このトピックでは、統合オフライン・リアルタイム分析ソリューションを構築する方法について説明します。このソリューションでは、MaxCompute を使用してオフラインデータウェアハウスを構築し、Flink と Hologres を使用してリアルタイムデータウェアハウスを構築します。その後、Hologres と MaxCompute でそれぞれリアルタイムおよびオフラインのデータ分析を実行できます。
背景情報
デジタルトランスフォーメーション (DX) が加速するにつれて、企業はますますタイムリーなデータを求めるようになっています。大規模なデータ処理向けに設計された従来のオフラインシナリオを超えて、多くのユースケースでリアルタイムのデータインジェスト、ストレージ、分析が必要とされるようになりました。このニーズに対応するため、統合オフライン・リアルタイム分析という概念が登場しました。
統合オフライン・リアルタイム分析とは、単一のプラットフォームでリアルタイムデータとオフラインデータの両方を管理・処理することを指します。リアルタイムデータ処理とオフライン分析をシームレスに統合し、効率と精度を向上させます。主な利点は次のとおりです。
-
データ処理効率の向上:リアルタイムデータとオフラインデータを 1 つのプラットフォームに統合することで、データ転送と変換のコストを削減します。
-
分析精度の向上:リアルタイムデータと履歴データを組み合わせることで、より精密で正確なインサイトを得ることができます。
-
システムの複雑さの軽減:データ管理と処理のワークフローを簡素化します。
-
データ価値の向上:データのビジネス価値を最大化し、より良い意思決定をサポートします。
Alibaba Cloud は、統合オフライン・リアルタイム分析のための効率的なソリューションを提供します。このアーキテクチャでは、オフラインワークロードに MaxCompute、リアルタイム分析に Hologres、リアルタイムデータ変換に Flink を使用します。これらのサービスは、Alibaba Cloud の統合データウェアハウスソリューションの中核となるエンジンコンポーネントです。
ソリューションアーキテクチャ
次の図は、MaxCompute と Hologres を使用した GitHub 公開イベントデータセットの統合オフライン・リアルタイム分析のエンドツーエンドのワークフローを示しています。

Elastic Compute Service (ECS) インスタンスは、リアルタイムとオフラインの両方の GitHub イベントデータを収集・集約します。データはその後、別々のリアルタイムパイプラインとオフラインパイプラインに流れ込み、最終的に Hologres で統合され、統一されたサービスレイヤーを提供します。
-
リアルタイムパイプライン:Flink は Simple Log Service (SLS) からのデータをリアルタイムで処理し、Hologres に書き込みます。Flink は強力なストリーム処理エンジンです。Hologres は、データインジェスト直後のクエリと Flink とのネイティブ統合をサポートし、高スループット、低レイテンシー、高品質のリアルタイム分析を可能にします。このパイプラインは、最新イベントの抽出やトレンドアクティビティの分析など、リアルタイムのビジネスニーズに対応します。
-
オフラインパイプライン:MaxCompute は大量の履歴データを処理・アーカイブします。Alibaba Cloud Object Storage Service (OSS) は、さまざまなデータ型に対して安全で信頼性が高く、コスト効率の良いクラウドストレージを提供します。このソリューションでは、生データは OSS に JSON 形式で保存されます。MaxCompute は、SaaS (Software-as-a-Service) モデルを使用し、分析に最適化されたエンタープライズグレードのクラウドデータウェアハウスです。外部テーブルを使用して OSS から半構造化データを直接読み取り・解析し、価値の高いデータを内部ストレージに統合し、DataWorks をデータ開発に使用してオフラインデータウェアハウスを構築できます。
-
Hologres と MaxCompute は、ストレージレイヤーでネイティブに統合されています。これにより、Hologres は MaxCompute の大規模な履歴データセットに対するクエリを高速化し、低頻度でありながら高性能なクエリ要件を満たすことができます。また、オフラインデータを使用してリアルタイムデータを簡単に補正し、リアルタイムパイプラインで発生しうるデータの欠落や漏れに対処することも可能です。
このソリューションの主な利点は次のとおりです。
-
安定かつ効率的なオフラインパイプライン:1 時間ごとのデータ更新、大規模データセットのバッチ処理、複雑な計算をサポートし、コンピューティングコストを削減し、処理効率を向上させます。
-
成熟したリアルタイムパイプライン:簡素化されたアーキテクチャとサブ秒の応答時間で、リアルタイムのインジェスト、イベント計算、分析をサポートします。
-
統一されたストレージとサービス:Hologres は、一貫したインターフェイス (SQL で統一された OLAP およびキー・バリュークエリ) を通じてすべてのデータを提供し、ストレージは一元化されています。
-
シームレスなリアルタイム・オフライン統合:データ冗長性とデータ移動を最小限に抑えながら、データ補正を可能にします。
エンドツーエンドの開発サポートにより、このソリューションはサブ秒のデータ応答性、完全なパイプラインの可視性、最小限のアーキテクチャコンポーネント、少ない依存関係、そして大幅に削減された運用コストと人件費を実現します。
ビジネスとデータの理解
開発者は GitHub 上で多くのオープンソースプロジェクトを作成し、開発プロセス中に多数のイベントを生成します。GitHub は、各イベントのタイプと詳細、開発者、リポジトリ、その他の情報を記録します。また、スター付けやコードコミットなどの公開イベントも公開しています。特定のイベントタイプの詳細については、「Webhook events and payloads」をご参照ください。
-
GitHub は OpenAPI を介してリアルタイムの公開イベントを公開します。この API は過去 5 分間のイベントのみを公開します。詳細については、「Events」をご参照ください。この API を使用してリアルタイムデータを取得できます。
-
GH Archive プロジェクトは、GitHub の公開イベントを 1 時間ごとに集約し、ダウンロード可能にしています。詳細については、「GH Archive」をご参照ください。このプロジェクトを使用してオフラインデータを取得できます。
GitHub ビジネスの概要
GitHub の中核ビジネスは、コード管理と開発者のコラボレーションを中心に展開しており、主に「開発者」「リポジトリ」「組織」の 3 つのトップレベルエンティティが関わっています。
このソリューションでは、Event はストレージと分析のための個別のエンティティとして扱われます。

生の公開イベントデータの理解
次の例は、JSON 形式の生のイベントサンプルを示しています。
{
"id": "19541192931",
"type": "WatchEvent",
"actor":
{
"id": 23286640,
"login": "herekeo",
"display_login": "herekeo",
"gravatar_id": "",
"url": "https://api.github.com/users/herekeo",
"avatar_url": "https://avatars.githubusercontent.com/u/23286640?"
