ワークフローは、複雑なタスクを順序付けされたステップに分解することでシステムの複雑さを軽減します。Alibaba Cloud Model Studio では、ワークフローを使用して大規模モデル、API、Function Compute などのノードを組み合わせることで、コーディングコストを削減できます。
コンソールの制限事項: 2025 年 4 月 21 日以前にアプリケーションを作成した国際版ユーザーのみが、次の図に示すように アプリケーション開発 タブにアクセスできます。
このタブには以下の機能が含まれます:アプリケーション(エージェントアプリケーションおよびワークフローアプリケーション)、コンポーネント(プロンプトエンジニアリングおよびプラグイン)、データ(ナレッジベースおよびアプリケーションデータ)。これらはすべてプレビュー機能です。本番環境での使用には十分ご注意ください。

API 呼び出しの制限事項: 2025 年 4 月 21 日以前にアプリケーションを作成した国際版ユーザーのみが、アプリケーションデータ、ナレッジベース、プロンプトエンジニアリング API を呼び出すことができます。
アプリケーション
ワークフローアプリケーションの利用理由
ワークフローは、複雑なタスクを一連のステップに分解することでシステムの複雑さを軽減します。Model Studio 上でワークフローアプリケーションを作成すると、実行順序を定義し、各ステップの責任を割り当て、依存関係を指定することでプロセスを自動化・最適化できます。
ワークフローアプリケーションの一般的なユースケースは以下のとおりです。
旅行計画:ワークフロープラグインを使用して目的地などのパラメーターを選択し、フライト、宿泊施設、観光スポットの推奨を含む旅行プランを自動生成できます。
レポート分析:複雑なデータセットに対して、データ処理、分析、可視化のプラグインを組み合わせて、構造化されフォーマットされた分析レポートを生成できます。
カスタマーサポート:自動化されたワークフローを使用して、問題分類を含む顧客問い合わせを処理し、応答速度と正確性を向上させることができます。
コンテンツ作成:記事やマーケティングコピーなどのコンテンツを生成できます。トピックと要件を提供すると、システムが自動的にドラフトを生成します。
教育・トレーニング:ワークフローを使用して進捗追跡と評価を含むパーソナライズされた学習プランを設計し、学生が自分のペースで学習できるようにします。
医療相談:患者が入力した症状に基づき、ワークフローが複数の分析ツールを組み合わせて初期評価を生成するか、関連検査を推奨し、医師のさらなる診断を支援します。
例
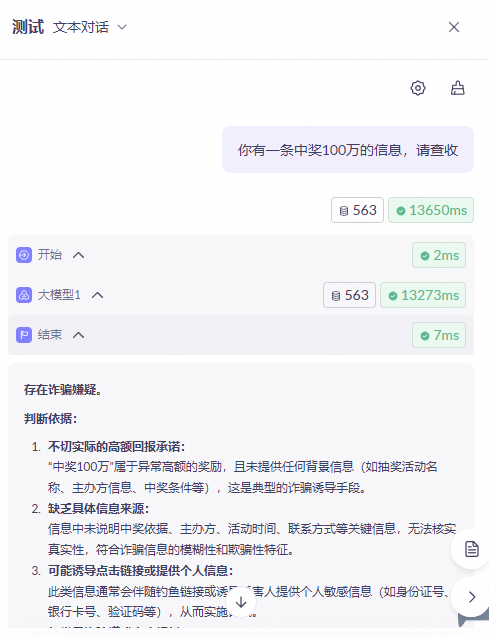
例 1:詐欺メッセージの検出
この例では、テキストメッセージが潜在的な詐欺かどうかを判断するワークフローアプリケーションの作成方法を示します。このワークフローは、開始ノード、大規模モデルノード、終了ノードを使用します。
| |
|
|
|
構成例:
|
|
|
|
|



 をクリックします。ワークフローの実行が完了したら、出力を確認します。
をクリックします。ワークフローの実行が完了したら、出力を確認します。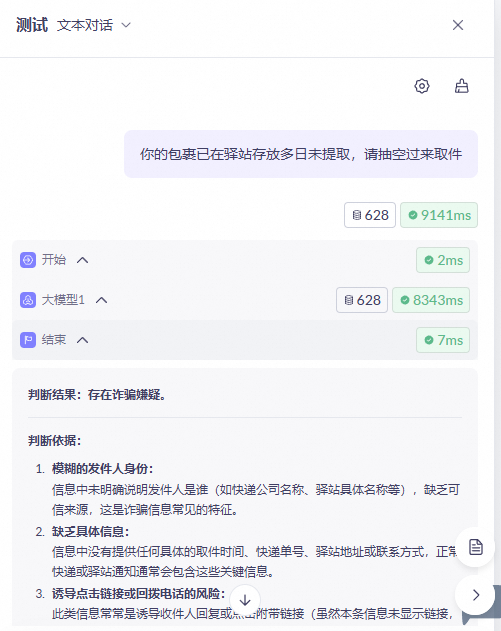
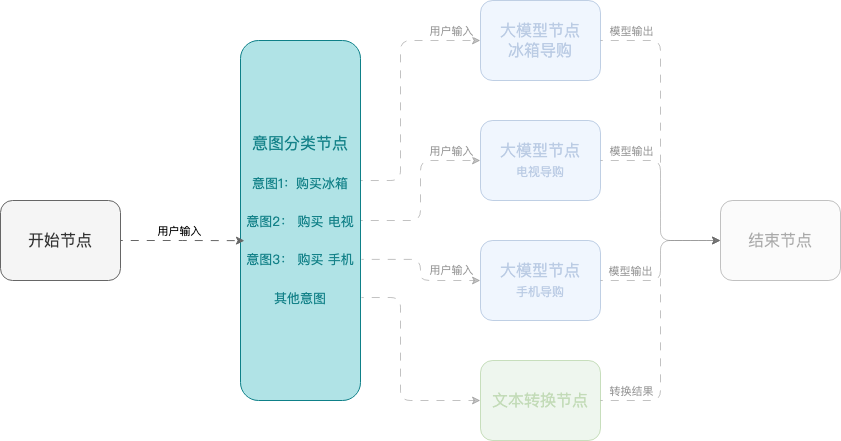
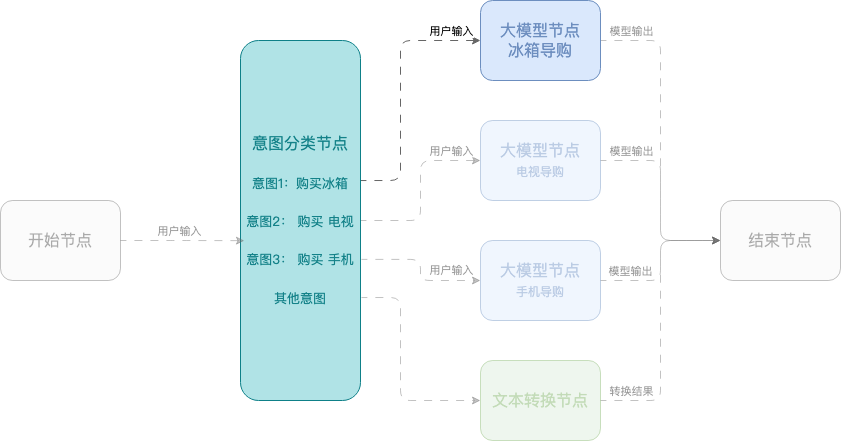
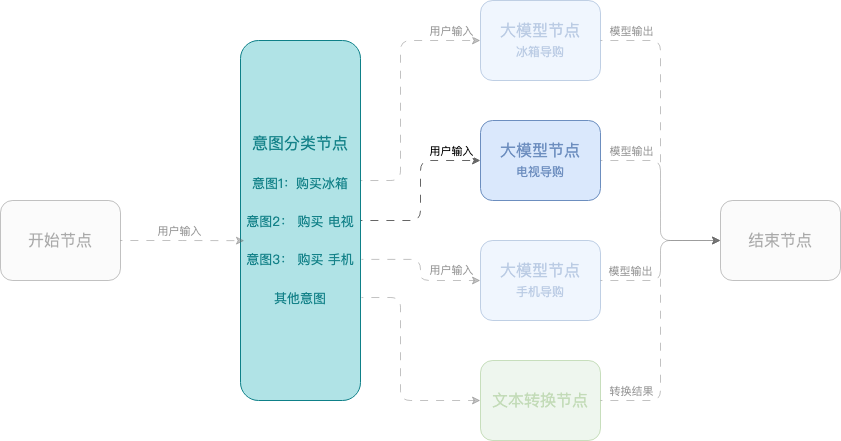
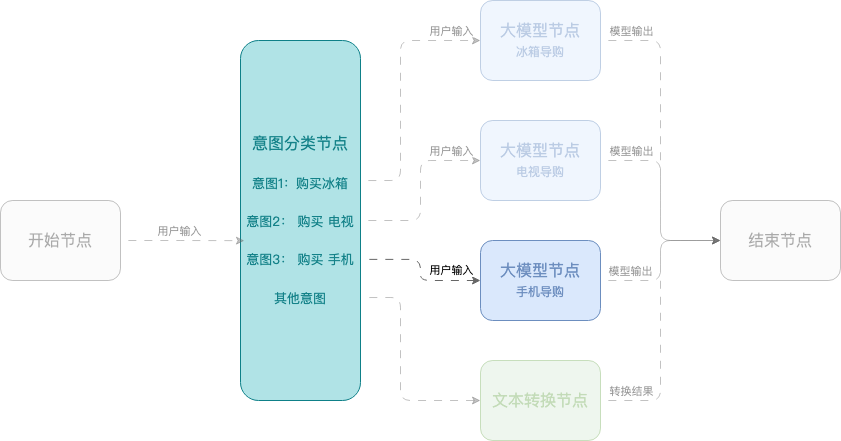
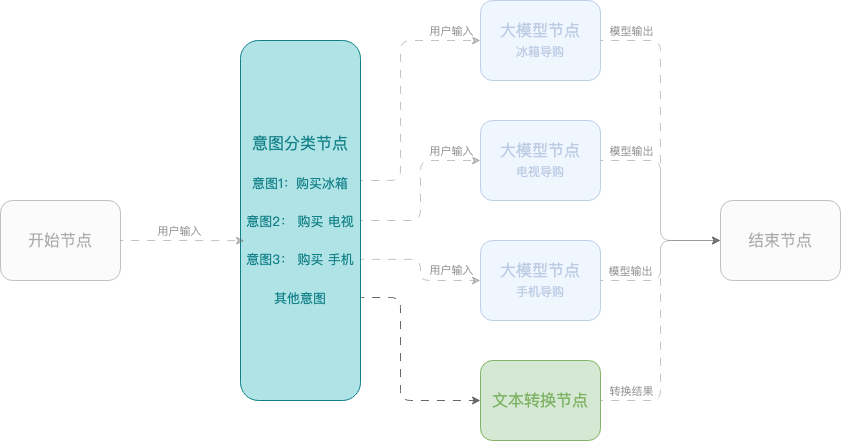
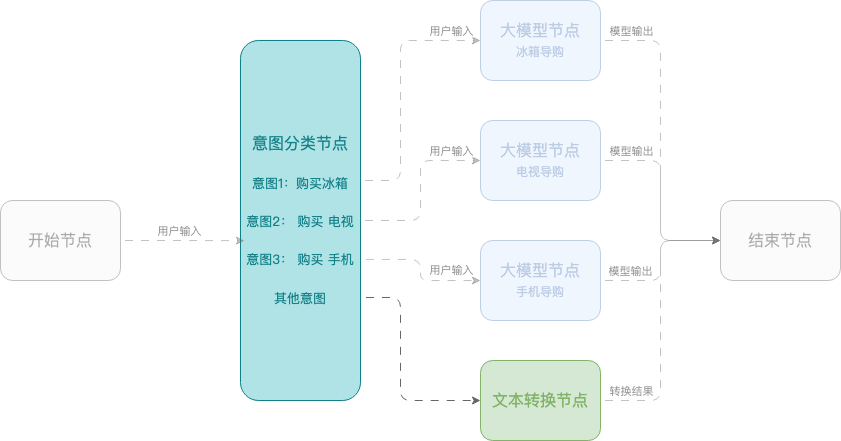
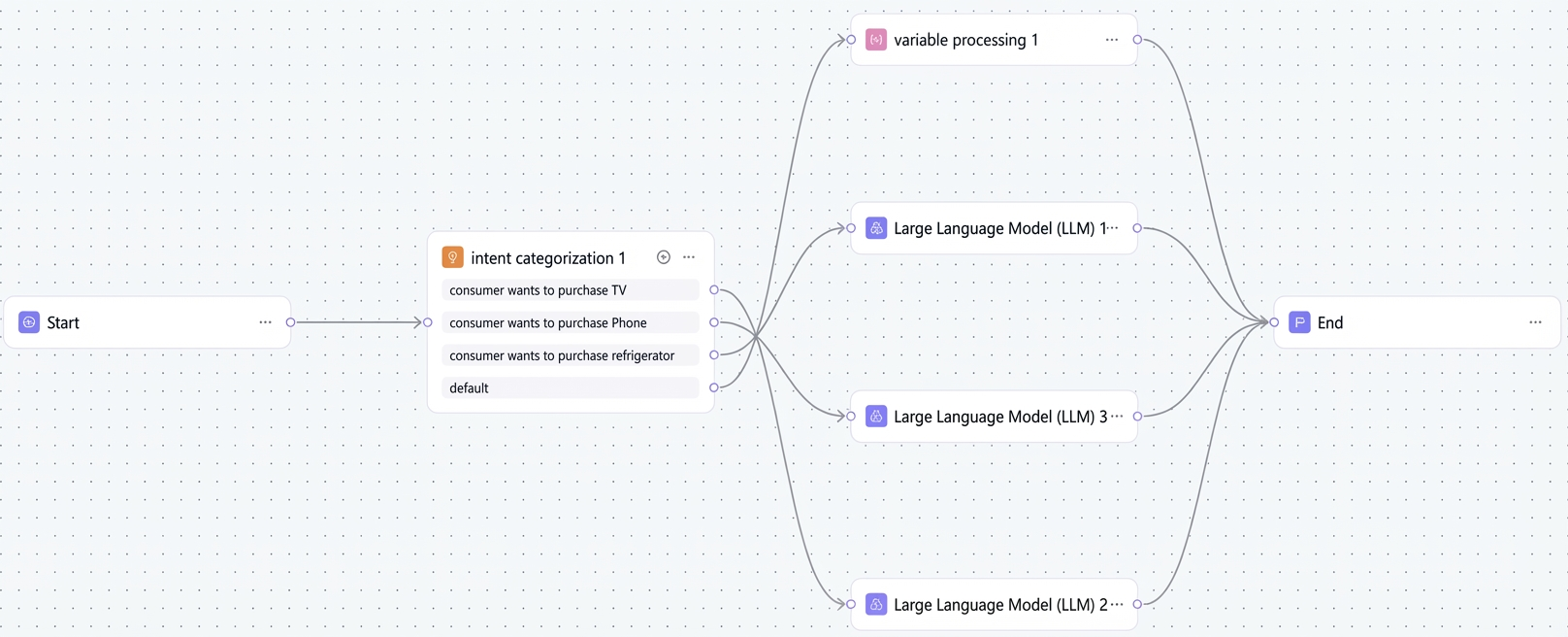
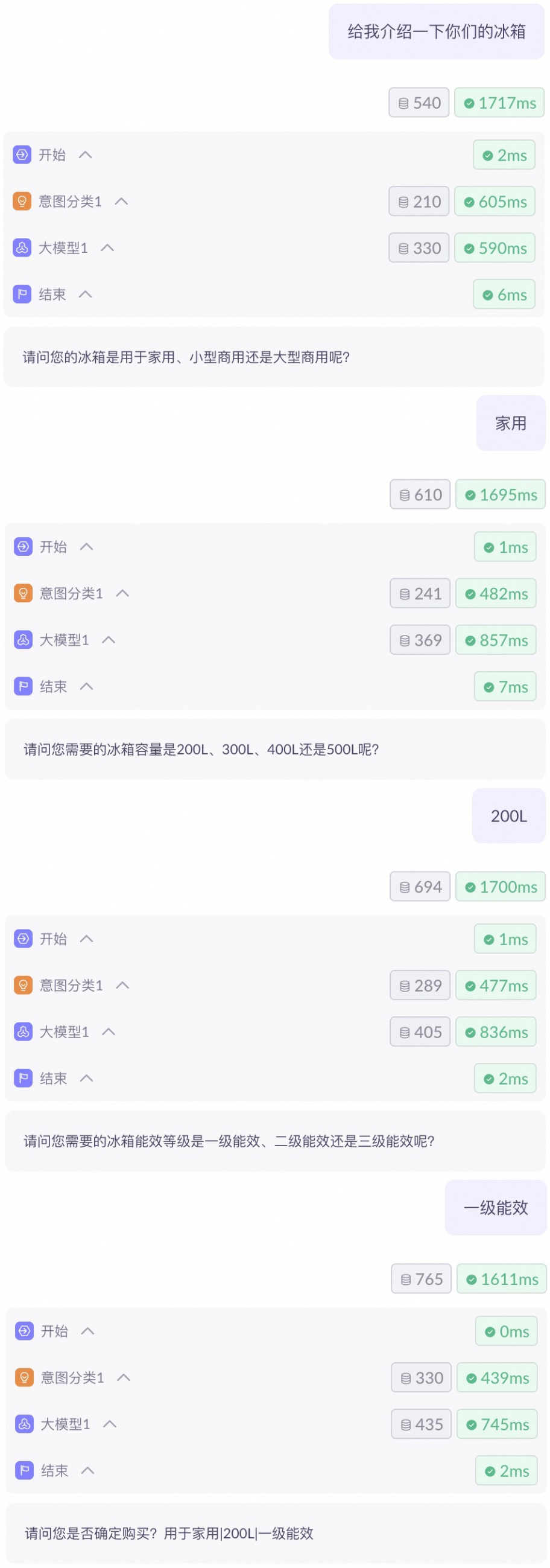
例 2:スマートショッピングアシスタント
この例では、モバイル端末、テレビ、冷蔵庫の選択をユーザーに支援するワークフローを使用したスマートショッピングアシスタントの作成方法を示します。このワークフローは、開始ノード、意図分類ノード、大規模モデルノード、終了ノードを使用します。
| |
|
|
|
|
|
|
|
|
|
|
|
構成例:
|
|
|
セッションパラメーター
セッション変数はグローバル変数として機能し、ワークフローのライフサイクル全体を通してパラメーターを保存し、任意のノードから参照できます。
キャンバス設定ページの右上隅にある  アイコンをクリックします。
アイコンをクリックします。

ノード
ノードはワークフローアプリケーションのコア機能ユニットです。各ノードは特定のタスク(アクションの実行、条件のトリガー、データの処理、ワークフローの制御など)を実行します。これらのノードをビルディングブロックのように組み合わせて、自動化されたプロセスを作成します。
開始と終了
使用タイミング
ワークフローを設計する際、開始ノードと終了ノードで入出力パラメーターの構造と内容を定義します。
使用方法
開始ノード
コンポーネント
説明
事前定義変数
ワークフローは、ユーザー入力の処理と会話履歴の維持のために以下の事前定義変数を提供します。
query:ユーザーのテキスト入力を格納します。
historyList:マルチターン対話におけるコンテキストを維持するために会話履歴を格納します。大規模モデルノードや意図分類ノードなど、メモリ機能をサポートするノードでこの変数を使用するには、カスタムキャッシュ を選択します。
imageList:画像分析やマルチモーダル対話を可能にするためにユーザーがアップロードした画像を格納します。大規模モデルノードや意図分類ノードなど、メモリ機能をサポートするノードでこの変数を使用するには、カスタムキャッシュ を選択します。
カスタム変数
カスタム変数は、ワークフロー用に定義する構造化された入力パラメーターです。テストまたは API 呼び出しからデータを受け取り、後続のノードで参照できます。カスタム変数を作成する際は、以下のパラメーターを構成します。
変数名:意味のある名前を入力します。漢字はサポートされていません。
型:変数のデータ型です。サポートされている型は、String、Boolean、Number、Object、Array(String、Boolean、Number、Object の配列)、File です。
説明:変数の目的と使用タイミングを簡潔に記述します。
終了ノード
コンポーネント
説明
出力モード
テキスト出力:非構造化コンテンツに適しています。入力ボックスには固定コンテンツを入力するか、
/を入力して変数を参照し、ユーザーに返される最終結果を決定します。ワークフローノードの出力またはセッション変数から変数を取得できます。出力変数を適切にマッピングすることで、ワークフローのデータフローを制御し、正確で完全な最終応答を保証できます。JSON Output:JSON 形式で構造化されたコンテンツを出力する場合に適しています。変数名を定義し、テキストを入力するか変数を参照できます。
ストリーミング出力
ストリーミング出力スイッチは、テキスト出力モードにのみ適用されます。
有効にすると、大規模モデルノードやアプリケーションコンポーネントノードからの応答がトークン単位でストリーミングされます。無効にすると、完全な応答が生成された後に一度に返されます。
大規模モデル
使用理由
