータセットを使用します。 データセットには、4月から6月までのeコマースプラットフォームのショッピングデータが含まれています。 次の表に、データセットのフィールドを示します。
項目 | 短い説明 | データ型 | 完全な説明 |
user_id | User ID | STRING | アイテムを購入したユーザーのID。 |
item_id | アイテムID | STRING | 購入したアイテムのID。 |
active_type | ショッピング行動 | STRING |
|
active_date | 購入日 | STRING | ユーザーがアイテムを購入した日付。 |
次の図は、サンプルパイプラインで使用される生データを示しています。 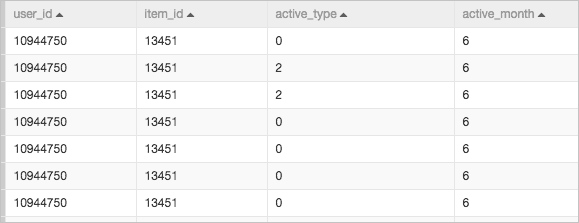
手順
Machine Learning Designerページに移動します。
PAIコンソールにログインします。
左側のナビゲーションウィンドウで、[ワークスペース] をクリックします。 [ワークスペース] ページで、管理するワークスペースの名前をクリックします。
ワークスペースページの左側のナビゲーションウィンドウで、機械学習デザイナーページに移動します。
パイプラインを作成します。
Visualized Modeling (Designer) ページで、プリセットテンプレートタブをクリックします。
[プリセットテンプレート] タブで、オブジェクト特性に基づく推奨事項をクリックし、作成.
[パイプラインの作成] ダイアログボックスで、パラメーターを設定します。 デフォルト値を使用できます。
Pipeline Data Pathパラメーターに指定された値は、パイプラインのランタイム中に生成された一時データおよびモデルのObject Storage Service (OSS) バケットパスです。
[OK] をクリックします。
パイプラインの作成には約10秒かかります。
[パイプライン] タブで、ダブルクリックします。オブジェクト特性に基づく推奨事項パイプラインを開きます。
キャンバス上のパイプラインのコンポーネントを表示します。 次の図は、プリセットテンプレートに基づいて自動的に作成されるパイプラインを示しています。

セクション
説明
①
このセクションのコンポーネントは、元のデータセットに基づいて次のフィーチャの新しいデータを生成するフィーチャエンジニアリングを実行します。
ユーザー機能: 生成されたデータには、各ユーザーの購入数、クリック数、クリック対購入の比率が含まれます。 クリック対購入の比率は、クリック数を購入数で割ることによって計算されます。 この比率は、ショッピング活動におけるユーザの決定性を反映する。
アイテムの特徴: 生成されたデータには、各アイテムの購入数、クリック数、購入対クリックの比率が含まれます。 購入対クリックの比率は、購入数をクリック数で割ることによって計算されます。
フィーチャエンジニアリング後、次の図に示すように、データセットは4フィールドから10フィールドに拡張されます。

②
このセクションのコンポーネントでは、論理回帰アルゴリズムを使用してモデルをトレーニングします。
トレーニング済みモデルを保存するには、[バイナリ分類のロジスティック回帰] コンポーネントをクリックし、右側のウィンドウで [フィールド設定] タブをクリックし、[PMMLを生成するかどうか] を選択します。
③
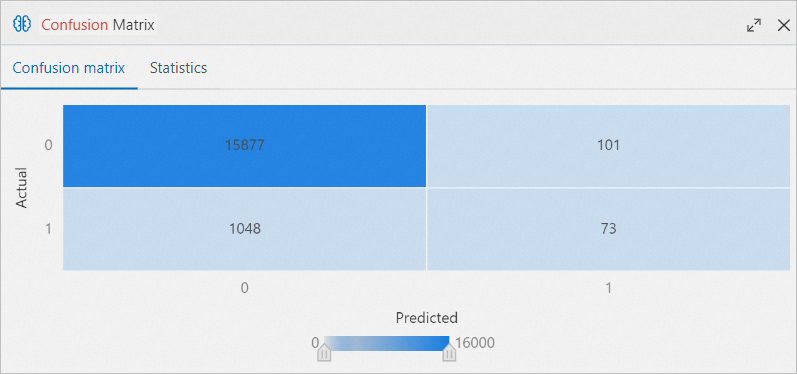
このセクションのコンポーネントでは、モデルのトレーニングに使用されていないデータを使用して、モデルのパフォーマンスを評価します。 ほとんどの場合、Confusion MatrixおよびBinary Classification Evaluationコンポーネントを使用して、推奨モデルのパフォーマンスを評価できます。
パイプラインを実行し、予測結果を表示します。
キャンバスの左上隅で、実行アイコンが表示されます。
パイプラインの実行が完了したら、バイナリ分類のロジスティック回帰キャンバス上のコンポーネントを選択し、トレーニング済みモデルをエクスポートします。
を右クリックし、予測キャンバス上のコンポーネントを選択し、モデルの予測結果を表示します。
モデルの評価結果を表示します。
キャンバス上のバイナリ分類評価コンポーネントを右クリックし、ビジュアル分析を選択します。
では、バイナリ分類評価セクションをクリックし、評価チャート受信機動作特性 (ROC) 曲線を見るためのタブ。
 青色領域は、曲線下面積 (AUC) 値を表す。 青い領域が大きいほど、モデルの品質が高いことを示します。
青色領域は、曲線下面積 (AUC) 値を表す。 青い領域が大きいほど、モデルの品質が高いことを示します。 キャンバス上の混乱マトリックスコンポーネントを右クリックし、ビジュアル分析を選択します。
では、混乱マトリックスセクションをクリックし、混乱マトリックスタブで評価結果を表示します。
モデルをデプロイします。
モデルのパフォーマンスが期待どおりの場合は、キャンバスの上部にある [モデル] をクリックして、モデルをオンラインサービスとしてデプロイします。 詳細については、「オンラインサービスとしてのモデルのデプロイ」をご参照ください。