MaxCompute は、管理オブジェクトを作成して外部データソースのメタデータとデータアクセス方法を定義できるデータレイク分析ソリューションを提供します。外部プロジェクトまたは外部スキーマは、外部データソースのカタログ、データベース、またはスキーマにマッピングでき、その中のすべてのテーブルに直接アクセスできます。このソリューションは、データレイクとデータウェアハウス間のサイロを解消します。データレイクの柔軟性と豊富なマルチエンジンエコシステムを、データウェアハウスのエンタープライズレベルの機能と組み合わせることで、統合データ管理プラットフォームを構築します。この機能はパブリックプレビュー中です。
データウェアハウスとデータレイク
カテゴリ | 機能 |
データウェアハウス | データウェアハウスは、構造化データと半構造化データの管理と制約を重視します。強力な管理に依存して、より優れたコンピューティングパフォーマンスと、より標準化された管理機能を実現します。 |
データレイク | データレイクは、オープンなデータストレージと共通のデータ形式を重視します。必要に応じてデータを生成または消費する複数のエンジンをサポートします。柔軟性を確保するために、弱い管理機能のみを提供します。非構造化データと互換性があり、スキーマオンリードのアプローチをサポートし、より柔軟なデータ管理方法を提供します。 |
MaxCompute データウェアハウス
MaxCompute は、サーバーレスアーキテクチャに基づくクラウドネイティブなデータウェアハウスです。以下の操作を実行できます。
MaxCompute を使用してデータウェアハウスをモデリングします。
抽出、変換、ロード (ETL) ツールを使用して、定義されたスキーマを持つモデリングされたテーブルにデータをロードして保存します。
標準の SQL エンジンを使用してデータウェアハウス内の大規模データを処理し、MaxQA または Hologres OLAP エンジンを使用してデータを分析します。
MaxCompute とデータレイクおよびフェデレーテッドクエリのシナリオ
データレイクのシナリオでは、データはレイク内に存在し、さまざまなエンジンによって生成または消費されます。MaxCompute コンピューティングエンジンは、これらのエンジンの1つとして機能し、データを処理および使用できます。この場合、MaxCompute はデータレイクの上流ソースによって生成されたデータを読み取り、さまざまな主流のオープンソースデータ形式と互換性を持ち、そのエンジン内で計算を実行し、下流ワークフロー用のデータを生成する必要があります。
高価値データを集約する安全で高性能かつコスト効率の高いデータウェアハウスとして、MaxCompute はデータレイクからメタデータとデータを取得する必要もあります。これにより、外部データに対するエンジン内での計算と、内部データとのフェデレーテッドクエリが可能になり、価値を抽出してデータウェアハウスに統合できます。
データレイクに加えて、データウェアハウスとしての MaxCompute は、Hadoop や Hologres などの他のさまざまな外部データソースからデータを取得し、内部データとのフェデレーテッドクエリを実行する必要もあります。フェデレーテッドクエリのシナリオでは、MaxCompute は外部システムからのメタデータとデータの読み取りもサポートする必要があります。
MaxCompute データレイク分析
MaxCompute データレイク分析は、MaxCompute コンピューティングエンジン上に構築されています。
相互接続されたクラウド製品ネットワークを介して、Alibaba Cloud メタデータサービスまたは Object Storage Service (OSS) へのアクセスをサポートします。データソースが VPC 内にある場合は、専用線を使用して外部データソースにアクセスできます。
管理オブジェクトを作成して、外部データソースのメタデータとデータアクセス方法を定義できます。外部プロジェクトまたは外部スキーマは、外部データソースのカタログ、データベース、またはスキーマにマッピングでき、そのスコープ内のすべてのテーブルに直接アクセスできます。
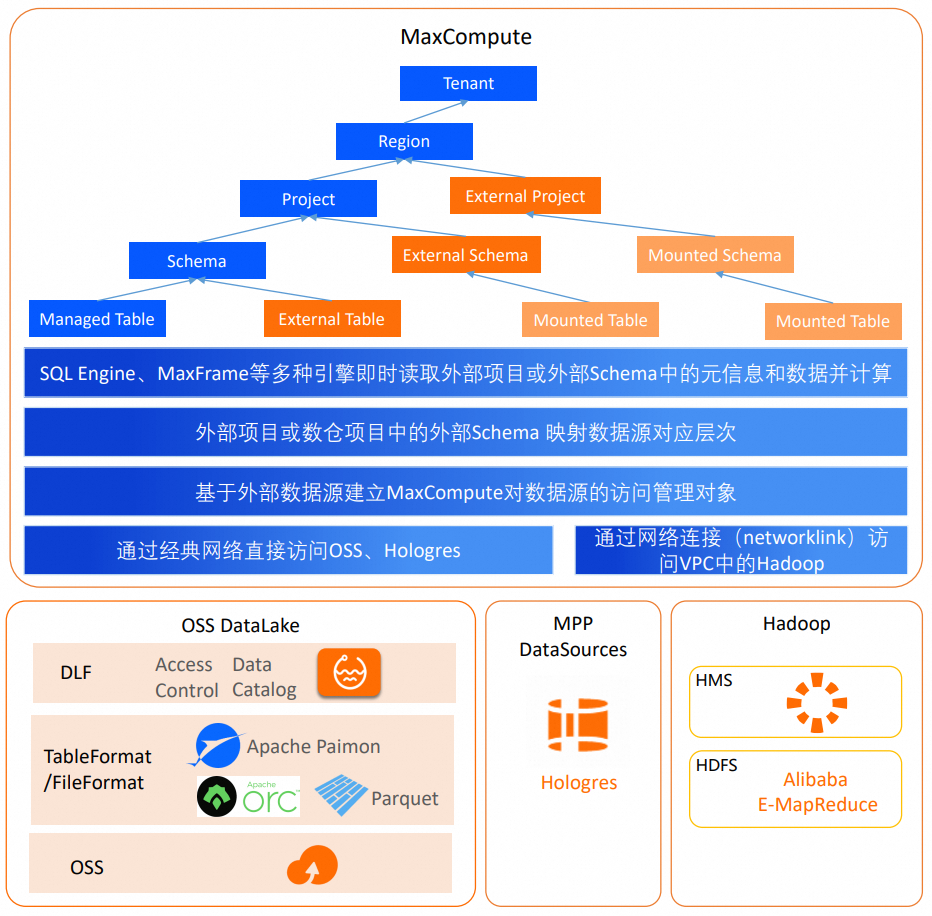
ネットワーク接続
Networklink の詳細については、「ネットワーク接続フロー」をご参照ください。MaxCompute は、ネットワーク接続を使用して、E-MapReduce (EMR) クラスターや ApsaraDB RDS インスタンス (近日提供予定) などの VPC 内のデータソースにアクセスできます。Data Lake Formation (DLF)、OSS、および Hologres は、クラウドサービスの相互接続ネットワーク内にあります。MaxCompute は、Networklink を設定しなくても、これらのサービス内のデータに直接アクセスできます。
外部サーバー
外部サーバーには、認証情報、場所、接続プロトコルなどのメタデータとデータアクセス情報が含まれます。MaxCompute は、外部サーバーを使用してデータソースに接続し、そのメタデータとデータを使用します。外部サーバーは、テナント管理者が定義するテナントレベルの管理オブジェクトです。
