MaxComputeでは、ユーザー定義のテーブル値関数 (UDTF) をJavaで記述できます。 これにより、複雑なデータ処理タスクを効率的に処理できます。 Java UDTFは、特定のデータ処理要件をより適切に満たし、Javaの特性に基づいて開発効率と処理パフォーマンスを向上させることができます。 このトピックでは、UDTFのコード構造、注意事項、および例について説明します。
UDTFコード構造
IntelliJ IDEAまたはMaxCompute StudioでMavenを使用して、UDTFコードをJavaで記述できます。 UDTFコードには、次の情報を含めることができます。
Javaパッケージ: オプション。
定義されているJavaクラスは、今後使用するためにJARファイルにパッケージ化できます。
基本UDTFクラス: 必須。
com.aliyun.odps.udf.UDTF、com.aliyun.odps.udf.annotation.Resolve、およびcom.aliyun.odps.udf.UDFExceptionの基本UDTFクラスを含める必要があります。 com.aliyun.odps.udf.annotation.Resolveは@ Resolveアノテーションを指定し、com.aliyun.odps.udf.UDFExceptionはJavaクラスの実装に使用されるメソッドを指定します。 他のUDTFクラスまたは複合データ型を使用する必要がある場合は、[概要] の手順に従って必要なクラスを追加します。カスタムJavaクラス: 必須。
カスタムクラスは、UDTFコードの組織単位です。 このクラスは、ビジネス要件を満たすために使用される変数とメソッドを定義します。
@ Resolveアノテーション: 必須です。アノテーションは
@ Resolve(<signature>)形式です。signatureは、入力パラメーターのデータ型とUDTFの戻り値を定義する関数シグネチャです。 リフレクション機能を使用してUDTFの関数シグネチャを取得することはできません。 関数シグネチャは、@ Resolve("smallint->varchar(10)")などの@ Resolveアノテーションを使用してのみ取得できます。@ Resolveアノテーションの詳細については、このトピックの「 @ Resolveアノテーション」をご参照ください。カスタムJavaクラスを実装するメソッド: required.
次の表に、Javaクラスの実装に使用できるメソッドを示します。 ビジネス要件に基づいていずれかの方法を選択できます。
移動方法
説明
public void setup(ExecutionContext ctx) throws UDFException初期化メソッド。 UDTFが入力データを処理する前に、MaxComputeはユーザー定義の初期化動作のコードを呼び出します。
setupは、ワーカーごとに1回呼び出されます。public void process(Object[] args) throws UDFExceptionprocessは、SQLレコードごとに1回呼び出されます。processのパラメーターは、SQL文で指定されたUDTFの入力パラメーターです。 入力パラメーターはObject[]としてプロセス関数に渡され、結果はforward関数を使用して返されます。 出力データを決定するには、process関数のforward関数を呼び出す必要があります。説明processまたはcloseメソッドを使用してforward関数を呼び出さないと、データ損失が発生する可能性があります。 作業は慎重に行ってください。 例えば、バックエンドスレッドは、forwardコールを実行するために使用される。forward呼び出しが完了するまでprocessメソッドが完了しないようにする必要があります。完了しないと、データが失われる可能性があります。public void close() throws UDFExceptionUDTFを終了するメソッド。 このメソッドは一度だけ呼び出されます。 最後のレコードが処理された後にのみ呼び出されます。
forward関数を呼び出してデータを返すことができます。forward関数が呼び出されるたびに1つのレコードが生成されます。 SQLクエリステートメントでUDTFを呼び出す場合、AS句を使用してforward関数の出力の名前を変更できます。Javaデータ型またはJava書き込み可能型を使用して、Java UDTFを記述できます。 MaxComputeプロジェクトでサポートされているデータ型、Javaデータ型、およびJava書き込み可能型間のマッピングの詳細については、「データ型」をご参照ください。
次の例は、UDTFコードを示しています。
// Package Java classes into a JAR file named org.alidata.odps.udtf.examples.
package org.alidata.odps.udtf.examples;
// The base UDTF classes.
import com.aliyun.odps.udf.UDTF;
import com.aliyun.odps.udf.UDTFCollector;
import com.aliyun.odps.udf.annotation.Resolve;
import com.aliyun.odps.udf.UDFException;
// The custom Java class.
