このトピックでは、Spark を使用して Phoenix に接続し、HBase のデータを MaxCompute に書き込む方法について説明します。
背景情報
Phoenix は HBase の SQL レイヤーです。高い同時実行性、低レイテンシー、および単純なクエリを必要とするシナリオ向けに設計されています。このトピックでは、Spark on MaxCompute を使用して Phoenix データにアクセスする方法について説明します。この手順には、Phoenix テーブルの作成、テーブルへのデータの書き込み、IntelliJ IDEA での Spark コードの作成、DataWorks でのコードのスモークテストの実行が含まれます。
前提条件
開始する前に、次の前提条件を満たしてください。
MaxCompute を有効化し、MaxCompute プロジェクトを作成します。詳細については、「MaxCompute の有効化」および「MaxCompute プロジェクトの作成」をご参照ください。
DataWorks を有効化します。詳細については、「DataWorks 購入ガイド」をご参照ください。
HBase を有効化します。詳細については、「HBase 購入ガイド」をご参照ください。
説明このチュートリアルでは、HBase 1.1 を例として使用します。開発環境では、他のバージョンの HBase を使用できます。
Phoenix 4.12.0 をダウンロードしてインストールします。詳細については、「HBase SQL (Phoenix) 4.x の使用」をご参照ください。
説明HBase 1.1 は Phoenix 4.12.0 に対応しています。開発中にバージョンに互換性があることを確認してください。
VPC を有効にし、HBase クラスターのセキュリティグループを設定します。詳細については、「ネットワーク接続手順」をご参照ください。
説明このチュートリアルでは、HBase クラスターは VPC 内にあります。したがって、セキュリティグループでポート 2181、10600、および 16020 を開く必要があります。
手順
Phoenix の
binディレクトリに移動し、次のサンプルコマンドを実行して Phoenix クライアントを起動します。./sqlline.py hb-2zecxg2ltnpeg8me4-master*-***.hbase.rds.aliyuncs.com:2181,hb-2zecxg2ltnpeg8me4-master*-***.hbase.rds.aliyuncs.com:2181,hb-2zecxg2ltnpeg8me4-master*-***.hbase.rds.aliyuncs.com:2181説明hb-2zecxg2ltnpeg8me4-master*-***.hbase.rds.aliyuncs.com:2181,hb-2zecxg2ltnpeg8me4-master*-***.hbase.rds.aliyuncs.com:2181,hb-2zecxg2ltnpeg8me4-master*-***.hbase.rds.aliyuncs.com:2181は ZooKeeper の接続アドレスです。HBase コンソールにログインし、HBase クラスターインスタンスの詳細ページの[データベース接続] ページから ZooKeeper 接続アドレスを取得できます。Phoenix クライアントで、次のステートメントを実行して users という名前のテーブルを作成し、データを挿入します。
CREATE TABLE IF NOT EXISTS users( id UNSIGNED_INT, username char(50), password char(50) CONSTRAINT my_ph PRIMARY KEY (id)); UPSERT INTO users(id,username,password) VALUES (1,'kongxx','Letmein');説明Phoenix の構文の詳細については、「HBase SQL (Phoenix) の使用開始」をご参照ください。
Phoenix クライアントで、次のステートメントを実行して users テーブルのデータを表示します。
select * from users;IntelliJ IDEA で Spark コードを記述してパッケージ化します。
Scala プログラミング言語を使用して Spark テストコードを記述します。
IntelliJ IDEA で、POM ファイルを使用してローカル開発環境を設定します。まず、パブリックエンドポイントを使用してテストできます。コードが検証されたら、サンプルコードの spark.hadoop.odps.end.point パラメーターの値を調整します。パブリックエンドポイントを取得するには、HBase コンソールにログインし、HBase クラスターインスタンスの詳細ページの[データベース接続] ページに移動します。以下にサンプルコードを示します。
