Centauri は Proxima CE の前身です。このトピックでは、データ規模を拡大する 3 つのテストシナリオにおいて、Centauri と Proxima CE (ハッシュシャーディングおよびクラスターシャーディング) を比較したベンチマークデータを示します。
データ規模別のメソッドの可用性
データ規模が大きくなると、すべてのメソッドが正常に完了するわけではありません。シナリオの詳細を読む前に、このまとめをご確認ください。
データ規模 | Centauri | Proxima CE のハッシュシャーディング | Proxima CE のクラスターシャーディング |
1 億レコード | 完了 | 完了 | 未テスト |
10 億レコード | 完了 | 完了 | 完了 |
16 億レコード | 失敗 (シークフェーズでメモリ不足) | 失敗 (出力が一時テーブルの制限を超過) | 完了 |
16 億レコードのデータ規模では、Proxima CE のクラスターシャーディングのみがすべてのフェーズを完了します。
本結果の読み方
各テストシナリオでは、最大 3 つのパイプラインフェーズを測定します。すべてのメソッドにすべてのフェーズが適用されるわけではありません。
フェーズ | 説明 | 適用対象 |
K-means | doc テーブルからクラスター重心テーブルを計算します | Proxima CE のクラスターシャーディングのみ |
自動チューニング | インデックス作成アルゴリズムの最適パラメーターを計算します | Centauri のみ |
ビルド | ベクターインデックスを構築します | すべてのメソッド |
シーク | 類似性検索を実行します | すべてのメソッド |
シナリオ 1:1 億件の BINARY レコード、512 次元
テスト構成
パラメーター | 値 |
doc テーブルのレコード | 100,000,000 |
クエリテーブルのレコード | 100,000,000 |
データ型 | BINARY |
次元 | 512 |
検索構成 | 50 行 x 4 列 |
列ごとのレコード数 (インデックス構築) | 25,000,000 |
検索メソッド | graph |
距離メジャー | ハミング |
結論
Proxima CE のハッシュシャーディングは、全体として Centauri よりも約 20% 高速です。Centauri は top-200 で 98.061% の取得率を達成しています。
メソッド | 自動チューニング (秒) | ビルドフェーズ | シークフェーズ (秒) | 合計時間 (分) |
Centauri | 1,524 | 12,653 | 5,914 | 336 |
Proxima CE のハッシュシャーディング | — | 9,647 | 6,431 | 268 |
K-means は Proxima CE のクラスターシャーディングにのみ適用されます。自動チューニングは Centauri にのみ適用されます。
ビルドフェーズの結果
Centauri 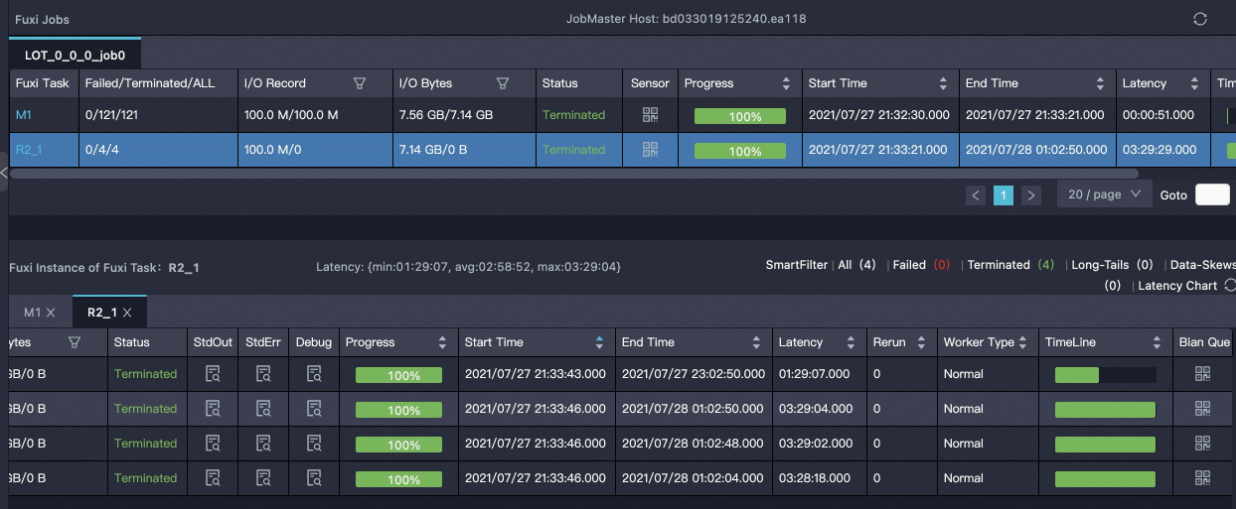
Proxima CE のハッシュシャーディング 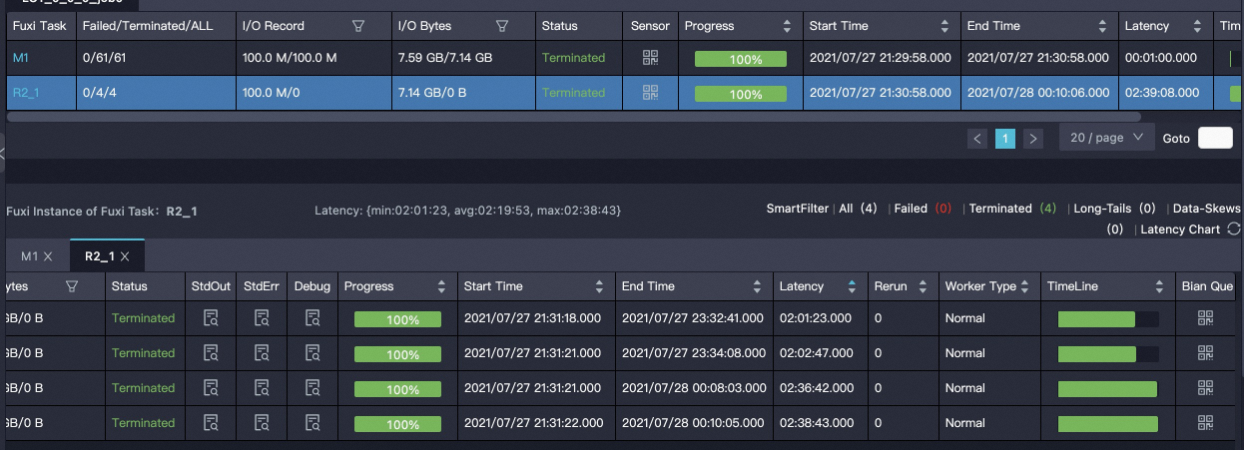
結果分析: Centauri では、1 つのノードが非常に高速でインデックスを構築し、残りの 3 つのノードはほぼ同じ時間がかかります。Proxima CE のハッシュシャーディングでは、2 つのノードが高速で構築し、他の 2 つは比較的低速で構築します。
シークフェーズの結果
Centauri 
Proxima CE のハッシュシャーディング 
結果分析:
ノードごとのインデックスシーク時間は、Centauri と Proxima CE のハッシュシャーディングで同等です。
Proxima CE のハッシュシャーディングでは、結果のマージに約 12 分長くかかります:
Proxima CE のハッシュシャーディング:最速ノードで 8 分、最遅ノードで 20 分
Centauri:最速ノードで 4 分、最遅ノードで 9 分
実行詳細
Centauri
Vector search Data type:BINARY , Vector dimension:512 , Search method:graph , Measure:hamming , Building mode:build:seek
Information about the doc table Table name: doc_table_pailitao_binary , Partition:20210712 , Number of data records in the doc table:100000000 , Vector delimiter:~