このノードはワークフローの知的コアであり、言語を理解し、テキストを生成し、画像を分析し、マルチターン対話を実現できます。コピーライティング、テキストの要約、画像コンテンツの分析(Qwen-VL モデルを使用)などに活用できます。
機能
単一入力処理と大規模データセットのバッチ処理の両方をサポートします。
Qwen-Plus など、さまざまな大規模モデルを構成できます。パフォーマンス、レイテンシー、その他の要件に基づいて適切なモデルを選択できます。
ノードパラメーター構成
パラメーター
説明
モード選択
Single Mode:大規模モデルを 1 回呼び出します。
Batch Mode:ノードが複数回実行され、各実行でリスト内のアイテムを 1 つずつバッチ変数に割り当てます。このプロセスは、リスト内のすべてのアイテムが処理されるか、構成された最大バッチ実行回数に達すると停止します。
Batch Configuration:
Maximum Number of Batches(範囲:1~100;標準ユーザーのデフォルト値:100):バッチ処理の最大実行回数です。
説明バッチ実行回数は、入力配列の最小長さによって決まります。入力変数が構成されていない場合、実行回数は構成されたバッチ数によって決まります。
Number of Parallel Runs(範囲:1~10):バッチ処理の同時実行制限を設定します。1 を設定すると、すべてのタスクが直列で実行されます。
モデル構成
適切な大規模モデルを選択し、パラメーターを調整します。利用可能なモデルは UI に表示されます。
モデルの詳細については、モデルリストをご参照ください。
各モデルの API 呼び出しレート制限については、レート制限をご参照ください。
パラメーター構成
temperature:生成コンテンツの多様性を制御します。温度値を高くすると生成テキストのランダム性が高まり、よりユニークな出力が得られますが、値を低くするとコンテンツがより保守的で一貫性のあるものになります。
この構成は、DeepSeek R1 シリーズモデルでは現在サポートされていません。
回答の最大文字数:モデルが生成するテキストの最大長(トークン数)を制限します(プロンプトは含みません)。この制限はモデルによって異なります。
以下のパラメーターは、Qwen-VLモデルを選択した場合にのみ利用できます。
モデルの入力パラメータ:
vlImageUrlには、変数を参照するか画像 URL を直接入力できます。Image Source:
画像セット:モデルは各アップロード画像を個別に扱い、ユーザーの質問に最も関連するものを選択します。
単一画像は直接渡せます。例:
https://****.com/****.jpg。複数画像はリストとして渡せます。例:
["URL","URL","URL"]。ビデオフレーム:モデルはアップロードされた画像を同じビデオからのものと見なし、全体として順番に理解します。最低 4 枚のビデオフレームを提供する必要があります。
システムプロンプト
モデルにシステムレベルの指示を提供します。モデルの役割、タスク、出力フォーマットを定義できます。例:「あなたは数学の専門家で、数学の問題を解くことに特化しています。正しいフォーマットで問題解決のプロセスと結果を出力してください。」
ユーザープロンプト
モデルへのユーザーの入力(リクエストや指示など)です。プロンプトテンプレートを構成するか、変数を挿入できます。モデルはこの入力を使って応答を生成します。
メモリ
メモリは、マルチターン対話においてモデルが複数回にわたって保持するコンテキストです。
現在のノードキャッシュ:このノードの出力をコンテキストとして使用します。モデルはこのノード内で生成されたコンテキストのみを記憶します。
メモリラウンド数:記憶する会話ラウンド数です。1 回の入力とそれに対応する出力が 1 ラウンドを構成します。
カスタムキャッシュ:指定されたコンテキスト変数をコンテキストとして使用します。
コンテキスト変数:コンテキストのソースを選択します。
出力変数
このノードの処理結果を格納する変数の名前です。後続のノードはこの変数を使用してこのノードの結果にアクセスできます。
DeepSeek R1 シリーズモデルは、ディープシンキングプロセス(
reasoningContent)の出力をサポートしています。失敗時の再試行
無効の場合、エラーが発生するとノードの実行は停止します。
有効の場合、エラーが発生すると、構成された再試行回数と間隔に従ってノードが再実行されます。
最大再試行回数:リクエストが失敗した場合の最大再試行回数です。
再試行間隔:各再試行の間隔(ミリ秒単位)です。
例外処理
無効の場合、ノードはシステムのデフォルトエラー処理メカニズムを使用してエラーを処理します。
有効の場合、エラーが発生したときに構成に従ってカスタム処理ロジックを実行します。
デフォルト値:例外が発生した場合、
resultのコンテンツが出力されます。例外ブランチ:例外が発生した場合、このブランチが実行されます。処理フローを構成する必要があります。
結果の返却
この機能は廃止予定です。
このオプションは API 呼び出しにのみ適用され、ノードのコンテンツを出力するかどうかを決定します。このコンポーネントの目的について詳しくは、アプリケーション呼び出しをご参照ください。
説明API を介してアプリケーションを統合する方法については、アプリケーション呼び出しをご参照ください。
ナレッジベース
定義
ナレッジベースノードは、検索拡張生成(RAG)を実装します。入力に基づいて指定されたナレッジベースから関連するチャンクを取得し、その結果をコンテキストとしてダウンストリームの大規模モデルノードに渡します。これにより、大規模モデルにありがちな知識の陳腐化、プライベートデータへのアクセス不可、ハルシネーションなどの問題を解決します。
入力構成
ナレッジベースをクエリするための基準を定義します。
パラメーター
説明
content
ナレッジベースをクエリするためのテキストです。テキストを直接入力するか、エディターで
/を入力して上流ノードの出力変数を選択・参照できます。imageList
ナレッジベースをクエリするための画像です。
https://xxx.xxx.com/xxx/xxx.jpegのような公開アクセス可能な画像 URL を入力するか、エディターで/を入力して上流ノードの出力変数を選択・参照できます。ナレッジベース選択方法
選択方法
適用シナリオ
構成
固定ナレッジベースを選択
各呼び出しで同じ事前選択されたナレッジベースを使用します。
ドロップダウンリストから特定のナレッジベースを選択します。ドキュメント、テーブル、画像の 3 種類のナレッジベースを追加できます。
動的インポート
上流ノードの出力が使用するナレッジベースを動的に決定します。
CodeList変数を構成します。変数を参照するか直接入力して、ナレッジベースのリストを指定できます。ナレッジベース呼び出し方法
この設定は、ナレッジベースのトリガーロジックを定義します。デフォルトの方法は 常に呼び出し です。
呼び出し方法
説明
パラメーター
always invoke
各ユーザー入力に対してナレッジベースの取得を実行します。高頻度の質問応答シナリオに適しています。
なし
intelligent invoke
エージェントがユーザーの入力とその説明に基づいてナレッジベースをクエリする必要があるかどうかを判断します。柔軟な対話シナリオに適しています。
ナレッジベースの説明(必須)
legacy invocation
