線形サポートベクターマシン (SVM) は、統計的学習理論に基づいて構築された二値分類器です。カーネル関数を使用せずに、構造的リスクを最小化することで、2つのクラス間のマージンを最大化する決定境界を見つけ出します。
線形 SVM は、次の場合に使用します:
分類タスクがバイナリ (2 クラスのみ) である。
線形 SVM は多クラス分類をサポートしていません。多クラス分類タスクには、別のコンポーネントを使用してください。
アルゴリズムのリファレンス
線形 SVM コンポーネントは、L2-SVM のための信頼領域ニュートン法を実装しています。詳細については、「Trust Region Newton Method for Large-Scale Logistic Regression」の「Trust region method for L2-SVM」セクションをご参照ください。
コンポーネントの設定
設定方法は、ビジュアルモデリングのビジュアルインターフェイスと PAI コマンドラインの 2 つがあります。インタラクティブな実験にはビジュアルモデリングインターフェイスを使用し、スクリプト化または自動化されたワークフローには PAI コマンドを使用します。
方法 1: ビジュアルモデリングで設定
入力ポート
線形 SVM コンポーネントには入力ポートが 1 つあります。これをテーブル読み込みコンポーネントに接続します。
パラメーター
| タブ | パラメーター | 必須 | 説明 |
|---|---|---|---|
| フィールド設定 | 特徴量列 | はい | 特徴量として使用される列。使用可能なデータ型:BIGINT または DOUBLE。 |
| フィールド設定 | ラベル列 | はい | クラスラベルを含む列。使用可能なデータ型:BIGINT、DOUBLE、または STRING。 |
| パラメーター設定 | 正例のラベル | いいえ | 正例クラスとして扱われるラベル値。省略した場合、コンポーネントはランダムに値を選択します。クラスのディストリビューションが不均衡な場合に、このパラメーターを指定します。 |
| パラメーター設定 | 正のペナルティ係数 | いいえ | 正例を誤分類した場合に割り当てられるコスト。この値を大きくすると、モデルは正例クラスのエラーに対してより重いペナルティを課すようになります。これは、偽陰性のコストが高い場合に役立ちます。有効な値:(0, +∞)。デフォルト:1.0。 |
| パラメーター設定 | 負例のペナルティ係数 | いいえ | 負例を誤分類した場合に割り当てられるコスト。この値を大きくすると、モデルは負例クラスのエラーに対してより重いペナルティを課すようになります。これは、偽陽性のコストが高い場合に役立ちます。有効な値:(0, +∞)。デフォルト:1.0。 |
| パラメーター設定 | 収束係数 | いいえ | 収束許容値 (イプシロン)。反復間の変化がこの値を下回ると、トレーニングが停止します。値を小さくするとトレーニングの精度は向上しますが、より多くの反復が必要になります。有効な値:(0, 1)。デフォルト:0.001。 |
| チューニング | コア数 | いいえ | トレーニングに使用する CPU コアの数。省略した場合は自動的に割り当てられます。 |
| チューニング | コアあたりのメモリサイズ | いいえ | コアあたりに割り当てられるメモリ (MB 単位)。省略した場合は自動的に割り当てられます。 |
出力ポート
このコンポーネントは、バッチモデルと同じフォーマットのバイナリモデルを、後続の予測コンポーネントに出力します。
方法 2:PAI コマンドの実行
SQL スクリプトコンポーネントを使用して PAI コマンドを送信します。設定手順については、「SQL スクリプト」をご参照ください。
PAI -name LinearSVM -project algo_public
-DinputTableName="bank_data"
-DmodelName="xlab_m_LinearSVM_6143"
-DfeatureColNames="pdays,emp_var_rate,cons_conf_idx"
-DlabelColName="y"
-DpositiveLabel="0"
-DpositiveCost="1.0"
-DnegativeCost="1.0"
-Depsilon="0.001";パラメーター
| パラメーター | 必須 | 説明 | デフォルト |
|---|---|---|---|
inputTableName | はい | 入力テーブルの名前。 | — |
inputTablepartitions | いいえ | トレーニングに使用するパーティション。フォーマット:Partition_name=value (単一) または name1=value1/name2=value2 (複数レベル)。複数のパーティションはカンマで区切ります。 | すべてのパーティション |
modelName | はい | 出力モデルの名前。 | — |
featureColNames | はい | 入力テーブルの特徴量列。 | — |
labelColName | はい | ラベル列の名前。 | — |
positiveLabel | いいえ | 正例クラスのラベル値。 | ラベル列からランダムな値 |
positiveCost | いいえ | 正例のペナルティ係数。この値を大きくすると、モデルは正例クラスのエラーに対してより重いペナルティを課すようになります。有効な値:(0, +∞)。 | 1.0 |
negativeCost | いいえ | 負例のペナルティ係数。この値を大きくすると、モデルは負例クラスのエラーに対してより重いペナルティを課すようになります。有効な値:(0, +∞)。 | 1.0 |
epsilon | いいえ | 収束許容値。有効な値:(0, 1)。 | 0.001 |
enableSparse | いいえ | 入力データがスパース形式の場合は true に設定します。 | false |