},
"repo":
{
"id": 52760178,
"name": "crazyguitar/pysheeet",
"url": "https://api.github.com/repos/crazyguitar/pysheeet"
},
"payload":
{
"action": "started"
},
"public": true,
"created_at": "2022-01-01T00:03:04Z"
}このソリューションは、非推奨または記録されていないタイプを除き、15 種類の公開イベントをカバーしています。詳細なリストと説明については、「GitHub public event types」をご参照ください。
前提条件
-
ECS インスタンスを作成し、Elastic IP Address (EIP) を関連付けて、GitHub API からリアルタイムのイベントデータを抽出します。詳細については、「ECS インスタンスの作成」および「Elastic IP Address」をご参照ください。
-
OSS を有効化し、ECS インスタンスに ossutil ツールをインストールして、GH Archive からの JSON データファイルを保存します。詳細については、「OSS の有効化」および「ossutil のインストール」をご参照ください。
-
MaxCompute を有効化し、プロジェクトを作成します。詳細については、「MaxCompute プロジェクトの作成」をご参照ください。
-
DataWorks を有効化し、ワークスペースを作成してオフラインスケジューリングタスクを構築します。詳細については、「ワークスペースの作成」をご参照ください。
-
SLS を有効化し、プロジェクトと Logstore を作成して、ECS によって抽出されたデータをログとして収集します。詳細については、「LoongCollector を使用した ECS テキストログの収集と分析」をご参照ください。
-
Realtime Compute for Apache Flink を有効化して、SLS で収集したログデータをリアルタイムで Hologres に書き込みます。詳細については、「Realtime Compute for Apache Flink の有効化」をご参照ください。
-
Hologres を有効化します。詳細については、「Hologres インスタンスの購入」をご参照ください。
オフラインデータウェアハウスの構築 (1時間ごとの更新)
ECS を使用した生データファイルのダウンロードと OSS へのアップロード
ECS インスタンスを使用して、GH Archive が提供する JSON データファイルをダウンロードできます。
-
履歴データには、
wgetコマンドを使用できます。たとえば、wget https://data.gharchive.org/{2012..2022}-{01..12}-{01..31}-{0..23}.json.gzを実行して、2012 年から 2022 年までの 1 時間ごとのデータをダウンロードできます。 -
新しい 1 時間ごとのデータについては、次のように定期タスクを設定できます。
説明-
ECS インスタンスに ossutil がインストールされていることを確認してください。詳細については、「ossutil のインストール」をご参照ください。ossutil パッケージを ECS インスタンスに直接ダウンロードし、
yum install unzipで unzip をインストールし、ossutil を展開して/usr/bin/ディレクトリに移動することを推奨します。 -
ECS インスタンスと同じリージョンに OSS バケットを作成します。カスタムのバケット名を使用できます。この例では、バケット名は
githubeventsです。 -
この例の ECS ダウンロードディレクトリは
/opt/hourlydata/gh_dataです。別のディレクトリを使用することもできます。
-
次のコマンドを実行して、
/opt/hourlydataディレクトリにdownload_code.shという名前のファイルを作成します。cd /opt/hourlydata vim download_code.sh -
iを押して編集モードに入り、次のスクリプトを追加します。d=$(TZ=UTC date --date='1 hour ago' '+%Y-%m-%d-%-H') h=$(TZ=UTC date --date='1 hour ago' '+%Y-%m-%d-%H') url=https://data.gharchive.org/${d}.json.gz echo ${url} # ./gh_data/ にデータをダウンロードします。このパスはカスタマイズ可能です。 wget ${url} -P ./gh_data/ # gh_data ディレクトリに切り替えます。 cd gh_data # ダウンロードしたデータを JSON ファイルに解凍します。 gzip -d ${d}.json echo ${d}.json # ルートディレクトリに切り替えます。 cd /root # ossutil を使用してデータを OSS にアップロードします。 # githubevents OSS バケットに hr=${h} という名前のディレクトリを作成します。 ossutil mkdir oss://githubevents/hr=${h} # /opt/hourlydata/gh_data から OSS にデータをアップロードします (このパスはカスタマイズ可能です)。 ossutil cp -r /opt/hourlydata/gh_data oss://githubevents/hr=${h} -u echo oss uploaded successfully! rm -rf /opt/hourlydata/gh_data/${d}.json echo ecs deleted! -
Esc キーを押し、
:wqと入力して Enter キーを押し、保存して終了します。 -
次のコマンドを実行して、
download_code.shスクリプトが毎時 10 分に実行されるようにスケジュールします。#1 次のコマンドを実行し、I を押して編集モードに入ります。 crontab -e #2 次の行を追加し、Esc を押して :wq と入力して終了します。 10 * * * * cd /opt/hourlydata && sh download_code.sh > download.log設定後、スクリプトは毎時 10 分に前の 1 時間の JSON ファイルをダウンロードし、ECS インスタンス上で解凍して OSS (パス:
oss://githubevents) にアップロードします。後で最新の 1 時間のデータのみが処理されるように、各アップロードでhr=%Y-%m-%d-%Hという名前のパーティションディレクトリが作成されます。後続の読み取りは、最新のパーティションのみを対象とします。
-
外部テーブルを使用した OSS データの MaxCompute へのインポート
MaxCompute クライアントまたは DataWorks の ODPS SQL ノードで次のコマンドを実行できます。詳細については、「ローカルクライアント (odpscmd) を使用した接続」または「ODPS SQL タスクの開発」をご参照ください。
-
OSS に保存されている JSON ファイルをマッピングするために、
githubeventsという名前の外部テーブルを作成します。CREATE EXTERNAL TABLE IF NOT EXISTS githubevents ( col STRING ) PARTITIONED BY ( hr STRING ) STORED AS textfile LOCATION 'oss://oss-cn-hangzhou-internal.aliyuncs.com/githubevents/' ;MaxCompute で OSS 外部テーブルを作成する方法の詳細については、「ORC 外部テーブル」をご参照ください。
-
解析されたデータを保存するために、
