オープンソースの XXL-JOB をベースとした自己管理型タスクスケジューリングシステムを使用するアプリケーションでは、複雑なタスク設定、低い実行効率、困難な監視と管理といった課題に直面する可能性があります。Alibaba Cloud は、スケジュールされたタスクのスケジューリングとタスクシャーディングをサポートするオープンソースソリューションを提供し、自己管理のスケジュールされたタスクをタスクスケジューリングプラットフォームへ迅速に接続できるよう支援します。
前提条件
-
XXL-JOB に必要な RAM 権限を RAM ユーザーに追加します。詳細については、「SchedulerX で XXL-JOB を承認する」をご参照ください。
-
XXL-JOB インスタンスを作成します。詳細については、「インスタンスの作成」をご参照ください。
ソリューション概要
このソリューションでは、SDK を使用して Java、Go、または Python アプリケーションを MSE-XXLJOB に接続し、スケジュールされたタスクをスケジューリングして実行する方法について説明します。
スケジュールされたタスクのロジックをコードに実装し、Bean ラベル付きタスクコンポーネントとして公開します。コンソールで Bean 名を設定することで、対応するタスクロジックをトリガーします。
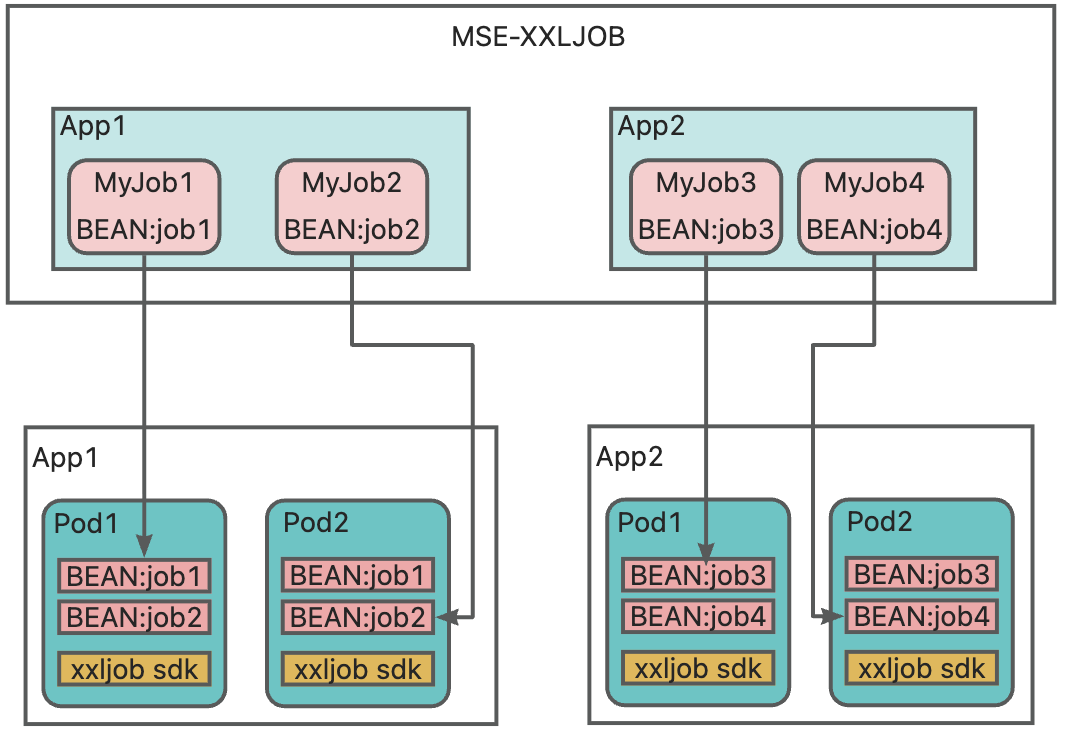
このソリューションには、以下のステップが含まれます。
-
アプリケーションの作成:スケジュールされたタスクを一元管理することで、表示、設定、スケジューリングを簡素化し、運用効率を向上させます。
-
アプリケーションの開発とデプロイ:スケジュールされたタスクコードを記述し、Docker イメージをビルドして Alibaba Cloud イメージリポジトリにアップロードすることで、コンテナによる管理とデプロイが可能になります。
-
テストと検証:接続されたアプリケーションが XXL-JOB プラットフォーム上で自動的にスケジューリングおよび管理され、タスクが正確かつ時間通りに実行されることを確認します。
ステップ 1:アプリケーションの作成
-
MSE XXL-JOB コンソールにログインし、上部メニューからリージョンを選択します。
-
対象のインスタンスをクリックして詳細ページに移動します。左側のナビゲーションペインで を選択し、Create Application をクリックします。[AppName] と 名前 を入力し、システムが生成した [AccessToken] を使用して、OK をクリックします。
ステップ 2:アプリケーションの開発とデプロイ
1. XXL-JOB タスクの開発
XXL-JOB は、Java、Go、Python で記述されたアプリケーションをサポートしています。詳細については、オープンソースの XXL-JOB デモプロジェクトをご参照ください。
Java
-
pom.xml ファイルに
xxl-job-coreの Maven 依存関係を追加します。バージョンの詳細については、xxl-job-executor-sample-springboot をご参照ください。<!-- xxl-job-core --> <dependency> <groupId>com.xuxueli</groupId> <artifactId>xxl-job-core</artifactId> <version>2.2.x</version> </dependency> -
エグゼキュータを初期化します。
@Configuration public class XxlJobConfig { private Logger logger = LoggerFactory.getLogger(XxlJobConfig.class); @Value("${xxl.job.admin.addresses}") private String adminAddresses; @Value("${xxl.job.accessToken}") private String accessToken; @Value("${xxl.job.executor.appname}") private String appname; @Value("${xxl.job.executor.address}") private String address; @Value("${xxl.job.executor.ip}") private String ip; @Value("${xxl.job.executor.port}") private int port; @Value("${xxl.job.executor.logpath}") private String logPath; @Value("${xxl.job.executor.logretentiondays}") private int logRetentionDays; @Bean public XxlJobSpringExecutor xxlJobExecutor() { logger.info(">>>>>>>>>>> xxl-job config init."); XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor(); xxlJobSpringExecutor.setAdminAddresses(adminAddresses); xxlJobSpringExecutor.setAppname(appname); xxlJobSpringExecutor.setAddress(address); xxlJobSpringExecutor.setIp(ip); xxlJobSpringExecutor.setPort(port); xxlJobSpringExecutor.setAccessToken(accessToken); xxlJobSpringExecutor.setLogPath(logPath); xxlJobSpringExecutor.setLogRetentionDays(logRetentionDays); return xxlJobSpringExecutor; } } -
