このトピックでは、MaxCompute から Hologres にアクセスする方法について説明します。
背景情報
Hologres は Alibaba Cloud のリアルタイムインタラクティブ分析プロダクトです。データ移行なしに MaxCompute データ分析を高性能でアクセラレーションできます。Hologres のリアルタイムデータと MaxCompute のオフラインデータに対してフェデレーテッド分析を実行することで、リアルタイムとオフラインの両方に対応した統合データウェアハウスを構築できます。この組み合わせにより、大規模オフライン分析、リアルタイム運用分析、インタラクティブクエリなど、さまざまなビジネスシナリオの要件を満たすことができます。
MaxCompute SQL 外部テーブルを使用して Hologres にアクセスする方法については、「MaxCompute SQL 外部テーブルを使用した Hologres アクセス」をご参照ください。
MaxCompute Spark を使用して Hologres にアクセスする方法については、以下のトピックをご参照ください。
前提条件
MaxCompute 環境を準備済みです。
MaxCompute を有効化し、Hologres 外部テーブルをホストする MaxCompute プロジェクトを作成済みです。
詳細については、「MaxCompute の有効化」および「MaxCompute プロジェクトの作成」をご参照ください。
MaxCompute クライアントをインストール済みです。
手順については、「MaxCompute クライアントのインストールと設定」をご参照ください。
MaxCompute Spark の開発環境をセットアップ済みです。
このチュートリアルでは、Linux オペレーティングシステムと Spark 2.4.5 リリースパッケージを使用します。詳細な手順については、「MaxCompute Spark の開発環境のセットアップ」をご参照ください。
DataWorks を有効化済みです。
詳細については、「DataWorks の有効化」をご参照ください。
Hologres を有効化し、HoloWeb に接続済みです。
詳細については、「Hologres の有効化」および「HoloWeb への接続とクエリの実行」をご参照ください。
PostgreSQL JDBC ドライバーをダウンロード済みです。
このチュートリアルでは、Linux システムの /home/postgreSQL ディレクトリに保存されている
postgresql-42.2.16.jarドライバーを使用します。
SQL 外部テーブルを使用した Hologres アクセス
Hologres コンソールでターゲットインスタンスを選択し、
mc_db_holoという名前の Hologres データベースを作成します。 詳細については、「Hologres データベースの作成」をご参照ください。HoloWeb で、
mc_db_holoデータベースに対して次の文を実行し、mc_sql_holoテーブルを作成してデータを挿入します。Hologres テーブルの作成方法については、「Hologres テーブルの作成」をご参照ください。
CREATE TABLE mc_sql_holo( id INTEGER, name TEXT ); INSERT INTO mc_sql_holo VALUES (1,'zhangsan'), (2,'lisi'), (3,'wangwu') ;RAM コンソールで、
AliyunOdpsHoloRoleという名前の RAM ロールを作成し、その信頼ポリシーを変更します。RAM ロールの作成方法については、「RAM ロールの作成」をご参照ください。
説明このチュートリアルでは、RAM ロールの信頼できるエンティティは Alibaba Cloud アカウント です。
AliyunOdpsHoloRoleRAM ロールを Hologres インスタンスに追加し、権限を付与します。詳細については、「Hologres インスタンスへの RAM ロールの追加と権限付与」をご参照ください。
MaxCompute クライアントで、次の文を実行して
