FieldMatchWeighted は、クエリがインデックス内の特定のフィールドにどの程度一致するかをスコア化します。フィールド内で一致するクエリ用語が多いほど、スコアは高くなります。このクラスを使用して、OpenSearch Industry Algorithm Edition でカスタム関連性スコアラーを構築します。
仕組み
各 FieldMatchWeighted スコアは、次の2つのコンポーネントを組み合わせたものです。
baseScore — 用語頻度重み付けスコア。各 term (
tw) の重みはクエリ分析によって生成されます。デフォルトのtwは1です。bonusScore — クエリがフィールド値に完全に一致する場合、またはクエリがフィールド値の部分文字列である場合に適用される追加の重み付けスコア。
最終スコアは次のように計算されます。
score = (A × baseScore + bonusScore) / (A + 1)ここで、A は baseScore の bonusScore に対する重みです。次の図は、baseScore がどのように計算されるかを示しています。
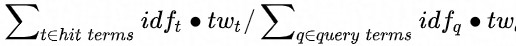
ボーナススコアの条件
bonusScore は、次の2つの異なる状況で適用されます。
| 条件 | トリガーされるタイミング | 制御元 |
|---|---|---|
| 完全に一致 | クエリがフィールド値全体と等しい場合 | setExactMatchBonus() |
| 部分文字列の一致 (ngram) | クエリがフィールド値内に現れる場合 | setNgramMatchBonus() |
例:
フィールド値:
"Apple iPhone 15 Pro"クエリ
"Apple iPhone 15 Pro"→ 完全に一致。exactMatchBonusが適用されます。クエリ
"iPhone 15 Pro"→ クエリがフィールドに含まれる。ngramMatchBonusが適用されます。
関数
注: すべての setter 関数 (setGroupScoreMergeOp、setParamA、setExactMatchBonus、setNgramMatchBonus) は、score()内ではなく、init()内で呼び出す必要があります。初期化後にこれらを呼び出しても効果はありません。
| 関数 | 説明 |
|---|---|
FieldMatchWeighted create(OpsScorerInitParams params, CString indexName, CString fieldName) | FieldMatchWeighted オブジェクトを作成します。 |
void setGroupScoreMergeOp(CString opName) | 複数のクエリグループからのスコアが集計される方法を設定します。サポートされている値: sum、max。デフォルト: sum。 |
void setParamA(double paramA) | 最終数式における変数 A ( baseScore の重み) を設定します。デフォルト: 0.5。 |
void setExactMatchBonus(double exactMatchBonus) | クエリがフィールドに完全に一致する場合に追加されるボーナススコアを設定します。デフォルト: 1.0。 |
void setNgramMatchBonus(double ngramMatchBonus) | クエリがフィールド値内に含まれる場合 (部分文字列の一致) に追加されるボーナススコアを設定します。デフォルト: 0.6。 |
double evaluate(OpsScoreParams params) | クエリとフィールド間の関連性スコアを返します。有効範囲: [0, 1]。 |
関数の詳細
create()
FieldMatchWeighted create(OpsScorerInitParams params, CString indexName, CString fieldName)特定のインデックスとフィールドにバインドされた FieldMatchWeighted オブジェクトを作成します。
| パラメーター | 型 | 説明 |
|---|---|---|
params | OpsScorerInitParams | 初期化パラメーター。OpsScorerInitParams をご参照ください。 |
indexName | CString | インデックス名。定数である必要があります。 |
fieldName | CString | インデックス内のフィールド名。定数である必要があります。TEXT または SHORT_TEXT 型である必要があります。 |
ターゲットフィールドでサポートされているアナライザ: 汎用中国語アナライザ、カスタムアナライザ、単一文字中国語アナライザ、英語アナライザ、あいまい検索アナライザ。
setGroupScoreMergeOp()
void setGroupScoreMergeOp(CString opName)複数のクエリグループ間で FieldMatchWeighted スコアが集計される方法を設定します。クエリグループは、アナライザが元のクエリを個別のセグメントに分割するときに生成されます。デフォルトでは、単一のクエリグループが存在します。
| パラメーター | サポートされている値 | デフォルト |
|---|---|---|
opName | "sum"、"max" | "sum" |
setParamA()
void setParamA(double paramA)スコアリング数式 (A × baseScore + bonusScore) / (A + 1) の変数 A を設定します。値が高いほど、bonusScore と比較して baseScore に与えられる重みが大きくなります。
| パラメーター | デフォルト |
|---|---|
paramA | 0.5 |
setExactMatchBonus()
void setExactMatchBonus(double exactMatchBonus)クエリが完全なフィールド値に完全に一致する場合に追加されるボーナススコアを設定します。
| パラメーター | デフォルト |
|---|---|
exactMatchBonus | 1.0 |
setNgramMatchBonus()
void setNgramMatchBonus(double ngramMatchBonus)クエリがフィールド値内に含まれる場合 (部分文字列の一致) に追加されるボーナススコアを設定します。
| パラメーター | デフォルト |
|---|---|
ngramMatchBonus | 0.6 |
evaluate()
double evaluate(OpsScoreParams params)設定されたフィールドに対するクエリの関連性を計算します。
| パラメーター | 型 | 説明 |
|---|---|---|
params | OpsScoreParams | スコア計算パラメーター。OpsScoreParams をご参照ください。 |
double 型の値を [0, 1] の範囲で返します。
例
次の例は、title_index インデックスの title フィールドに対する FieldMatchWeighted スコアラーを作成します。すべての setter 呼び出しは init() 内で行われ、score() は evaluate() のみを呼び出します。
package users.scorer;
import com.aliyun.opensearch.cava.framework.OpsScoreParams;
import com.aliyun.opensearch.cava.framework.OpsScorerInitParams;
import com.aliyun.opensearch.cava.features.similarity.fieldmatch.FieldMatchWeighted;
class BasicSimilarityScorer {
FieldMatchWeighted _f1;
boolean init(OpsScorerInitParams params) {
// 必須: 特定のインデックスとフィールドにバインドします
_f1 = FieldMatchWeighted.create(params, "title_index", "title");
// オプション: クエリグループ全体で合計する代わりに、最高のスコアを使用します
_f1.setGroupScoreMergeOp("max"); // デフォルト: "sum"
// オプション: bonusScore と比較して baseScore に完全な重み (A=1) を与えます
_f1.setParamA(1); // デフォルト: 0.5
// オプション: 一致条件のボーナススコアを調整します
_f1.setExactMatchBonus(0.5); // デフォルト: 1.0
_f1.setNgramMatchBonus(0.3); // デフォルト: 0.6
return true;
}
double score(OpsScoreParams params) {
return _f1.evaluate(params);
}
}