デルタテーブルは、増分データの書き込みと保存をサポートします。 効率的な増分クエリおよびコンピューティング最適化を目的として、新しいSQL増分クエリ構文は、ほぼリアルタイムの増分処理リンクをサポートするように設計されています。
増分クエリのプロセス
次の図は、Deltaテーブルの増分クエリのプロセスを示しています。
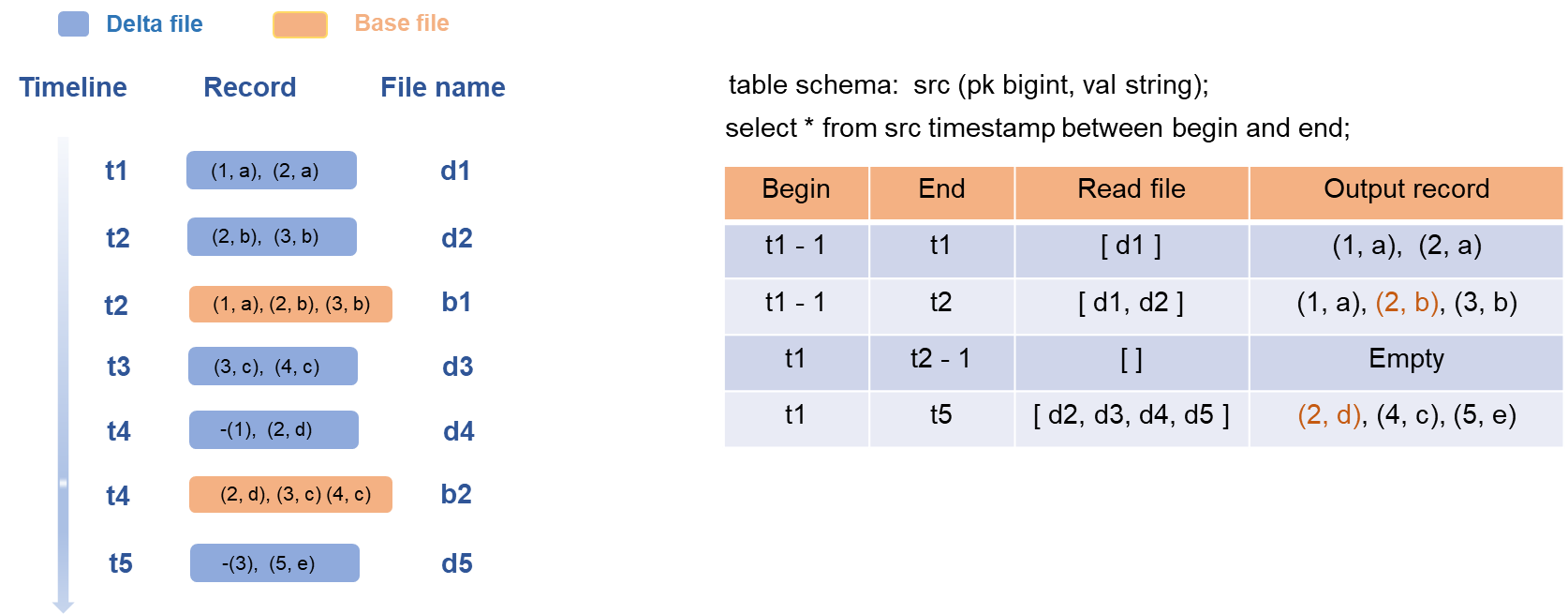
SQL文を入力すると、エンジンは指定されたバージョン範囲を解析して、指定された時間範囲内のすべてのデルタファイルを照会します。 次に、エンジンはデルタファイル内のデータをマージして出力を生成します。
クラスタリングおよびコンパクション操作中に新しいデータファイルが生成されます。 新しいデータファイルでは、元のレコードが編成され、最適化され、新しい論理レコードは追加されません。 したがって、新しいデータファイル内のレコードは、出力のための新しいデータと見なされるべきではない。 増分クエリは、ビジネス要件を満たすように最適化されます。 最適化後、コンパクションおよびクラスタリング中に生成されたレコードは、増分クエリから除外されます。 したがって、MaxComputeは増分クエリ中にベースファイルを読み取りません。 代わりに、MaxComputeは指定された時間範囲内のすべてのデルタファイルのみを読み取り、指定されたポリシーに基づいてデルタファイル内のデータをマージして出力を生成します。
上の図は、srcという名前のトランザクションテーブルのデータを照会する方法を示しています。
テーブルのスキーマは、pk列とval列で構成されます。
上の図の左側は、データ変更プロセスを示しています。 時刻t1〜t5は、トランザクションの時刻バージョンを表す。 5つのデータ書き込みトランザクションが実行され、5つのデルタファイルが生成される。
時刻t2, t4でコンパクションが行われ、2つのベースファイルb1, b2が生成される。
この例では、Begin列の値がt1-1で、End列の値がt1の場合、MaxComputeはt1でデルタファイルd1のみを読み取って出力を生成する必要があります。 Begin列の値がt2の場合、MaxComputeは2つのデルタファイルd1とd2を読み取る必要があります。 Begin列の値がt1で、End列の値がt2-1の場合、クエリ時間範囲は (t1, t2) です。 この場合、時間範囲内で増分データが挿入されないため、空の行が返されます。