ドキュメント、テーブル、画像のナレッジベースの結果が一緒にリコールされます。単一の topK パラメーターがリコールされるチャンク数を制御し、各タイプごとの個別のデバッグはサポートされていません。
topK(範囲:1~50、デフォルト:10)
パラメーターの説明:
ナレッジベースの説明:ナレッジベースのコンテンツと、そのデータを応答に使用できる条件を記述します。テキスト入力または
/を入力して変数を挿入できます。topK:各ナレッジベースからリコールされるチャンクの最大数です。実際のリコールチャンク数はマッチング結果に依存し、topK 値より少なくなる場合があります。
リコール結果のデバッグ
この機能は always invoke および intelligent invoke モードでのみサポートされています。デバッグ ボタンをドキュメント、テーブル、または画像タイプの横にクリックして、そのナレッジベースのリコール結果をテストします。結果を使用して構成を微調整できます。完了したら、右上隅の 保存 をクリックして現在のアプリケーションに構成を適用します。
ナレッジベースフィルタリング
この機能はデフォルトで無効になっています。有効にすると、システムは大規模モデルを使用してドキュメントとテーブルからリコールされた結果をインテリジェントにフィルタリングし、最終出力の品質を向上させます。回答精度が要求されるシナリオや、不必要な情報をフィルタリングする必要がある場合に適しています。
ノード出力
ナレッジベースノードは、
resultオブジェクトを含む構造化されたオブジェクトを出力します。フィールド
型
説明
result
オブジェクト
現在のクエリから返されたすべての情報を含みます。
result.chunkList
Array<Object>
リコールされたチャンクの配列です。クエリが結果を返さない場合、この配列は空になります。
result.chunkList[ ].content
String
リコールされたナレッジベースチャンクの元のコンテンツです。
result.chunkList[ ].title
String
チャンクが属するドキュメントのタイトルです。
result.chunkList[ ].documentName
String
リコールされたチャンクが配置されているドキュメントの名前です。
result.chunkList[ ].score
Number
ナレッジベースチャンクの類似度スコアです。スコアが高いほど、より良いマッチを示します。
result.chunkList[ ].id
String
チャンク ID です。
result.chunkList[ ].dataId
String
ドキュメント ID です。
result.chunkList[ ].docUrl
String
ソースファイルのダウンロードリンクです。
result.chunkList[ ].knowledgeBaseId
String
ナレッジベース ID です。
result.chunkList[ ].nid
String
元のテキストの識別子です。
result.chunkList[ ].images
Array<String>
画像のリストです。
result.chunkList[ ].pageNumber
Array<Number>
ページ番号の配列です。
result.rewriteQuery
String
書き換えられたユーザークエリです。
API
API ノードがターゲットサービスにアクセスできるようにするには、ターゲットサーバーのセキュリティグループまたはファイアウォールのインバウンドルールの許可リストに、Model Studio サービスの IP アドレス(47.93.216.17、39.105.109.77、60.205.180.248、および 59.110.152.173)を追加してください。
定義
POST、GET、PUT、PATCH、DELETE メソッドを使用してカスタム API サービスを呼び出し、API 呼び出しの結果を出力します。
パラメーター構成
パラメーター
説明
API アドレス
API のリクエスト URL です。
リクエストメソッド:
POST:データをサーバーに送信して新しいリソースを作成します。
GET:サーバー上のデータを変更せずにリソースを取得します。
PUT:指定されたリソースを更新するか、サーバー上に新しいリソースを作成します。
PATCH:サーバー上のリソースを部分的に更新します。
DELETE:サーバーから指定されたリソースを削除します。
URL:入力フィールドに完全な API アドレスを入力します。直接アドレスを入力するか、前のノードの値を参照する変数を使用できます。例:
https://dashscope.aliyuncs.com/compatible-mode/v1/files。
ヘッダー設定
Content-Type や Authorization などの HTTP リクエストヘッダーを指定します。直接値を入力するか、前のノードから参照できます。
パラメーター設定
リクエスト URL のクエリパラメーターです。直接値を入力するか、前のノードから参照できます。
例:
limitinhttps://dashscope.aliyuncs.com/compatible-mode/v1/files?limit=5。ボディ設定
API の要件に基づいて正しいタイプを選択します。
none:リクエストボディがありません。GET リクエストに適しています。
form-data:フォームデータで、ファイルアップロードやキーと値のペアに使用します。
raw:JSON や XML などの生テキストです。
JSON:自動的にフォーマットされた JSON オブジェクトです。
タイムアウト設定 (秒)
応答を待つ最大時間です。この時間内に応答が受信されない場合、リクエストはタイムアウトします。
失敗時の再試行
無効の場合、エラーが発生するとノードの実行は停止します。
有効の場合、エラーが発生すると、構成された最大再試行回数と再試行間隔に従ってリクエストが再試行されます。
最大再試行回数:失敗したリクエストの最大再試行回数です。
再試行間隔:再試行間の間隔(ミリ秒単位)です。
例外処理
無効の場合、ノードはエラー発生時にデフォルトのエラー処理メカニズムを使用します。
有効の場合、エラー発生時にカスタムロジックを実行します。
デフォルト値:例外発生時に
resultのコンテンツが出力されます。例外ブランチ:例外が発生した場合、このブランチに進みます。このブランチの処理フローを構成する必要があります。
出力
API 応答を指定された変数に格納し、後続のノードで使用します。
説明API を使用したアプリケーション統合の詳細については、アプリケーション統合をご参照ください。
プラグイン
定義
ワークフローアプリケーションにプラグインノードを追加して、より複雑なタスクを実行できます。Model Studio は Quark Search、電卓、Python コードインタープリターなどの公式プラグインを提供しています。特定のニーズを満たすためにカスタムプラグインを作成することもできます。
詳細については、プラグイン概要をご参照ください。
前提条件
パラメーター構成
パラメーター
説明
入力
ノードが処理するコンテンツを指定します。選択したプラグインによって変数が変化します。プラグインを選択すると、その組み込み変数が自動的に読み込まれます。
出力
ノードの処理結果を含む出力変数です。後続のノードはこの変数を使用して結果にアクセスします。
失敗時の再試行
無効の場合、エラーが発生するとノードの実行は停止します。
