このトピックでは、Append Delta テーブルのデータ編成を最適化するために使用されるアーキテクチャについて説明します。
概要
Append Delta テーブルの革新的なテーブルフォーマットは、基盤となるデータ編成にレンジクラスタリング構造を使用しています。デフォルトでは、Row_ID がクラスターキーであり、バケット数はデータの増加に応じて動的に割り当てられます。クラスターキーが指定されると、バックグラウンドのクラスタリングジョブがデータに対して増分再クラスタリングを実行します。このプロセスにより、すべてのデータが順序付けられた状態に保たれます。
Append Delta テーブルは、複雑なビジネスシナリオで優れたパフォーマンスを発揮します。その大幅なパフォーマンス向上は、ビッグデータ分析におけるデータストレージフォーマットの最適化というコアバリューを浮き彫りにします。技術的な利点とパフォーマンスの最適化は、以下のように要約されます。
データの自律性: マージ、コンパクション、再クラスタリングなどのバックグラウンドタスクを通じて、ストレージ効率とクエリパフォーマンスの動的なバランスを実現します。
スケーラビリティ: 動的バケット化と自動分割/マージポリシーにより、テラバイトからエクサバイトまでのデータのシームレスなスケーリングをサポートします。
リアルタイムクラスタリング: 増分再クラスタリングは、ミリ秒レベルのデータ鮮度を提供し、オペレーショナルデータストア (ODS) レイヤーでのクラスター化クエリを高速化します。
動的バケット化
課題
レンジ/ハッシュクラスターテーブルを作成するには、まずビジネスのデータ規模を見積もる必要があります。次に、その見積もりに基づいて適切なバケット数とクラスターキーを設定します。テーブルが作成されると、MaxCompute はクラスタリングアルゴリズムを使用して、クラスターキーに基づいてデータを正しいバケットにルーティングします。
これにより、2 つの問題が発生する可能性があります。
データスキュー: データ量が多すぎてバケット数が少なすぎると、個々のバケットが大きくなりすぎます。これにより、クエリ中のデータプルーニングの効果が低下します。
データの断片化: バケット数がデータ量に対して必要以上に多い場合、各バケットに含まれるデータが少なすぎます。これにより、多数の小さな断片化されたファイルが作成され、クエリのパフォーマンスが損なわれます。
テーブル作成時にバケット数を明示的に指定することは、ユーザーにとって困難です。データ量に基づいて適切なバケット数を設定するには、ユーザーは自身のビジネス利用パターンと基盤となる MaxCompute テーブルフォーマットを理解する必要があります。そうして初めて、クラスタリング機能を正しく使用し、クエリパフォーマンスを最大化できます。
大規模なデータ移行の場合、各テーブルの潜在的なデータ量を評価する必要があります。この評価は、テーブル数が少ない場合は管理可能ですが、数千または数万のテーブルを扱う場合には実行が非常に困難になります。
