MaxCompute は、データベース管理ツールである DataGrip をサポートしています。このトピックでは、MaxCompute JDBC ドライバーを DataGrip に接続して、データ管理に利用する方法について説明します。
背景情報
DataGrip は、開発者向けの包括的なデータベース管理ツールであり、ローカルマシン、サーバー、またはクラウド上のデータベースのクエリ、作成、および管理を行うための便利な方法を提供します。詳細については、「DataGrip」をご参照ください。
前提条件
MaxCompute プロジェクトが作成されている。
MaxCompute プロジェクトの作成の詳細については、「MaxCompute プロジェクトを作成する」をご参照ください。
MaxCompute プロジェクトの AccessKey ID と AccessKey Secret が取得されている。
これらは AccessKey ページで確認できます。
完全な依存関係を持つ JAR パッケージ
jar-with-dependenciesがダウンロードされている。odps-jdbc-3.9.0.jar をクリックして直接ダウンロードするか、GitHub または Maven リポジトリ から最新バージョンの MaxCompute JDBC ドライバーを取得できます。この例で使用されているバージョンは 3.9.0 です。
JetBrains から DataGrip がインストールされている。
インストール手順については、「DataGrip のインストール」をご参照ください。
この例で使用されている DataGrip のバージョンは 2024.3.3 です。
手順
DataGrip を MaxCompute に接続するには、次の手順に従います。
MaxCompute JDBC ドライバーパッケージを DataGrip にアップロードして、MaxCompute プロジェクトにアクセスできるようにします。接続パラメーターを構成して、MaxCompute プロジェクトへの接続を確立します。
手順 2: DataGrip で MaxCompute プロジェクトを管理する