package com.phoenix import org.apache.hadoop.conf.Configuration import org.apache.spark.sql.SparkSession import org.apache.phoenix.spark._ /** * この例は Phoenix 4.x に適用されます。 */ object SparkOnPhoenix4xSparkSession { def main(args: Array[String]): Unit = { // HBase クラスターの ZooKeeper 接続アドレス。 val zkAddress = hb-2zecxg2ltnpeg8me4-master*-***.hbase.rds.aliyuncs.com:2181,hb-2zecxg2ltnpeg8me4-master*-***.hbase.rds.aliyuncs.com:2181,hb-2zecxg2ltnpeg8me4-master*-***.hbase.rds.aliyuncs.com:2181 // Phoenix のテーブル名。 val phoenixTableName = users // Spark のテーブル名。 val ODPSTableName = users_phoenix val sparkSession = SparkSession .builder() .appName("SparkSQL-on-MaxCompute") .config("spark.sql.broadcastTimeout", 20 * 60) .config("spark.sql.crossJoin.enabled", true) .config("odps.exec.dynamic.partition.mode", "nonstrict") // spark.master を local[N] に設定してコードを直接実行します。N は同時操作の数です。 //.config("spark.master", "local[4]") .config("spark.hadoop.odps.project.name", "***") .config("spark.hadoop.odps.access.id", "***") .config("spark.hadoop.odps.access.key", "***") //.config("spark.hadoop.odps.end.point", "http://service.cn.maxcompute.aliyun.com/api") .config("spark.hadoop.odps.end.point", "http://service.cn-beijing.maxcompute.aliyun-inc.com/api") .config("spark.sql.catalogImplementation", "odps") .getOrCreate() var df = sparkSession.read.format("org.apache.phoenix.spark").option("table", phoenixTableName).option("zkUrl",zkAddress).load() df.show() df.write.mode("overwrite").insertInto(ODPSTableName) } }以下は POM ファイルです。
<?xml version="1.0" encoding="UTF-8"?> <!-- Apache License, Version 2.0 (「本ライセンス」) に基づいてライセンスされます。 お客様が本ライセンスに準拠しない限り、このファイルを使用することはできません。 ライセンスのコピーは、次の場所で入手できます。 http://www.apache.org/licenses/LICENSE-2.0 適用される法律または書面による同意がない限り、 本ライセンスに基づいて配布されるソフトウェアは、明示または黙示を問わず、 いかなる保証も条件もなしに「現状のまま」で配布されます。 本ライセンスに基づく権利および制限を規定する特定の言語については、 本ライセンスをご参照ください。添付の LICENSE ファイルをご参照ください。 --> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <properties> <spark.version>2.3.0</spark.version> <cupid.sdk.version>3.3.8-public</cupid.sdk.version> <scala.version>2.11.8</scala.version> <scala.binary.version>2.11</scala.binary.version> <phoenix.version>4.12.0-HBase-1.1</phoenix.version> </properties> <groupId>com.aliyun.odps</groupId> <artifactId>Spark-Phonix</artifactId> <version>1.0.0-SNAPSHOT</version> <packaging>jar</packaging> <dependencies> <dependency> <groupId>org.jpmml</groupId> <artifactId>pmml-model</artifactId> <version>1.3.8</version> </dependency> <dependency> <groupId>org.jpmml</groupId> <artifactId>pmml-evaluator</artifactId> <version>1.3.10</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_${scala.binary.version}</artifactId> <version>${spark.version}</version> <scope>provided</scope> <exclusions> <exclusion> <groupId>org.scala-lang</groupId> <artifactId>scala-library</artifactId> </exclusion> <exclusion> <groupId>org.scala-lang</groupId> <artifactId>scalap</artifactId> </exclusion> </exclusions> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_${scala.binary.version}</artifactId> <version>${spark.version}</version> <scope>provided</scope> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-mllib_${scala.binary.version}</artifactId> <version>${spark.version}</version> <scope>provided</scope> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming_${scala.binary.version}</artifactId> <version>${spark.version}</version> <scope>provided</scope> </dependency> <dependency> <groupId>com.aliyun.odps</groupId> <artifactId>cupid-sdk</artifactId> <version>${cupid.sdk.version}</version> <scope>provided</scope> </dependency> <dependency> <groupId>com.aliyun.phoenix</groupId> <artifactId>ali-phoenix-core</artifactId> <version>4.12.0-AliHBase-1.1-0.8</version> <exclusions> <exclusion> <groupId>com.aliyun.odps</groupId> <artifactId>odps-sdk-mapred</artifactId> </exclusion> <exclusion> <groupId>com.aliyun.odps</groupId> <artifactId>odps-sdk-commons</artifactId> </exclusion> </exclusions> </dependency> <dependency> <groupId>com.aliyun.phoenix</groupId> <artifactId>ali-phoenix-spark</artifactId> <version>4.12.0-AliHBase-1.1-0.8</version> <exclusions> <exclusion> <groupId>com.aliyun.phoenix</groupId> <artifactId>ali-phoenix-core</artifactId> </exclusion> </exclusions> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-shade-plugin</artifactId> <version>2.4.3</version> <executions> <execution> <phase>package</phase> <goals> <goal>shade</goal> </goals> <configuration> <minimizeJar>false</minimizeJar> <shadedArtifactAttached>true</shadedArtifactAttached> <artifactSet> <includes> <!