mc_externaltable_holoという名前の外部テーブルを作成します。create external table if not exists mc_externaltable_holo ( id int , name string ) stored by 'com.aliyun.odps.jdbc.JdbcStorageHandler' with serdeproperties ( 'odps.properties.rolearn'='acs:ram::13969******5947:role/aliyunodpsholorole') LOCATION 'jdbc:postgresql://hgprecn-cn-2r42******-cn-hangzhou-internal.hologres.aliyuncs.com:80/mc_db_holo?currentSchema=public&useSSL=false&table=mc_sql_holo/' TBLPROPERTIES ( 'mcfed.mapreduce.jdbc.driver.class'='org.postgresql.Driver', 'odps.federation.jdbc.target.db.type'='holo', 'odps.federation.jdbc.colmapping'='id:id,name:name' );説明外部テーブルの作成に使用されるパラメーターの詳細については、「Hologres 外部テーブル」をご参照ください。
外部テーブルを作成後、MaxCompute クライアントで次の文を実行して Hologres 外部テーブルをクエリします。
set odps.sql.split.hive.bridge=true; set odps.sql.hive.compatible=true; select * from mc_externaltable_holo limit 10;説明SET操作のプロパティの詳細については、「SET 操作」をご参照ください。クエリの結果は次のとおりです。
+----+----------+ | id | name | +----+----------+ | 1 | zhangsan | | 2 | lisi | | 3 | wangwu | +----+----------+MaxCompute クライアントで次の文を実行して、Hologres 外部テーブルにデータを書き込みます。
set odps.sql.split.hive.bridge=true; set odps.sql.hive.compatible=true; insert into mc_externaltable_holo values (4,'alice');HoloWeb で、
mc_sql_holoテーブルのデータをクエリし、新しいデータが書き込まれたことを確認します。select * from mc_sql_holo;
ローカルモードでの Spark による Hologres アクセス
HoloWeb で、
mc_db_holoデータベースに対して次の文を実行し、mc_jdbc_holoという名前の Hologres テーブルを作成します。Hologres テーブルの作成方法については、「Hologres テーブルの作成」をご参照ください。
CREATE TABLE mc_jdbc_holo( id INTEGER, name TEXT );Linux システム上で、/home/pythoncode ディレクトリに
holo_local.pyという名前の Python ファイルを作成します。以下のコードはサンプル Python スクリプトです。
from pyspark.sql import SparkSession spark = SparkSession \ .builder \ .appName("Spark_local") \ .config("spark.eventLog.enabled","false") \ .getOrCreate() jdbcDF = spark.read.format("jdbc"). \ options( url='jdbc:postgresql://hgprecn-cn-2r42******-cn-hangzhou.hologres.aliyuncs.com:80/mc_db_holo', dbtable='mc_jdbc_holo', user='LTAI****************', password='********************', driver='org.postgresql.Driver').load() jdbcDF.printSchema()以下の表は、スクリプト内のパラメーターを示しています。
url:
postgresqlドライバーを使用する JDBC 接続 URL です。hgprecn-cn-2r42******-cn-hangzhou.hologres.aliyuncs.com:80: Hologres インスタンスのパブリックエンドポイントです。エンドポイントを取得する方法については、「インスタンスの詳細の表示」をご参照ください。
mc_db_holo: ターゲット Hologres データベースの名前です。このチュートリアルでは、データベース名は mc_db_holo です。
dbtable: Hologres 内のソーステーブルの名前です。このチュートリアルでは、テーブル名は mc_jdbc_holo です。