有効の場合、エラーが発生すると、構成された再試行回数と間隔に従ってノードが再実行されます。
最大再試行回数:リクエストが失敗した場合の最大再試行回数です。
再試行間隔:各再試行の間隔(ミリ秒単位)です。
例外処理
無効の場合、ノードはシステムのデフォルトエラー処理メカニズムを使用します。
有効の場合、ノードはエラー発生時にカスタムロジックを実行します。
デフォルト値:例外発生時に
resultのコンテンツが出力されます。例外ブランチ:例外が発生した場合、このブランチを実行します。ブランチの処理フローを構成する必要があります。
Function Compute
定義
Alibaba Cloud Function Compute 上のカスタムサービスを呼び出します。
パラメーター構成
重要Function Compute ノードのデフォルトタイムアウトは 60 秒で、変更できません。
パラメーター
説明
入力
このノードが処理する入力変数です。上流ノードの変数を参照するか、直接値を入力できます。
リージョン
Function Compute サービスが配置されているリージョンを選択します:Singapore、クアラルンプール、または Indonesia (Jakarta)。
サービス構成
呼び出す Function Compute サービスを選択します。事前に関数を作成しておく必要があります。
Function Compute サービスを作成した Alibaba Cloud アカウントは、Model Studio (Bailian) にログインするために使用しているアカウントと同じであるか、または同じ Alibaba Cloud ルートアカウントに属している必要があります。
出力
ノードの出力を格納する変数です。後続のノードがこの変数を参照できます。
スクリプト
定義
スクリプトを使用して入力を特定のテンプレートまたは出力フォーマットに変換します。これには、データの解析、変換、フォーマットが含まれ、一貫性と読みやすさを確保します。
パラメーター構成
パラメーター
説明
input
固定値を受け入れるか、上流ノードまたはセッション変数の変数を参照します。
code
ノードのコアロジックを定義します。JavaScript と Python の両方をサポートしています。
入力の取得:組み込みの
paramsオブジェクトを使用して、params.<variable_name>の形式で入力パラメーターにアクセスします。例:params.input1。出力の返却:
mainハンドラ関数はreturnで辞書またはオブジェクトを返す必要があります。このオブジェクトのキーと値のペアがノードの出力になります。
output
コード内の
return文によって返される辞書が、このノードの出力として機能します。たとえば、
{'result': 'Processing successful'}を返す場合、ダウンストリームノードはnode_name.resultを使用して文字列 "Processing successful" にアクセスできます。失敗時の再試行
無効の場合、エラーが発生するとノードの実行は停止します。
有効の場合、エラーが発生すると、構成された最大再試行回数と再試行間隔に従ってノードが再実行されます。
最大再試行回数:失敗後の最大再試行回数です。
再試行間隔:再試行間の間隔(ミリ秒単位)です。
例外処理
無効の場合、ノードはシステムのデフォルトエラー処理メカニズムを使用します。
有効の場合、ノードはエラー発生時にカスタムロジックを実行します。
デフォルト値:例外発生時に
resultのコンテンツが出力されます。例外ブランチ:例外が発生した場合、ユーザーが構成した別のブランチに実行がルーティングされます。
条件
定義
条件ノードはワークフローに分岐ロジックを追加します。変数が指定された条件を満たすと、ワークフローは対応するダウンストリームリンクに従います。このノードは
AND/OR構成をサポートし、条件を上から下へ順番に評価します。パラメーター構成
パラメーター
説明
条件付きブランチ
条件式を入力します。
異なるグループの条件は
ORで結合され、同じグループ内の条件はANDで結合されます。else
定義された条件がいずれも満たされない場合のデフォルト出力です。
意図分類
定義
ユーザー入力をその説明に基づいて事前定義された意図とインテリジェントにマッチングし、対応するリンクにルーティングします。
パラメーター構成
パラメーター
説明
入力変数
分類する入力変数を指定します。直接値を入力するか、前のノードまたはセッション変数の変数を使用できます。
モデル選択
Qwen-Plus および意図分類モデルをサポートします。
意図分類
モデルが分類する意図を定義します。モデルは説明に基づいて入力を意図にマッチングし、対応するリンクにルーティングします。例:「数学の問題を計算するため」または「天気に関する質問に答えるため」。
その他意図
モデルが入力が定義された意図のいずれにもマッチしないと判断した場合に、このブランチが実行されます。
意図モード
シングル選択モード:大規模モデルは、利用可能な構成から最もよくマッチする単一の意図を選択します。
マルチ選択モード:大規模モデルは、利用可能な構成からすべてのマッチする意図を選択します。
推論モード
高速モード:複雑な推論ステップを回避することで処理速度を向上させ、シンプルなシナリオに適しています。
品質モード:ステップバイステップの推論を使用して、より正確な分類を実現します。
メモリ
マルチターン対話において、モデルが会話履歴を記憶する能力を指し、コンテキストとして機能します。
ノードローカルキャッシュ:このノードの出力をコンテキストとして使用します。モデルのメモリはこのノードで生成されたコンテキストに限定されます。
メモリターン数:記憶する会話ターン数です。1 回の入力とその対応する出力が 1 ターンを構成します。
カスタムキャッシュ:指定されたコンテキスト変数のコンテンツをコンテキストとして使用します。
コンテキスト変数:コンテキストのソースを指定します。
プロンプト
意図分類モデルに対する追加の指示または制約を提供します。モデルの分類結果が要件により一致するように、例を追加したり制約を定義したりできます。
この例では、具体的な分類例を提供することで、モデルが「配達時間の問い合わせ」を「注文照会」の意図として分類するよう導き、制約により他の無関係な質問を除外する範囲を限定しています。
出力
ノードの出力を格納する変数です。ダウンストリームノードはこの変数を使用して結果にアクセスできます。
説明このノードの実行にはトークンが消費されます。実行時に消費されるトークン数が表示されます。
フロー出力
定義
フロー出力ノードは、ワークフロー内の任意の時点で指定されたコンテンツを出力します。これは、ワークフローが完了した後にのみ返される最終出力とは異なります。
フロー出力ノードは、以下のシナリオで役立ちます。
大きな出力を分割する: ワークフローが大量の出力を生成する場合、コンテンツを 2 つの部分に分割するためにフロー出力ノードを挿入できます。1 つの部分はフロー出力ノードで出力され、もう 1 つの部分は終了ノードで出力されます。
中間情報を取得する: ワークフロー内の重要なポイントにこのノードを挿入して、変数値やプロセスの状態などの情報を出力します。これにより、進捗を追跡し、問題をトラブルシューティングできます。
