MaxCompute Graphは、反復グラフ計算用に設計された処理フレームワークです。 グラフ計算ジョブでは、グラフを使ってモデルが構築されます。 グラフは、値を持つ頂点とエッジのコレクションです。 MaxCompute Graphが提供するSDK for Javaを使用して、グラフコンピューティングプログラムを作成できます。
MaxCompute Graphでは、グラフに対して次の操作を実行できます。
頂点またはエッジの値を変更します。
頂点を追加または削除します。
エッジを追加または削除します。
頂点またはエッジを編集するときは、頂点とエッジの関係を維持するためのコードを使用する必要があります。
MaxCompute Graphは、イテレーションを実行してグラフを編集し、グラフを進化させ、分析結果を取得します。 典型的なアプリケーションには、PageRank、単一ソース最短パス (SSSP) アルゴリズム、およびk-meansアルゴリズムが含まれます。 MaxCompute Graphが提供するSDK for Javaを使用して、グラフ計算プログラムをコンパイルできます。
用語
グラフ: オブジェクト間の関係を表すために使用される抽象データ構造。 頂点とエッジはグラフで使用されます。 頂点はオブジェクトを表し、エッジはオブジェクト間の関係を表します。 グラフに記述されたデータをグラフデータと呼ぶ。
Vertex: グラフ内のオブジェクトを表します。
エッジ: グラフ内のオブジェクト間の関係を表す単一の有向エッジ。 エッジは、ソース頂点ID、宛先頂点ID、およびエッジに関連するデータからなる。
有向グラフ: エッジが方向を有するグラフ。 エッジ上の2つの頂点は、異なるオブジェクトを表す。 例えば、ページAはページBに接続されている。有向グラフでは、エッジは出て行くエッジと入ってくるエッジに分類される。
無向グラフ: ユーザーグループ内の一般的なユーザーなど、エッジに方向がないグラフ。
出力エッジ: 現在の頂点が原点である有向エッジ。
着信エッジ: 現在の頂点が宛先である有向エッジ。
度: 頂点に接続するエッジの数。
Outdegree: 頂点に接続する出力エッジの数。
Indegree: 頂点に接続する入力エッジの数。
スーパーステップ: グラフの反復。
グラフデータ構造
MaxCompute Graphは有向グラフを処理します。 MaxComputeは、2次元のテーブルストレージ構造のみを提供します。 したがって、グラフデータを2次元のテーブルに解決し、MaxComputeに保存する必要があります。 ビジネス要件に基づいてグラフデータを解決できます。
グラフの計算と分析中に、カスタムGraphLoaderを使用して、2次元テーブルデータをMaxCompute graphに適用可能な頂点とエッジに変換します。
頂点の構造は <ID, 値, Halted, Edges> です。 パラメーター:
ID: 頂点のID。
値: 頂点の値。
Halted: 頂点の反復を終了するかどうかを指定します。
エッジ: 頂点から始まるエッジ。
エッジの構造は <DestVertexID, Value> です。 パラメーター:
DestVertexID: 宛先頂点のID。
値: エッジの値。
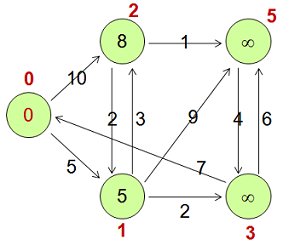 たとえば、上の図は次の2次元テーブルで表すことができます。
たとえば、上の図は次の2次元テーブルで表すことができます。
頂点 | <ID、値、停止、エッジ> |
v0 | <0, 0, false, [<1,5>, <2,10>]> |
v1 | <1, 5, false, [<2,3>, <3,2>, <5,9>]> |
v2 | <2, 8, false, [<1, 2>, <5, 1 >]> |
v3 | <3, Long.MAX_VALUE, false, [<0, 7>, <5, 6>]> |
v5 | <5, Long.MAX_VALUE, false, [<3, 4 >]> |
Graphプログラムのロジック
グラフプログラムは、グラフロード、反復計算、および反復終了の操作を実行します。
グラフの読み込み。
グラフの読み込みは、次の手順で構成されます。
グラフの読み込み: MaxCompute GraphはカスタムGraphLoaderを呼び出して、入力テーブルのレコードを頂点またはエッジに解決します。
パーティショニング: MaxCompute Graphは、カスタムのPartitionerを呼び出して頂点をパーティション分割し、パーティションを関連するワーカーに配布します。 デフォルトでは、MaxCompute Graphは、ワーカーの数を法とする頂点IDのハッシュ値に基づいて頂点を分割します。
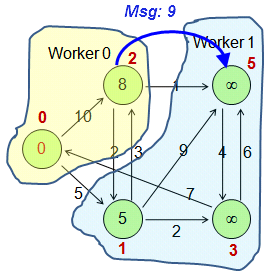 上の図では、ワーカーの数は2です。 頂点0と頂点2は、頂点IDモジュロ2の結果が0であるため、Worker 0に分散されます。 頂点1、頂点3、および頂点5は、頂点IDモジュロ2の結果が1であるため、Worker 1に分散される。
上の図では、ワーカーの数は2です。 頂点0と頂点2は、頂点IDモジュロ2の結果が0であるため、Worker 0に分散されます。 頂点1、頂点3、および頂点5は、頂点IDモジュロ2の結果が1であるため、Worker 1に分散される。反復コンピューティング。
反復はスーパーステップと呼ばれます。 反復中、プログラムは、停止されていないすべての頂点またはメッセージを受信するすべての頂点をトラバースし、
compute(ComputeContextコンテキスト、反復可能メッセージ)メソッドを呼び出します。 停止していない頂点の場合、haltedパラメーターの値はfalseです。 停止した頂点は、メッセージを受信すると自動的にアクティブになります。compute(ComputeContext context, Iterable messages)メソッドを使用して、次の操作を実行できます。前のスーパーステップによって現在の頂点に送信されたメッセージを処理します。
必要に応じてグラフを編集する:
頂点またはエッジの値を変更します。
いくつかの頂点にメッセージを送信します。
頂点またはエッジを追加または削除します。
アグリゲーターを使用して情報を収集し、グローバル情報を更新します。 詳細については、「Aggregator実装メカニズム」をご参照ください。
現在の頂点を停止状態または非停止状態に設定します。
MaxCompute Graphを有効にして、各スーパーステップで関連するワーカーにメッセージを非同期で送信します。 メッセージは次のスーパーステップで処理されます。
反復終了。
次の条件の1つ以上が満たされると、イテレーションは終了します。
すべての頂点は停止状態にあり (haltedパラメーターの値はtrue) 、新しいメッセージは生成されません。
反復の最大数に達した。
アグリゲータの
terminateメソッドはtrueを返します。
Graphプログラムの疑似コード:
// 1. load for each record in input_table { GraphLoader.load(); } // 2. setup WorkerComputer.setup(); for each aggr in aggregators { aggr.createStartupValue(); } for each v in vertices { v.setup(); } // 3. superstep for (step = 0; step < max; step ++) { for each aggr in aggregators { aggr.createInitialValue(); } for each v in vertices { v.compute(); } } // 4. cleanup for each v in vertices { v.cleanup(); } WorkerComputer.cleanup();