タスク実行コードを記述します (バージョン 2.2.x を例とします)。
説明インターフェイスは XXL-JOB のバージョンによって異なります。詳細については、オープンソースのデモプロジェクトをご参照ください。
@Component public class SampleXxlJob { private static Logger logger = LoggerFactory.getLogger(SampleXxlJob.class); @XxlJob("helloworld") public ReturnT<String> helloworld(String param) throws Exception { XxlJobLogger.log("XXL-JOB, Hello World, start..."); for (int i = 0; i < 5; i++) { XxlJobLogger.log("beat at:" + i); TimeUnit.SECONDS.sleep(2); } System.out.println("XXL-JOB, Hello World, finished"); return ReturnT.SUCCESS; } }
Golang
-
次のコマンドを実行して、XXL-JOB の Go SDK の最新タグバージョンをプルします。バージョンの詳細については、xxl-job-executor-go をご参照ください。
go get github.com/xxl-job/xxl-job-executor-go@{latest tag} -
エグゼキュータ初期化コードを記述します。
package main import ( "context" "fmt" xxl "github.com/xxl-job/xxl-job-executor-go" "github.com/xxl-job/xxl-job-executor-go/example/task" "log" ) func main() { exec := xxl.NewExecutor( xxl.ServerAddr("xxxxxx"), // リクエスト URL。コンソールの [Application Management] > [Access Configuration] から取得します xxl.AccessToken("xxxxxxx"), // アクセストークン。コンソールの [Application Management] > [Access Configuration] から取得します xxl.ExecutorPort("9999"), // デフォルトは 9999 (オプション) xxl.RegistryKey("golang-jobs"), // エグゼキュータ名 xxl.SetLogger(&logger{}), // カスタムロガー ) exec.Init() exec.Use(customMiddleware) // ログ表示ハンドラを設定します exec.LogHandler(customLogHandle) // タスクハンドラを登録します exec.RegTask("task.test", task.Test) exec.RegTask("task.shardingTest", task.ShardingTest) log.Fatal(exec.Run()) } // カスタムログハンドラ func customLogHandle(req *xxl.LogReq) *xxl.LogRes { return &xxl.LogRes{Code: xxl.SuccessCode, Msg: "", Content: xxl.LogResContent{ FromLineNum: req.FromLineNum, ToLineNum: 2, LogContent: "This is a custom log handler", IsEnd: true, }} } // xxl.Logger インターフェイスを実装します type logger struct{} func (l *logger) Info(format string, a ...interface{}) { fmt.Println(fmt.Sprintf("Custom log - "+format, a...)) } func (l *logger) Error(format string, a ...interface{}) { log.Println(fmt.Sprintf("Custom log - "+format, a...)) } // カスタムミドルウェア func customMiddleware(tf xxl.TaskFunc) xxl.TaskFunc { return func(cxt context.Context, param *xxl.RunReq) string { log.Println("I am a middleware start") res := tf(cxt, param) log.Println("I am a middleware end") return res } } -
タスク実行コードを記述します。
