TPC-DSは、ビッグデータシステムのパフォーマンスと効率を測定するために使用される最も有名で広く認識されているベンチマークの1つです。 Alibaba Cloud E-MapReduce (EMR) は、TPC-DSの100テラバイトベンチマークを実行できると認定された最初のビッグデータシステムです。 このトピックでは、EMRクラスター内のOSS-HDFSを最大限に活用して、TPC-DSの99個のSQL文を正常に実行し、一連の最適化対策を講じることで最高のパフォーマンスを達成する方法について説明します。
シナリオ
ビッグデータのパフォーマンス評価
特に大規模なデータ分析とクエリワークロードを最適化するために、OSS-HDFSをHadoopのストレージとして使用するときのビッグデータ処理パフォーマンスを評価する場合は、TPC-DSを意思決定支援ベンチマークとして使用できます。
データレイクのアーキテクチャ検証
Alibaba Cloud Object Storage Service (OSS) をベースにしたデータレイクアーキテクチャを構築しているか、すでに持っていて、複雑なクエリ処理、抽出、変換、ロード (ETL) ジョブ、およびデータウェアハウスパフォーマンスの効率を検証したい場合は、EMRクラスターでTPC-DSを実行して、客観的かつ標準化された結果を取得できます。
システム性能を理解する
クラスターをスケールアウトしたり、ハードウェアをアップグレードしたり、ストレージポリシーを調整したりする場合、TPC-DSベンチマークは、データ量の増加やコンピューティングリソースの変更に伴うシステム全体のパフォーマンスを把握するのに役立ちます。
コスト効率分析
OSSには、コストの点で従来のHadoop分散ファイルシステム (HDFS) に比べて利点があります。 TPC-DSに対するOSS-HDFSのパフォーマンスを測定することで、コスト要因を組み合わせて、OSS-HDFSが特定のビジネスシナリオに適しているかどうかを判断し、より経済的な選択を行うことができます。
背景情報
TPC-DSは、データ管理システムの測定ベンチマークを定義する最もよく知られている組織の1つであるTransaction Processing Performance Council (TPC) によって設計および維持される標準ベンチマークです。 TPC-DSの公式ツールは、主にスタンドアロンのデータ生成とSQLクエリの実行に使用されますが、大規模な分散シナリオには適していません。 ビッグデータ分析シナリオに適用するには、次のツールとEMRクラスターを準備する必要があります。
このツールはHortonworksによって開発され、HadoopエコシステムのHiveやSparkなどのコンポーネント用にカスタマイズされています。 ビッグデータクエリの課題を効果的にシミュレートし、TPC-DSでの複雑なSQL文の生成と実行、およびクラスター環境でのTPC-H標準をサポートできます。
5.15.1以降のEMRクラスター
5.15.1以降のEMRクラスターを使用する必要があります。 このバージョンは、Hive 3.1に対応するHortonworks Data Platform (HDP) 3シリーズと互換性があり、サポートしています。
手順1: EMRクラスターの作成とTPC-DSベンチマークテストツールのダウンロード
5.15.1以降のEMRクラスターを作成します。
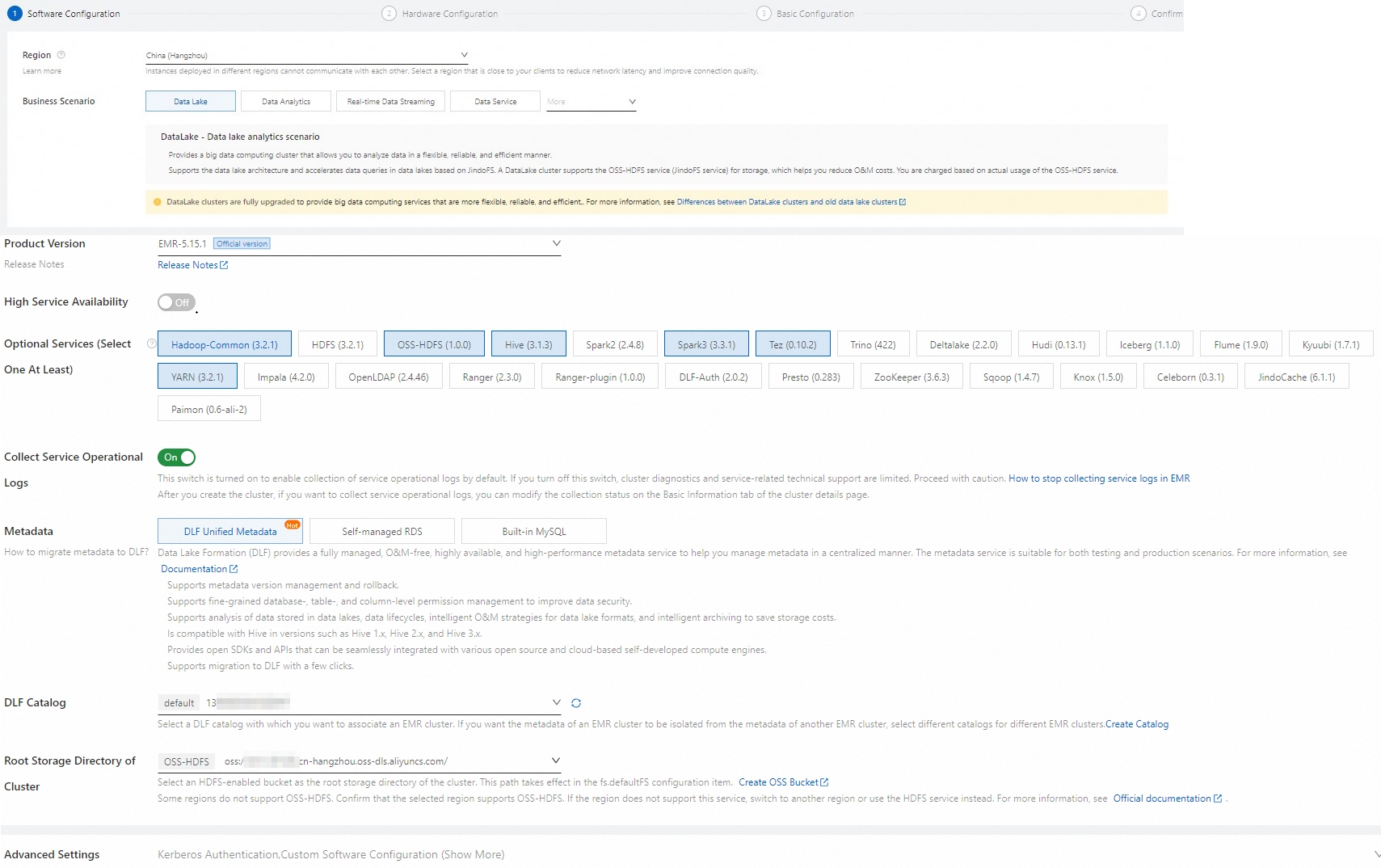
EMRクラスターを作成するときは、次のパラメーターに注意してください。 その他のパラメーターの詳細については、「クラスターの作成」をご参照ください。
カテゴリ
パラメーター
説明
ソフトウェア設定
ビジネスシナリオ
[新しいデータレイク] を選択します。
メタデータ
[DLF統合メタデータ] を選択します。
クラスタのルートストレージディレクトリ
OSS-HDFSが有効になっているバケットを選択します。
ハードウェア構成
ノードグループ
ノードグループを [パブリックネットワークIPの割り当て] に設定します。
