このトピックでは、DataWorks Data Integration を使用して Kafka クラスターから MaxCompute にデータを移行する方法について説明します。
前提条件
MaxCompute データソースが追加されていること。 詳細については、「MaxCompute 計算リソースの関連付け」をご参照ください。
DataWorks ワークスペースにワークフローが作成されていること。 このトピックでは、基本モードのワークスペースのワークフローを例として使用します。 詳細については、「ワークフローの作成」をご参照ください。
Kafka クラスターがセットアップされていること。
データ移行を実行する前に、ご利用の Kafka クラスター環境が動作可能であることを確認してください。 このトピックでは、Alibaba Cloud EMR サービスを使用して Kafka クラスターを自動的にデプロイします。 詳細な手順については、「Kafka クイックスタート」をご参照ください。
このトピックで使用される EMR Kafka クラスターには、次の構成があります:
EMR バージョン: EMR-3.12.1
クラスタータイプ: Kafka
ソフトウェア: Ganglia 3.7.2、ZooKeeper 3.4.12、Kafka 2.11-1.0.1、および Kafka-Manager 1.3.X.XX
Kafka クラスターは、中国 (杭州) リージョンの VPC を使用します。 プライマリインスタンスグループの ECS 計算リソースは、パブリック IP アドレスとプライベート IP アドレスで構成されています。
背景情報
Kafka は、分散型のパブリッシュ/サブスクライブミドルウェアです。 高いパフォーマンスとスループットにより広く使用されており、1 秒あたり数百万のメッセージを処理できます。 Kafka はストリームデータの処理に適しており、主にユーザー行動追跡やログ収集などのシナリオで使用されます。
一般的な Kafka クラスターには、複数のプロデューサー、ブローカー、コンシューマー、および ZooKeeper クラスターが含まれます。 Kafka クラスターは ZooKeeper を使用して構成を管理し、サービスを調整します。
トピックはメッセージのコレクションであり、Kafka クラスターの基本的な概念です。 トピックはメッセージストレージの論理的な概念です。 トピックは物理ディスクには保存されません。 代わりに、トピック内のメッセージは、クラスター内の異なるノードのディスク上のパーティションに保存されます。 複数のプロデューサーがトピックにメッセージを送信でき、複数のコンシューマーがトピックからメッセージをプル (消費) できます。
メッセージがパーティションに追加されると、オフセットが割り当てられます。 オフセットは 0 から始まる番号付けを使用し、そのパーティション内のメッセージの一意の ID として機能します。
ステップ 1: Kafka データの準備
Kafka クラスターでテストデータを作成します。 EMR クラスターのヘッダーホストにログインでき、MaxCompute と DataWorks がホストと通信できるようにするには、EMR クラスターのヘッダーホストのセキュリティグループを構成して、TCP ポート 22 と 9092 でのトラフィックを許可する必要があります。
EMR クラスターのヘッダーホストにログインします。
EMR Hadoop コンソールに移動します。
上部のナビゲーションバーで、[クラスター管理] をクリックします。
表示されたページで、テストデータを作成するクラスターを見つけ、その詳細ページに移動します。
クラスターの詳細ページで、ホストリストをクリックし、EMR クラスターのヘッダーホストのアドレスを見つけ、SSH 接続を使用してホストにリモートでログインします。
テストトピックを作成します。
次のコマンドを実行して、テストトピック testkafka を作成します:
kafka-topics.sh --zookeeper emr-header-1:2181/kafka-1.0.1 --partitions 10 --replication-factor 3 --topic testkafka --createテストデータを書き込みます。
testkafka トピックにデータを書き込むプロデューサーをシミュレートするには、次のコマンドを実行します。 Kafka はストリームデータを処理するため、トピックに継続的にデータを書き込むことができます。 有効なテスト結果を保証するために、10 件以上のデータレコードを書き込んでください。
kafka-console-producer.sh --broker-list emr-header-1:9092 --topic testkafka別の SSH ウィンドウを開き、次のコマンドを実行して、データが Kafka に正常に書き込まれたかどうかを検証するコンシューマーをシミュレートします。 データが正常に書き込まれると、データが表示されます。
