data Lake Formation (DLF) のデータ取り込み機能は更新されなくなりました。 このトピックでは、DataWorks Data Integrationを使用して、MySQLデータをデータレイクに取り込み、MaxComputeの外部プロジェクトを作成し、外部プロジェクトからDLFのテーブルデータをクエリする方法について説明します。
制限事項
データレイクハウスソリューションは、中国 (杭州) 、中国 (上海) 、中国 (北京) 、中国 (張家口) 、中国 (深セン) 、中国 (香港) 、シンガポール、ドイツ (フランクフルト) の各リージョンでのみサポートされています。
MaxCompute、Object Storage Service (OSS) 、およびApsaraDB RDS for MySQLは、DLFと同じリージョンにデプロイする必要があります。
MySQLデータをデータレイクにインポートする
DLFを使用してデータをデータレイクに取り込む方法の詳細については、「入門」をご参照ください。
手順1: データレイクのメタデータベースを作成する
DLFコンソールにログインします。 上部のナビゲーションバーで、リージョンを選択します。 左側のナビゲーションウィンドウで、 を選択します。 [メタデータ] ページで、メタデータベースを作成します。 詳細については、「メタデータベースの作成」をご参照ください。
手順2: DataWorks Data Integrationを使用してデータをOSSに取り込む
取り込みたいデータを準備します。
ApsaraDB for RDS コンソールにログインします。 上部のナビゲーションバーで、リージョンを選択します。 左側のナビゲーションウィンドウで、[インスタンス] をクリックします。
[インスタンス] ページで、目的のApsaraDB RDS for MySQLインスタンスを見つけ、目的のデータベースにログインします。
データベースにテーブルを作成し、少量のテストデータをテーブルに挿入します。 詳細については、「DMSを使用したApsaraDB RDS For MySQLインスタンスへのログイン」をご参照ください。 たとえば、次のステートメントを実行して、rds_mcという名前のテーブルを作成できます。
CREATE TABLE `rds_mc` ( `id` varchar(32) , `name` varchar(32) , PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; INSERT INTO `rds_mc`(`id` ,`name` ) VALUES(1,"Bob"); INSERT INTO `rds_mc`(`id` ,`name` ) VALUES(2,"zhangsan"); INSERT INTO `rds_mc`(`id` ,`name` ) VALUES(3,"zhaosi"); INSERT INTO `rds_mc`(`id` ,`name` ) VALUES(4,"wangwu"); INSERT INTO `rds_mc`(`id` ,`name` ) VALUES(5,"55555"); INSERT INTO `rds_mc`(`id` ,`name` ) VALUES(8,"6666"); SELECT * FROM `rds_mc`;
ApsaraDB RDS for MySQLデータソースを準備します。
DataWorksでApsaraDB RDS for MySQLを設定します。 詳細については、「MySQL データソース」をご参照ください。
OSSデータソースを準備します。
DataWorksでOSSデータソースを設定します。 詳細については、「OSSデータソースの追加」をご参照ください。
データ同期タスクを作成して実行します。
DataWorksコンソールの [DataStudio] ページで、バッチ同期タスクを作成します。 詳細については、「コードレスUIを使用したバッチ同期タスクの設定」をご参照ください。 次のコンテンツでは、設定する必要がある主要なパラメーターについて説明します。
ネットワーク接続とリソースグループを設定します。
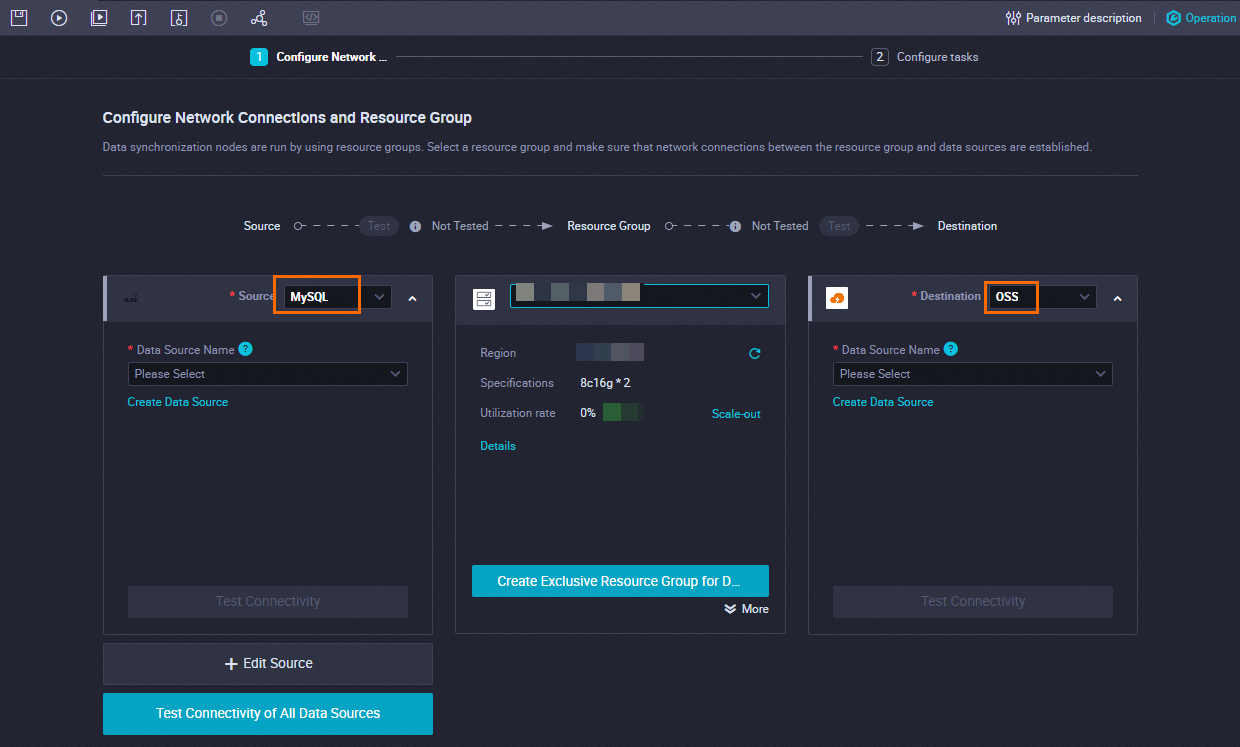
パラメーター
説明
ソース
ソース
MySQL を選択します。
Data Source Name
作成したApsaraDB RDS for MySQLデータソースの名前を選択します。
リソースグループ
リソースグループ
Data Integrationの排他的リソースグループを選択します。
目的地
目的地
[OSS] を選択します。
Data Source Name
作成したOSSデータソースを選択します。
タスクを設定します。
[Configure tasks] ステップで、テーブルおよびファイル名 (パスを含む) パラメーターを指定します。
パラメーター
説明
テーブル
ApsaraDB RDSデータベースに作成されたテーブルの名前を選択します。
