このトピックでは、PyODPS DataFrameコードのランタイム環境を確認する方法の概要を説明し、さまざまな環境でのコード実行から生じる一般的な問題に対するソリューションを提供します。
概要
PyODPSは、標準のPythonランタイム環境内で動作するPythonパッケージであり、通常のPythonインタープリターと一貫した動作を保証します。 以下のサンプルコードは、その運用原理とランタイム環境に関する洞察を提供します。
コード例
from odps import ODPS, options import numpy as np o = ODPS(...) df = o.get_table('pyodps_iris').to_df() coeffs = [0.1, 0.2, 0.4] def handle(v): import numpy as np return float(np.cosh(v)) * sum(coeffs) options.df.supersede_libraries = True val = df.sepal_length.map(handle).sum().execute(libraries=['numpy.zip', 'other.zip']) print(np.sinh(val))コード実行システム
以下の図は、簡単にするためにMaxComputeの外部で行われるコード実行に関与するシステムを示しています。以降の説明ではローカルと呼びます。
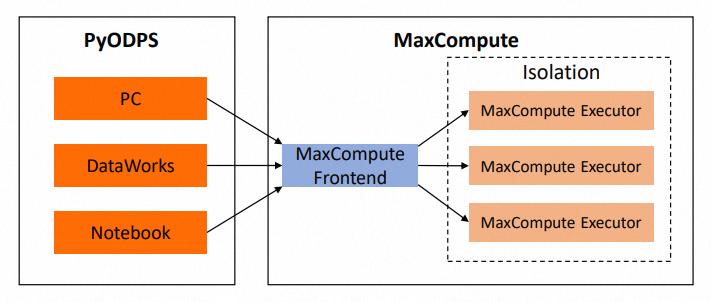
コード分析
第三者のパッケージの参照
ローカルで実行されるコードは、HANDLE関数の外部の要素を含む場合があります。HANDLEがMAPに渡されると、関数自体だけが渡され、その実行は渡されないことに注意することが重要です。 これは、標準のPythonコードの実行方法と同様に動作します。 ローカルパッケージは、サードパーティのライブラリをインポートするときに使用されます。 たとえば、提供されたコードでは、
libraries=['numpy.zip ', 'other.zip']はローカルにインストールされていないother.zipを参照しようとします。 したがって、other.zipがMaxComputeリソースにアップロードされている場合でも、other.zipパッケージがローカルに存在しないため、import otherのようなコマンドは実行エラーにつながります。 ローカルコードにPyODPSパッケージが含まれていない場合、その問題はPyODPSに関連していないため、実行エラーを個別に解決する必要があります。ハンドル関数
HANDLE関数がMAPメソッドに渡され、MaxComputeバックエンドが使用されると、関数は次の手順を実行します。
cloudpickleモジュールは、関数のクロージャとバイトコードを取得します。
PyODPS DataFrameは、クロージャとバイトコードをPython UDFに変換し、MaxComputeに送信します。
MaxComputeでのSQLジョブの実行中に、Python UDFが呼び出され、そのバイトコードとクロージャが逆シリアル化され、UDFがMaxComputeエグゼキュータ内で実行されます。
まとめ
HANDLE関数のコード本体は、ローカルシステムではなく、MaxComputeエグゼキュータによって実行されます。
ローカルシステムにインストールされているパッケージは、HANDLE関数内では使用できません。 MaxCompute executors内のパッケージのみアクセス可能です。
MaxComputeにアップロードされるサードパーティパッケージは、エグゼキュータのPythonバージョン (現在はPython 2.7、UCS2) と互換性がある必要があります。
coeffsなど、HANDLE関数内で参照される外部変数への変更は、オンプレミスシステムの対応する値には影響しません。ハンドル機能外のパッケージをその本体にインポートすると、環境の違いによるエラーが発生する可能性があります。 Cloudpickleは、ローカルパッケージ参照を誤ってMaxComputeエグゼキュータに置き換えることがあります。 これを回避するには、HANDLE関数内でインポートを実行します。
HANDLE関数が別のファイルのコードを参照する場合、ファイルのパッケージがMaxComputeエグゼキュータに存在している必要があります。 サードパーティのパッケージへの依存を回避するには、参照されるすべての個人コードを同じファイルに保持します。
HANDLE関数のガイドラインは、apply、map_reduce、およびカスタム集計関数で使用されるカスタムメソッドと集計クラスにも適用されます。 パンダのバックエンドを使用する場合、すべてのコードがローカルで実行され、対応するパッケージをローカルシステムにインストールする必要があります。 pandasバックエンドでデバッグした後、コードはMaxComputeに転送されて実行されます。 したがって、パッケージをローカルにインストールするときは、MaxComputeバックエンド開発ルールに従うことをお勧めします。
サードパーティパッケージの使用
パーソナルコンピューター /自営サーバー: ローカルで使用するために、対応するPythonバージョンにサードパーティのパッケージをインストールします。
ノートブック: サードパーティパッケージを使用するローカルコードについては、プラットフォームプロバイダーを参照してください。
DataWorks: サードパーティのパッケージをローカルにインストールすることはできませんが、DataWorks環境内で呼び出すことはできます。 他のファイルのコードの場合は、ファイルの読み取りと
execコマンドを組み合わせてローカルで実行します。 詳細については、PyODPSノードに関する参照ドキュメントをご参照ください。重要DataStudioのフォルダー構造は、ファイルシステムの実際の部分ではありません。 インポートまたは直接オープンしようとすると、実行に失敗します。
DataWorksにリソースをアップロードした後、[送信] をクリックして、正しくODPSに転送されていることを確認します。
カスタムバージョンのNumPyを使用する場合は、適切なホイールパッケージをアップロードし、
odps.df.supersede_libraries = Trueを設定して、アップロードしたNumPyパッケージをライブラリの最初のパラメーターとして優先順位付けします。
他のMaxComputeテーブルの参照データ
パーソナルコンピューター /自己所有サーバー /ノートブック /DataWorks: エンドポイントに到達可能な場合、PyODPS/DataFrameを使用してMaxComputeテーブルにローカルでアクセスします。 エンドポイントへのアクセスが不可能な場合は、プラットフォームプロバイダーに支援を求めます。
map/apply/map_reduce/custom aggregation: これらのコンテキストで他のMaxComputeテーブルにアクセスすることは、通常、エンドポイントまたはトンネルエンドポイントに接続できず、PyODPSパッケージがないMaxCompute executorsではサポートされていません。 したがって、ODPSエントリオブジェクトまたはPyODPS DataFrameを直接利用することも、カスタム関数の外部からこれらのオブジェクトを渡すこともできません。 小さなデータセットの場合は、DataFrameをリソースとして渡すことを検討してください。 詳細については、「参照ドキュメント」をご参照ください。 大きなデータセットの場合は、テーブル結合をお勧めします。