ユーザーがテーブルの現在のデータ規模を正確に評価できたとしても、ビジネスの進化に伴い、実際のデータ規模は変化します。今日適切なバケット数が、将来も適切であるとは限りません。
静的なバケット数構成では、大規模なデータ移行や急速に変化するビジネス環境を効果的にサポートできません。より良いアプローチは、プラットフォームが実際のデータ量に基づいてバケット数を動的に設定することです。これにより、ユーザーは基盤となるバケット数を管理する必要がなくなり、学習曲線が低くなり、システムが変化するデータ規模により良く適応できるようになります。
ソリューション
Append Delta テーブルフォーマットは、バケットの動的割り当てをサポートするように設計されています。テーブル内のすべてのデータは自動的にバケットに分割されます。各バケットは論理的に隣接したストレージユニットであり、約 500 MB のデータを含みます。
テーブルを作成してデータを書き込む際に、バケット数を指定する必要はありません。データが継続的に書き込まれると、必要に応じて新しいバケットが自動的に作成されます。これにより、データ量の変化に伴ってバケットが大きすぎたり小さすぎたりすることによるデータスキューや断片化の懸念がなくなります。
ワークフローを次の図に示します。
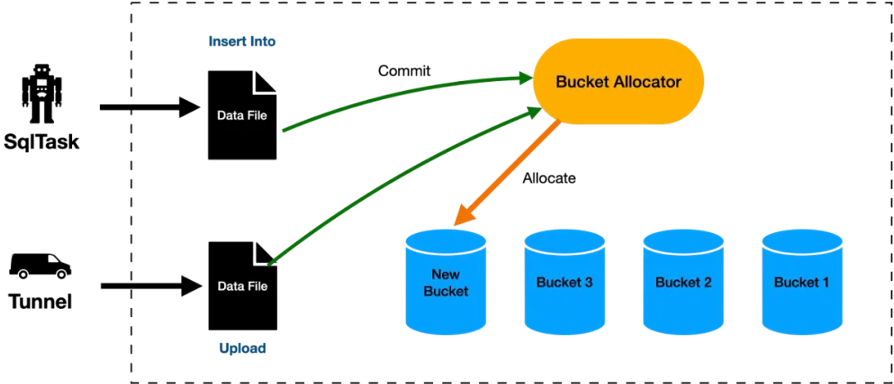
増分再クラスタリング
課題
クラスタリングは一般的なデータ最適化メソッドです。クラスターキーは、ユーザーが指定するテーブルプロパティです。指定されたデータフィールドをソートし、隣接して格納することで機能します。クエリがクラスターキーを使用すると、プッシュダウンやプルーニングなどの最適化によってデータスキャンの範囲を狭めることができます。これにより、クエリ効率が向上します。
以前は、MaxCompute はレンジクラスタリングとハッシュクラスタリングを提供していました。これらの機能は、レンジまたはハッシュによるデータのバケット化をサポートし、各バケット内のデータをソートします。これにより、クエリプロセス中にバケットとバケット内のデータをプルーニングすることでクエリを高速化します。プロセスを次の図に示します。
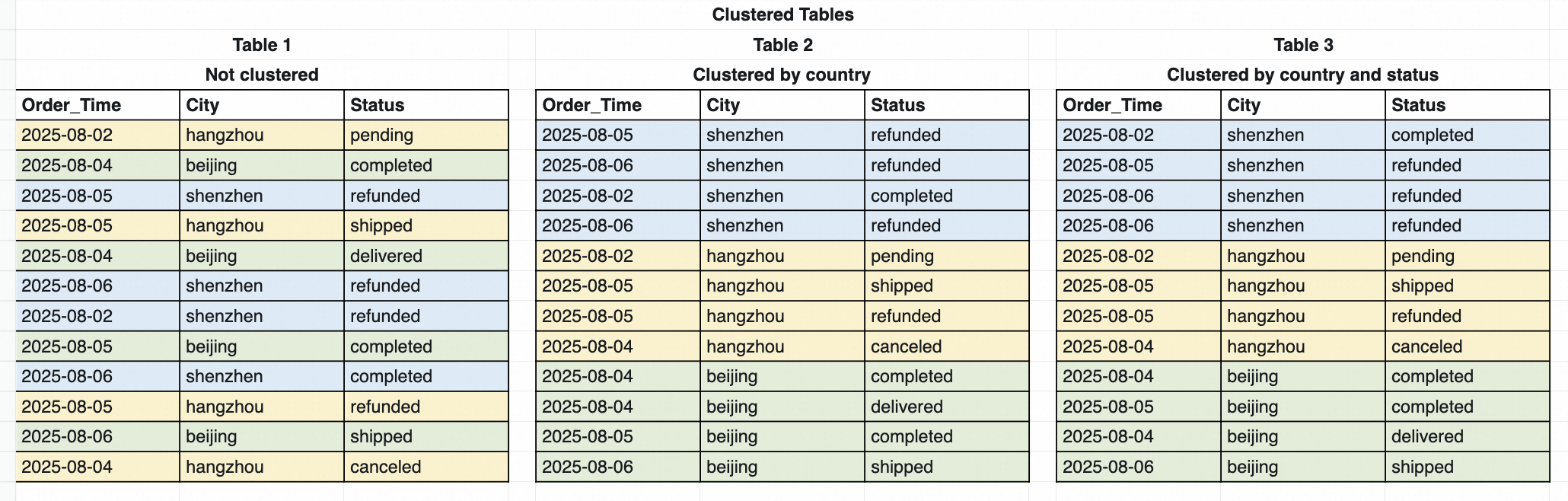
問題 1: データの追加コストが高い
レンジ/ハッシュクラスタリングを使用するテーブルの制限は、グローバルにソートされた状態を達成するために、書き込みプロセス中にデータをバケット化してソートする必要があることです。これにより、データの書き込み方法が制限されます。データは、データの挿入または上書き (INSERT INTO | INSERT OVERWRITE) を使用して単一の操作で書き込む必要があります。最初の書き込みが完了した後、さらにデータを追加するには、テーブルからすべての既存データを読み取り、新しいデータと union (UNION) を使用して結合し、データセット全体を再書き込みする必要があります。このプロセスにより、データの追加は非常に高コストで非効率になります。