最高のパフォーマンスを実現したい場合は、emr-coreノードにビッグデータまたはローカルSSDインスタンスタイプを選択することを推奨します。 少量のデータを使用してすべてのプロセスを短時間で完了する場合は、emrコアノード用に4つのvCPUと16 GiBのメモリを持つ汎用インスタンスタイプを選択することもできます。
重要使用するデータセットに基づいて、クラスターサイズを決定できます。 コアノードのデータディスクの合計容量がデータセットのサイズの3倍を超えていることを確認します。 データセットの詳細については、「手順3: データの生成と読み込み」をご参照ください。
SSHモードでemrクラスターのEMR-masterノードにログインします。 詳細については、「クラスターへのログイン」をご参照ください。
GitとMavenをインストールします。
次のコマンドを実行してGitをインストールします。
sudo yum install -y gitapache-maven-3.9.6-bin.tar.gzなどの最新バージョンのBinary tar.gzアーカイブパッケージをApache Mavenプロジェクトページからダウンロードします。
Binary tar.gzアーカイブパッケージをemrクラスターのEMR-masterノードにアップロードし、パッケージを解凍します。
tar zxf apache-maven-3.9.6-bin.tar.gz環境変数を設定します。
次のコマンドを実行して、apache-maven-3.9.6ディレクトリに切り替えます。
cd apache-maven-3.9.6次のコマンドを実行して環境変数を設定します。
export MAVEN_HOME='pwd' export PATH='pwd'/bin:$PATH
Hive TPC-DSベンチマークテストツールをダウンロードします。
次のいずれかの方法を使用して、Hive TPC-DSベンチマークテストツールをダウンロードします。
GitHubからツールをダウンロードする
中国本土のリージョンにあるノードで次のコマンドを実行すると、ダウンロードが遅くなることがあります。 ダウンロードが失敗した場合は、別の方法を使用できます。
git clone https://github.com/hortonworks/hive-testbench.githive-testbench-hdp3.zipのパッケージをローカルコンピューターにダウンロードします。
ZIPパッケージをemrクラスターのEMR-masterノードにアップロードします。
次のコマンドを実行して、emrクラスターのEMR-masterノードでアップロードされたZIPパッケージを解凍します。
unzip hive-testbench-hdp3.zip
ステップ2: データジェネレータのコンパイルとパッケージ化
オプションです。 Alibaba Cloudイメージを設定します。
Alibaba Cloudが提供するイメージを使用して、中国本土のリージョンでMavenのコンパイルを高速化できます。 画像が使用される場合、データジェネレータは2〜3分でコンパイルおよびパッケージ化できます。
次のコマンドを実行してディレクトリを作成します。
mkdir -p〜 /.m2/次のコマンドを実行して、Mavenの構成ファイルを新しいディレクトリにコピーします。
cp $MAVEN_HOME/conf/settings.xml ~/.m2/~/.m2/settings.xmlファイルに次の画像情報を追加します。
<ミラー> <id>aliyun</id> <mirrorOf>central</mirrorOf> <name>Nexus aliyun</name> <url>http://maven.aliyun.com/nexus/content/groups/public</url> </mirror>
hive-testbench-hdp3ディレクトリに切り替えます。
cd hive-testbench-hdp3tpcds-extern.patchファイルをダウンロードし、現在のディレクトリにアップロードしてから、
tpcds-gen/patches/all/ディレクトリにコピーします。cp tpcds-extern.patch。/tpcds-gen/patches/all/TPC-DSのツールセットを使用して、データジェネレーターをコンパイルおよびパッケージ化します。
. /tpcds-build.sh
