Proxima CE は、ベクトル検索タスクでクラスタシャーディングをサポートしています。このトピックでは、クラスタシャーディング機能の使用方法と例について説明します。
前提条件
Proxima CE パッケージがインストールされていること。詳細については、「Proxima CE パッケージをインストールする」をご参照ください。
基本原則
Proxima CE は、ベクトル検索中にハッシュシャーディングとクラスタシャーディングをサポートしています。-sharding_mode パラメーターを構成して、インデックスシャーディングモードを指定できます。このパラメーターを hash に設定すると、ハッシュシャーディングが実行されます。このパラメーターを cluster に設定すると、クラスタシャーディングが実行されます。デフォルトでは、ハッシュシャーディングが実行されます。
ハッシュシャーディング: Proxima CE がインデックスを構築するとき、doc テーブルのデータ全体がシャーディングされ、特定の数のインデックスが取得されます。取得できるインデックスの数は、column_num パラメーターによって指定されます。ベクトル検索中に、Proxima CE は各クエリですべてのインデックスシャードのデータを検索し、取得結果をマージします。
クラスタシャーディング: Proxima CE は、doc テーブルのデータに対してクラスタリングを実行し、互いに近いデータを同じインデックスシャードに割り当てます。ベクトル検索中に、Proxima CE は、クエリとクラスタ重心間の距離に基づいて、特定の最近傍クラスタ重心に対応するインデックスシャードのデータを検索します。
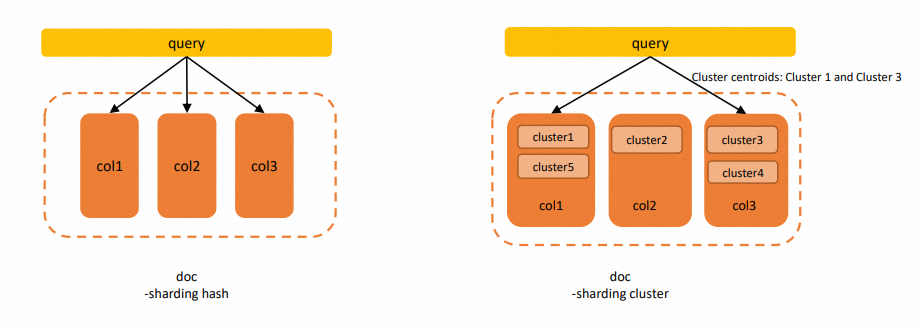
インデックスのクラスタシャーディングは、クエリのパフォーマンスを向上させることを目的としています。この機能を使用すると、Proxima CE は特定のインデックスシャードのデータのみを検索し、すべてのインデックスシャードをクエリすることなく最適な結果を取得します。インデックスのクラスタシャーディングには、次のフェーズが含まれます。
インデックス構築フェーズ
Proxima CE がインデックスを構築するとき、doc テーブルのデータセットに対して k-means クラスタリングが実行され、特定の数のクラスタ重心が生成されます。生成できるクラスタ重心の数は、kmeans_cluster_num パラメーターによって指定されます。
次に、Proxima CE は、空間距離に基づいてクラスタ重心を特定の数のセットに分割します。セットの数は、column_num パラメーターによって指定されます。このプロセスは、クラスタ重心を指定された数のインデックスに割り当てるために使用されます。
Proxima CE が doc テーブルのデータをクラスタリングするとき、Proxima CE はデータレコードを、データレコードに最も近いクラスタ重心に対応するインデックスシャードに割り当てます。
インデックスクエリフェーズ
Proxima CE は、クエリと各クラスタ重心間の距離を計算します。
Proxima CE は、最近傍クラスタ重心に対応する特定の割合のインデックスシャードを選択し、インデックスシャードのデータを検索します。選択できるインデックスシャードの割合は、kmeans_seek_ratio パラメーターによって指定されます。
Proxima CE は、インデックスシャードで取得された結果をマージします。
ユースケース
クラスタシャーディングは、数十億件のデータレコードなど、非常に大量のデータが存在するシナリオに適しています。この機能は、非常に大量のクエリデータが存在するシナリオに特に適しています。
クラスタシャーディングは、インデックスが一度構築され、その後複数回クエリされるシナリオに適しています。
説明インデックスのクラスタシャーディングでは、doc テーブルのデータセットに対して k-means クラスタリングが必要であり、これには一定の時間がかかります。さらに、インデックスシャードの一部のみが取得されるため、取得損失が発生します。したがって、この機能はすべてのベクトル検索シナリオに適しているわけではありません。
クラスタシャーディングは、マルチカテゴリ検索をサポートしていません。距離関数は、ユークリッド距離またはハミング距離以外の距離メジャータイプを使用する距離式をサポートしていません。
使用ロジック
-sharding_modeパラメーターを cluster に設定します。初期クラスタ重心を格納するテーブルの名前を、JAR コマンドの
-resourcesオプションに追加します。説明このパラメーターはコマンドラインパラメーターではなく、JAR コマンドで必要なパラメーターです。初期クラスタ重心を格納するテーブルの名前はカスタム名であり、一意である必要があります。たとえば、名前は
foo_init_center_resourceにすることができます。Proxima CE が実行されると、クラスタ重心を格納するための MaxCompute テーブルが作成されます。MaxCompute リソースのメカニズムにより、クラスタ重心を格納するテーブルの名前を手動で指定する必要があります。
-kmeans_resource_nameパラメーターの値が-resourcesオプションの値と同じであることを確認します。Proxima CE は、-resourcesオプションの値を直接取得できません。したがって、コマンドラインパラメーター-kmeans_resource_nameを指定して、-resources オプションの値を渡す必要があります。その他のパラメーターを構成します。その他のパラメーターはオプションです。詳細については、「オプションパラメーター」の名前が
kmeans_で始まるパラメーターをご参照ください。オプション パラメーター
入力テーブルの作成とデータのインポート
DataWorks の SQL ノードで次のステートメントを実行できます。
-- 注: origin_table テーブルは、Alibaba Cloud サービスの 128 次元 FLOAT ベクトルデータテーブルです。
-- doc テーブルを準備します。
CREATE TABLE cluster_10kw_128f_doc(pk STRING, vector STRING) PARTITIONED BY (pt STRING);