接続が完了したら、確立されたデータ接続に基づいて、DataGrip を使用して MaxCompute プロジェクトを管理します。
手順 1: ドライバーを追加し、データソースを構成する
DataGrip を起動し、メインインターフェイスにアクセスします。
[メインメニュー]
 をクリックし、 を選択します。
をクリックし、 を選択します。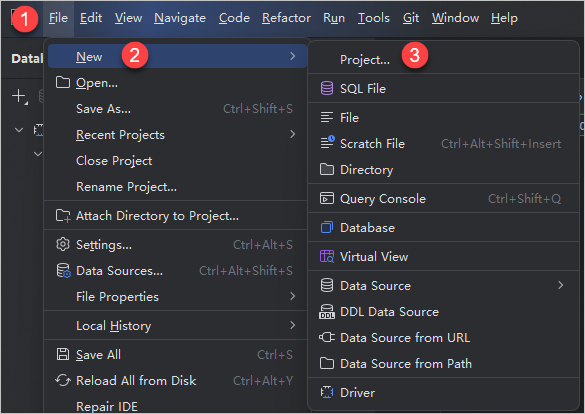
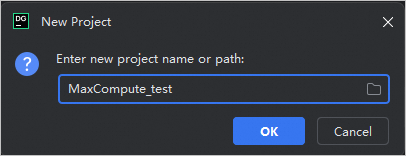
[新規プロジェクト] ダイアログボックスで、プロジェクト名(例:MaxCompute_test)を入力します。
[新規プロジェクト] ウィンドウで、[新規]
 > [ドライバー] をクリックします。
> [ドライバー] をクリックします。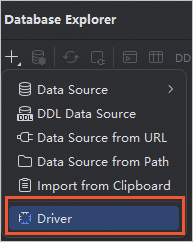
[データソースとドライバー] ページで、[ドライバー] タブを選択し、
 アイコンをクリックして [ユーザー ドライバー] を作成し、MaxCompute などのドライバー名を入力します。
アイコンをクリックして [ユーザー ドライバー] を作成し、MaxCompute などのドライバー名を入力します。[ドライバー ファイル] セクションで、
アイコン > [カスタム JAR] をクリックします。ダウンロードした MaxCompute JDBC ドライバー JAR ファイル(例:odps-jdbc-3.9.0-rc4-jar-with-dependencies.jar)をコンピューターから選択します。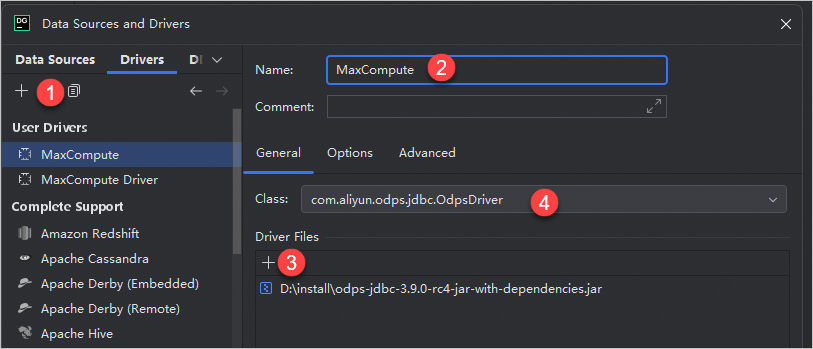
パラメーター
説明
名前
追加するドライバーの名前(例:MaxCompute)。
クラス
MaxCompute JDBC ドライバー JAR パッケージをアップロードした後、ドロップダウンリストから [com.aliyun.odps.jdbc.OdpsDriver] を選択します。
[データソース] タブに移動し、