package task import ( "context" "fmt" xxl "github.com/xxl-job/xxl-job-executor-go" ) func Test(cxt context.Context, param *xxl.RunReq) (msg string) { fmt.Println("test one task" + param.ExecutorHandler + " param: " + param.ExecutorParams + " log_id:" + xxl.Int64ToStr(param.LogID)) return "test done" } func ShardingTest(cxt context.Context, param *xxl.RunReq) (msg string) { fmt.Println("shardingId:" + xxl.Int64ToStr(param.BroadcastIndex) + ", shardingTotal:" + xxl.Int64ToStr(param.BroadcastTotal)) return "ShardingTest done" }
Python
-
依存関係をインストールします。バージョンの詳細については、xxl-job-executor-python をご参照ください。
pip install pyxxl # ログを Redis に書き込む必要がある場合 pip install "pyxxl[redis]" # .env から設定を読み込む場合 pip install "pyxxl[dotenv]" # すべての機能をインストールする場合 pip install "pyxxl[all]" -
タスク実行コードを記述します。
import asyncio import time from pyxxl import ExecutorConfig, PyxxlRunner from pyxxl.ctx import g config = ExecutorConfig( xxl_admin_baseurl="http://xxljob-1b3fd81****.schedulerx.mse.aliyuncs.com/api/", executor_app_name="xueren-test", access_token="default_token", # executor_listen_host="0.0.0.0", # xxl-admin がエグゼキュータの IP に直接接続できる場合は省略可能です ) app = PyxxlRunner(config) @app.register(name="demoJobHandler") async def test_task(): # "g" を使用してタスクパラメータを取得できます g.logger.info("get executor params: %s" % g.xxl_run_data.executorParams) for i in range(10): g.logger.warning("test logger %s" % i) await asyncio.sleep(5) return "Success..." @app.register(name="sync_func") def test_task4(): # xxl-admin で実行ログを表示するには、常に g.logger を使用します (デフォルトでは info レベル以上が記録されます) n = 1 g.logger.info("Job %s get executor params: %s" % (g.xxl_run_data.jobId, g.xxl_run_data.executorParams)) # ループを含む同期タスクでは、各反復で g.cancel_event をチェックしてキャンセルに対応します while n <= 10 and not g.cancel_event.is_set(): # ログを xxl-admin に表示する必要がない場合は、独自のロガーを使用します g.logger.info( "log to {} logger test_task4.{},params:{}".format( g.xxl_run_data.jobId, n, g.xxl_run_data.executorParams, ) ) time.sleep(2) n += 1 return "Success3" if __name__ == "__main__": app.run_executor()
2. Alibaba Cloud へのアプリケーションのデプロイ
Alibaba Cloud XXL-JOB は Alibaba Cloud ネットワークのみをサポートします。アプリケーションを Alibaba Cloud にデプロイする必要があります。次の例では、Java アプリケーションを Container Service for Kubernetes にデプロイする方法を示します。
Container Service クラスターは、SchedulerX XXL-JOB クラスターと同じ VPC 内に存在する必要があります。
-
Spring Boot アプリケーションのルートディレクトリに Dockerfile を作成します。
# 独自のベースイメージに置き換えてください FROM reg.docker.alibaba-inc.com/xxx/xxxx-java:1.0-beta MAINTAINER xueren ENV JAVA_OPTS="" ADD target/xxl-job-executor-sample-springboot-*.jar /app.jar ENTRYPOINT ["sh","-c","java -jar $JAVA_OPTS /app.jar] -
Docker を使用してイメージをビルドし、Alibaba Cloud イメージリポジトリにプッシュします。