外部スキーマ
外部スキーマは、MaxCompute データウェアハウスプロジェクトにおける特殊なタイプのスキーマです。上の図に示すように、データソースのデータベース (DLF_legacy または Hive のシナリオの場合) またはスキーマ (Hologres のシナリオの場合) にマッピングできます。これにより、そのスコープ内のテーブルとデータに直接アクセスできます。MaxCompute メタデータで作成されず、外部スキーマを介して外部データソースからマッピングされるテーブルは、フェデレーテッド外部テーブル (マウントテーブル) と呼ばれます。
フェデレーテッド外部テーブルは、MaxCompute 内にメタデータを保存しません。代わりに、MaxCompute は外部サーバーオブジェクトで指定されたメタデータサービスからリアルタイムでメタデータを取得します。クエリを実行するときに、DDL 文を使用して外部テーブルを作成する必要はありません。プロジェクト名と外部スキーマ名を名前空間として使用して、元のテーブルを直接参照できます。ソースのテーブル構造またはデータが変更されると、フェデレーテッド外部テーブルはすぐに最新の状態を反映します。外部スキーマがマッピングするデータソースレベルは、データソースの階層と外部サーバーで定義されたアクセスレベルによって異なります。
外部プロジェクト
Data Lakehouse Solution 1.0 では、外部プロジェクトは2層モデルを使用していました。外部スキーマと同様に、データソースのデータベース (DLF_legacy または Hive のシナリオの場合) またはスキーマ (Hologres のシナリオの場合) にマッピングされ、外部データを読み取って計算するための実行環境としてデータウェアハウスプロジェクトが必要でした。しかし、プロジェクトレベルでデータベースまたはスキーマをマッピングすると、外部プロジェクトが多すぎることになりました。さらに、MaxCompute は現在、外部データソースの3層のカタログ階層によりよく整合させるために、3層プロジェクトモデルを推奨しています。Data Lakehouse Solution 1.0 の2層の外部プロジェクトは、新しい3層のデータウェアハウスプロジェクトと互換性がありません。したがって、MaxCompute は Data Lakehouse Solution 1.0 の外部プロジェクトを段階的に廃止しています。既存の外部プロジェクトを外部スキーマに移行できます。移行の詳細については、「Data Lakehouse Solution 1.0 の外部プロジェクトを Data Lakehouse 2.0 の外部スキーマに移行する」をご参照ください。
データレイク分析では、新しい外部プロジェクトは3層データソースのカタログ (DLF のシナリオの場合) またはデータベース (Hologres のシナリオの場合) に直接マッピングされます。これにより、DLF カタログ下のデータベースまたは Hologres データベース下のスキーマが直接可視化されます。MaxCompute で作成されずに直接マッピングされるこの中間レベルは、マウントスキーマと呼ばれます。その後、ソーステーブルにフェデレーテッド外部テーブルとしてアクセスできます。
データソースタイプ | 外部サーバー階層 | 外部スキーマのマッピング | 外部プロジェクトのマッピング | レガシー外部プロジェクトのマッピング | 認証方式 |
DLF_legacy+OSS | リージョンレベルの DLF および OSS サービス | DLF Catalog.Database | サポートされていません | DLF Catalog.Database | RAMRole |
Hive+HDFS | EMR インスタンス | Hive Database | サポートされていません | Hive Database | 認証なし |
Hologres | Hologres インスタンスのデータベース | Schema | - | サポートされていません | RAMRole |
- | Database | サポートされていません | SLR および現在のユーザーID認証 | ||
DLF | リージョンレベルの DLF サービス | サポートされていません | DLF Catalog | サポートされていません | SLR および現在のユーザーID認証 |
Filesystem Catalog | OSS 上の Paimon カタログレベルのディレクトリ | サポートされていません | Paimon カタログレベルのディレクトリから解析されたカタログ | サポートされていません | RAMRole |
データソースによってサポートされる認証の種類は異なります。MaxCompute は、今後のリリースで、現在のユーザー ID を使用して Hologres にアクセスしたり、Kerberos 認証を使用して Hive にアクセスしたりするなど、より多くの認証方式をサポートする予定です。