長時間の操作中にフィードバックを提供する: ユーザーにフィードバックがない状態を避けるために、フロー出力ノードを挿入して一時的なメッセージを表示できます。これは、外部 API の呼び出し、複雑な計算の実行、データのバッチ処理など、時間がかかる操作中に役立ちます。「データを読み込んでいます。しばらくお待ちください...」や「リクエストを処理中です。このウィンドウを閉じないでください。」などのステータス更新を提供することで、システムがフリーズまたは応答していないのではなく、動作していることをユーザーに知らせます。
パラメーター構成
パラメーター
説明
出力コンテンツ
固定コンテンツを入力するか、
/を入力して前のノードまたはセッション変数の変数を参照します。ストリーミング出力
有効にすると、大規模モデルからのコンテンツがトークン単位で会話にストリーミングされます。無効にすると、応答全体が最初に生成され、その後一度に出力されます。
変数処理
定義
テキストコンテンツの変換と処理に使用され、特定のコンテンツの抽出やフォーマットの変換などが可能です。このノードはテンプレートモードもサポートしています。
パラメーター構成
パラメーター
説明
出力モード
テキスト出力:入力をテキストに変換します。エディターでは、コンテンツを直接入力するか、上流ノードまたはセッション変数の変数を挿入できます。
JSON 出力:入力変数を JSON オブジェクトとしてフォーマットします。
グループ集約:指定された戦略に従ってグループからどの値を返すかを決定します。各グループから最初または最後の空でない値を返すことができます。
出力変数
ノードの出力を格納する変数を指定し、後続のノードで使用します。
結果の返却
この機能は廃止予定です。
API 呼び出しにのみ適用され、ノードの出力が返されるかどうかを決定します。アプリケーション呼び出しをご参照ください。
パラメーター抽出
定義
モデルを使用してテキストから構造化されたパラメーターを抽出します。
パラメーター構成
パラメーター
説明
入力
パラメーターを抽出するテキストです。
モデル選択
パラメーターを抽出するために使用するモデルを指定します。ビジネスニーズに最も適したものを選択してください。
抽出するパラメーター
モデルは、提供された名前、型、説明に基づいて入力からパラメーターを抽出します。
プロンプト
パラメーター抽出中にモデルをガイドする追加の指示です。
メモリ
メモリは会話のコンテキストを提供し、マルチターンシナリオでモデルが以前のやり取りを記憶するのを助けます。
このノード内にキャッシュ:このノードの出力をコンテキストとして使用します。モデルはこのノードからのコンテキストのみを記憶します。
メモリターン数:記憶する会話ターン数です。1 ターンは 1 回の入力とその対応する出力で構成されます。
カスタムキャッシュ:指定されたコンテキスト変数を使用してコンテキストを提供します。
コンテキスト変数:コンテキストのソースを選択します。
出力
モデルによって抽出されたパラメーターを含みます。後続のノードはこの出力を変数として参照できます。
エージェントグループ
定義
エージェントグループには複数のサブエージェントが含まれます。グループ内の意思決定モデルがタスク要件に基づいて自動的に実行フローを計画し、サブエージェントをスケジューリングして調整し、タスクを完了します。大規模なプロジェクトを完了する必要があるが、具体的なワークフローの設計方法がわからない場合にこのノードを使用します。複雑なタスクをサブタスクに分解し、異なるエージェントが並行して処理することで、タスク実行速度を向上させることができます。
パラメーター構成
パラメーター
説明
入力
ノードが処理するコンテンツを指定します。前のノードの変数を参照できます。
モデル選択
意思決定モデルを選択します。
グループ名
エージェントグループのカスタム名を入力します。
エージェント
エージェントグループ内のサブエージェントを指定します。公開済みのエージェントアプリケーションのみを追加できます。
サブエージェントを追加した後、Configureをクリックしてその機能を説明します。この説明により、意思決定モデルが現在のタスクに対してどのサブエージェントを呼び出すかを判断できます。
出力変数
このノードの出力を格納する変数を指定します。この変数は後続のノードで参照できます。
エージェント作成
定義
オーケストレーションキャンバス専用の新しいエージェントを作成します。
パラメーター構成
パラメーター
説明
入力
このノードが処理するコンテンツです。前のノードの変数を参照できます。
エージェント名
エージェントのカスタム名です。
モデル選択
エージェントが使用する大規模モデルです。
プロンプト
自然言語を使用してエージェントの役割とタスクを定義します。
ナレッジベース
エージェントのナレッジベースを選択します。
プラグイン
公式またはカスタムプラグインを呼び出して、エージェントの機能を拡張できるようにします。
出力変数
ノードの出力を格納する変数で、後続のノードで使用します。
マルチモーダル生成
定義
マルチモーダル生成ノードは、Alibaba Cloud のマルチモーダルモデルを使用して、構成されたプロンプトとパラメーターに基づいて画像、ビデオ、または音声コンテンツを生成します。このノードは、コンテンツ作成、マーケティングアセット制作、ショートビデオ生成、ボイスオーバー合成に使用できます。
モデル選択
モデル選択
ドロップダウンリストからマルチモーダル生成モデルを選択します。モデルは機能別に分類されています。
モデルタイプ
サポートモデル
特徴
画像生成
Qwen-Image
複雑な中国語および英語テキストのレンダリングに優れています。
Wan 2.6-image-generation
テキスト指示から画像を生成および編集し、画像編集とテキスト・画像混合モードをサポートします。
Qwen-Image-Plus
複雑な中国語および英語テキストのレンダリングに優れています。
Z-Image-Turbo
軽量なテキスト-to-画像モデルで、高品質な画像を迅速に生成します。中国語と英語のバイリンガルレンダリング、複雑な意味理解、複数のスタイルとテーマをサポートします。
Wan 2.2-text-to-image-Plus
Wan 2.2 のプロ版で、創造性、安定性、写実性が包括的に向上しています。
Wan 2.2-text-to-image-Flash
Wan 2.2 のフラッシュ版で、創造性、安定性、写実性が包括的に向上しています。
ビデオ生成
Wan 2.6-text-to-video
Wan 2.6。マルチショットストーリーテリング機能を備え、自動音声読み上げとカスタム音声ファイル入力をサポートします。
Wan 2.6-image-to-video
Wan 2.6。マルチショットストーリーテリング機能を備え、自動音声読み上げとカスタム音声ファイル入力をサポートします。
Wan 2.5-text-to-video-Preview
Wan 2.5 プレビュー。自動音声読み上げとカスタム音声ファイル入力をサポートします。
Wan 2.5-image-to-video-Preview
Wan 2.5 プレビュー。自動音声読み上げとカスタム音声ファイル入力をサポートします。
Wan 2.2-text-to-video-Plus
Wan 2.2 のプロ版。命令理解の精度が向上し、安定的で滑らかなモーション生成、豊かな出力の詳細を提供します。
Wan 2.2-image-to-video-Plus
Wan 2.2 のプロ版で、命令理解の精度が向上し、カメラの動きを制御でき、視覚的一貫性を保ちます。安定性、成功率、コンテンツの豊かさが包括的に向上しています。
Wan 2.2-image-to-video-Flash