Information about the query table Table name: doc_table_pailitao_binary , Partition:20210712 , Number of data records in the query table: 100000000 , Vector delimiter:~
Information about the output table Table name: output_table_pailitao_binary_centauri , Partition:20210712
Row and column information Number of rows: 50 , Number of columns:4 , Number of data records in the doc table of each column for index building:25000000
Whether to clear volume indexes:false
Time required for each worker node (seconds):
worker:TmpDataTableJoinWorker , times:0
worker:TmpTableWorker , times:16
worker:CleanUpWorker , times:4
worker:AutotuningFastWorker , times:46
worker:RowColWorker , times:53
worker:SeekJobWorker , times:5914
worker:BuildJobWorker , times:12653
worker:AutotuningNormalWorker , times:1478
Total time required (minutes):336
Top recall rate User setting train:
top200:0.95
Top recall rate normal train:
top200:98.061%
Autotuning Fast Build Params:
proxima.general.builder.memory_quota=0
proxima.graph.common.max_doc_cnt=27500000
proxima.general.builder.thread_count=15
proxima.hnsw.builder.efconstruction=400
proxima.graph.common.neighbor_cnt=100
Autotuning Normal Search Params:
proxima.hnsw.searcher.ef=400
Sample commands:
jar -resources centauri-1.1.5.jar,libcentauri-1.1.5.so -classpath /data/jiliang.ljl/centauri_1.1.5/centauri-1.1.5.jar
com.alibaba.proxima.CentauriRunner
-proxima_version 1.1.5
-doc_table doc_table_pailitao_binary -doc_table_partition 20210712
-query_table doc_table_pailitao_binary -query_table_partition 20210712
-output_table output_table_pailitao_binary_centauri -output_table_partition 20210712
-data_type binary -dimension 512 -app_id 201220 -pk_type int64 -clean_build_volume false -distance_method hamming -binary_to_int true -row_num 50 -column_num 4;Proxima CE のハッシュシャーディング
Vector search Data type:1 , Vector dimension:512 , Search method:hnsw , Measure:Hamming , Building mode:build:build:seek