通常、ビジネスではオペレーショナルデータストア (ODS) レイヤーのテーブルにクラスタリングを使用しません。これは、ODS レイヤーのデータが生のビジネスデータに近く、外部のコレクションパイプラインを通じて継続的にインポートされることが多いためです。このプロセスには高いデータインポートパフォーマンスが要求されます。従来のクラスター化テーブルの高コストな書き込みモデルでは、低レイテンシー、高スループットの書き込み要件を満たすことができません。
問題 2: DW レイヤーでのデータ鮮度のレイテンシー
そのため、ビジネスではデータウェアハウス (DW) レイヤーのテーブルにクラスターキーを設定する傾向があります。ODS テーブルの前のデータタイムスタンプのデータはクリーンアップされ、より安定した DW レイヤーにインポートされます。このプロセスにより、後続のクエリのパフォーマンスが向上します。
しかし、このアプローチは DW レイヤーのデータ鮮度に遅延をもたらします。繰り返される更新による書き込み増幅を避けるため、DW レイヤーは通常、ODS レイヤーのデータが安定した後にのみ更新されます。これにより、DW レイヤーからクエリされたデータにデータタイムスタンプの遅延が生じます。一部のシナリオでは、クエリパフォーマンスとデータ鮮度の両方に対して非常に高い要件があります。これらのシナリオでは、クエリを高速化し、リアルタイム情報を取得するために ODS レイヤーでのクラスタリングが必要です。
したがって、データ書き込み中に同期クラスタリングを実行するという元の MaxCompute ソリューションは、リアルタイムパフォーマンスに対するユーザーの要求を満たすことができません。
ソリューション
Append Delta テーブルの増分クラスタリング機能は、バックグラウンドのデータサービスを使用して非同期で増分クラスタリングを実行します。これにより、データインポートパフォーマンス、データ鮮度、およびクエリパフォーマンスの最適なバランスが実現されます。
次の図に示すように、データはストリーミング書き込みを使用して MaxCompute にインポートされます。書き込みフェーズでは、データはソートされずに直接ディスクに書き込まれ、バケットに割り当てられます。このメソッドは、書き込みスループットを最大化し、レイテンシーを最小化します。新しく書き込まれたデータはまだクラスター化されていないため、新しいバケットのデータ範囲は既存のクラスター化されたバケットのデータ範囲と重複します。クエリが実行されると、SQL エンジンはクラスター化されたバケットをプルーニングし、増分バケットをスキャンします。
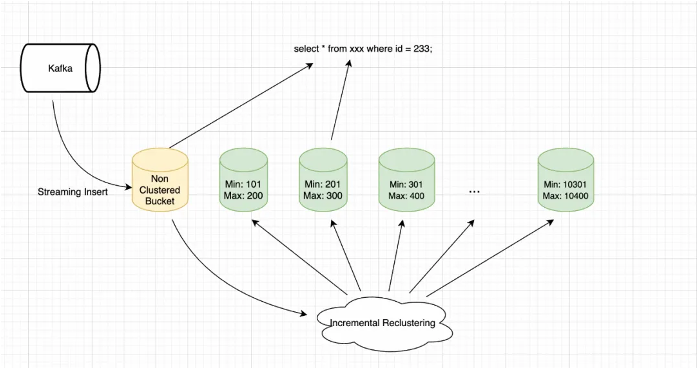
MaxCompute のバックグラウンドデータサービスは、バケット重複深度を継続的にモニターします。重複が特定のしきい値に達すると、増分再クラスタリングをトリガーします。この操作は、新しく書き込まれたバケットを再クラスタリングします。このプロセスにより、データの大部分が順序付けられた状態に保たれ、安定した全体的なクエリパフォーマンスが提供されます。