dwd_github_events_odpsという名前のファクトテーブルを作成します。次のコードは DDL 文を提供します。CREATE TABLE IF NOT EXISTS dwd_github_events_odps ( id BIGINT COMMENT 'イベント ID' ,actor_id BIGINT COMMENT 'アクター ID' ,actor_login STRING COMMENT 'アクターのログイン名' ,repo_id BIGINT COMMENT 'リポジトリ ID' ,repo_name STRING COMMENT '完全なリポジトリ名:owner/repository_name' ,org_id BIGINT COMMENT '組織 ID' ,org_login STRING COMMENT '組織名' ,`type` STRING COMMENT 'イベントタイプ' ,created_at DATETIME COMMENT 'イベント発生時刻' ,action STRING COMMENT 'イベントアクション' ,iss_or_pr_id BIGINT COMMENT 'Issue またはプルリクエスト ID' ,number BIGINT COMMENT 'Issue またはプルリクエスト番号' ,comment_id BIGINT COMMENT 'コメント ID' ,commit_id STRING COMMENT 'コミット ID' ,member_id BIGINT COMMENT 'メンバー ID' ,rev_or_push_or_rel_id BIGINT COMMENT 'レビュー、プッシュ、またはリリース ID' ,ref STRING COMMENT '作成または削除されたリソースの名前' ,ref_type STRING COMMENT '作成または削除されたリソースのタイプ' ,state STRING COMMENT 'Issue、プルリクエスト、またはプルリクエストレビューの状態' ,author_association STRING COMMENT 'アクターとリポジトリの関係' ,language STRING COMMENT 'マージされたコードのプログラミング言語' ,merged BOOLEAN COMMENT 'マージが受け入れられたかどうか' ,merged_at DATETIME COMMENT 'コードのマージ時刻' ,additions BIGINT COMMENT '追加された行数' ,deletions BIGINT COMMENT '削除された行数' ,changed_files BIGINT COMMENT 'プルリクエストで変更されたファイル数' ,push_size BIGINT COMMENT 'コミット数' ,push_distinct_size BIGINT COMMENT '個別コミット数' ,hr STRING COMMENT 'イベント発生時間 (例:00:23 → hr=00)' ,`month` STRING COMMENT 'イベント発生月 (例:2015年10月 → month=2015-10)' ,`year` STRING COMMENT 'イベント発生年 (例:2015年 → year=2015)' ) PARTITIONED BY ( ds STRING COMMENT 'イベント発生日 (ds=yyyy-mm-dd)' ); -
JSON データを解析し、ファクトテーブルに書き込みます。
次のコマンドを実行してパーティションを追加し、JSON データを
dwd_github_events_odpsテーブルに解析します。msck repair table githubevents add partitions; set odps.sql.hive.compatible = true; set odps.sql.split.hive.bridge = true; INSERT into TABLE dwd_github_events_odps PARTITION(ds) SELECT CAST(GET_JSON_OBJECT(col,'$.id') AS BIGINT ) AS id ,CAST(GET_JSON_OBJECT(col,'$.actor.id')AS BIGINT) AS actor_id ,GET_JSON_OBJECT(col,'$.actor.login') AS actor_login ,CAST(GET_JSON_OBJECT(col,'$.repo.id')AS BIGINT) AS repo_id ,GET_JSON_OBJECT(col,'$.repo.name') AS repo_name ,CAST(GET_JSON_OBJECT(col,'$.org.id')AS BIGINT) AS org_id ,GET_JSON_OBJECT(col,'$.org.login') AS org_login ,GET_JSON_OBJECT(col,'$.type') as type ,to_date(GET_JSON_OBJECT(col,'$.created_at'), 'yyyy-mm-ddThh:mi:ssZ') AS created_at ,GET_JSON_OBJECT(col,'$.payload.action') AS action ,case WHEN GET_JSON_OBJECT(col,'$.type')="PullRequestEvent" THEN CAST(GET_JSON_OBJECT(col,'$.payload.pull_request.id')AS BIGINT) WHEN GET_JSON_OBJECT(col,'$.type')="IssuesEvent" THEN CAST(GET_JSON_OBJECT(col,'$.payload.issue.id')AS BIGINT) END AS iss_or_pr_id ,case WHEN GET_JSON_OBJECT(col,'$.type')="PullRequestEvent" THEN CAST(GET_JSON_OBJECT(col,'$.payload.pull_request.number')AS BIGINT) WHEN GET_JSON_OBJECT(col,'$.type')="IssuesEvent" THEN CAST(GET_JSON_OBJECT(col,'$.payload.issue.number')AS BIGINT) ELSE CAST(GET_JSON_OBJECT(col,'$.payload.number')AS BIGINT) END AS number ,CAST(GET_JSON_OBJECT(col,'$.payload.comment.id')AS BIGINT) AS comment_id ,GET_JSON_OBJECT(col,'$.payload.comment.commit_id') AS commit_id ,CAST(GET_JSON_OBJECT(col,'$.payload.member.id')AS BIGINT) AS member_id ,case WHEN GET_JSON_OBJECT(col,'$.type')="PullRequestReviewEvent" THEN CAST(GET_JSON_OBJECT(col,'$.payload.review.id')AS BIGINT) WHEN GET_JSON_OBJECT(col,'$.type')="PushEvent" THEN CAST(GET_JSON_OBJECT(col,'$.payload.push_id')AS BIGINT) WHEN GET_JSON_OBJECT(col,'$.type')="ReleaseEvent" THEN CAST(GET_JSON_OBJECT(col,'$.payload.release.id')AS BIGINT) END AS rev_or_push_or_rel_id ,GET_JSON_OBJECT(col,'$.payload.ref') AS ref ,GET_JSON_OBJECT(col,'$.payload.ref_type') AS ref_type ,case WHEN GET_JSON_OBJECT(col,'$.type')="PullRequestEvent" THEN GET_JSON_OBJECT(col,'$.payload.pull_request.state') WHEN GET_JSON_OBJECT(col,'$.type')="IssuesEvent" THEN