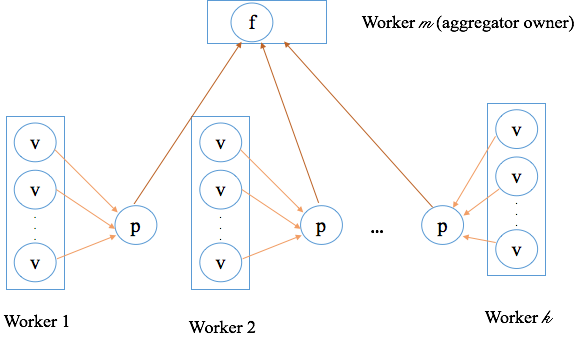
Aggregator は MaxCompute Graph の一般的な機能であり、分散ジョブにおいてすべてのワーカーにわたるグローバル情報を集約・処理します。これを使用して、グローバル条件が満たされているかどうか(機械学習における収束など)を確認したり、複数のワーカーにまたがる統計情報を維持したりできます。
仕組み
Aggregator のロジックは、部分集約を行うすべてのワーカーと、グローバル集約を行う単一の指定されたワーカー(Aggregator オーナー)の 2 か所で実行されます。
各スーパーステップは以下のシーケンスに従います。
-
各ワーカーは起動時に
createStartupValueを呼び出して、AggregatorValueを作成します。 -
各反復の開始時に、各ワーカーは
createInitialValueを呼び出して、その反復用のAggregatorValueを初期化します。 -
反復中に、各頂点は
context.aggregate()を呼び出し、これによりaggregate()がトリガーされてワーカー上で部分結果が構築されます。 -
各ワーカーはその部分結果を Aggregator オーナーワーカーに送信します。
-
Aggregator オーナーワーカーは
mergeを繰り返し呼び出して、すべての部分結果をグローバル集約結果に結合します。 -
Aggregator オーナーワーカーは
terminateを呼び出してグローバル結果を確定し、反復を終了するかどうかを決定します。
その後、グローバル結果は次のスーパーステップの開始時にすべてのワーカーに配信されます。
API オペレーション
Aggregator には 5 つの API オペレーションがあります。このうち 3 つはすべてのワーカーで実行され、部分集約を処理します。残りの 2 つは Aggregator オーナーワーカーでのみ実行され、グローバル集約を処理します。
| API | 実行環境 | 呼び出し元 | 目的 |
|---|---|---|---|
createStartupValue(context) |
すべてのワーカー | フレームワーク(各スーパーステップ前に 1 回) | 初期化 AggregatorValue |
createInitialValue(context) |
すべてのワーカー | フレームワーク(各スーパーステップ開始時に 1 回) | 現在の反復用の AggregatorValue の初期化 |
aggregate(value, item) |
すべてのワーカー | 明示的な呼び出し ComputeContext#aggregate(item) |
部分集約 |
merge(value, partial) |
Aggregator オーナーのみ | フレームワーク | 部分結果をマージしてグローバル結果を生成 |
terminate(context, value) |
Aggregator オーナーのみ | merge() |
グローバル結果を確定し、true を返して反復を終了 |
createStartupValue(context)
各スーパーステップ開始前に、すべてのワーカーで 1 回呼び出されます。AggregatorValue を初期化するために使用します。スーパーステップ 0 では、WorkerContext.getLastAggregatedValue() または ComputeContext.getLastAggregatedValue() を呼び出して初期化済みオブジェクトを取得します。
createInitialValue(context)
各スーパーステップの開始時に、すべてのワーカーで 1 回呼び出されます。現在の反復用の AggregatorValue を初期化するために使用します。通常、WorkerContext.getLastAggregatedValue() を呼び出して前回の反復の結果を取得し、それをもとに初期化します。
aggregate(value, item)
すべてのワーカーで呼び出されます。createStartupValue や createInitialValue とは異なり、このメソッドは自動的に呼び出されません。頂点コードが ComputeContext#aggregate(item) を呼び出したときにトリガーされます。
-
value:このスーパーステップにおけるワーカーの現在の集約結果(createInitialValueによって初期化) -
item:ComputeContext#aggregate(item)によって渡された値
value を item を使って更新し、部分結果を構築します。すべての aggregate 呼び出しが完了すると、フレームワークは value を Aggregator オーナーワーカーに送信します。
merge(value, partial)
Aggregator オーナーワーカーで呼び出され、すべてのワーカーからの部分結果を結合します。
-
value:実行中のグローバル集約結果 -
partial:ワーカーから受信した部分結果
partial を使用して value を更新します。たとえば、ワーカー w0、w1、w2 が部分結果 p0、p1、p2 を生成し、順に p1、p0、p2 で到着した場合:
-
merge(p1, p0)— p1 が p0 を含むように更新されます -
merge(p1, p2)— p1 が p2 を含むように更新され、p1 がグローバル集約結果となります
ワーカーが 1 つしかない場合は、merge() は呼び出されません。
terminate(context, value)
Aggregator オーナーワーカーで、すべての merge() 呼び出しが完了した後に呼び出されます。value にはグローバル集約結果が含まれます。
必要に応じて value を変更し、次のように返します。
-
true— ジョブ全体の反復を終了 -
false— 次の反復に進む
terminate() が返された後、フレームワークはグローバル集約オブジェクトを次のスーパーステップのためにすべてのワーカーに配信します。収束が完了した時点で true を返すことでジョブを即座に停止します。これは機械学習のシナリオで一般的なパターンです。
k 平均法クラスタリングの例
以下の例では、k 平均法クラスタリング用の Aggregator の実装方法を示します。主なロジックは Aggregator クラスに集中しており、ワーカー間の部分集約を調整し、収束を推進します。
完全なソースコードについては、Kmeans.gz をダウンロードしてください。以下のコードはリファレンスとして抜粋したものです。
GraphLoader
KmeansReader は入力テーブルの各行を頂点としてロードします。recordNum が頂点 ID となり、行データは頂点値として DenseVector に格納されます。(DenseVector は matrix-toolkits-java に由来します。)