Information about the doc table Table name: doc_table_pailitao_binary2 , Partition:20210712 , Number of data records in the doc table:100000000 , Vector delimiter:~
Information about the query table Table name: doc_table_pailitao_binary2 , Partition:20210712 , Number of data records in the query table:100000000 , Vector delimiter:~
Information about the output table Table name: output_table_pailitao_binary_ce , Partition:20210712
Row and column information Number of rows: 50 , Number of columns:4 , Number of data records in the doc table of each column for index building:25000000
Whether to clear volume indexes:false
Time required for each worker node (seconds):
SegmentationWorker: 2
TmpTableWorker: 1
KmeansGraphWorker: 0
BuildJobWorker: 9647
SeekJobWorker: 6431
TmpResultJoinWorker: 0
RecallWorker: 0
CleanUpWorker: 3
Total time required (minutes):268
Sample commands:
jar -resources proxima_ce_g.jar -classpath /data/jiliang.ljl/project/proxima2-java/proxima-ce/target/binary/proxima-ce-0.1-SNAPSHOT-jar-with-dependencies.jar com.alibaba.proxima2.ce.ProximaCERunner
-doc_table doc_table_pailitao_binary2 -doc_table_partition 20210712
-query_table doc_table_pailitao_binary2 -query_table_partition 20210712
-output_table output_table_pailitao_binary_ce -output_table_partition 20210712
-data_type binary -dimension 512 -app_id 201220 -pk_type int64 -clean_build_volume false -distance_method Hamming -binary_to_int true -row_num 50 -column_num 4;シナリオ 2:10 億件の FLOAT レコード、128 次元
テスト構成
パラメーター | 値 |
doc テーブルのレコード | 1,000,000,000 |
クエリテーブルのレコード | 1,000,000,000 |
データ型 | FLOAT |
次元 | 128 |
検索構成 | 50 行 x 60 列 |
結論
Centauri との比較:
Proxima CE のハッシュシャーディングは、全体として約 30% 高速です。
Proxima CE のクラスターシャーディングは、全体で約 2 倍の改善を実現し、シークフェーズは約 7.5 倍高速です。
INT8 量子化により、データパフォーマンスが約 10% 向上します。
メソッド | 自動チューニングまたは K-means (秒) | ビルドフェーズ | シークフェーズ (秒) |
Centauri | 1,220 | 9,822 | 37,245 |
Proxima CE のハッシュシャーディング | 該当なし | 9,841 | 23,462 |
Proxima CE のハッシュシャーディング + INT8 量子化 | 該当なし | 7,600 | 21,624 |
Proxima CE のクラスターシャーディング | 1,247 | 14,404 | 5,028 |