Wan 2.2 のフラッシュ版で、超高速生成、命令理解とカメラ制御の精度向上、視覚的一貫性を実現し、安定性と成功率が包括的に向上しています。
音声生成
Qwen3-TTS-Flash
混合言語テキスト入力とストリーミング音声出力をサポートします。
利用可能なモデルのリストは変更される可能性があります。最新のオプションについては UI をご確認ください。モデル呼び出しの課金については、モデル呼び出し課金をご参照ください。
構成パラメーターはモデルによって異なります。パネルには選択内容に関連する設定のみが表示されます。
画像生成
画像生成モデルを選択した後、以下のパラメーターを構成します。利用可能なパラメーターはモデルによって異なります。具体的なオプションについては UI をご確認ください。
パラメーター
必須
説明
肯定的なプロンプト
はい
ターゲット画像のコンテンツ、スタイル、構図などの要素を記述します。テキストを直接入力するか、
/を入力して上流ノードの出力変数を挿入できます。否定的なプロンプト
いいえ
画像に含めたくないコンテンツ(ぼやけやウォーターマークなど)を記述します。テキストを直接入力するか、
/を入力して上流ノードの出力変数を挿入できます。サイズ/解像度
はい
画像の寸法です。
prompt_extend
いいえ
有効にすると、システムは大規模モデルを使用して入力プロンプトをインテリジェントに書き換えます。この機能は肯定的なプロンプトにのみ適用されます。短いプロンプトの結果を大幅に改善しますが、3~4 秒の遅延が発生します。
ウォーターマークの追加
いいえ
生成された画像に Alibaba Cloud のウォーターマークを追加するかどうかを制御します。この機能はデフォルトで無効になっています。
参照画像
いいえ
スタイルまたはコンテンツをガイドするために参照画像をアップロードします。開始ノードからの File 型変数または公開 URL を渡せます。
画像数
いいえ
1 回のリクエストで生成する画像の数です。デフォルト値は 1 です。
インテリジェントプロンプトリライト
いいえ
有効にすると、大規模モデルが入力プロンプトをインテリジェントに書き換えます。この機能は肯定的なプロンプトにのみ適用されます。短いプロンプトの結果を大幅に改善しますが、画像生成時間が増加します。
enable_interleave
いいえ
無効(デフォルト):画像編集モード。1~4 枚の入力画像を使用して編集、スタイル転送、一貫性のある被写体を生成します。
有効:テキストと画像の混合出力モード。画像またはプレーンテキストに基づいて、テキストと画像の両方を含む単一のコンテンツブロックを生成します。
ランダムシード
いいえ
生成された出力のランダム性を制御します(デフォルト:1234)。同じシード値とプロンプトを使用すると、類似した画像が生成されます。
インテリジェントシンキング
いいえ
有効にすると、大規模モデルが推論とプロンプトリライトを実行します。これにより生成品質が向上しますが、生成時間も増加します。
ビデオ生成
ビデオ生成モデルを選択した後、以下のパラメーターを構成します。利用可能なパラメーターはモデルによって異なります。具体的なオプションについては UI をご確認ください。
パラメーター
必須
説明
肯定的なプロンプト
はい
ターゲットビデオのシーン、アクション、スタイルなどの要素を記述します。テキストを直接入力するか、
/を入力して上流ノードの出力変数を挿入できます。否定的なプロンプト
いいえ
ビデオに含めたくないコンテンツ(ぼやけやウォーターマークなど)を記述します。テキストを直接入力するか、
/を入力して上流ノードの出力変数を挿入できます。解像度
はい
ビデオの解像度です。利用可能なオプションはモデルによって異なります。
ビデオの長さ
はい
生成されるビデオの長さです。利用可能なオプションはモデルによって異なります。
ランダムシード
はい
生成された出力のランダム性を制御します。同じシード値とプロンプトを使用すると、類似したビデオが生成されます。
インテリジェント拡張
いいえ
有効にすると、システムは大規模モデルを使用して入力プロンプトをインテリジェントに書き換え、ビデオ生成品質を向上させます。この機能は肯定的なプロンプトにのみ適用されます。
スマートマルチショット
いいえ
有効にすると、モデルがマルチショットビデオを生成します。
音声を生成
いいえ
有効にすると、公開音声ファイル URL を提供してボイスオーバーを追加できます。
参照画像
はい(画像-to-ビデオモデルのみ)
ビデオの最初のフレームとして機能する参照画像を指定します。モデルはこの画像に基づいてビデオを生成します。開始ノードからの File 型変数または公開 URL を渡せます。
音声生成
パラメーター
必須
説明
合成用テキスト
はい
音声に変換するテキストコンテンツです。テキストを直接入力するか、
/を入力して上流ノードの出力変数を挿入できます。言語タイプ
いいえ
合成音声の言語(デフォルト:中国語)。サポート言語:中国語、英語、ドイツ語、イタリア語、ポルトガル語、スペイン語、日本語、韓国語、フランス語、ロシア語。
音声
いいえ
合成音声の音声です。サポートされている音声のリストについては、リアルタイム音声合成 - Qwenをご参照ください。
ノード出力
マルチモーダル生成ノードの実行後、以下の変数が出力されます。
パラメーター
型
説明
例
output
オブジェクト
タスクステータス、実行時間、結果を含む完全な出力オブジェクトです。
-
output.task_status
String
タスクステータス(例:「SUCCEEDED」または「FAILED」)。
SUCCEEDED
output.submit_time
String
タスク送信時間(YYYY-MM-DD HH:mm:ss.SSS 形式)。
2026-01-22 10:54:44.200
output.end_time
String
タスク終了時間(YYYY-MM-DD HH:mm:ss.SSS 形式)。
2026-01-22 10:54:51.685
output.task_id
String
タスクの一意の識別子です。
e36c2221-b7fd-xxxx
output.scheduled_time
String
タスクスケジュール時間(YYYY-MM-DD HH:mm:ss.SSS 形式)。
2026-01-22 10:54:44.251
output.results
Array<Object>
生成結果の配列で、生成されたアセットのメタデータを含みます。
-
output.results[].orig_prompt
String
ユーザーが入力した元のプロンプトです。
a cute cat sitting on a windowsill
output.results[].actual_prompt
String
モデル拡張後の生成に使用されたプロンプトです。
a cute white cat with fluffy, soft fur...
output.results[].url
String
生成されたファイルの URL です。
https://dashscope-result...
usage
オブジェクト
モデル使用統計情報です。
-
usage.image_count
Number
生成された画像の数(画像生成モード)。
1
urls
Array<String>
生成されたファイルの URL の配列です。これらの URL を使用して出力にアクセスまたはダウンロードできます。
["https://dashscope-result..."]