public static class KmeansValue implements Writable {
DenseVector sample;
public KmeansValue() {
}
public KmeansValue(DenseVector v) {
this.sample = v;
}
@Override
public void write(DataOutput out) throws IOException {
wirteForDenseVector(out, sample);
}
@Override
public void readFields(DataInput in) throws IOException {
sample = readFieldsForDenseVector(in);
}
}public static class KmeansReader extends
GraphLoader<LongWritable, KmeansValue, NullWritable, NullWritable> {
@Override
public void load(
LongWritable recordNum,
WritableRecord record,
MutationContext<LongWritable, KmeansValue, NullWritable, NullWritable> context)
throws IOException {
KmeansVertex v = new KmeansVertex();
v.setId(recordNum);
int n = record.size();
DenseVector dv = new DenseVector(n);
for (int i = 0; i < n; i++) {
dv.set(i, ((DoubleWritable)record.get(i)).get());
}
v.setValue(new KmeansValue(dv));
context.addVertexRequest(v);
}
}頂点
各頂点はサンプルを部分集約に提供します。compute ロジック全体は、単一の context.aggregate() 呼び出しで構成されます。
public static class KmeansVertex extends
Vertex<LongWritable, KmeansValue, NullWritable, NullWritable> {
@Override
public void compute(
ComputeContext<LongWritable, KmeansValue, NullWritable, NullWritable> context,
Iterable<NullWritable> messages) throws IOException {
context.aggregate(getValue()); // この頂点のサンプルを部分集約に提出
}
}Aggregator
KmeansAggrValue は、ワーカー間で集約され、各スーパーステップで再配信されるデータを保持します。
public static class KmeansAggrValue implements Writable {
DenseMatrix centroids; // 現在のクラスターセンターの K x m マトリックス
DenseMatrix sums; // センター再計算用のクラスターディメンションごとの累積和
DenseVector counts; // 各クラスターセンターに割り当てられたサンプル数
@Override
public void write(DataOutput out) throws IOException {
wirteForDenseDenseMatrix(out, centroids);
wirteForDenseDenseMatrix(out, sums);
wirteForDenseVector(out, counts);
}
@Override
public void readFields(DataInput in) throws IOException {
centroids = readFieldsForDenseMatrix(in);
sums = readFieldsForDenseMatrix(in);
counts = readFieldsForDenseVector(in);
}
}sums(i,j) は、センター i に最も近いすべてのサンプルのディメンション j の合計を格納します。counts と併用することで、各スーパーステップで新しいセンター位置を再計算します。
createStartupValue — centers キャッシュファイルから初期センターを読み取り、sums および counts をゼロに初期化します。
public static class KmeansAggregator extends Aggregator<KmeansAggrValue> {
public KmeansAggrValue createStartupValue(WorkerContext context) throws IOException {
KmeansAggrValue av = new KmeansAggrValue();
byte[] centers = context.readCacheFile("centers"); // 初期クラスターセンターをロード
String lines[] = new String(centers).split("\n");
int rows = lines.length;
int cols = lines[0].split(",").length; // 行数 >= 1 を前提とする
av.centroids = new DenseMatrix(rows, cols);
av.sums = new DenseMatrix(rows, cols);
av.sums.zero(); // 最初のスーパーステップ前にゼロに初期化
av.counts = new DenseVector(rows);
av.counts.zero(); // 最初のスーパーステップ前にゼロに初期化
for (int i = 0; i < lines.length; i++) {
String[] ss = lines[i].split(",");
for (int j = 0; j < ss.length; j++) {
av.centroids.set(i, j, Double.valueOf(ss[j]));
}
}
return av;
}
}createInitialValue — sums および counts をゼロにリセットしながら、前回の反復の centroids は保持します。
@Override