ビルドフェーズの詳細
メソッド | マッパー | ビルドレデューサー | 合計所要時間 (秒) |
Centauri | - | - | - |
Proxima CE のハッシュシャーディング | 00:01:23.116 レイテンシー:{min:00:00:03, avg:00:00:23, max:00:01:00} | 02:41:43.563 レイテンシー:{min:00:02:40, avg:01:32:33, max:02:41:33} | 9,841 |
Proxima CE のハッシュシャーディングと INT8 量子化 | 00:01:36.166 レイテンシー:{min:00:00:09, avg:00:00:25, max:00:01:09} | 02:04:11.440 レイテンシー:{min:00:06:56, avg:01:06:06, max:02:03:53} | 7,600 |
Proxima CE のクラスターシャーディング | 00:15:33.022 レイテンシー:{min:00:00:03, avg:00:03:24, max:00:15:21} | 03:43:37.529 レイテンシー:{min:00:03:57, avg:01:33:32, max:03:43:35} | 14,404 |
シークフェーズの詳細
メソッド | マッパー | TopN レデューサー | マージレデューサー | 合計所要時間 (秒) | 備考 |
Centauri | 00:15:45.000 34 秒から 11 分 | 08:33:50.000 98 分から 489 分 | 01:30:20.000 30 分から 70 分 | 37,245 |
|
Proxima CE のハッシュシャーディング | 00:06:29.791 レイテンシー:{min:00:00:02, avg:00:01:39, max:00:05:56} | 04:50:42.422 レイテンシー:{min:00:01:48, avg:01:54:33, max:03:47:54} | 04:50:42.422 レイテンシー:{min:00:00:35, avg:00:33:39, max:01:32:16} | 23,462 |
|
Proxima CE のハッシュシャーディングと INT8 量子化 | 00:06:25.718 レイテンシー:{min:00:00:17, avg:00:01:27, max:00:06:02} | 03:58:00.566 レイテンシー:{min:00:00:25, avg:01:06:41, max:02:40:07} | 01:54:35.620 レイテンシー:{min:00:01:56, avg:00:20:54, max:01:39:55} | 21,624 | 該当なし。 |
Proxima CE のクラスターシャーディング | 00:23:51.623 レイテンシー:{min:00:00:04, avg:00:03:01, max:00:08:34} | 01:00:38.382 レイテンシー:{min:00:05:15, avg:00:18:00, max:01:00:10} | 00:12:39.341 レイテンシー:{min:00:00:31, avg:00:07:08, max:00:12:33} | 5,028 | 該当なし。 |
シナリオ 3:16 億件の FLOAT レコード、クラスターシャーディング
テスト構成
パラメーター | 値 |
doc テーブルのレコード | 1,600,000,000 |
クエリテーブルのレコード | 1,600,000,000 |
データ型 | FLOAT |
次元 | 128 |
行と列の構成 | 自動計算 |
結論
このデータ規模では、Proxima CE のクラスターシャーディングのみがすべてのフェーズを完了します。Centauri はシークフェーズでメモリ不足 (OOM) エラーにより失敗し、Proxima CE のハッシュシャーディングは出力が一時テーブルのサイズ制限を超えたため失敗します。
メソッド | 自動チューニングまたは K-means (秒) | ビルドフェーズ | シークフェーズ (秒) |
Centauri | 1,127 | 19,962 | 失敗 — メモリ不足 (OOM) エラー (2 回試行) |
Proxima CE のハッシュシャーディング | 該当なし | 14,637 | 失敗 — 出力データが一時テーブルの制限を超過 (1 回試行) |
Proxima CE のクラスターシャーディング | 5,478 | 17,911 | 6,801 |