user: Alibaba Cloud アカウントまたは RAM ユーザーの AccessKey ID です。AccessKey 管理ページで AccessKey ID を取得できます。
password: 指定された AccessKey ID の AccessKey Secret です。AccessKey 管理ページで AccessKey Secret を取得できます。
driver: PostgreSQL ドライバーです。値は org.postgresql.Driver である必要があります。
Linux システム上の任意のディレクトリから、spark-submit コマンドを実行してローカルジョブを送信します。
spark-submit -- master local -- driver-class-path /home/postgreSQL/postgresql-42.2.16.jar -- jars /home/postgreSQL/postgresql-42.2.16.jar /home/pythoncode/holo_local.pySpark ログを確認します。
mc_jdbc_holoテーブルのスキーマと出力されたスキーマが一致する場合、接続は成功しています。
クラスターモードでの Spark による Hologres アクセス
HoloWeb で、
mc_db_holoデータベースに対して次の文を実行し、mc_jdbc_holoという名前の Hologres テーブルを作成します。Hologres テーブルの作成方法については、「Hologres テーブルの作成」をご参照ください。
CREATE TABLE mc_jdbc_holo( id INTEGER, name TEXT );Linux システム上で、/home/pythoncode ディレクトリに
holo_yarncluster.pyという名前の Python ファイルを作成します。以下のコードはサンプル Python スクリプトです。
from pyspark.sql import SparkSession spark = SparkSession \ .builder \ .appName("Spark_yarn") \ .getOrCreate() jdbcDF = spark.read.format("jdbc"). \ options( url='jdbc:postgresql://hgprecn-cn-2r42******-cn-hangzhou-internal.hologres.aliyuncs.com:80/mc_db_holo', dbtable='mc_jdbc_holo', user='LTAI****************', password='********************', driver='org.postgresql.Driver').load() jdbcDF.printSchema()以下の表は、スクリプト内のパラメーターを示しています。
url: postgresql ドライバーを使用する JDBC 接続 URL です。
hgprecn-cn-2r42******-cn-hangzhou-internal.hologres.aliyuncs.com:80: Hologres インスタンスのクラシックネットワークエンドポイントです。エンドポイントを取得する方法については、「インスタンスの詳細の表示」をご参照ください。
mc_db_holo: ターゲット Hologres データベースの名前です。このチュートリアルでは、データベース名は mc_db_holo です。
dbtable: Hologres 内のソーステーブルの名前です。このチュートリアルでは、テーブル名は mc_jdbc_holo です。
user: Alibaba Cloud アカウントまたは RAM ユーザーの AccessKey ID です。AccessKey 管理ページで AccessKey ID を取得できます。
password: 指定された AccessKey ID の AccessKey Secret です。AccessKey 管理ページで AccessKey Secret を取得できます。
driver: PostgreSQL ドライバーです。値は org.postgresql.Driver である必要があります。
MaxCompute Spark クライアントを解凍したディレクトリの /home/spark2.4.5/spark-2.4.5-odps0.33.2/conf にある