// The @Resolve annotation.
@Resolve("string,bigint->string,bigint")
public class MyUDTF extends UDTF {
// The methods that are used to implement the custom Java class.
@Override
public void process(Object[] args) throws UDFException {
String a = (String) args[0];
Long b = (Long) args[1];
for (String t: a.split("\\s+")) {
forward(t, b);
}
}
}制限事項
ユーザー定義関数 (UDF) を使用してインターネットにアクセスすることはできません。 UDFを使用してインターネットにアクセスする場合は、ビジネス要件に基づいてネットワーク接続申請フォームに入力し、申請書を送信します。 申請が承認された後、MaxComputeテクニカルサポートチームがお客様に連絡し、ネットワーク接続の確立を支援します。 ネットワーク接続申請フォームへの記入方法の詳細については、「ネットワーク接続プロセス」をご参照ください。
SELECTステートメントでUDTFを使用する場合、このステートメントで他の列を指定したり、他の式を使用したりすることはできません。 次のサンプルコードは、誤ったSQL文を示しています。-- The statement contains a UDTF and another column. select value, user_udtf(key) as mycol ...UDTFはネストできません。 次のサンプルコードは、誤ったSQL文を示しています。
-- A UDTF named user_udtf2 is nested in a UDTF named user_udtf1. select user_udtf1(user_udtf2(key)) as mycol...;UDTFは、同じ
SELECTステートメントのGROUP BY、DISTRIBUTE BY、またはSORT BY句では使用できません。 次のサンプルコードは、誤ったSQL文を示しています。-- A UDTF is used together with a GROUP BY clause. select user_udtf(key) as mycol ... group by mycol;
注意事項
Java UDTFを作成するときは、次の点に注意してください。
同じ名前でロジックが異なるクラスを、異なるUDTFのJARファイルにパッケージ化しないことをお勧めします。 たとえば、UDTF1のJARファイルの名前はudtf1.jar、UDTF2のJARファイルの名前はudtf2.jarです。 どちらのファイルにも
com.aliyun.UserFunction.classという名前のクラスが含まれていますが、クラスのロジックは異なります。 UDTF 1とUDTF 2が同じSQL文で呼び出された場合、MaxComputeは2つのファイルのいずれかからcom.aliyun.UserFunction.classを読み込みます。 その結果、UDTFは期待どおりに実行できず、コンパイルエラーが発生する可能性があります。Java UDTFの入力パラメーターまたは戻り値のデータ型はオブジェクトです。 Java UDTFコードで指定するデータ型の最初の文字は、Stringなどの大文字である必要があります。
MaxCompute SQLのNULL値は、JavaではNULLで表されます。 MaxCompute SQLでは、Javaのプリミティブデータ型はNULL値を表すことができません。 したがって、これらのデータ型は使用できません。
@ Resolveアノテーション