アイコンをクリックして、新しく追加されたドライバー(例:MaxCompute)を選択します。[全般] タブで、必要な情報を入力します。
パラメーター
説明
名前
デフォルト値はドライバー名と同じです。カスタマイズすることもできます。
認証
[ユーザーとパスワード] を選択します。
ユーザー
MaxCompute プロジェクトにアクセスするために使用される AccessKey ID。
AccessKey ページで取得できます。
パスワード
AccessKey ID に対応する AccessKey Secret。
URL
MaxCompute プロジェクトへの接続に使用される URL。形式は
jdbc:odps:<MaxCompute_endpoint>?project=<MaxCompute_project_name>[&interactiveMode={true|false}]です。構成時には<>記号を削除してください。次の表は、上記のステートメントで指定されたパラメーターについて説明しています。<MaxCompute_endpoint>: 必須。MaxCompute のエンドポイント。MaxCompute プロジェクトが存在するリージョンに基づいて、このパラメーターを構成します。
さまざまなリージョンにおける MaxCompute のエンドポイントの詳細については、「エンドポイント」をご参照ください。
<MaxCompute_project_name>: 必須。MaxCompute プロジェクトの名前。
このパラメーターは、MaxCompute プロジェクトが対応する DataWorks ワークスペースではなく、MaxCompute プロジェクトの名前を指定します。MaxCompute コンソール にログインし、上部のナビゲーションバーで MaxCompute プロジェクトが存在するリージョンを選択し、[ワークスペース] > [プロジェクト] を選択します。その後、MaxCompute プロジェクトの名前を表示できます。