spark-defaults.confファイルを設定します。# 次の構成を設定します。 spark.hadoop.odps.project.name = <MaxCompute_Project_Name> spark.hadoop.odps.end.point = <Endpoint> spark.hadoop.odps.runtime.end.point = <VPC_Endpoint> spark.hadoop.odps.access.id = <AccessKey_ID> spark.hadoop.odps.access.key = <AccessKey_Secret> spark.hadoop.odps.cupid.trusted.services.access.list = <Hologres_Classic_Network> # 以下の内容は変更しません。 spark.master = yarn-cluster spark.driver.cores = 2 spark.driver.memory = 4g spark.dynamicAllocation.shuffleTracking.enabled = true spark.dynamicAllocation.shuffleTracking.timeout = 20s spark.dynamicAllocation.enabled = true spark.dynamicAllocation.maxExecutors = 10 spark.dynamicAllocation.initialExecutors = 2 spark.executor.cores = 2 spark.executor.memory = 8g spark.eventLog.enabled = true spark.eventLog.overwrite = true spark.eventLog.dir = odps://admin_task_project/cupidhistory/sparkhistory spark.sql.catalogImplementation = hive spark.sql.sources.default = hive以下の表は、構成ファイル内のパラメーターを示しています。
MaxCompute_Project_Name: アクセスする MaxCompute プロジェクトの名前です。
これは MaxCompute プロジェクト名であり、ワークスペース名ではありません。MaxCompute コンソールにログインし、左上隅でリージョンを切り替えて、左側のナビゲーションウィンドウで を選択すると、プロジェクト名を確認できます。
AccessKey_ID: 対象の MaxCompute プロジェクトにアクセスする権限を持つ AccessKey ID です。
AccessKey 管理ページで AccessKey ID を取得できます。
AccessKey_Secret: 指定された AccessKey ID の AccessKey Secret です。
Endpoint: MaxCompute プロジェクトが存在するリージョンのパブリックエンドポイントです。
各リージョンのパブリックエンドポイントの詳細については、「エンドポイント」をご参照ください。
VPC_Endpoint: MaxCompute プロジェクトが存在するリージョンの VPC エンドポイントです。
各リージョンの VPC エンドポイントの詳細については、「VPC エンドポイント」をご参照ください。
Hologres_Classic_Network: Hologres インスタンスのクラシックネットワークエンドポイントです。この設定により、MaxCompute サンドボックス環境から Hologres インスタンスへの接続を許可するネットワークポリシーが構成されます。この設定がないと、MaxCompute クラスターは外部サービスにアクセスできません。
Linux システム上の任意のディレクトリから、spark-submit コマンドを実行してジョブを送信します。
spark-submit -- master yarn-cluster -- driver-class-path /home/postgreSQL/postgresql-42.2.16.jar -- jars /home/postgreSQL/postgresql-42.2.16.jar /home/pythoncode/holo_yarncluster.pyジョブを送信後、正常に完了したジョブからは診断用の Logview URL および Spark UI Jobview URL が返されます。
ジョブの Logview URL。

Spark UI Jobview URL。

Logview URL を開きます。ジョブステータスが success の場合、 に移動して、
jdbcDF.printSchema()の出力を確認します。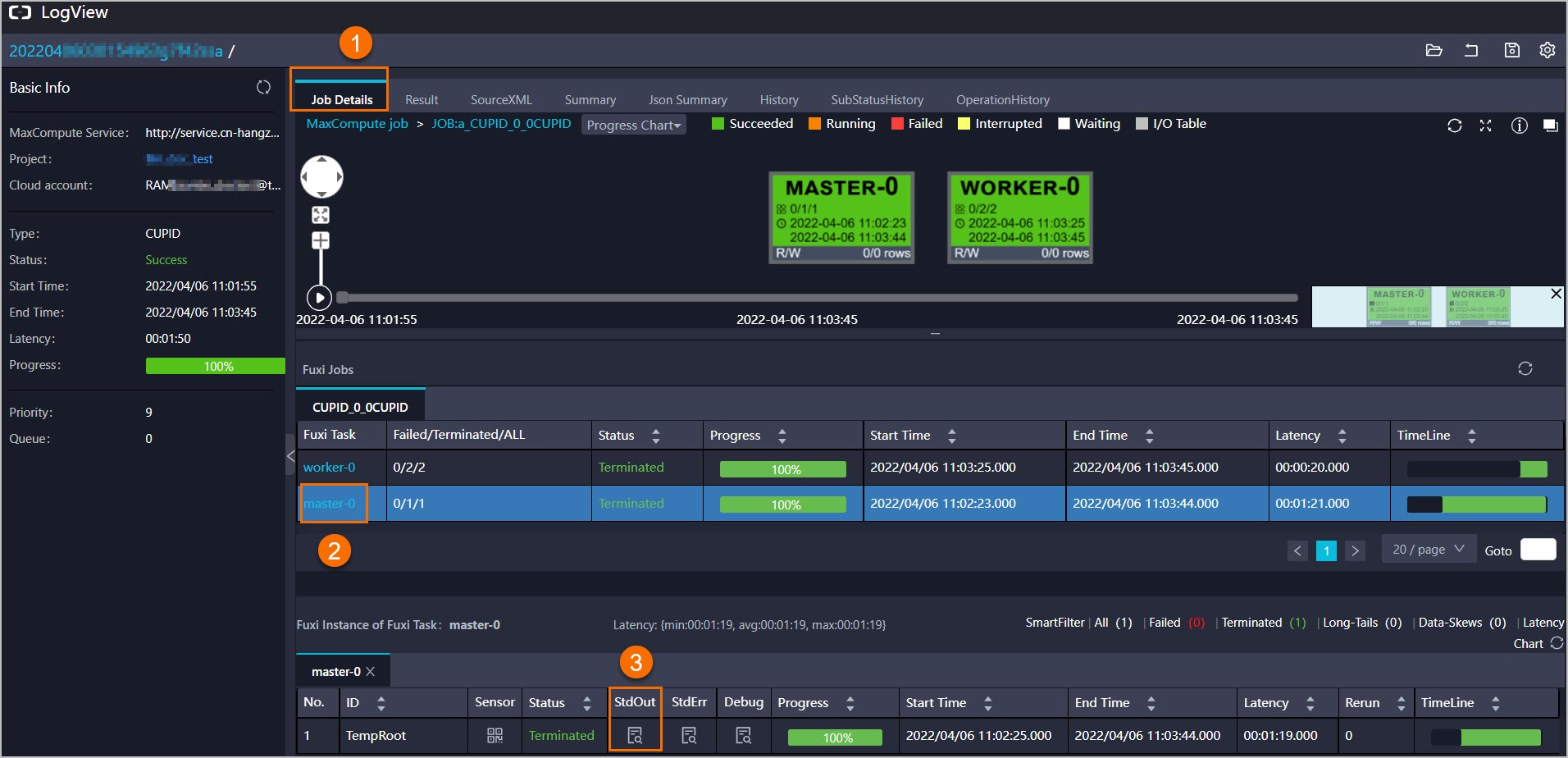
StdOut ログを確認します。
mc_jdbc_holoテーブルのスキーマと出力されたスキーマが一致する場合、接続は成功しています。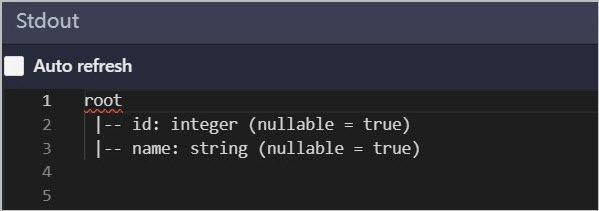 説明