注釈形式 @ Resolve:
@Resolve(<signature>)signatureは関数署名文字列です。 このパラメーターは、入力パラメーターと戻り値のデータ型を識別するために使用されます。 UDTFを実行する場合、UDTFの入力パラメーターと戻り値は、関数シグネチャで指定されたものと同じデータ型である必要があります。 データ型の整合性は、セマンティック解析中にチェックされます。 データ型に矛盾がある場合は、エラーが返されます。 署名の形式は次のとおりです。
'arg_type_list -> type_list'パラメーターの説明:
type_list: 戻り値のデータ型を示します。 UDTFは複数の列を返すことができます。 BIGINT、STRING、DOUBLE、BOOLEAN、DATETIME、DECIMAL、FLOAT、BINARY、DATE、DECIMAL(precision、scale) のデータ型がサポートされています。 ARRAY、MAP、STRUCTなどの複雑なデータ型、およびネストされた複雑なデータ型もサポートされています。arg_type_list: 入力パラメーターのデータ型を指定します。 複数の入力パラメーターを使用する場合は、複数のデータ型を指定し、コンマ (,) で区切ります。 BIGINT、STRING、DOUBLE、BOOLEAN、DATETIME、DECIMAL、FLOAT、BINARY、DATE、DECIMAL(precision、scale) 、CHAR、VARCHAR、複合データ型 (ARRAY、MAP、STRUCT) 、およびネストされた複合データ型がサポートされています。arg_type_listは、アスタリスク (*) または空のまま ('') で表すことができます。arg_type_listがアスタリスク (*) で表される場合、ランダムな数の入力パラメーターが許可されます。arg_type_listが空 ('') の場合、入力パラメーターは使用されません。
@ Resolveアノテーションの構文拡張機能の詳細については、「UDAFおよびUDTFの動的パラメーター」をご参照ください。
次の表に、@ Resolveアノテーションの例を示します。
@Resolve annotation | 説明 |
| 入力パラメーターのデータ型はBIGINTとBOOLEANです。 戻り値のデータ型はSTRINGとDATETIMEです。 |
| ランダムな数の入力パラメーターが使用され、戻り値のデータ型はSTRINGとDATETIMEです。 |
| 入力パラメーターは使用されず、戻り値のデータ型はDOUBLE、BIGINT、STRINGです。 |
| 入力パラメータのデータ型は、ARRAY、STRUCT、およびMAPである。 戻り値のデータ型はMAPとSTRUCTです。 |
データ型
MaxComputeでは、異なるデータ型エディションが異なるデータ型をサポートします。 MaxCompute V2.0以降では、ARRAY、MAP、STRUCTなど、より多くのデータ型と複雑なデータ型がサポートされています。 MaxComputeデータ型のエディションの詳細については、「データ型のエディション」をご参照ください。
次の表に、MaxComputeプロジェクトでサポートされているデータ型、Javaデータ型、およびJava書き込み可能型の間のマッピングを示します。 データ型の一貫性を確保するには、マッピングに基づいてJava UDTFを記述する必要があります。 次の表に、データ型のマッピングについて説明します。
MaxComputeタイプ | Javaタイプ | Java書き込み可能タイプ |
TINYINT | java.lang.Byte | ByteWritable |
SMALLINT | java.lang.Short | ShortWritable |