docker login --username=xxx@aliyun.com registry.cn-hangzhou.aliyuncs.com --password=xxxxxx docker buildx build --platform linux/amd64 -t schedulerx-registry.cn-hangzhou.cr.aliyuncs.com/schedulerx3/xxljob-demo:2.4.1 . docker push schedulerx-registry.cn-hangzhou.cr.aliyuncs.com/schedulerx3/xxljob-demo:2.4.1 -
左側のナビゲーションペインで、 ページに移動し、対象のアプリケーションの [Actions] 列の [Access Configuration] をクリックします。
-
Alibaba Cloud Container Service にログインし、対象のクラスターに移動します。左側のナビゲーションペインで、 を選択し、右上隅の [Create Resource Using YAML] をクリックして Deployment を作成します。次の例では、アクセス方法 2 (-D パラメータを使用したアプリケーションの再起動) を使用します。YAML 内の JAVA_OPTS 値を置き換えて、環境変数経由で JVM パラメータを注入します。
apiVersion: apps/v1 kind: Deployment metadata: name: xxljob-xueren-test labels: app: xxljob-xueren-test spec: replicas: 2 selector: matchLabels: app: xxljob-xueren-test template: metadata: labels: app: xxljob-xueren-test spec: containers: - name: xxljob-executor image: schedulerx-registry.cn-hangzhou.cr.aliyuncs.com/schedulerx3/xxljob-demo:2.4.1 ports: - containerPort: 9999 env: - name: JAVA_OPTS value: >- -Dxxl.job.admin.addresses=http://xxljob-xxxxx.schedulerx.mse.aliyuncs.com -Dxxl.job.executor.appname=xueren_test -Dxxl.job.accessToken=xxxxxxx
ステップ 3:テストと検証
1. エグゼキュータ接続の検証
インスタンス詳細ページに移動し、左側のナビゲーションペインで [Application Management] をクリックし、対象のアプリケーションのエグゼキュータ数をクリックすると、接続されたエグゼキュータアドレスとオンラインステータスが表示されます。
2. タスクのテストと検証
単一ノードタスクテスト
単一ノードタスクは、実行ごとに、ルーティングポリシーに基づいてアプリケーションのすべてのエグゼキュータから選択された 1 つのエグゼキュータで 1 回実行されます。
-
左側のナビゲーションペインで [Task Management] を選択し、Add Task をクリックします。Task Name と jobHandler 名を入力し、[Associated Application] で対象のアプリケーションを選択し、[Routing Policy] で [Round Robin] を選択して、Next をクリックします。
[Task Type] を [BEAN] に、[Blocking Handling Policy] を [Serial Execution on Single Node] に、[Priority] を [Medium] に設定します。
-
[Scheduling Settings] を設定します。[Time Type] で cron を選択し、[Use Generator] をクリックして cron 式を生成します。この例では、毎日 12:00 に 1 回実行されます。Next をクリックします。
cron 式フィールドに
0 0 12 * * ?を入力します。 -
[Notifications] を設定します。タイムアウトアラート、成功通知、失敗アラート、通知方法、通知受信者を設定できます。この例では、コンソールのデフォルト設定を使用します。
-
作成後、タスクの [Actions] 列の [Run Once] をクリックします。手動実行ダイアログで、[Target Machine] を指定し、[Instance Parameters] を設定して、OK をクリックします。
-
をクリックして、タスク実行レコードを表示します。
実行一覧には、[Execution ID]、[Task ID/Name]、[Application]、[Start Time]、[End Time]、[Status]、[Actions] を含むタスクレコードが表示されます。[Success] ステータスのレコードについては、[Details] と [Logs] を表示できます。[Failed] ステータスのレコードでは、[Rerun] も実行できます。
-
左側のナビゲーションペインで [Execution List] をクリックし、対象の実行レコードの ログ 列の ログ をクリックすると、タスク実行ログが表示されます。