public KmeansAggrValue createInitialValue(WorkerContext context)
throws IOException {
KmeansAggrValue av = (KmeansAggrValue)context.getLastAggregatedValue(0);
// アキュムレーターをリセットし、前回の反復の重心を保持
av.sums.zero();
av.counts.zero();
return av;
}aggregate — 各サンプルに対して最も近い重心を見つけ、sums および counts を累積します(各ワーカーでの部分集約)。
@Override
public void aggregate(KmeansAggrValue value, Object item)
throws IOException {
DenseVector sample = ((KmeansValue)item).sample;
int min = findNearestCentroid(value.centroids, sample); // 最も近いクラスターセンターを検索
for (int i = 0; i < sample.size(); i ++) {
value.sums.add(min, i, sample.get(i)); // サンプルディメンションを累積
}
value.counts.add(min, 1.0d); // このクラスターのサンプル数をインクリメント
}merge — すべてのワーカーからの部分結果を、sums および counts を合計することで結合します(Aggregator オーナーワーカーでのグローバル集約)。
@Override
public void merge(KmeansAggrValue value, KmeansAggrValue partial)
throws IOException {
value.sums.add(partial.sums); // このワーカーからの sums を累積
value.counts.add(partial.counts); // このワーカーからの counts を累積
}terminate — 新しいクラスターセンターを計算し、ユークリッド距離を用いてしきい値 0.05 で収束をチェックし、反復を終了するかどうかを決定します。
@Override
public boolean terminate(WorkerContext context, KmeansAggrValue value)
throws IOException {
// 集約された sums および counts から新しいセンターを計算
DenseMatrix newCentriods = calculateNewCentroids(value.sums, value.counts, value.centroids);
// デバッグ用に古い重心と新しい重心を出力
System.out.println("\nsuperstep: " + context.getSuperstep() +
"\nold centriod:\n" + value.centroids + " new centriod:\n" + newCentriods);
boolean converged = isConverged(newCentriods, value.centroids, 0.05d); // ユークリッド距離のしきい値
System.out.println("superstep: " + context.getSuperstep() + "/"
+ (context.getMaxIteration() - 1) + " converged: " + converged);
if (converged || context.getSuperstep() == context.getMaxIteration() - 1) {
// 収束した、または最大反復回数に達した — 最終的なセンターを書き込み、停止
for (int i = 0; i < newCentriods.numRows(); i++) {
Writable[] centriod = new Writable[newCentriods.numColumns()];
for (int j = 0; j < newCentriods.numColumns(); j++) {
centriod[j] = new DoubleWritable(newCentriods.get(i, j));
}
context.write(centriod);
}
return true; // 反復を終了
}
value.centroids.set(newCentriods); // 次の反復のためにセンターを更新
return false; // 反復を継続
}main メソッド
main メソッドは GraphJob を構築し、すべてのコンポーネントクラスを設定してジョブを送信します。デフォルトの最大反復回数は 30 で、第 3 引数で設定可能です。
public static void main(String[] args) throws IOException {
if (args.length < 2)
printUsage();
GraphJob job = new GraphJob();
job.setGraphLoaderClass(KmeansReader.class);
job.setRuntimePartitioning(false); // 各ワーカーが独自のデータパーティションをロードして保持
job.setVertexClass(KmeansVertex.class);
job.setAggregatorClass(KmeansAggregator.class); // Aggregator 実装を登録
job.addInput(TableInfo.builder().tableName(args[0]).build());
job.addOutput(TableInfo.builder().tableName(args[1]).build());
// デフォルトの最大反復回数は 30
job.setMaxIteration(30);
if (args.length >= 3)
job.setMaxIteration(Integer.parseInt(args[2]));
long start = System.currentTimeMillis();
job.run();
System.out.println("Job Finished in "
+ (System.currentTimeMillis() - start) / 1000.0 + " seconds");
}job.setRuntimePartitioningがfalseに設定されている場合、各ワーカーによってロードされたデータは partitioner によってパーティション分割されません。各ワーカーが独自のデータをロードして保持します。