INT | java.lang.Integer | IntWritable |
BIGINT | java.lang.Long | LongWritable |
FLOAT | java.lang.Float | FloatWritable |
DOUBLE | java.lang.Double | DoubleWritable |
DECIMAL | java.math.BigDecimal | BigDecimalWritable |
BOOLEAN | java.lang.Boolean | BooleanWritable |
STRING | java.lang.String | Text |
VARCHAR | com.aliyun.odps.data.Varchar | VarcharWritable |
BINARY | com.aliyun.odps.data.Binary | BytesWritable |
DATE | java.sql.Date | DateWritable |
DATETIME | java.util.Date | DatetimeWritable |
TIMESTAMP | java.sql.Timestamp | TimestampWritable |
INTERVAL_YEAR_MONTH | 非該当 | IntervalYearMonthWritable |
INTERVAL_DAY_TIME | 非該当 | IntervalDayTimeWritable |
ARRAY | java.util.List | 非該当 |
MAP | java.util.Map | 非該当 |
STRUCT | com.aliyun.odps.data.Struct | 非該当 |
MaxComputeプロジェクトがMaxCompute V2.0データ型エディションを使用している場合にのみ、UDTFの入力パラメーターまたは戻り値にJava書き込み可能型を使用できます。
注意事項
[開発プロセス] の手順に従ってJava UDTFを開発した後、MaxCompute SQLを使用してJava UDTFを呼び出すことができます。 次のいずれかのメソッドを使用して、Java UDTFを呼び出すことができます。
MaxComputeプロジェクトでUDFを使用する: この方法は、組み込み関数を使用する方法と似ています。
プロジェクト間でUDFを使用する: プロジェクトaでプロジェクトBのUDFを使用します。次のステートメントは、例を示します。
select B:udf_in_other_project(arg0, arg1) as res from table_t;プロジェクト間共有の詳細については、「パッケージに基づくプロジェクト間リソースアクセス」をご参照ください。
MaxCompute Studioを使用してJava UDTFを開発および呼び出す方法の詳細については、「例」をご参照ください。
例:
この例では、MaxCompute Studioを使用してJava UDTFを開発し、呼び出す方法について説明します。
準備をします。
MaxCompute Studioを使用してUDFを開発およびデバッグする前に、MaxCompute Studioをインストールし、MaxCompute StudioをMaxComputeプロジェクトに接続する必要があります。 MaxCompute Studioをインストールし、MaxCompute StudioをMaxComputeプロジェクトに接続する方法の詳細については、以下のトピックを参照してください。
UDTFコードを書きます。
[Project] タブの左側のナビゲーションウィンドウで、 を選択し、[java] を右クリックして、 を選択します。
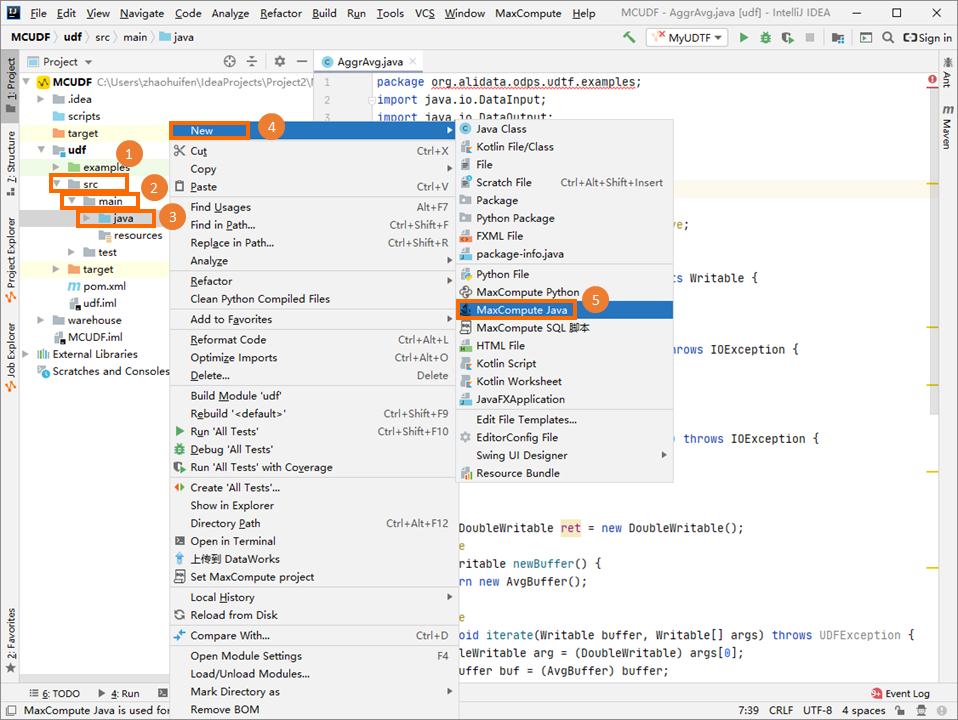