interactiveMode: オプション。このパラメーターは、MaxCompute Query Acceleration (MCQA) 機能を有効にするかどうかを指定します。
MCQA 機能を有効にする場合は、URL の末尾に
&interactiveMode=trueを追加します。MCQA 機能の詳細については、「クエリ高速化」をご参照ください。
useProjectTimeZone: オプション。プロジェクトのタイムゾーンを使用するかどうかを指定します。 DataGrip が MaxCompute サーバーサイドインスタンスと同じタイムゾーンを維持する必要がある場合は、URL に
&useProjectTimeZone=trueを追加します。
[接続テスト] をクリックして、データソースの構成が成功したことを確認します。
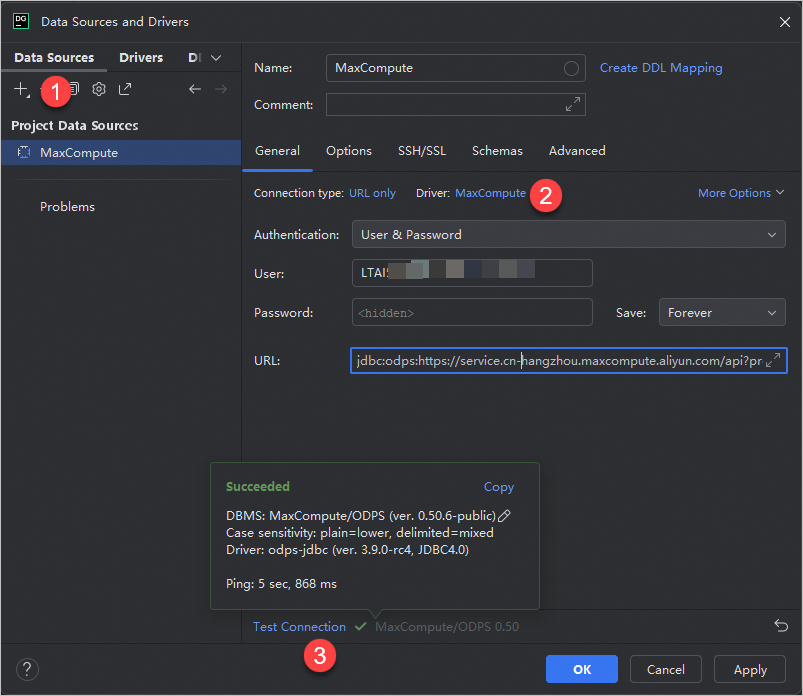
[OK] をクリックして構成を完了します。
手順 2: DataGrip を使用して MaxCompute プロジェクトを管理する
DataGrip が MaxCompute に接続されると、接続は左側のパネルに表示されます。 SQL スクリプトを作成および実行して、MaxCompute プロジェクトを管理できます。その他の操作については、「DataGrip ヘルプ」をご参照ください。
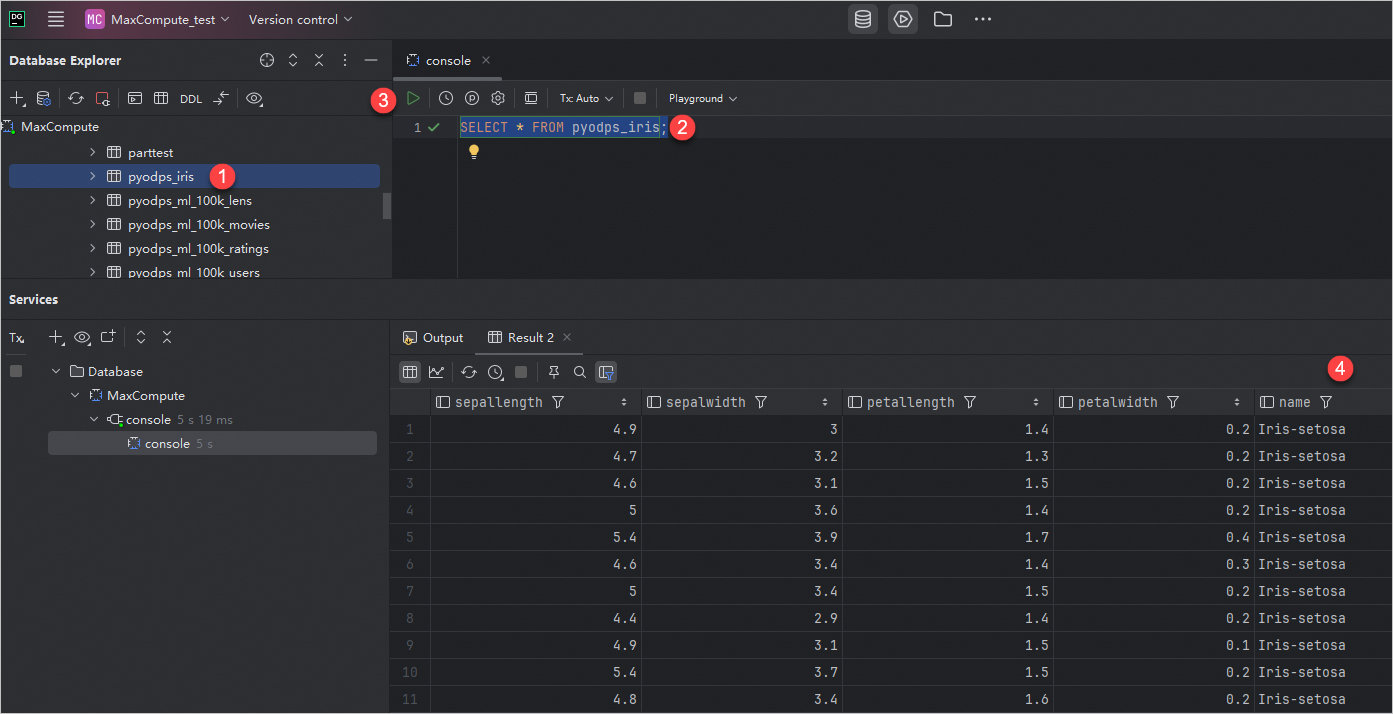
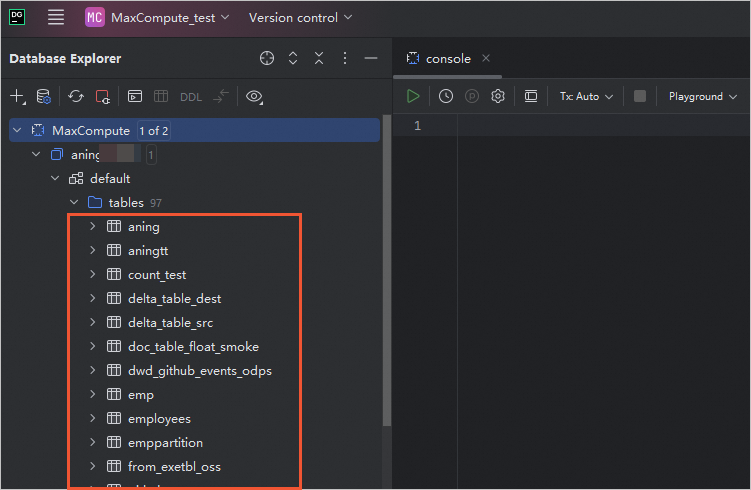
既存のすべてのテーブルをクエリする
MaxCompute 接続の下にリストされているすべてのテーブルの情報を表示できます。
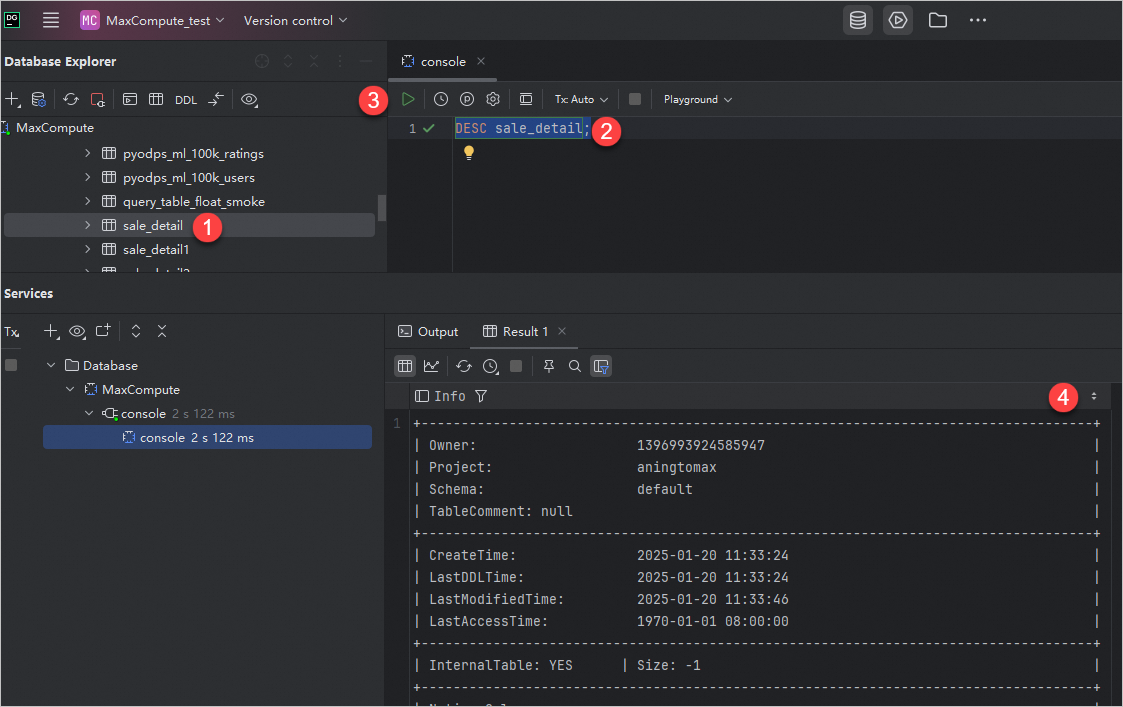
テーブルスキーマをクエリする
MaxCompute 接続の下にあるテーブルを右クリックし、 を選択し、SQL エディターを使用してテーブルスキーマのクエリを作成して実行します。
テーブルデータをクエリする
MaxCompute 接続の下にあるテーブルを右クリックし、 を選択し、SQL エディターを使用してテーブルデータのクエリを作成して実行します。