このトピックでは、Delta テーブルのデータ編成を最適化するサービスのアーキテクチャについて説明します。
背景
Delta テーブルは、MaxCompute の増分データテーブルフォーマットです。分レベルのほぼリアルタイムのデータインポートをサポートします。高トラフィックのシナリオでは、これにより多くの小さな増分ファイルと冗長な中間状態が発生する可能性があります。ストレージのオーバーヘッドとコンピューティングコストを削減し、分析実行とデータ読み書き操作の速度を向上させるために、MaxCompute は 3 つの最適化サービスを提供しています: クラスタリング (小規模ファイルのマージ)、COMPACTION、およびデータ再利用です。
クラスタリング (小規模ファイルのマージ)
課題
Delta テーブルは、分レベルのほぼリアルタイムの増分データインポートをサポートします。高トラフィックのシナリオでは、これにより小さな増分ファイルの数が急増する可能性があります。この状況は、以下の問題につながります:
高いストレージコストと増加した I/O 負荷。
多くの小規模ファイルは、頻繁なメタデータ更新もトリガーします。
分析実行の遅延と非効率なデータ読み書き操作。
これらの理由から、これらのシナリオを自動的に最適化するために、クラスタリングサービスとして知られる、適切に設計された小規模ファイルマージサービスが必要です。
解決策
クラスタリングサービスは、MaxCompute の内部ストレージサービスによって実行され、小規模ファイルをマージするように設計されています。クラスタリングは、データの履歴の中間状態を変更しません。これは、サービスがどのレコードの中間履歴状態も削除しないことを意味します。
ワークフロー
クラスタリングサービスの全体的なワークフローを次の図に示します。
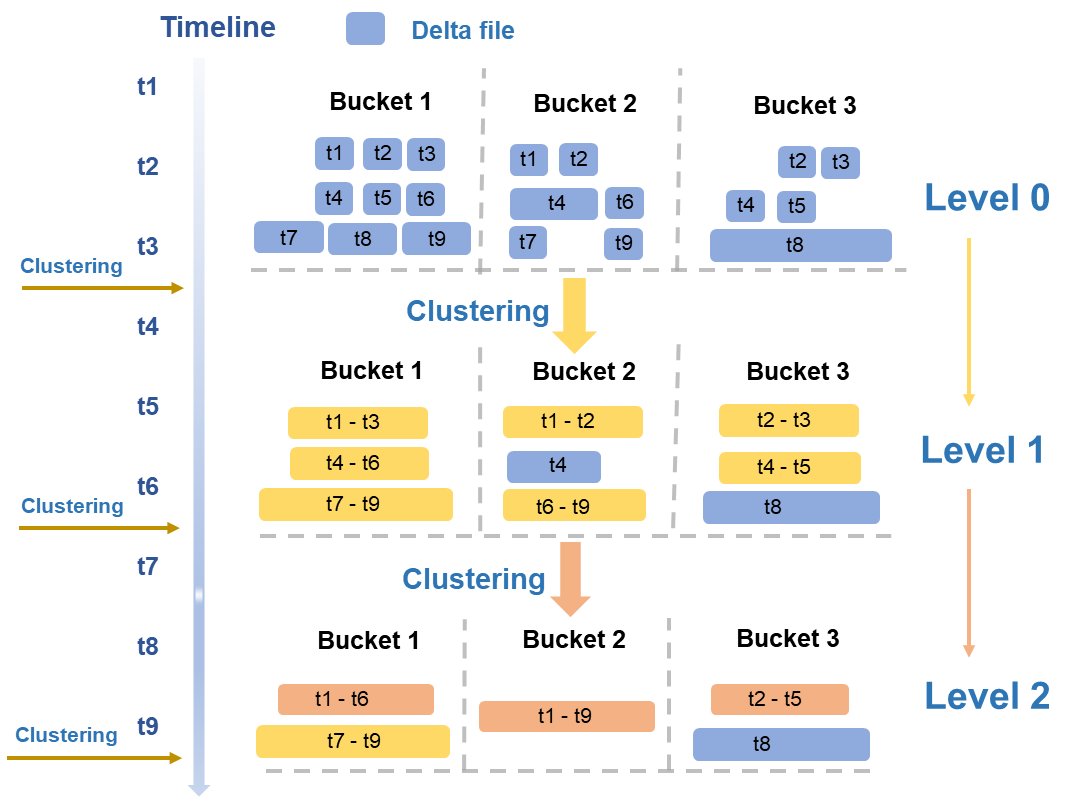
階層的マージ
サービスは、典型的な読み書きビジネスシナリオに基づくクラスタリングポリシーを使用します。サービスは、サイズや数量などの複数のディメンションに基づいてデータファイルを定期的に評価し、階層的なマージを実行します。
レベル 0 → レベル 1: 初回の書き込み操作からの最小の DeltaFiles (図の青いデータファイル) は、中サイズの DeltaFiles (図の黄色いデータファイル) にマージされます。
レベル 1 → レベル 2: 中サイズの DeltaFiles が特定の規模に達すると、より高いレベルのマージがトリガーされ、より大きく最適化されたファイル (図のオレンジ色のデータファイル) が生成されます。
読み書き増幅の回避
大規模ファイルの分離: Bucket3 の T8 ファイルなど、特定のサイズを超えるデータファイルはマージから除外されます。
タイムスパン制限: タイムスパンの大きいファイルはマージされません。これにより、Time Travel または増分クエリ中にクエリの時間範囲外にある大量の履歴データを読み取る必要がなくなります。
自動実行トリガー: 各クラスタリング操作は、データを少なくとも 1 回読み書きします。これにより、コンピューティングリソースと I/O リソースが消費され、ある程度の読み書き増幅が発生します。クラスタリングサービスが効率的に実行されるように、MaxCompute エンジンはシステムの状態に基づいて操作を自動的にトリガーします。
同時実行性とトランザクション性
同時実行: データは BucketIndex によってパーティション分割されて保存されるため、クラスタリングサービスはバケットレベルで同時に実行されます。これにより、全体の実行時間が大幅に短縮されます。
トランザクションの保証: クラスタリングサービスは、Meta Service と対話して、処理するテーブルまたはパーティションのリストを取得します。操作が完了すると、新しいデータファイルと古いデータファイルに関する情報を Meta Service に渡します。Meta Service はこのプロセスで重要な役割を果たします。トランザクションの競合を検出し、新旧ファイルのメタデータのシームレスな更新を調整し、古いデータファイルを安全に再利用する責任があります。
コンパクション
課題
Delta テーブルは UPDATE および DELETE 操作をサポートします。これらの操作は、古いレコードをその場で変更するのではなく、新しいレコードを書き込んで古いレコードの以前の状態をマークします。このような操作が多くなると、次のようになります:
データ冗長性: 中間状態の冗長なレコードは、ストレージコストとコンピューティングコストを増加させます。