[新しいMaxCompute javaクラスの作成] ダイアログボックスで、[UDTF] をクリックし、[名前] フィールドに名前を入力してから、enterキーを押します。 この例では、Javaクラスの名前はMyUDTFです。
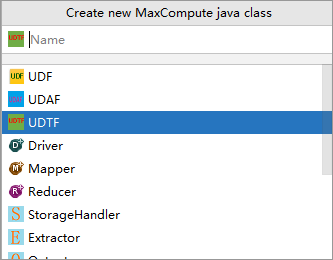
Name: MaxCompute Javaクラスの名前。 パッケージを作成していない場合は、このパラメーターをpackagename.classname形式で指定します。 システムは自動的にパッケージを生成します。
コードエディターでコードを記述します。
 次の例は、UDTFコードを示しています。
次の例は、UDTFコードを示しています。 package org.alidata.odps.udtf.examples; import com.aliyun.odps.udf.UDTF; import com.aliyun.odps.udf.UDTFCollector; import com.aliyun.odps.udf.annotation.Resolve; import com.aliyun.odps.udf.UDFException; // TODO define input and output types, e.g., "string,string->string,bigint". @Resolve("string,bigint->string,bigint") public class MyUDTF extends UDTF { @Override public void process(Object[] args) throws UDFException { String a = (String) args[0]; Long b = (Long) args[1]; for (String t: a.split("\\s+")) { forward(t, b); } } }
オンプレミスマシンでUDTFをデバッグして、コードが正常に実行できるようにします。
デバッグ操作の詳細については、「ローカル実行を実行してUDFをデバッグする」をご参照ください。
 説明
説明前の図のパラメーター設定は参考用です。
作成したUDTFをJARファイルにパッケージ化し、そのファイルをMaxComputeプロジェクトにアップロードしてから、UDTFを登録します。 この例では、関数名は
user_udtfです。UDTFをパッケージ化する方法の詳細については、「手順」をご参照ください。
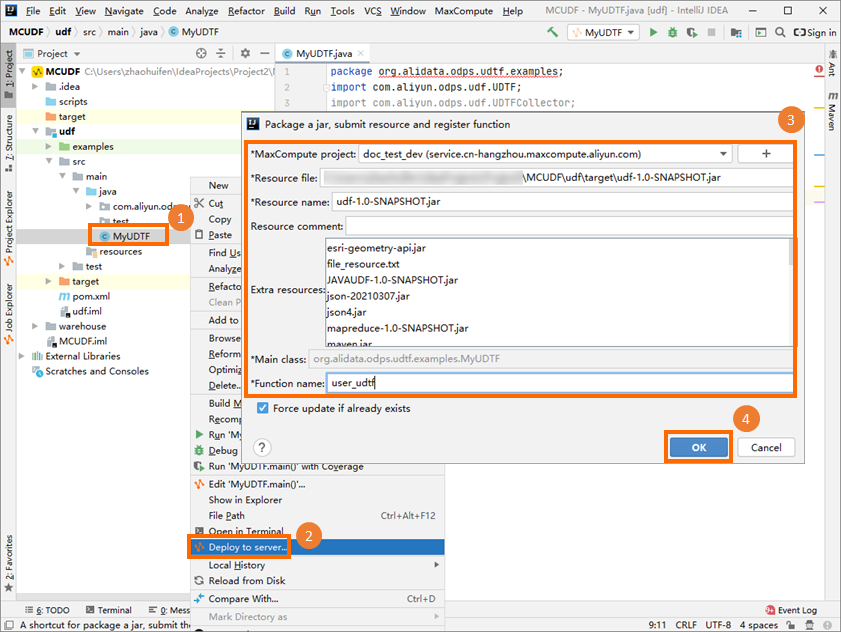
MaxCompute Studioの左側のナビゲーションウィンドウで、[Project Explorer] をクリックします。 MaxComputeプロジェクトを右クリックし、ドロップダウンリストから [コンソールで開く] を選択してMaxComputeクライアントを起動し、SQL文を実行して新しいUDTFを呼び出します。
次の例は、クエリするmy_tableテーブルのデータ構造を示しています。
+------------+------------+ | col0 | col1 | +------------+------------+ | A B | 1 | | C D | 2 | +------------+------------+次のSQL文を実行してUDTFを呼び出します。
select user_udtf(col0, col1) as (c0, c1) from my_table;次の応答が返されます。
+----+------------+ | c0 | c1 | +----+------------+ | A | 1 | | B | 1 | | C | 2 | | D | 2 | +----+------------+
関連ドキュメント
Java UDTFの使用方法の詳細については、「Java UDTFの例」をご参照ください。