GET_JSON_OBJECT(col,'$.payload.issue.state') WHEN GET_JSON_OBJECT(col,'$.type')="PullRequestReviewEvent" THEN GET_JSON_OBJECT(col,'$.payload.review.state') END AS state ,case WHEN GET_JSON_OBJECT(col,'$.type')="PullRequestEvent" THEN GET_JSON_OBJECT(col,'$.payload.pull_request.author_association') WHEN GET_JSON_OBJECT(col,'$.type')="IssuesEvent" THEN GET_JSON_OBJECT(col,'$.payload.issue.author_association') WHEN GET_JSON_OBJECT(col,'$.type')="IssueCommentEvent" THEN GET_JSON_OBJECT(col,'$.payload.comment.author_association') WHEN GET_JSON_OBJECT(col,'$.type')="PullRequestReviewEvent" THEN GET_JSON_OBJECT(col,'$.payload.review.author_association') END AS author_association ,GET_JSON_OBJECT(col,'$.payload.pull_request.base.repo.language') AS language ,CAST(GET_JSON_OBJECT(col,'$.payload.pull_request.merged') AS BOOLEAN) AS merged ,to_date(GET_JSON_OBJECT(col,'$.payload.pull_request.merged_at'), 'yyyy-mm-ddThh:mi:ssZ') AS merged_at ,CAST(GET_JSON_OBJECT(col,'$.payload.pull_request.additions')AS BIGINT) AS additions ,CAST(GET_JSON_OBJECT(col,'$.payload.pull_request.deletions')AS BIGINT) AS deletions ,CAST(GET_JSON_OBJECT(col,'$.payload.pull_request.changed_files')AS BIGINT) AS changed_files ,CAST(GET_JSON_OBJECT(col,'$.payload.size')AS BIGINT) AS push_size ,CAST(GET_JSON_OBJECT(col,'$.payload.distinct_size')AS BIGINT) AS push_distinct_size ,SUBSTR(GET_JSON_OBJECT(col,'$.created_at'),12,2) as hr ,REPLACE(SUBSTR(GET_JSON_OBJECT(col,'$.created_at'),1,7),'-','-') as month ,SUBSTR(GET_JSON_OBJECT(col,'$.created_at'),1,4) as year ,REPLACE(SUBSTR(GET_JSON_OBJECT(col,'$.created_at'),1,10),'-','-') as ds from githubevents where hr = cast(to_char(dateadd(getdate(),-9,'hh'), 'yyyy-mm-dd-hh') as string); -
データのクエリ
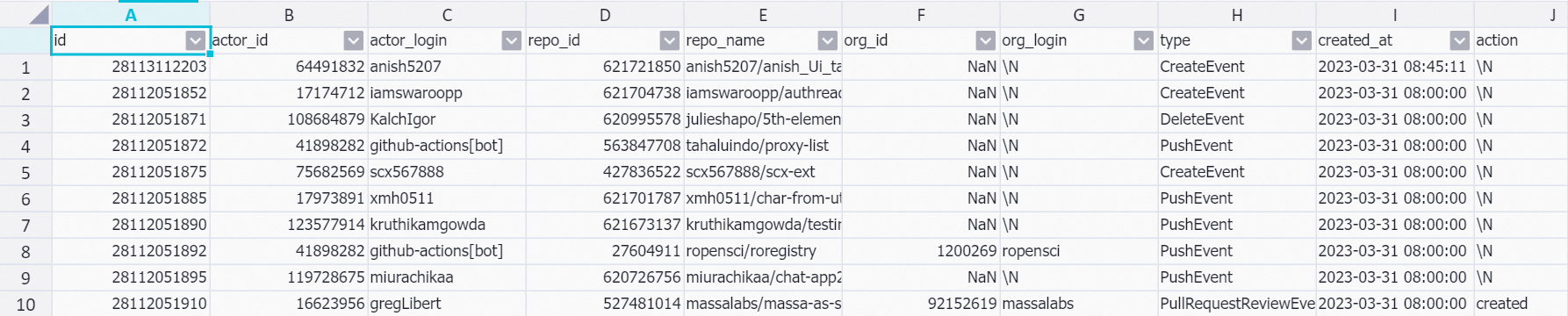
次のコマンドを実行して、
dwd_github_events_odpsテーブルからデータをクエリします。SET odps.sql.allow.fullscan=true; SELECT * FROM dwd_github_events_odps where ds = '2023-03-31' limit 10;出力例:
リアルタイムデータウェアハウスの構築
ECS を使用したリアルタイムデータの収集
ECS インスタンスを使用して、GitHub API からリアルタイムのイベントデータを抽出できます。次のスクリプトは、GitHub API を介してリアルタイムデータを収集する 1 つの方法を示しています。
-
各スクリプトの実行は 1 分間続き、その間に利用可能なリアルタイムイベントを収集し、各イベントを JSON オブジェクトとして保存します。
-
このスクリプトは、すべてのリアルタイムイベントのキャプチャを保証するものではありません。
-
GitHub API から継続的にデータを収集するには、Accept ヘッダーと Authorization トークンを提供する必要があります。Accept ヘッダーは固定値です。Authorization トークンには、GitHub のパーソナルアクセストークンが必要です。トークンの作成方法の詳細については、「Creating a personal access token」をご参照ください。
-
次のコマンドを実行して、
/opt/realtimeディレクトリにdownload_realtime_data.pyという名前のファイルを作成します。cd /opt/realtime vim download_realtime_data.py -
iを押して編集モードに入り、次の内容を追加します。#!python import requests import json import sys import time # レスポンスヘッダーから次のページの URL を取得 def get_next_link(resp): resp_link = resp.headers['link'] link = '' for l in resp_link.split(', '): link = l.split('; ')[0][1:-1] rel = l.split('; ')[1] if rel == 'rel="next"': return link return None # API から 1 ページ分のデータをダウンロード def download(link, fname): # GitHub API の Accept および Authorization ヘッダーを定義 headers = {"Accept": "application/vnd.github+json","Authorization": "<Bearer> <github_api_token>"} resp = requests.get(link, headers=headers) if int(resp.status_code) != 200: return None with open(fname, 'a') as f: for j in resp.json(): f.write(json.dumps(j)) f.write('\n') print('downloaded {} events to {}'.format(len(resp.json()), fname)) return resp # API から複数ページのデータをダウンロード def download_all_data(fname): link = 'https://api.github.com/events?per_page=100&page=1' while True: resp = download(link, fname) if resp is None: break link = get_next_link(resp) if link is None: break # 現在のタイムスタンプをミリ秒単位で取得 def get_current_ms(): return round(time.time()*1000) # スクリプトを正確に 1 分間実行 def main(fname): current_ms = get_current_ms() while get_current_ms() - current_ms < 60*1000: download_all_data(fname) time.sleep(0.1) # スクリプトを実行 if __name__ == '__main__': if len(sys.argv) < 2: print('usage: python {} <log_file>'.format(sys.argv[0])) exit(0) main(sys.argv[1]) -