クエリ効率の低下
したがって、中間状態を排除し、これらのシナリオを最適化するために、適切に設計されたコンパクションサービスが必要です。
解決策
コンパクションは、BaseFiles と DeltaFiles を含む選択されたデータファイルをマージします。同じプライマリキーを持つ複数のレコードを結合し、中間の UPDATE および DELETE 状態を排除します。最新の状態のレコードのみが保持されます。最後に、INSERT データのみを含む新しい BaseFile が生成されます。
ワークフロー
コンパクションサービスの全体的なワークフローは次のとおりです。
DeltaFiles のマージ
t1 から t3 にかけて、新しいバッチの DeltaFiles が書き込まれます。これにより、バケットレベルで同時に実行されるコンパクション操作がトリガーされます。この操作はファイルをマージして、各バケットに新しい BaseFile を生成します。
t4 と t6 で、新しい DeltaFiles の別のバッチが書き込まれ、別のコンパクション操作がトリガーされます。この操作は、既存の BaseFile を新しい DeltaFiles とマージして、新しい BaseFile を生成します。
トランザクションの保証
コンパクションサービスも Meta Service と対話する必要があります。プロセスはクラスタリングのプロセスと似ています。この操作を実行するテーブルまたはパーティションのリストを取得します。操作が完了すると、新しいデータファイルと古いデータファイルに関する情報を Meta Service に渡します。Meta Service は、コンパクション操作のトランザクション競合を検出し、新旧ファイルのメタデータをアトミックに更新し、古いデータファイルを再利用する責任があります。
実行頻度
コンパクションサービスは、履歴レコードの状態を排除することで、コンピューティングリソースとストレージリソースを節約します。これにより、完全スナップショットクエリの効率が向上します。ただし、頻繁なコンパクション操作には、かなりのコンピューティングリソースと I/O リソースが必要です。また、新しい BaseFile が追加のストレージを使用する原因にもなります。履歴の DeltaFiles は Time Travel クエリに使用される可能性があり、すぐに削除できないため、ストレージコストが発生し続けます。
したがって、コンパクション操作の実行頻度は、特定のビジネスニーズとデータ特性に基づいて決定する必要があります。UPDATE および DELETE 操作が頻繁で、完全スナップショットクエリの需要が高い場合は、クエリ速度を最適化するためにコンパクションの頻度を増やすことを検討してください。
データ再利用
Time Travel と増分クエリはどちらも履歴データ状態をクエリするため、Delta テーブルはデータの履歴バージョンを一定期間保持します。
再利用ポリシー:
acid.data.retain.hoursテーブルプロパティを使用してデータ保持期間を設定できます。履歴データが設定値より古い場合、システムは自動的にそれを再利用してクリーンアップします。クリーンアップが完了すると、その履歴バージョンは Time Travel を使用してクエリできなくなります。再利用されたデータは、主に操作ログとデータファイルで構成されます。説明Delta テーブルの場合、新しい DeltaFiles を継続的に書き込むと、どの DeltaFiles も削除できません。これは、他の DeltaFiles がそれらに対して状態の依存関係を持つ可能性があるためです。COMPACTION または InsertOverwrite 操作を実行した後、後続で生成されたデータファイルは以前の DeltaFiles に依存しなくなります。Time Travel クエリ期間が終了すると、それらは削除できます。
強制クリーンアップ: 特殊なシナリオでは、
PURGEコマンドを使用して、履歴データの強制クリーンアップを手動でトリガーできます。自動メカニズム: コンパクションが長期間実行されない場合に発生する可能性のある、無制限の履歴データ増加を防ぐために、MaxCompute エンジンにはいくつかの最適化が含まれています。バックエンドシステムは、設定された Time Travel 期間よりも古い BaseFiles または DeltaFiles に対して、定期的に自動コンパクションを実行します。これにより、再利用メカニズムが正しく機能することが保証されます。