2024-08-21 12:00:00 [com.xxl.job.core.thread.JobThread#run]-[124]-[Thread-10] ----------- xxl-job job execute start ----------- ----------- Param:123456 2024-08-21 12:00:00 [com.xxl.job.executor.service.jobhandler.SampleXxlJob#helloworld]-[38]-[Thread-10] XXL-JOB, Hello World, start... 2024-08-21 12:00:00 [com.xxl.job.executor.service.jobhandler.SampleXxlJob#helloworld]-[40]-[Thread-10] beat at:0 2024-08-21 12:00:02 [com.xxl.job.executor.service.jobhandler.SampleXxlJob#helloworld]-[40]-[Thread-10] beat at:1 2024-08-21 12:00:04 [com.xxl.job.executor.service.jobhandler.SampleXxlJob#helloworld]-[40]-[Thread-10] beat at:2 2024-08-21 12:00:06 [com.xxl.job.executor.service.jobhandler.SampleXxlJob#helloworld]-[40]-[Thread-10] beat at:3 2024-08-21 12:00:08 [com.xxl.job.executor.service.jobhandler.SampleXxlJob#helloworld]-[40]-[Thread-10] beat at:4 2024-08-21 12:00:10 [com.xxl.job.core.thread.JobThread#run]-[164]-[Thread-10] ----------- xxl-job job execute end(finish) ----------- ----------- ReturnT:ReturnT [code=200, msg=null, content=null] 2024-08-21 12:00:10 [com.xxl.job.core.thread.TriggerCallbackThread#callbackLog]-[191]-[xxl-job, executor TriggerCallbackThread] ----------- xxl-job job callback finish.
シャーディングブロードキャストタスクテスト
シャーディングブロードキャストタスクは、実行ごとにアプリケーションのすべてのエグゼキュータで実行されます。各エグゼキュータは一意のシャード番号を受け取り、分散バッチ処理が可能になります。オープンソースの XXL-JOB にはシャーディングブロードキャストの集約機能がありませんが、Alibaba Cloud XXL-JOB は各実行のすべてのシャード結果を集約して表示します。
-
左側のナビゲーションペインで [Task Management] を選択し、Add Task をクリックします。Task Name と jobHandler 名を入力し、[Associated Application] で対象のアプリケーションを選択し、[Routing Policy] で [Sharded Broadcast] を選択して、Next をクリックします。
-
[Scheduling Settings] を設定します。[Time Type] で cron を選択し、[Use Generator] をクリックして cron 式を生成します。この例では、毎時 10 分に 1 回実行されます。Next をクリックします。
cron 式フィールドに
0 10 * * * ?を入力します。 -
[Notifications] を設定します。タイムアウトアラート、成功通知、失敗アラート、通知方法、通知受信者を設定できます。この例では、コンソールのデフォルト設定を使用します。
-
作成後、タスクの [Actions] 列の [Run Once] をクリックします。手動実行ダイアログで、[Target Machine] を指定し、[Instance Parameters] を設定して、OK をクリックします。
-
をクリックして、タスク実行レコードを表示します。
-
左側のナビゲーションペインで [Execution List] をクリックします。タスク実行一覧ページで、対象の実行レコードの 詳細 列にある 詳細 をクリックします。[Shard Details] セクションに、各マシンの実行ステータスが集約されます。
実行結果には、全体の進行状況が 100% と表示され、両方のシャード (シャード 0 とシャード 1) が成功しています。
-
各シャードについて、ログ 列の ログ をクリックすると実行ログが表示されます。
2024-08-21 12:10:00 [INFO] Job execution start... 2024-08-21 12:10:00 [INFO] Task: task.shardingTest 2024-08-21 12:10:00 [INFO] Parameters: 2024-08-21 12:10:00 [INFO] shardingId:0, shardingTotal:2 2024-08-21 12:10:00 [INFO] Job execution finished. 2024-08-21 12:10:00 [INFO] Result: ShardingTest done