Esc キーを押し、
:wqと入力して Enter キーを押し、保存して終了します。 -
download_realtime_data.pyを実行し、各実行のデータを個別に保存するためにrun_py.shファイルを作成します。ファイルには次の内容が含まれます。python /opt/realtime/download_realtime_data.py /opt/realtime/gh_realtime_data/$(date '+%Y-%m-%d-%H:%M:%S').json -
古いデータを削除するために
delete_log.shファイルを作成します。ファイルには次の内容が含まれます。d=$(TZ=UTC date --date='2 day ago' '+%Y-%m-%d') rm -f /opt/realtime/gh_realtime_data/*${d}*.json -
次のコマンドを実行して、毎分 GitHub データを収集し、古いデータを毎日削除します。
#1 次のコマンドを実行し、I を押して編集モードに入ります。 crontab -e #2 次の行を追加し、Esc を押して :wq と入力して終了します。 * * * * * bash /opt/realtime/run_py.sh 1 1 * * * bash /opt/realtime/delete_log.sh
SLS を使用した ECS データの収集
SLS を使用して、ECS インスタンスからリアルタイムのイベントデータをログとして収集できます。
SLS は Logtail を介した ECS インスタンスからのログ収集をサポートしています。データは JSON 形式であるため、Logtail の JSON モードを使用して、ECS インスタンスから増分 JSON ログを迅速にインジェストできます。収集の詳細については、「JSON モードを使用したログの収集」をご参照ください。このソリューションでは、SLS は生データからトップレベルのキーと値のペアを解析します。
Logtail 設定のログパスパラメーターは /opt/realtime/gh_realtime_data/**/*.json に設定されています。
設定後、SLS は ECS インスタンスから増分イベントデータを継続的に収集します。次の図は、収集されたデータのサンプルを示しています。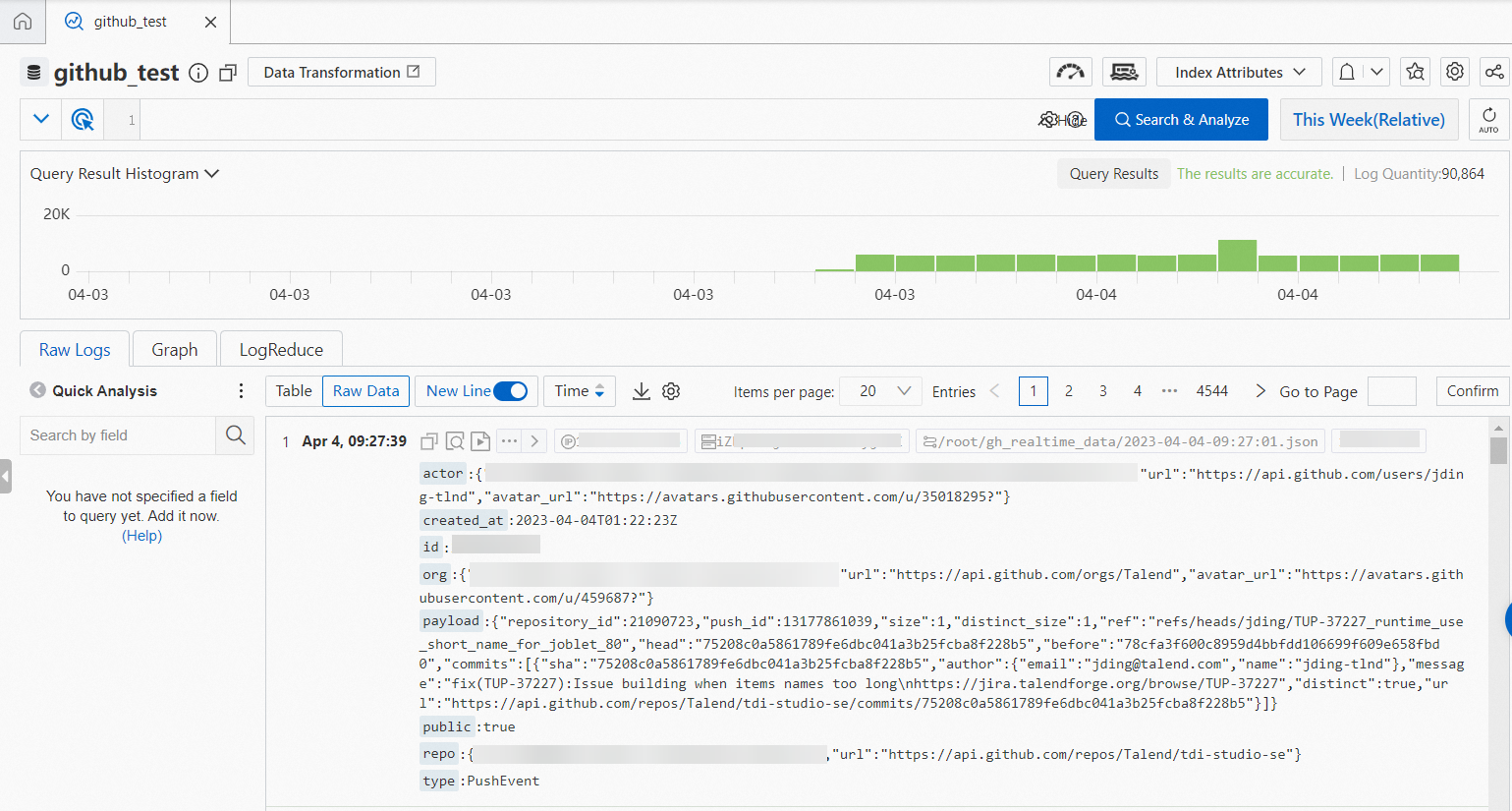
Flink を使用した SLS データの Hologres へのリアルタイム書き込み
Flink を使用して、SLS で収集したログデータをリアルタイムで Hologres に書き込むことができます。Flink で SLS ソーステーブルと Hologres 結果テーブルを定義することにより、SLS から Hologres にデータをストリームできます。詳細については、「SLS からのインポート」をご参照ください。
-
Hologres 内部テーブルの作成
このテーブルは、生の JSON データから選択したフィールドを保持します。イベント
idと日付dsをプライマリキー、idを分散キー、dsをパーティションキー、created_atをイベント時間列として設定します。クエリパターンに基づいて追加のインデックスを作成し、パフォーマンスを向上させることができます。インデックスの詳細については、「CREATE TABLE」をご参照ください。次のコードは、サンプルの DDL を提供します。DROP TABLE IF EXISTS gh_realtime_data; BEGIN; CREATE TABLE gh_realtime_data ( id bigint, actor_id bigint, actor_login text, repo_id bigint, repo_name text, org_id bigint, org_login text, type text, created_at timestamp with time zone NOT NULL, action text, iss_or_pr_id bigint, number bigint, comment_id bigint, commit_id text, member_id bigint, rev_or_push_or_rel_id bigint, ref text, ref_type text, state text, author_association text, language text, merged boolean, merged_at timestamp with time zone, additions bigint, deletions bigint, changed_files bigint, push_size bigint, push_distinct_size bigint, hr text, month text, year text, ds text, PRIMARY KEY (id,ds) ) PARTITION BY LIST (ds); CALL set_table_property('public.gh_realtime_data', 'distribution_key', 'id'); CALL set_table_property('public.gh_realtime_data', 'event_time_column', 'created_at'); CALL set_table_property('public.gh_realtime_data', 'clustering_key', 'created_at'); COMMENT ON COLUMN public.gh_realtime_data.id IS 'イベント ID'; COMMENT ON COLUMN public.gh_realtime_data.actor_id IS 'アクター ID'; COMMENT ON COLUMN public.gh_realtime_data.actor_login IS 'アクターのログイン名'; COMMENT ON COLUMN public.gh_realtime_data.repo_id IS 'リポジトリ ID'; COMMENT ON COLUMN public.gh_realtime_data.repo_name IS 'リポジトリ名'; COMMENT ON COLUMN public.gh_realtime_data.org_id IS '組織 ID'; COMMENT ON COLUMN public.gh_realtime_data.org_login IS '組織名'; COMMENT ON COLUMN public.gh_realtime_data.type IS 'イベントタイプ'; COMMENT ON COLUMN public.gh_realtime_data.created_at IS 'イベント発生時刻'; COMMENT ON COLUMN public.gh_realtime_data.action IS 'イベントアクション'; COMMENT ON COLUMN public.gh_realtime_data.iss_or_pr_id IS 'Issue またはプルリクエスト ID'; COMMENT ON COLUMN public.gh_realtime_data.number IS 'Issue またはプルリクエスト番号'; COMMENT ON COLUMN public.gh_realtime_data.comment_id IS 'コメント ID'; COMMENT ON COLUMN public.gh_realtime_data.commit_id IS 'コミット ID'; COMMENT ON COLUMN