説明Spark UI Jobview URL を開いて、ジョブを表示および診断することもできます。
DataWorks での Spark による Hologres アクセス
HoloWeb で、
mc_db_holoデータベースに対して次の文を実行し、mc_jdbc_holoという名前の Hologres テーブルを作成します。Hologres テーブルの作成方法については、「Hologres テーブルの作成」をご参照ください。
CREATE TABLE mc_jdbc_holo( id INTEGER, name TEXT );MaxCompute Spark クライアントを解凍したディレクトリの /home/spark2.4.5/spark-2.4.5-odps0.33.2/conf にある
spark-defaults.confファイルを設定します。# 次の構成を設定します。 spark.hadoop.odps.project.name = <MaxCompute_Project_Name> spark.hadoop.odps.end.point = <Endpoint> spark.hadoop.odps.runtime.end.point = <VPC_Endpoint> spark.hadoop.odps.access.id = <AccessKey_ID> spark.hadoop.odps.access.key = <AccessKey_Secret> spark.hadoop.odps.cupid.trusted.services.access.list = <Hologres_Classic_Network> # 以下の内容は変更しません。 spark.master = yarn-cluster spark.driver.cores = 2 spark.driver.memory = 4g spark.dynamicAllocation.shuffleTracking.enabled = true spark.dynamicAllocation.shuffleTracking.timeout = 20s spark.dynamicAllocation.enabled = true spark.dynamicAllocation.maxExecutors = 10 spark.dynamicAllocation.initialExecutors = 2 spark.executor.cores = 2 spark.executor.memory = 8g spark.eventLog.enabled = true spark.eventLog.overwrite = true spark.eventLog.dir = odps://admin_task_project/cupidhistory/sparkhistory spark.sql.catalogImplementation = hive spark.sql.sources.default = hive以下の表は、構成ファイル内のパラメーターを示しています。
MaxCompute_Project_Name: アクセスする MaxCompute プロジェクトの名前です。
これは MaxCompute プロジェクト名であり、ワークスペース名ではありません。MaxCompute コンソールにログインし、左上隅でリージョンを切り替えて、左側のナビゲーションウィンドウで を選択すると、プロジェクト名を確認できます。
AccessKey_ID: 対象の MaxCompute プロジェクトにアクセスする権限を持つ AccessKey ID です。
AccessKey 管理ページで AccessKey ID を取得できます。
AccessKey_Secret: 指定された AccessKey ID の AccessKey Secret です。
Endpoint: MaxCompute プロジェクトが存在するリージョンのパブリックエンドポイントです。
各リージョンのパブリックエンドポイントの詳細については、「エンドポイント」をご参照ください。
VPC_Endpoint: MaxCompute プロジェクトが存在するリージョンの VPC エンドポイントです。
各リージョンの VPC エンドポイントの詳細については、「VPC エンドポイント」をご参照ください。
Hologres_Classic_Network: Hologres インスタンスのクラシックネットワークエンドポイントです。この設定により、MaxCompute サンドボックス環境から Hologres インスタンスへの接続を許可するネットワークポリシーが構成されます。この設定がないと、MaxCompute クラスターは外部サービスにアクセスできません。
DataWorks コンソールにログインします。
左側のナビゲーションウィンドウで、ワークスペース をクリックします。