アプリケーションのテスト
ワークフローを設定した後は、テスト機能を使用して、期待どおりに実行されることを確認できます。右上隅にある テスト ボタンをクリックして、テストパネルを開きます。テストパネルには、さまざまなテストケース向けの複数のテストモードが用意されています。
テキスト会話
テキスト会話はデフォルトのテストモードです。会話履歴を保持し、継続的なマルチターン対話をサポートします。
テストパネル上部のドロップダウンリストからテキスト会話モードを選択します(デフォルトで選択されています)。ワークフローにカスタム変数が含まれている場合、パラメーター構成エリアでその値を入力します。
入力ボックスにテストコンテンツ(テキストおよびファイル添付)を入力し、Send ボタンをクリックするか Enter キーを押してテストを実行します。
テスト結果を確認します。ノードをクリックして詳細な入力と出力を表示したり、出力フォーマットをテキストと JSON の間で切り替えたりできます。
会話を続けるには、入力ボックスに次のターンを入力して送信します。新しい会話を開始するには、クリア ボタンをクリックします。
テキスト生成
テキスト生成モードは、シングルターンのインタラクション用です。各テストは独立しており、会話履歴は保持されません。
チェックリスト
チェックリストには、ワークフローに必要な構成が記載されています。
チェックリストを表示するには、キャンバス構成ページの右上隅にある  アイコンをクリックします。
アイコンをクリックします。

アプリケーションのリリース
アプリケーションをリリースすると、API を介して呼び出すか、同じメインアカウントの RAM ユーザーと Web ページとして共有できます。そのためには、エージェントアプリケーション管理ページの右上隅にある 公開 ボタンをクリックします。
API による呼び出し
ワークフローアプリケーションの Publish Channel タブで、API の横にある View API をクリックして、API を使用してエージェントアプリケーションを呼び出す方法を確認します。
注:API を呼び出すには、YOUR_API_KEY をご利用の API キーに置き換える必要があります。

API 呼び出しに関する FAQ および情報については、以下のトピックをご参照ください。
呼び出し方法(HTTP/SDK)については、アプリケーション呼び出しをご参照ください。
API 呼び出しパラメーターの詳細については、アプリケーション呼び出しパラメーター情報をご参照ください。
パラメーターの受け渡しの詳細については、アプリケーションのパラメーター受け渡しをご参照ください。
API 呼び出しによって返されたエラーを解決するには、エラーメッセージをご参照ください。
アプリケーション自体には同時実行数の制限はありません。代わりに、呼び出すモデルによって制限が決まります。Model Studio コンソールをご参照ください。
現在、ワークフローから Xiyan サービスを呼び出すことはできません。代わりに、API ノードを使用してカスタム API サービスを呼び出してください。
API 呼び出しのタイムアウトは 300 秒で、変更できません。タイムアウトが発生する可能性がある場合は、以下のソリューションを検討してください。
非同期モードの使用:このモードでは、システムがタスク ID を返します。その後、タスク ID を使用して結果を照会することで、同期タイムアウト制限を回避できます。
タスクの分割:タスクを複数のステップに分割するか、バッチデータをより小さなチャンクに処理して、単一の実行がタイムアウトしないようにします。
ワークフローのインポートまたはエクスポート
Model Studio ワークフローのインポートまたはエクスポート
ワークフローページの上部にある
 アイコンをクリックし、Export DSL または 百煉DSLをインポートする を選択します。
アイコンをクリックし、Export DSL または 百煉DSLをインポートする を選択します。
Dify ワークフローのインポート
Model Studio は、Dify ワークフローをワンクリックでインポートして、簡単に移行および再利用できるようにサポートしています。
ワークフローページの上部にある
アイコンをクリックし、Import Dify DSL を選択します。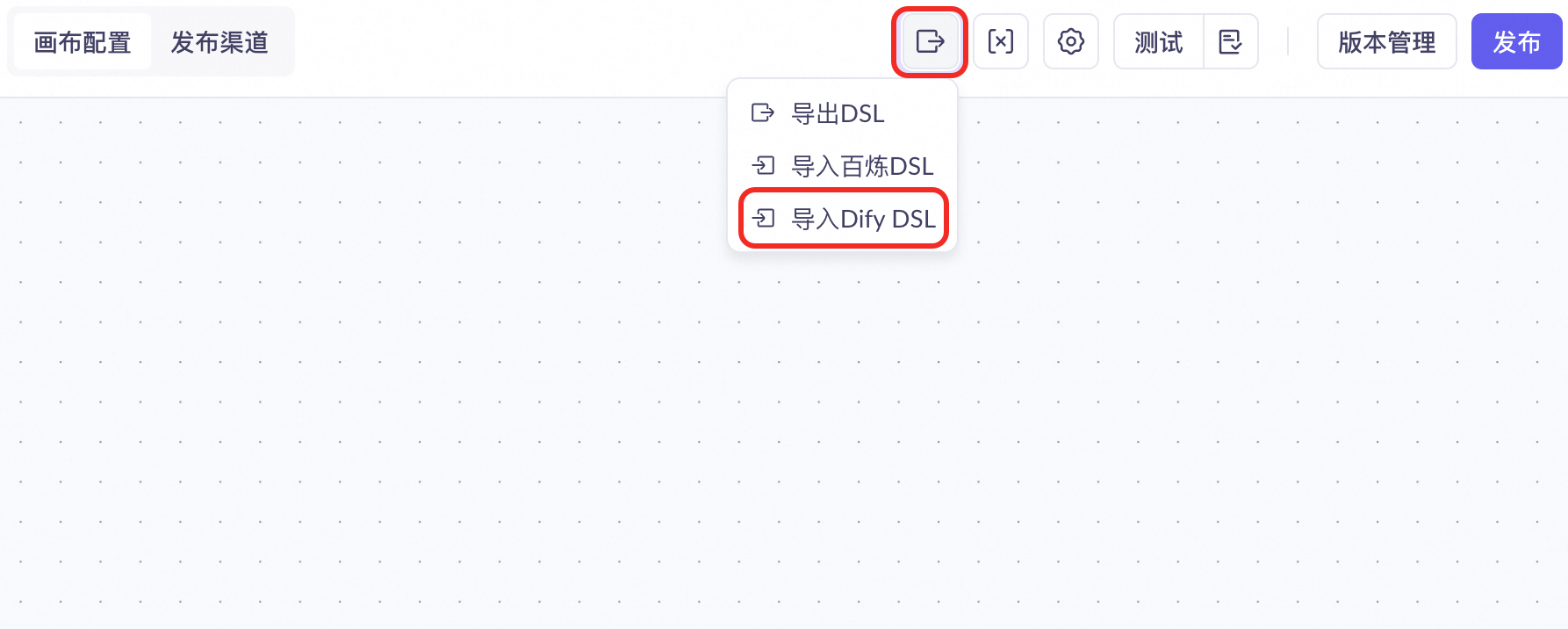
各ノードのパラメーターを調整します。
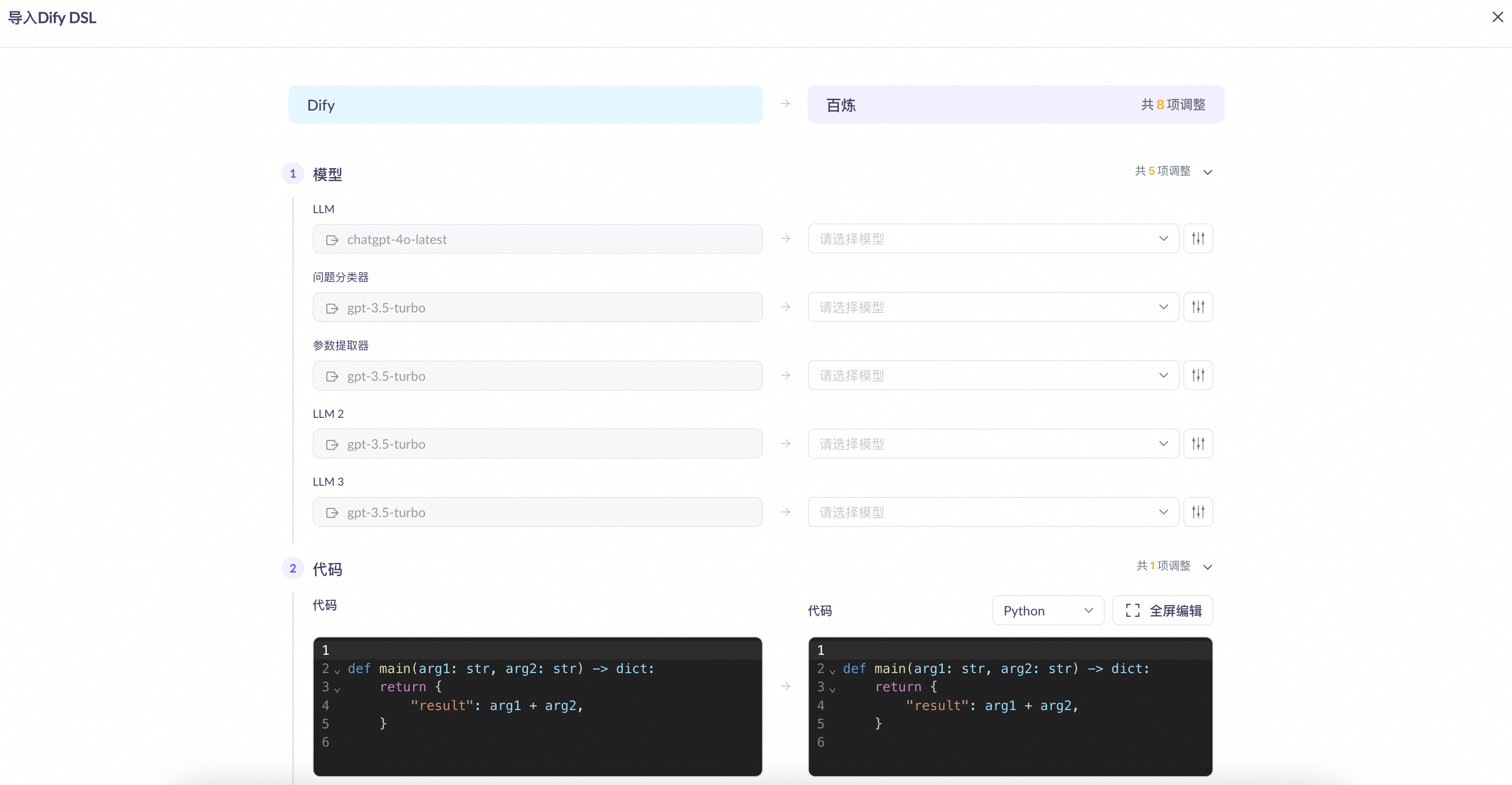
ノードの互換性の詳細は以下のとおりです。
Dify ノード
マップされた Model Studio ノード
互換性
start
start
sys.queryはqueryにマッピングされます。sys.dialogue_countは最大メモリターン数にマッピングされます。
LLM
LLM
モデル:Model Studio は、サポートされていないモデルのモデルフィールドをインポート後にクリアし、手動で選択する必要があります。サポートされているモデルは完全に互換性があります。
プロンプト:Dify のシステムプロンプトは Model Studio のメインプロンプトにマッピングされ、ユーザープロンプトはユーザープロンプトにマッピングされます。
ビジョン機能:完全に互換性があります。
コンテキスト:Model Studio は、Dify のコンテキストからの生フィールドをシステムプロンプトに直接組み込みます。
knowledge retrieval
ナレッジベース
入力:Model Studio は一貫して
contentフィールドを入力として使用します。ナレッジベース:Model Studio はインポート後にこのフィールドをクリアします。Model Studio で手動でナレッジベースを関連付ける必要があります。
取得設定:Dify の
Top-kパラメーターは取得フラグメント数にマッピングされます。
Direct Reply
出力ノード
完全に互換性があります。
agent
なし
名前のみ保持されます。ノードをクリックして、特定の Model Studio ノードを置き換えとして選択する必要があります。
Question Classifier
意図分類
Model Studio は、非対応モデルのモデルフィールドをクリアするため、手動でモデルを選択する必要があります。対応モデルは完全に互換性があります。
Iteration
バッチ処理
入力: Batch Array にマッピングされます。
出力変数: Output Variable にマッピングされます。
loop
loop
完全に互換性があります。
code execution