kafka-console-consumer.sh --bootstrap-server emr-header-1:9092 --topic testkafka --from-beginning
ステップ 2: DataWorks でターゲットテーブルを作成
DataWorks でターゲットテーブルを作成し、Kafka からのデータを保存します。
[データ開発] ページに移動します。
DataWorks コンソールにログインします。
左側のナビゲーションウィンドウで、 をクリックします。
ドロップダウンリストから対応するワークスペースを選択し、 [Data Studio に移動] をクリックします。
目的のビジネスフローを右クリックし、を選択します。
[テーブルの作成] ダイアログボックスで、テーブル名を入力し、[作成] をクリックします。
説明テーブル名は文字で始まる必要があり、漢字や特殊文字を含めることはできません。
Data Studio に複数の MaxCompute データソースをアタッチする場合、適切な [MaxCompute エンジンインスタンス] を選択してください。
テーブル編集ページで、[DDL 文] をクリックします。
[DDL] ダイアログボックスで、次のテーブル定義文を入力し、[テーブルスキーマの生成] をクリックします。
CREATE TABLE testkafka ( key string, value string, partition1 string, timestamp1 string, offset string, t123 string, event_id string, tag string ) ;各列は、DataWorks Data Integration の Kafka リーダーのデフォルト列に対応しています:
__key__:メッセージキー。
__value__:完全なメッセージ内容。
__partition__:現在のメッセージが存在するパーティション。
__headers__:現在のメッセージのヘッダー。
__offset__:現在のメッセージのオフセット。
__timestamp__:現在のメッセージのタイムスタンプ。
カスタム名を指定することもできます。 詳細については、「Kafka リーダー」をご参照ください。
[本番環境にコミット] と [確認] をクリックします。
ステップ 3: データの同期
Data Integration 専用リソースグループを作成します。
Kafka リーダーは、Data Integration 用共有リソースグループでは期待どおりに実行できません。 データを同期するには、Data Integration 専用リソースグループを使用する必要があります。 詳細については、「Data Integration 専用リソースグループの使用」をご参照ください。
データ統合ノードを作成します。
Data Studio ページに移動し、必要なワークフローを右クリックして、 を選択します。
[ノードの作成] ダイアログボックスで、ノードの [名前] を入力し、[確認] をクリックします。
上部のナビゲーションバーで、
 アイコンを選択します。
アイコンを選択します。スクリプトモードで、
 アイコンをクリックします。
アイコンをクリックします。スクリプトを構成します。 サンプルコードは次のとおりです:
{ "type": "job", "steps": [ { "stepType": "kafka", "parameter": { "server": "47.xxx.xxx.xxx:9092", "kafkaConfig": { "group.id": "console-consumer-83505" }, "valueType": "ByteArray", "column": [ "__key__", "__value__", "__partition__", "__timestamp__", "__offset__", "'123'", "event_id", "tag.desc" ], "topic": "testkafka", "keyType": "ByteArray", "waitTime": "10", "beginOffset": "0", "endOffset": "3" }, "name": "Reader", "category": "reader" }, { "stepType": "odps", "parameter": { "partition": "", "truncate": true, "compress": false, "datasource": "odps_source",// MaxCompute データソース名 "column": [ "key", "value", "partition1", "timestamp1", "offset", "t123", "event_id", "tag" ], "emptyAsNull": false, "table": "testkafka" }, "name": "Writer", "category": "writer" } ], "version": "2.0", "order": { "hops": [ { "from": "Reader", "to": "Writer" } ] }, "setting": { "errorLimit": { "record": "" }, "speed": { "throttle": false, "concurrent": 1 } } }EMR Kafka クラスターのマスターノードで `kafka-consumer-groups.sh --bootstrap-server emr-header-1:9092 --list` コマンドを実行して、コンシューマーグループ名と `group.id` パラメーターの値を確認できます。
コマンド例
kafka-consumer-groups.sh --bootstrap-server emr-header-1:9092 --list結果
_emr-client-metrics-handler-group console-consumer-69493 console-consumer-83505 console-consumer-21030 console-consumer-45322 console-consumer-14773
たとえば、`console-consumer-83505` の場合、ヘッダーホストで `kafka-consumer-groups.sh --bootstrap-server emr-header-1:9092 --describe --group console-consumer-83505` コマンドを実行して、`beginOffset` および `endOffset` パラメーターの値を確認できます。
コマンド例
kafka-consumer-groups.sh --bootstrap-server emr-header-1:9092 --describe --group console-consumer-83505結果
TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID testkafka 6 0 0 0 - - - test 6 3 3 0 - - - testkafka 0 0 0 0 - - - testkafka 1 1 1 0 - - - testkafka 5 0 0 0 - - -
スケジュールリソースグループを構成します。
ノード編集ページの右側のナビゲーションバーで、 [スケジュール設定] ボタンをクリックします。
[リソースプロパティ] セクションで、[スケジュールリソースグループ] に、作成した Data Integration 専用リソースグループを選択します。
説明Kafka データを MaxCompute に定期的に (たとえば 1 時間ごとに) 書き込むには、`beginDateTime` および `endDateTime` パラメーターを使用してデータ読み取り間隔を 1 時間に設定します。 その後、データ統合タスクを 1 時間に 1 回実行するようにスケジュールできます。 詳細については、「Kafka リーダー」をご参照ください。
 アイコンをクリックしてコードを実行します。
アイコンをクリックしてコードを実行します。[操作ログ] で結果を表示できます。
次のステップ
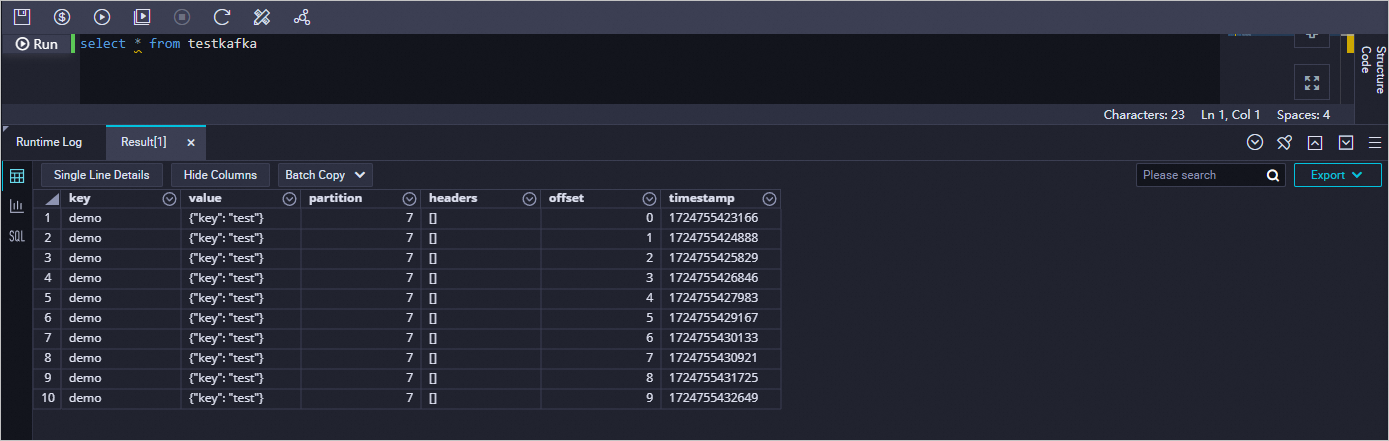
Data Studio でタスクを作成して SQL 文を実行し、ApsaraMQ for Kafka からのデータがテーブルに同期されているかどうかを確認できます。 このトピックでは、select * from testkafka 文を例として使用します。 タスクを作成する手順は次のとおりです:
[データ開発] ページに移動します。
DataWorks コンソールにログインします。
左側のナビゲーションウィンドウで [ワークスペース] をクリックして、[ワークスペース] ページに移動します。
上部のナビゲーションバーでターゲットリージョンに切り替え、作成したワークスペースを見つけ、[アクション] 列で をクリックして Data Studio ページに移動します。
DataStudio ページの左側のナビゲーションウィンドウで、
 アイコンをクリックして [アドホッククエリ] ペインに移動します。 [アドホッククエリ] ペインで、
アイコンをクリックして [アドホッククエリ] ペインに移動します。 [アドホッククエリ] ペインで、 アイコンをクリックし、 を選択します。
アイコンをクリックし、 を選択します。[ノードの作成] ダイアログボックスで、[パス] と [名前] パラメーターを構成できます。
[確認] をクリックします。
ノード構成ページで、
select * from testkafka文を入力し、 アイコンをクリックしてノードを実行し、操作ログを表示します。
アイコンをクリックしてノードを実行し、操作ログを表示します。