public.gh_realtime_data.member_id IS 'メンバー ID'; COMMENT ON COLUMN public.gh_realtime_data.rev_or_push_or_rel_id IS 'レビュー、プッシュ、またはリリース ID'; COMMENT ON COLUMN public.gh_realtime_data.ref IS '作成または削除されたリソースの名前'; COMMENT ON COLUMN public.gh_realtime_data.ref_type IS '作成または削除されたリソースのタイプ'; COMMENT ON COLUMN public.gh_realtime_data.state IS 'Issue、プルリクエスト、またはプルリクエストレビューの状態'; COMMENT ON COLUMN public.gh_realtime_data.author_association IS 'アクターとリポジトリの関係'; COMMENT ON COLUMN public.gh_realtime_data.language IS 'プログラミング言語'; COMMENT ON COLUMN public.gh_realtime_data.merged IS 'マージが受け入れられたかどうか'; COMMENT ON COLUMN public.gh_realtime_data.merged_at IS 'コードのマージ時刻'; COMMENT ON COLUMN public.gh_realtime_data.additions IS '追加された行数'; COMMENT ON COLUMN public.gh_realtime_data.deletions IS '削除された行数'; COMMENT ON COLUMN public.gh_realtime_data.changed_files IS 'プルリクエストで変更されたファイル数'; COMMENT ON COLUMN public.gh_realtime_data.push_size IS 'コミット数'; COMMENT ON COLUMN public.gh_realtime_data.push_distinct_size IS '個別コミット数'; COMMENT ON COLUMN public.gh_realtime_data.hr IS 'イベント発生時間 (例:00:23 → hr=00)'; COMMENT ON COLUMN public.gh_realtime_data.month IS 'イベント発生月 (例:2015年10月 → month=2015-10)'; COMMENT ON COLUMN public.gh_realtime_data.year IS 'イベント発生年 (例:2015年 → year=2015)'; COMMENT ON COLUMN public.gh_realtime_data.ds IS 'イベント発生日 (ds=yyyy-mm-dd)'; COMMIT; -
Flink を使用したリアルタイムでのデータ書き込み
Flink を使用して SLS データをさらに解析し、リアルタイムで Hologres に書き込むことができます。次の Flink SQL は、イベント ID または
created_atが null のダーティデータをフィルタリングし、最近のイベントのみを保持します。CREATE TEMPORARY TABLE sls_input ( actor varchar, created_at varchar, id bigint, org varchar, payload varchar, public varchar, repo varchar, type varchar ) WITH ( 'connector' = 'sls', 'endpoint' = '<endpoint>',--SLS のプライベートエンドポイント 'accessid' = '<accesskey id>',--アカウントの AccessKey ID 'accesskey' = '<accesskey secret>',--アカウントの AccessKey Secret 'project' = '<project name>',--SLS プロジェクトの名前 'logstore' = '<logstore name>',--SLS LogStore の名前 'starttime' = '2023-04-06 00:00:00'--SLS からのデータインジェスト開始時刻 ); CREATE TEMPORARY TABLE hologres_sink ( id bigint, actor_id bigint, actor_login string, repo_id bigint, repo_name string, org_id bigint, org_login string, type string, created_at timestamp, action string, iss_or_pr_id bigint, number bigint, comment_id bigint, commit_id string, member_id bigint, rev_or_push_or_rel_id bigint, `ref` string, ref_type string, state string, author_association string, `language` string, merged boolean, merged_at timestamp, additions bigint, deletions bigint, changed_files bigint, push_size bigint, push_distinct_size bigint, hr string, `month` string, `year` string, ds string ) WITH ( 'connector' = 'hologres', 'dbname' = '<hologres dbname>', --Hologres データベースの名前 'tablename' = '<hologres tablename>', --Hologres の宛先テーブルの名前 'username' = '<accesskey id>', --Alibaba Cloud アカウントの AccessKey ID 'password' = '<accesskey secret>', --Alibaba Cloud アカウントの AccessKey Secret 'endpoint' = '<endpoint>', --Hologres インスタンスの VPC エンドポイント 'jdbcretrycount' = '1', --接続失敗時のリトライ回数 'partitionrouter' = 'true', --パーティションテーブルにデータを書き込むかどうかを指定 'createparttable' = 'true', --パーティションを自動的に作成するかどうかを指定 'mutatetype' = 'insertorignore' --データ書き込みモード ); INSERT INTO hologres_sink SELECT id ,CAST(JSON_VALUE(actor, '$.id') AS bigint) AS actor_id ,JSON_VALUE(actor, '$.login') AS actor_login ,CAST(JSON_VALUE(repo, '$.id') AS bigint) AS repo_id ,JSON_VALUE(repo, '$.name') AS repo_name ,CAST(JSON_VALUE(org, '$.id') AS bigint) AS org_id ,JSON_VALUE(org, '$.login') AS org_login ,type ,TO_TIMESTAMP_TZ(replace(created_at,'T',' '), 'yyyy-MM-dd HH:mm:ss', 'UTC') AS created_at ,JSON_VALUE(payload, '$.action') AS action ,CASE WHEN type='PullRequestEvent' THEN