ワークスペース一覧 ページで、対象のワークスペースの 操作 列の クイックアクセス > データ開発 をクリックします。
PostgreSQL JDBC リソースと ODPS Spark ノードを作成します。
対象のワークフロー内で右クリックし、 を選択します。リソースの作成 ダイアログボックスで、PostgreSQL JDBC JAR ファイルをアップロードし、OK をクリックします。
説明ワークフローの作成方法の詳細については、「ワークフローの作成」をご参照ください。
MaxCompute リソースの作成および使用方法の詳細については、「MaxCompute リソースの作成と使用」をご参照ください。
対象のワークフロー内で右クリックし、 を選択します。リソースの作成 ダイアログボックスで、リソース名 を入力し、OK をクリックします。
この実践では、リソース名 は
read_holo.pyに設定します。read_holo.pyに次のスクリプト内容を入力し、 をクリックします。
をクリックします。from pyspark.sql import SparkSession spark = SparkSession \ .builder \ .appName("Spark") \ .getOrCreate() jdbcDF = spark.read.format("jdbc"). \ options( url='jdbc:postgresql://hgprecn-cn-2r42******-cn-hangzhou-internal.hologres.aliyuncs.com:80/mc_db_holo', dbtable='mc_jdbc_holo', user='LTAI****************', password='********************', driver='org.postgresql.Driver').load() jdbcDF.printSchema()以下の表は、スクリプト内のパラメーターを示しています。
url:
postgresqlドライバーを使用する JDBC 接続 URL です。hgprecn-cn-2r42******-cn-hangzhou.hologres.aliyuncs.com:80: Hologres インスタンスのパブリックエンドポイントです。エンドポイントを取得する方法については、「インスタンスの詳細の表示」をご参照ください。
mc_db_holo: ターゲット Hologres データベースの名前です。このチュートリアルでは、データベース名は mc_db_holo です。
dbtable: Hologres 内のソーステーブルの名前です。このチュートリアルでは、テーブル名は mc_jdbc_holo です。
user: Alibaba Cloud アカウントまたは RAM ユーザーの AccessKey ID です。AccessKey 管理ページで AccessKey ID を取得できます。
password: 指定された AccessKey ID の AccessKey Secret です。AccessKey 管理ページで AccessKey Secret を取得できます。
driver: PostgreSQL ドライバーです。値は org.postgresql.Driver である必要があります。
対象のワークフロー内で右クリックし、 を選択します。ノードの作成 ダイアログボックスで、ノード名 を入力し、OK をクリックします。
spark_read_holoノードを設定します。構成項目:
spark.hadoop.odps.cupid.trusted.services.access.list。値:
hgprecn-cn-2r42******-cn-hangzhou-internal.hologres.aliyuncs.com:80。これは Hologres のクラシックネットワークエンドポイントです。説明この設定により、MaxCompute サンドボックス環境から Hologres インスタンスへの接続を許可するネットワークポリシーが構成されます。この設定がないと、MaxCompute クラスターは外部サービスにアクセスできません。
ワークフローキャンバス上で、 を選択します。
ジョブが実行されると、MaxCompute ジョブの診断情報、Logview URL、および Spark UI Jobview URL を含むログが表示されます。
Logview URL を開きます。ジョブステータスが success の場合、 に移動して、
jdbcDF.printSchema()の出力を確認します。StdOut ログを確認します。
mc_jdbc_holoテーブルのスキーマと出力されたスキーマが一致する場合、接続は成功しています。説明Spark UI Jobview URL を開いて、ジョブを表示および診断することもできます。