-- ここに、fat jar にパッケージ化する依存関係を含めます --> <include>*:*</include> </includes> </artifactSet> <filters> <filter> <artifact>*:*</artifact> <excludes> <exclude>META-INF/*.SF</exclude> <exclude>META-INF/*.DSA</exclude> <exclude>META-INF/*.RSA</exclude> <exclude>**/log4j.properties</exclude> </excludes> </filter> </filters> <transformers> <transformer implementation="org.apache.maven.plugins.shade.resource.AppendingTransformer"> <resource>reference.conf</resource> </transformer> <transformer implementation="org.apache.maven.plugins.shade.resource.AppendingTransformer"> <resource>META-INF/services/org.apache.spark.sql.sources.DataSourceRegister</resource> </transformer> </transformers> </configuration> </execution> </executions> </plugin> <plugin> <groupId>net.alchim31.maven</groupId> <artifactId>scala-maven-plugin</artifactId> <version>3.3.2</version> <executions> <execution> <id>scala-compile-first</id> <phase>process-resources</phase> <goals> <goal>compile</goal> </goals> </execution> <execution> <id>scala-test-compile-first</id> <phase>process-test-resources</phase> <goals> <goal>testCompile</goal> </goals> </execution> </executions> </plugin> </plugins> </build> </project>IntelliJ IDEA で、コードと依存関係ファイルを JAR ファイルにパッケージ化します。次に、MaxCompute クライアントを使用して、JAR ファイルを MaxCompute プロジェクト環境にアップロードします。詳細については、「リソースの追加」をご参照ください。
説明DataWorks インターフェイスには、JAR ファイルのアップロード制限が 50 MB あります。したがって、MaxCompute クライアントを使用して JAR ファイルをアップロードする必要があります。
DataWorks でスモークテストを実行します。
DataWorks で、次のステートメントを実行して MaxCompute テーブルを作成します。詳細については、「MaxCompute テーブルの作成と使用」をご参照ください。
CREATE TABLE IF NOT EXISTS users_phoenix ( id INT , username STRING, password STRING ) ;DataWorks で、MaxCompute プロジェクト環境を選択し、アップロードされた JAR ファイルをリソースとしてデータ開発環境に追加します。詳細については、「MaxCompute リソースの作成と使用」をご参照ください。
ODPS Spark ノードを作成し、ジョブパラメーターを設定します。詳細については、「ODPS Spark ジョブの開発」をご参照ください。
次の図は、Spark ジョブを送信するための構成パラメーターを示しています。
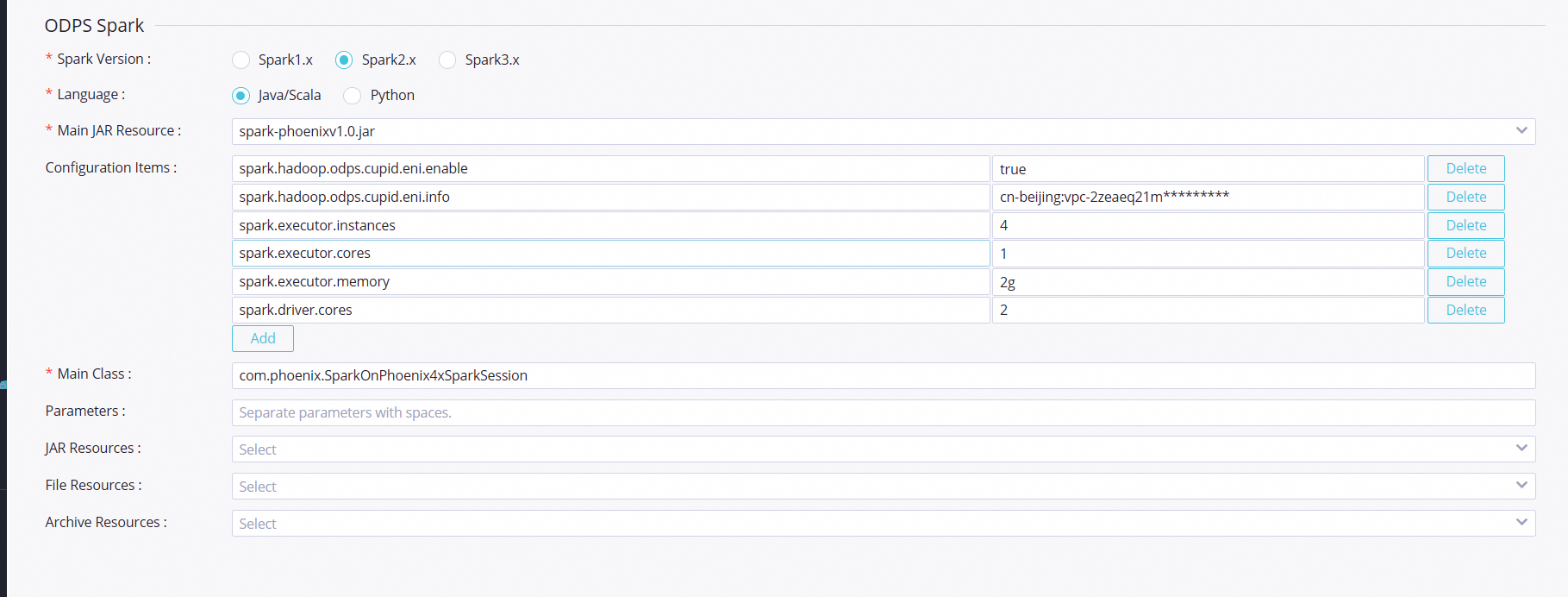
spark.hadoop.odps.cupid.eni.enable = true spark.hadoop.odps.cupid.eni.info=cn-beijing:vpc-2zeaeq21mb1dmkqh0**** アイコンをクリックしてスモークテストを開始します。
アイコンをクリックしてスモークテストを開始します。
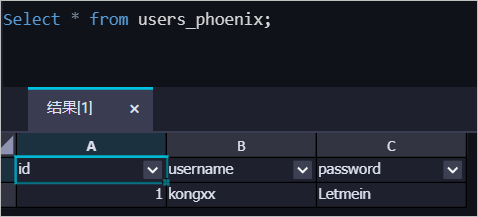
スモークテストが成功したら、アドホッククエリノードで次のクエリ文を実行します。
SELECT * FROM users_phoenix;次の図に示すように、データは MaxCompute テーブルに書き込まれます。