ステップ3: データの生成とロード
スケールファクタ (SF) を指定します。
SFは、データセットのサイズを指定するために使用される。 サイズはGB単位で測定されます。 例えば、SF=1は1 GBのデータセットを示し、SF=100は100 GBのデータセットを示し、SF=1000は1テラバイトのデータセットを示す。 この例では、小さいデータセットが使用され、SFは3に設定される。 Command:
SF=3重要コアノードのデータディスクの合計容量がデータセットのサイズの3倍を超えていることを確認します。 それ以外の場合、後続の操作でエラーが報告されます。
使用するHiveデータベースを確認してクリーンアップします。
使用するHiveデータベースが存在するかどうかを確認します。
hive -e "desc database tpcds_bin_partitioned_orc_$SF"オプションです。 データベースが存在する場合は、データベースをクリーンアップします。
重要tpcds_bin_partitioned_orc_$SFデータベースが存在する場合は、次のコマンドを実行してデータベースをクリーンアップする必要があります。 それ以外の場合、後続の操作でエラーが報告されます。 データベースが存在しない場合は、この手順をスキップします。
hive -e "ドロップデータベースtpcds_bin_partitioned_orc_$SFカスケード"
HiveサービスのURLを設定します。
tpcds-setup.shスクリプトファイルで設定されているデフォルトのHiveサービスURLが、EMRクラスターで設定されているHiveサービスURLと一致していません。 次のコマンドを実行して、デフォルトのHiveサービスURLをEMRクラスターで設定されたHiveサービスURLに置き換えます。
sed -iの /localhost:2181\/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2?tez.queue.name=default/master-1-1:10000\// 'tpcds-setup.shスクリプトファイルのデフォルトのHiveサービスURLは、
jdbc:hive2:// localhost:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2?tez.queue.name=defaultです。 上記のコマンドを実行すると、HiveサービスのURLがjdbc:hive2:// master-1-1:10000/に変更されます。Hive TPC-DSベンチマークテストツールの構成の問題を修正しました。
一部のパラメータは、Hive 2やHive 3などの特定のバージョンのオープンソースHiveでサポートされていません。 Hive 2またはHive 3で引き続きTPC-DSを使用すると、ジョブに対してエラーが報告されることがあります。 サポートされていないパラメーターを置き換えるには、次のコマンドを実行する必要があります。
sed -i 's/hive.optimize.sort.dynamic.partition.threshold=0/hive.optimize.sort.dynamic.partition=true/'settings/*.sqlデータを生成してロードします。
SFが3に設定される場合、データは約40〜50分で生成され、ロードされることができる。 この手順が成功すると、生成されたTPC-DSデータテーブルがtpcds_bin_partitioned_orc_$SFデータベースにロードされます。 生成されたデータは、EMRクラスターの作成時に指定したルートストレージパス (OSS-HDFSが有効になっているバケットのルートディレクトリ) に自動的に保存されます。 次のコマンドを実行してデータをロードします。
. /tpcds-setup.sh $SFHiveテーブル統計を取得します。
Hiveテーブルの統計情報を取得するには、Hive SQL ANALYZEコマンドを使用することを推奨します。 これにより、後続のSQLクエリを高速化できます。 SFが3に設定されている場合、Hiveテーブル統計は約20〜30分で取得できます。