スクリプト
Model Studio は、Python スクリプトと JavaScript スクリプトを区別します。
Template Transform
なし
互換性がありません。Model Studio はカスタムノードを生成します。
Variable Aggregator
変数処理
Aggregate Groups 出力モードの Variable Processing ノードにマッピングされます。
Document Extractor
なし
互換性がありません。Model Studio はカスタムノードを生成します。
Variable Assignment
変数設定
完全に互換性があります。
Parameter Extractor
パラメーター抽出
Model Studio は推論モードをサポートしていません。その他の機能は完全に互換性があります。
HTTP request
API
完全に互換性がありますが、再認証が必要です。
List Operation
なし
互換性がありません。Model Studio はカスタムノードを生成します。
Tool
プラグイン、MCP
互換性がありません。Model Studio はカスタムノードを生成します。
comment
なし
互換性がありません。
end
end
Dify ワークフローに複数の終了ノードが含まれている場合、Model Studio はそれらを単一の変数処理ノードと単一の終了ノードに変換します。
ワークフローバージョンの管理
|
|
|
|
|
|
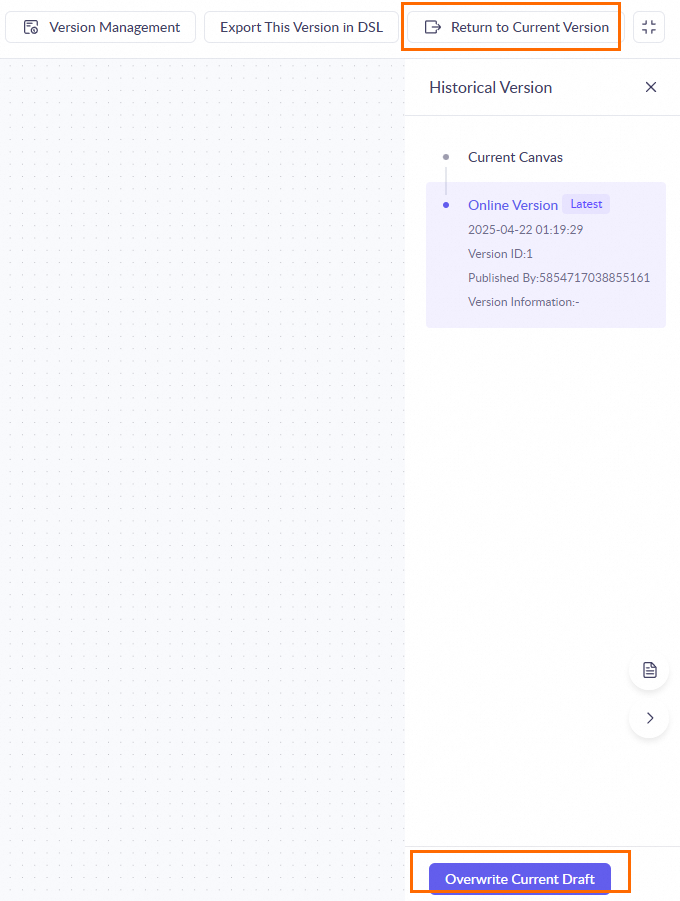
ワークフローアプリケーションの削除とコピー
My Applications で、公開済みのアプリケーションカードを見つけ、 |
|
 アイコンをクリックして、アプリケーションの削除、ワークフローのコピー、アプリケーション名の変更 を行います。
アイコンをクリックして、アプリケーションの削除、ワークフローのコピー、アプリケーション名の変更 を行います。
よくある質問
ワークフローアプリケーション
ワークフロー実行の結果をデータベースに書き込むにはどうすればよいですか?
スクリプト変換ノードを使用して、前のノードからの出力をデータベースに書き込みます。
Model Studio でワークフローアプリケーションを構築する際にファイルをアップロードするにはどうすればよいですか?
ワークフローアプリケーションに API ノードを追加してファイルをアップロードします。
画像をアップロードするにはどうすればよいですか?
VL モデルを使用して、画像 URL をパラメーターとして渡します。
ワークフローアプリケーション内で非同期タスク API を使用できますか?
ワークフローアプリケーションのタイムアウトは 600 秒です。ワークフロー内で非同期タスク API の使用は避けてください。
フロントエンドアプリケーションから Model Studio ワークフロー API を呼び出してストリーミング出力を受信するにはどうすればよいですか?
フロントエンド呼び出しは現在サポートされていません。
スタンドアロンの .yaml ファイルを Model Studio ワークフローにインポートできないのはなぜですか?
Model Studio はスタンドアロンの .yaml ファイルのインポートをサポートしていません。MD5 ファイルを含む圧縮パッケージを提供する必要があります。問題が発生した場合は、MD5 を再生成することをお勧めします。
Model Studio ワークフローの変数名に中国語を使用できますか?
いいえ、変数名に漢字を含めることはできません。
会話履歴はどのように保存されますか?
ワークフローアプリケーションはデータを 1 か月間のみ保存します。会話履歴はご自身で保存する必要があります。
session_idの有効期間は 1 時間です。
ノード
コンテキストを有効にした意図分類ノードが失敗するのはなぜですか?
意図分類ノードでコンテキストを有効にする場合、それに渡す変数はリストである必要があります。
ストリーミング出力を使用した API ノードが失敗するのはなぜですか?
ワークフロー内の API ノードはストリーミング出力をサポートしていません。ただし、基盤となる HTTP API はストリーミング出力をサポートしています。
遅い条件ノードを高速化するにはどうすればよいですか?
ワークフロー構成を確認する:各ノード(特に条件ノード)が正しく構成されていることを確認します。不必要に複雑な計算やデータ処理を避け、応答時間を短縮します。
スクリプトロジックを最適化する:条件ロジックにカスタムスクリプトが含まれている場合、不要なループや冗長なデータ処理を減らしてスクリプトを最適化し、パフォーマンスを向上させます。
バッチテストを実行する:ワークフローの平均応答時間を測定して、特定の条件下でのパフォーマンスボトルネックを特定します。
大規模モデルノードから推論プロセスをストリーミングするにはどうすればよいですか?
大規模モデルノードの後にテキスト変換ノードを追加し、
reasoning_content変数を構成して、結果の返却を有効にする必要があります。終了ノードが結果を受信する必要があります。大規模モデルノードの出力パラメーターをカスタマイズするにはどうすればよいですか?
スクリプトノードを使用して出力を処理する:大規模モデルノードの後にスクリプトノードを追加して、その出力を処理し、目的のフォーマットに変換するか、追加のパラメーターを追加します。
バッチノードを構成する:大規模モデルノードをバッチノード内で使用する場合、バッチノードの構成で大規模モデルノードの出力を最終出力として選択できます。手順は以下のとおりです。
バッチノードに大規模モデルノードを追加します。
バッチノードの構成で、大規模モデルノードの出力を最終出力
resultListとして選択します。
アプリケーションのパラメーター受け渡しをご参照ください。
API ノードが結果を返さない、またはパラメーターを渡せないのはなぜですか?
API キーと Base URL が正しいことを確認します。入力パラメーターが正しく構成されていることを確認し、必要に応じてフィールド入力タイプを調整します。モデル観測を使用してモデル使用量の詳細を確認します。
ナレッジベースから Excel データにアクセスする際に問題が発生した場合はどうすればよいですか?
ローカルファイルに直接アクセスすることはできません。MCP を使用してローカルリソースにアクセスする必要があります。ナレッジベースノードの出力は手動で処理する必要があります。テーブル形式に変換するために、大規模モデルノードを追加して出力を処理し、その後スクリプトノードに渡すことをお勧めします。