ALTER TABLE cluster_10kw_128f_doc add PARTITION(pt='20221111');
INSERT OVERWRITE TABLE cluster_10kw_128f_doc PARTITION (pt='20221111') SELECT pk, vector FROM origin_table WHERE pt='20221111';
-- クエリテーブルを準備します。
CREATE TABLE cluster_10kw_128f_query(pk STRING, vector STRING) PARTITIONED BY (pt STRING);
ALTER TABLE cluster_10kw_128f_query add PARTITION(pt='20221111');
INSERT OVERWRITE TABLE cluster_10kw_128f_query PARTITION (pt='20221111') SELECT pk, vector FROM origin_table WHERE pt='20221111';DataWorks を使用して Proxima CE を実行する
この例では、DataWorks を使用して Proxima CE を実行し、事前に外部ボリュームを作成します。
次のサンプルコードで使用されているパラメーター構成の詳細については、「リファレンス: Proxima CE パラメーター」をご参照ください。
サンプルコマンド:
--@resource_reference{"proxima-ce-aliyun-1.0.0.jar"}
jar -resources proxima-ce-aliyun-1.0.0.jar -- アップロードされた Proxima CE の JAR パッケージ。
-classpath proxima-ce-aliyun-1.0.0.jar com.alibaba.proxima2.ce.ProximaCERunner -- classpath は、main 関数のエントリクラスを指定します。
-doc_table cluster_10kw_128f_doc
-doc_table_partition 20221111
-query_table cluster_10kw_128f_query
-query_table_partition 20221111
-output_table cluster_10kw_128f_output
-output_table_partition 20221111
-algo_model hnsw
-data_type float
-pk_type int64
-dimension 128
-column_num 50
-row_num 50
-vector_separator ,
-topk 1,50,100,200 -- top K が 1、50、100、200 に設定されている場合の再現率を取得します。
-job_mode train:build:seek:recall
-- -clean_build_volume true -- インデックスを保持します。後続のインデックスの使用のために、このオプションを true に設定できます。このオプションを true に設定する場合は、job_mode パラメーターを `seek(:recall optional)` に設定する必要があります。
-external_volume_name udf_proxima_ext
-sharding_mode cluster
-kmeans_resource_name kmeans_center_resource_xxx -- kmeans リソースの名前を手動で指定します。この例では、kmeans_center_resource_xxx が使用されています。
-kmeans_cluster_num 1000
-- -kmeans_sample_ratio 0.05 -- デフォルト値を使用します。
-- -kmeans_seek_ratio 0.1 -- デフォルト値を使用します。
-- -kmeans_iter_num 30 -- デフォルト値を使用します。
-- -kmeans_init_center_method "" -- デフォルト値を使用します。
-- -kmeans_worker_num 0 -- デフォルト値を使用します。
;実行結果
出力テーブルには大量のデータが含まれています。この例では、実際の実行ログのみを提供し、出力テーブルのデータレコードは提供しません。出力テーブルのスキーマは、「実行結果」のスキーマと同じです。
ベクトル検索 データ型:4、ベクトル次元:128、検索方法:HNSW、メジャー:SquaredEuclidean、構築モード:train:build:seek:recall
doc テーブルの情報 テーブル名: cluster_10kw_128f_doc、パーティション:20221111、doc テーブルのデータレコード数:100000000、ベクトルデリミタ: ,
クエリテーブルの情報 テーブル名: cluster_10kw_128f_query、パーティション:20221111、クエリテーブルのデータレコード数:100000000、ベクトルデリミタ: ,
出力テーブルの情報 テーブル名:cluster_10kw_128f_output、パーティション:20221111
行と列の情報 行数: 50、列数:50、インデックス構築の各列の doc テーブルのデータレコード数:2000000
ボリュームインデックスをクリアするかどうか:true
各ワーカーノードに必要な時間(秒):
SegmentationWorker: 3
TmpTableWorker: 1
KmeansGraphWorker: 2243
BuildJobWorker: 4973
SeekJobWorker: 5922
TmpResultJoinWorker: 0
RecallWorker: 986
CleanUpWorker: 6
合計所要時間(分):235
実際の再現率
Recall@1: 0.999
Recall@50: 0.9941600000000027
Recall@100: 0.9902300000000046
Recall@200: 0.9816199999999914