ハイブ-f。/hive-testbench-hdp3/ddl-tpcds/bin_partitioned/analyze.sql \ -- hiveconf hive.exe cution.engine=tez \ -- データベースtpcds_bin_partitioned_orc_$SF
ステップ4: TPC-DS SQL文を実行する
HiveまたはSparkを使用して、TPC-DSのSQL文を実行できます。
Hiveを使用したTPC-DS SQL文の実行
単一のSQL文を実行します。
TPC-DSには、query10.sqlやquery11.sqlなど、合計99のSQLファイルがあります。 すべてのファイルはsample-queries-tpcdsディレクトリに配置されます。 SFが3に設定されている場合、すべてのTPC-DS SQL文は5分以内に出力を返すことができます。
重要TPC-DSクエリとTPC-DSデータはランダムに生成されます。 したがって、一部のSQL文はレコードを返さない場合があります。
cd sample-queries-tpcds hive -- データベースtpcds_bin_partitioned_orc_$SF hive.exe cution.engine=tezを設定します。ソースquery10.sql;TPC-DSのツールセットで提供されているスクリプトファイルを使用して、99のSQL文をすべて順番に実行します。 例:
cd ~/hive-testbench-hdp3 # Hive構成ファイルを生成し、Hive実行エンジンをTezに設定します。 echo 'set hive.exe cution.engine=tez;' > sample-queries-tpcds/testbench.settings . /runSuite.pl tpcds $SF

Sparkを使用したTPC-DS SQL文の実行
TPC-DSのツールセットは、Spark-queries-tpcdsディレクトリにいくつかのサンプルspark SQL文を提供します。 Spark SQLやSpark Beelineなどのコマンドラインツールを使用して、サンプルステートメントを実行できます。 このステップでは、Spark Thrift Serverに接続されているSpark Beelineをこの例で使用します。 この例では、TPC-DS SQL文を実行して、手順3で生成されたTPC-DSデータセットを照会する方法を示します。
EMR Sparkを使用すると、HDFSやOSSなどの複数のストレージメディアにテーブルを保存でき、DLFにメタデータを保存できます。
Spark Beeline ANALYZEコマンドを実行して、Hiveテーブル統計を取得します。 これにより、後続のSQLクエリを高速化できます。
cd ~/hive-testbench-hdp3 spark-beeline -u jdbc:hive2:// master-1-1:10001/tpcds_bin_partitioned_orc_$SF \ -fだ /ddl-tpcds/bin_partitioned/analyze.sqlサンプルSpark SQL文が配置されているディレクトリに切り替えます。
cd spark-queries-tpcds/単一のSQL文を実行します。
spark-beeline -u jdbc:hive2:// master-1-1:10001/tpcds_bin_partitioned_orc_$SF -f q1.sql99のSQL文をすべて順番に実行します。
TPC-DSのツールセットには、一度にすべてのSpark SQL文を実行するために使用できるスクリプトファイルは含まれていません。 参照には、次の簡単なスクリプトを使用できます。
'ls *.sql' でqを
します。 spark-beeline -u jdbc:hive2:// master-1-1:10001/tpcds_bin_partitioned_orc_$SF -f $q > $q.out 完了重要q30.sqlファイルでは、列名c_last_review_date_skが誤ってc_last_review_dateとして書き込まれます。 その結果、30番目のSQL文は失敗します。