CAST(JSON_VALUE(payload, '$.pull_request.id') AS bigint) WHEN type='IssuesEvent' THEN CAST(JSON_VALUE(payload, '$.issue.id') AS bigint) END AS iss_or_pr_id ,CASE WHEN type='PullRequestEvent' THEN CAST(JSON_VALUE(payload, '$.pull_request.number') AS bigint) WHEN type='IssuesEvent' THEN CAST(JSON_VALUE(payload, '$.issue.number') AS bigint) ELSE CAST(JSON_VALUE(payload, '$.number') AS bigint) END AS number ,CAST(JSON_VALUE(payload, '$.comment.id') AS bigint) AS comment_id ,JSON_VALUE(payload, '$.comment.commit_id') AS commit_id ,CAST(JSON_VALUE(payload, '$.member.id') AS bigint) AS member_id ,CASE WHEN type='PullRequestReviewEvent' THEN CAST(JSON_VALUE(payload, '$.review.id') AS bigint) WHEN type='PushEvent' THEN CAST(JSON_VALUE(payload, '$.push_id') AS bigint) WHEN type='ReleaseEvent' THEN CAST(JSON_VALUE(payload, '$.release.id') AS bigint) END AS rev_or_push_or_rel_id ,JSON_VALUE(payload, '$.ref') AS `ref` ,JSON_VALUE(payload, '$.ref_type') AS ref_type ,CASE WHEN type='PullRequestEvent' THEN JSON_VALUE(payload, '$.pull_request.state') WHEN type='IssuesEvent' THEN JSON_VALUE(payload, '$.issue.state') WHEN type='PullRequestReviewEvent' THEN JSON_VALUE(payload, '$.review.state') END AS state ,CASE WHEN type='PullRequestEvent' THEN JSON_VALUE(payload, '$.pull_request.author_association') WHEN type='IssuesEvent' THEN JSON_VALUE(payload, '$.issue.author_association') WHEN type='IssueCommentEvent' THEN JSON_VALUE(payload, '$.comment.author_association') WHEN type='PullRequestReviewEvent' THEN JSON_VALUE(payload, '$.review.author_association') END AS author_association ,JSON_VALUE(payload, '$.pull_request.base.repo.language') AS `language` ,CAST(JSON_VALUE(payload, '$.pull_request.merged') AS boolean) AS merged ,TO_TIMESTAMP_TZ(replace(JSON_VALUE(payload, '$.pull_request.merged_at'),'T',' '), 'yyyy-MM-dd HH:mm:ss', 'UTC') AS merged_at ,CAST(JSON_VALUE(payload, '$.pull_request.additions') AS bigint) AS additions ,CAST(JSON_VALUE(payload, '$.pull_request.deletions') AS bigint) AS deletions ,CAST(JSON_VALUE(payload, '$.pull_request.changed_files') AS bigint) AS changed_files ,CAST(JSON_VALUE(payload, '$.size') AS bigint) AS push_size ,CAST(JSON_VALUE(payload, '$.distinct_size') AS bigint) AS push_distinct_size ,SUBSTRING(TO_TIMESTAMP_TZ(replace(created_at,'T',' '), 'yyyy-MM-dd HH:mm:ss', 'UTC'),12,2) as hr ,REPLACE(SUBSTRING(TO_TIMESTAMP_TZ(replace(created_at,'T',' '), 'yyyy-MM-dd HH:mm:ss', 'UTC'),1,7),'/','-') as `month` ,SUBSTRING(TO_TIMESTAMP_TZ(replace(created_at,'T',' '), 'yyyy-MM-dd HH:mm:ss', 'UTC'),1,4) as `year` ,SUBSTRING(TO_TIMESTAMP_TZ(replace(created_at,'T',' '), 'yyyy-MM-dd HH:mm:ss', 'UTC'),1,10) as ds FROM sls_input WHERE id IS NOT NULL AND created_at IS NOT NULL AND to_date(replace(created_at,'T',' ')) >= date_add(CURRENT_DATE, -1);パラメーターの詳細については、「SLS ソーステーブル」および「Hologres 結果テーブル」をご参照ください。
説明GitHub からの生のイベントデータは UTC ですが、タイムゾーン属性は含まれていません。一方、Hologres のデフォルトのタイムゾーンは UTC+8 です。したがって、Flink がリアルタイムで Hologres にデータを書き込む際に、データのタイムゾーンを調整する必要があります。これを行うには、Flink SQL でソーステーブルデータに UTC タイムゾーン属性を割り当て、ジョブ開始時に Flink システムのタイムゾーンを
Asia/Shanghaiに設定するために、ジョブ起動設定 ページの Flink 設定 セクションにtable.local-time-zone:Asia/Shanghai文を追加します。 -
データのクエリ
Flink によって Hologres に書き込まれた SLS データをクエリできます。その後、ビジネスニーズに基づいてさらなる分析を開発できます。
SELECT * FROM public.gh_realtime_data limit 10;出力例:

オフラインデータを使用したリアルタイムデータの補正
このシナリオでは、リアルタイムデータに欠落がある可能性があります。オフラインデータを使用してリアルタイムデータを補正できます。次の手順は、前日のリアルタイムデータを補正する方法を示しています。ビジネスニーズに基づいて補正サイクルを調整できます。
-
Hologres に外部テーブルを作成して、MaxCompute のオフラインデータにアクセスします。
IMPORT FOREIGN SCHEMA <maxcompute_project_name> LIMIT to ( <foreign_table_name> ) FROM SERVER odps_server INTO public OPTIONS(if_table_exist 'update',if_unsupported_type 'error');パラメーターの詳細については、「IMPORT FOREIGN SCHEMA」をご参照ください。