ファイル名 (パスを含む)
ファイル名は、<OSSで作成されたファイルディレクトリ>/<OSSにエクスポートするデータファイルの名前> 形式である必要があります。
例:
doc-test-01/datalake/anti.csvバッチ同期タスクの設定ページの左上隅にある
 アイコンをクリックして設定を保存し、
アイコンをクリックして設定を保存し、 アイコンをクリックしてタスクを実行します。
アイコンをクリックしてタスクを実行します。 DataWorksでタスクが正常に実行された後、データがOSSディレクトリにインポートされているかどうかを確認できます。
手順3: DLFを使用してメタデータを抽出し、メタデータをデータレイクに取り込む
DLFコンソールにログインし、抽出タスクを作成してメタデータを抽出し、そのメタデータをデータレイクに取り込みます。 詳細については、「メタデータ検出」をご参照ください。
手順4: データレイクでメタデータを表示する
DLFコンソールにログインします。 左側のナビゲーションウィンドウで、[メタデータ] > [メタデータ] を選択します。 [メタデータ] ページで、[データベース] タブをクリックします。 [データベース] タブで目的のデータベースを見つけ、[操作] 列の [テーブル] をクリックします。 [テーブル] タブで、目的のテーブルに関する情報を表示します。
メタデータが抽出されたテーブルのシリアル化方法がorg.apache.hadoop.hive.serde2.OpenCSVSerdecの場合、MaxComputeはOpenCSVでサポートされているSTRINGデータ型のメタデータフィールドを識別します。 この場合、関連するクエリは失敗し、エラーが報告されます。 この問題を解決するには、識別されたメタデータフィールドのデータ型を手動でSTRINGに変更する必要があります。
アクセス許可の付与
MaxCompute、DLF、およびOSSを使用してデータレイクハウスを構築する場合は、次のいずれかの方法を使用して承認を完了します。 MaxComputeプロジェクトの作成に使用されるアカウントは、許可なくDLFにアクセスできません。 次のいずれかの方法を使用して、MaxComputeにDLFへのアクセスを許可できます。
ワンクリック認証: 同じアカウントを使用してMaxComputeプロジェクトを作成し、DLFをデプロイする場合は、Resource Access Management (RAM) コンソールのCloud Resource Access authorizationページでワンクリック認証を実行することを推奨します。
カスタム権限付与: 同じアカウントを使用してMaxComputeプロジェクトを作成し、DLFをデプロイするかどうかに関係なく、この方法を使用できます。 詳細については、「RAMユーザーにDLFへのアクセスを許可する」をご参照ください。
MaxComputeの外部プロジェクトを作成する
DataWorksコンソールで外部プロジェクトを作成します。
DataWorksコンソールにログインします。 上部のナビゲーションバーで、中国 (上海) リージョンを選択します。
DataWorksコンソールの左側のナビゲーションウィンドウで、. を選択します。
Lake and Warehouseの統合 (データレイクハウス)ページで開始. をクリックします。
[データレイクハウスの作成] ページで、パラメーターを設定します。 次の表にパラメーターを示します。
表 1 [データウェアハウスの作成] ステップのパラメーター
パラメーター
説明
外部プロジェクト名
ext_dlf_delta
MaxComputeプロジェクト
ms_proj1
表 2. [データレイク接続の作成] ステップのパラメーター
パラメーター
説明
異種データプラットフォームタイプ
ドロップダウンリストから [Alibaba Cloud DLF + OSS] を選択します。
なし
Alibaba Cloud DLF + OSS
外部プロジェクトの説明
なし
DLFが有効になっているリージョン
cn-shanghai
DLFエンドポイント
dlf-share.cn-shanghai.aliyuncs.com
DLFデータベース名
datalake
DLF RoleARN
なし
[作成] をクリックします。 表示されるページで、[プレビュー] をクリックします。
DLFデータベースのテーブル情報をプレビューできる場合、操作は成功です。
外部プロジェクトからのデータの照会
DataWorksコンソールの [DataStudio] ページの [アドホッククエリ] ウィンドウで、外部プロジェクトのテーブルデータをクエリします。
DataWorksが提供するアドホッククエリ機能の詳細については、「アドホッククエリノードを使用してSQL文を実行する (オプション) 」をご参照ください。
例:
select * from ext_dlf_delta.rds_mc;次の図は、返された結果を示しています。