itemDelimiter | いいえ | スパース入力でキーと値のペアを区切るデリミタ。 | , (カンマ) |
kvDelimiter | いいえ | スパース入力でキーと値を区切るデリミタ。 | : (コロン) |
coreNum | いいえ | CPU コアの数。正の整数である必要があります。 | 自動割り当て |
memSizePerCore | いいえ | コアあたりのメモリ (MB 単位)。有効な値:1~65536。 | 自動割り当て |
注意事項
不均衡なクラス:正例と負例のサンプルに大きな偏りがある場合は、[正例のラベル] を明示的に設定し、positiveCost または negativeCost の値を上げて少数派クラスの重みを大きくします。例えば、偽陽性よりも偽陰性の方が有害である場合は、positiveCost を 1.0 より大きい値に設定します。
スパースデータ:高次元のスパース特徴量 (例えば、テキストデータやワンホットエンコーディングされたデータ) の場合は、enableSparse=true に設定し、ご利用のデータ形式に合わせて itemDelimiter と kvDelimiter を設定します。
リソースのチューニング:ほとんどのワークロードでは、[コア数] と [コアあたりのメモリサイズ] は未設定のままにしてください。プラットフォームがデータサイズに基づいて自動的にリソースを割り当てます。予測可能なリソース使用量が必要な場合にのみ、これらの値を手動で設定してください。
例
この例では、小規模なデータセットで線形 SVM 二値分類器をトレーニングします。
入力として、以下のトレーニングデータを使用します。
id y f0 f1 f2 f3 f4 f5 f6 f7 1 -1 -0.294118 0.487437 0.180328 -0.292929 -1 0.00149028 -0.53117 -0.0333333 2 +1 -0.882353 -0.145729 0.0819672 -0.414141 -1 -0.207153 -0.766866 -0.666667 3 -1 -0.0588235 0.839196 0.0491803 -1 -1 -0.305514 -0.492741 -0.633333 4 +1 -0.882353 -0.105528 0.0819672 -0.535354 -0.777778 -0.162444 -0.923997 -1 5 -1 -1 0.376884 -0.344262 -0.292929 -0.602837 0.28465 0.887276 -0.6 6 +1 -0.411765 0.165829 0.213115 -1 -1 -0.23696 -0.894962 -0.7 7 -1 -0.647059 -0.21608 -0.180328 -0.353535 -0.791962 -0.0760059 -0.854825 -0.833333 8 +1 0.176471 0.155779 -1 -1 -1 0.052161 -0.952178 -0.733333 9 -1 -0.764706 0.979899 0.147541 -0.0909091 0.283688 -0.0909091 -0.931682 0.0666667 10 -1 -0.0588235 0.256281 0.57377 -1 -1 -1 -0.868488 0.1 入力として、以下のテストデータを使用します。
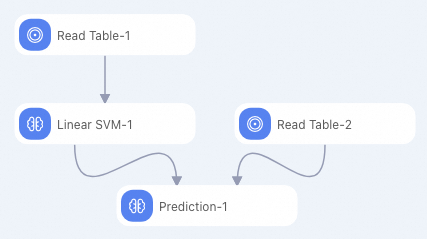
id y f0 f1 f2 f3 f4 f5 f6 f7 1 +1 -0.882353 0.0854271 0.442623 -0.616162 -1 -0.19225 -0.725021 -0.9 2 +1 -0.294118 -0.0351759 -1 -1 -1 -0.293592 -0.904355 -0.766667 3 +1 -0.882353 0.246231 0.213115 -0.272727 -1 -0.171386 -0.981213 -0.7 4 -1 -0.176471 0.507538 0.278689 -0.414141 -0.702128 0.0491804 -0.475662 0.1 5 -1 -0.529412 0.839196 -1 -1 -1 -0.153502 -0.885568 -0.5 6 +1 -0.882353 0.246231 -0.0163934 -0.353535 -1 0.0670641 -0.627669 -1 7 -1 -0.882353 0.819095 0.278689 -0.151515 -0.307329 0.19225 0.00768574 -0.966667 8 +1 -0.882353 -0.0753769 0.0163934 -0.494949 -0.903073 -0.418778 -0.654996 -0.866667 9 +1 -1 0.527638 0.344262 -0.212121 -0.356974 0.23696 -0.836038 -0.8 10 +1 -0.882353 0.115578 0.0163934 -0.737374 -0.56974 -0.28465 -0.948762 -0.933333 次の図に示すパイプラインを作成します。詳細については、「アルゴリズムモデリング」をご参照ください。
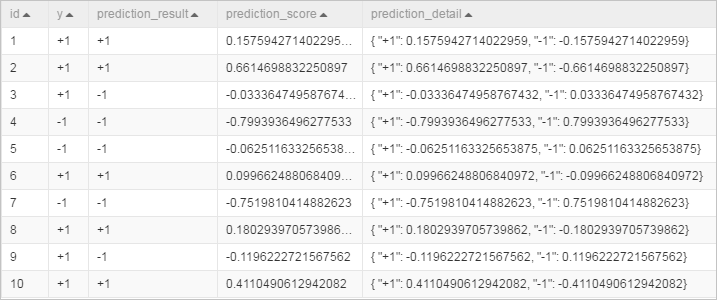
線形 SVM コンポーネントに対して、次の表にリストされているパラメーターを設定します。他のすべてのパラメーターはデフォルト値のままにします。
タブ パラメーター 値 フィールド設定 特徴量カラム f0、f1、f2、f3、f4、f5、f6、および f7 を選択します。 フィールド設定 ラベルカラム y を選択します。 パイプラインを実行し、予測結果を表示します。