-
一時テーブルを作成することで、オフラインデータを使用して前日のリアルタイムデータを補正できます。
説明Hologres V2.1.17 以降は Serverless Computing をサポートしています。大規模なオフラインデータのインポート、大規模な抽出、変換、ロード (ETL) ジョブ、外部テーブルに対する大量のクエリなどのシナリオでは、Serverless Computing を使用してこれらのタスクを実行できます。この機能は、インスタンス自身のリソースの代わりに、追加のサーバーレスリソースを使用します。インスタンスに追加の計算リソースを予約する必要はありません。これにより、インスタンスの安定性が大幅に向上し、メモリ不足 (OOM) エラーの可能性が減少し、個々のタスクに対してのみ課金されます。Serverless Computing の詳細については、「Serverless Computing」をご参照ください。Serverless Computing の使用方法については、「Serverless Computing の使用ガイド」をご参照ください。
-- 既存の一時テーブルをクリーンアップ DROP TABLE IF EXISTS gh_realtime_data_tmp; -- 一時テーブルを作成 SET hg_experimental_enable_create_table_like_properties = ON; CALL HG_CREATE_TABLE_LIKE ('gh_realtime_data_tmp', 'select * from gh_realtime_data'); -- (オプション) 大規模なオフラインインポートと ETL に Serverless Computing を使用 SET hg_computing_resource = 'serverless'; -- 一時テーブルにデータを挿入し、統計を更新 INSERT INTO gh_realtime_data_tmp SELECT * FROM <foreign_table_name> WHERE ds = current_date - interval '1 day' ON CONFLICT (id, ds) DO NOTHING; ANALYZE gh_realtime_data_tmp; -- サーバーレスリソースの不要な使用を避けるために構成をリセット RESET hg_computing_resource; -- パーティションを補正済みデータでアトミックに置き換え BEGIN; DROP TABLE IF EXISTS "gh_realtime_data_<yesterday_date>"; ALTER TABLE gh_realtime_data_tmp RENAME TO "gh_realtime_data_<yesterday_date>"; ALTER TABLE gh_realtime_data ATTACH PARTITION "gh_realtime_data_<yesterday_date>" FOR VALUES IN ('<yesterday_date>'); COMMIT;
データ分析
収集したデータを使用して、豊富な分析を実行できます。必要な時間範囲に基づいて追加のデータウェアハウスレイヤーを設計し、リアルタイム、オフライン、および統合分析をサポートできます。
以下の例は、前の手順で収集したリアルタイムデータを分析する方法を示しています。特定のリポジトリや開発者を分析することもできます。
-
今日の公開イベントの総数をクエリします。
SELECT count(*) FROM gh_realtime_data WHERE created_at >= date_trunc('day', now());出力例:
count ------ 1006 -
過去 1 日間でイベント数が最も多い上位 5 つのリポジトリを検索します。
SELECT repo_name, COUNT(*) AS events FROM gh_realtime_data WHERE created_at >= now() - interval '1 day' GROUP BY repo_name ORDER BY events DESC LIMIT 5;出力例:
repo_name events ----------------------------------------+------ leo424y/heysiri.ml 29 arm-on/plan 10 Christoffel-T/fiverr-pat-20230331 9 mate-academy/react_dynamic-list-of-goods 9 openvinotoolkit/openvino 7 -
過去 1 日間でイベント数が最も多い上位 5 人の開発者を検索します。
SELECT actor_login, COUNT(*) AS events FROM gh_realtime_data WHERE created_at >= now() - interval '1 day' AND actor_login NOT LIKE '%[bot]' GROUP BY actor_login ORDER BY events DESC LIMIT 5;出力例:
actor_login events ------------------+------ direwolf-github 13 arm-on 10 sergii-nosachenko 9 Christoffel-T 9 yangwang201911 7 -
過去 1 時間に使用された上位のプログラミング言語をランク付けします。
SELECT language, count(*) total FROM gh_realtime_data WHERE created_at > now() - interval '1 hour' AND language IS NOT NULL GROUP BY language ORDER BY total DESC LIMIT 10;出力例:
language total -----------+---- JavaScript 25 C++ 15 Python 14 TypeScript 13 Java 8 PHP 8 -
過去 1 日間に追加されたスターの数でリポジトリをランク付けします。
説明この例では、スターを削除したユーザーは考慮されていません。
SELECT repo_id, repo_name, COUNT(actor_login) total FROM gh_realtime_data WHERE type = 'WatchEvent' AND created_at > now() - interval '1 day' GROUP BY repo_id, repo_name ORDER BY total DESC LIMIT 10;出力例:
repo_id repo_name total ---------+----------------------------------+----- 618058471 facebookresearch/segment-anything 4 619959033 nomic-ai/gpt4all 1 97249406 denysdovhan/wtfjs 1 9791525 digininja/DVWA 1 168118422 aylei/interview 1 343520006 joehillen/sysz 1 162279822 agalwood/Motrix 1 577723410 huggingface/swift-coreml-diffusers 1 609539715 e2b-dev/e2b 1 254839429 maniackk/KKCallStack 1 -
今日のデイリーアクティブユーザーとリポジトリをクエリします。
SELECT uniq (actor_id) actor_num, uniq (repo_id) repo_num FROM gh_realtime_data WHERE created_at > date_trunc('day', now());出力例:
actor_num repo_num ---------+-------- 743 816