MaxCompute では、Python インターフェースを使用して、Apache Airflow でジョブをスケジュールできます。このトピックでは、Apache Airflow の Python オペレーターを使用して MaxCompute ジョブをスケジュールする方法について説明します。
背景情報
Apache Airflow は、Airbnb によって開発されたオープンソースツールです。 Apache Airflow は Python で記述されており、ジョブのスケジュールに使用されます。 Apache Airflow は、有向非循環グラフ(DAG)を使用して、依存関係を持つジョブのグループを定義し、それらの関係に基づいてジョブをスケジュールします。 Apache Airflow では、Python インターフェースを使用してサブジョブを定義することもできます。 Apache Airflow は、ビジネス要件を満たすためにさまざまなオペレーターをサポートしています。 Apache Airflow の詳細については、「Apache Airflow」をご参照ください。
前提条件
Apache Airflow を使用して MaxCompute ジョブをスケジュールする前に、以下の条件が満たされていることを確認してください。
Apache Airflow がインストールされ、起動されている。
詳細については、「クイックスタート」をご参照ください。
このトピックでは、Apache Airflow 1.10.7 を使用しています。
ステップ 1:ジョブスケジューリング用の Python スクリプトを作成し、ファイルを Apache Airflow のホームディレクトリに保存する
ジョブスケジューリング用の Python スクリプトを作成し、.py ファイルとして保存します。 スクリプトファイルには、完全なスケジューリングロジックと、スケジュールするジョブの名前が含まれています。 このステップでは、Airflow_MC.py という名前の Python スクリプトファイルが作成されます。 このファイルには、次の内容が含まれています。
# -*- coding: UTF-8 -*-
import sys
import os
from odps import ODPS
from odps import options
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
from datetime import datetime, timedelta
from configparser import ConfigParser
import time
reload(sys)
sys.setdefaultencoding('utf8')
# デフォルトのエンコード形式を変更します。
# MaxCompute パラメーター設定
options.sql.settings = {'options.tunnel.limit_instance_tunnel': False, 'odps.sql.allow.fullscan': True}
cfg = ConfigParser()
cfg.read("odps.ini")
print(cfg.items())
# ALIBABA_CLOUD_ACCESS_KEY_ID 環境変数をユーザーアカウントの AccessKey ID に置き換えます。
# ALIBABA_CLOUD_ACCESS_KEY_SECRET 環境変数をユーザーアカウントの AccessKey シークレットに置き換えます。
# AccessKey ID と AccessKey シークレットの文字列を直接使用しないことをお勧めします。
odps = ODPS(cfg.get("odps",os.getenv('ALIBABA_CLOUD_ACCESS_KEY_ID')),cfg.get("odps",os.getenv('ALIBABA_CLOUD_ACCESS_KEY_SECRET')),cfg.get("odps","project"),cfg.get("odps","endpoint"))
default_args = {
'owner': 'airflow',
'depends_on_past': False,
'retry_delay': timedelta(minutes=5),
'start_date':datetime(2020,1,15)
# 'email': ['airflow@example.com'],
# 'email_on_failure': False,
# 'email_on_retry': False,
# 'retries': 1,
# 'queue': 'bash_queue',
# 'pool': 'backfill',
# 'priority_weight': 10,
# 'end_date': datetime(2016, 1, 1),
}
# ワークフロースケジューリング
dag = DAG(
'Airflow_MC', default_args=default_args, schedule_interval=timedelta(seconds=30))
def read_sql(sqlfile):
with io.open(sqlfile, encoding='utf-8', mode='r') as f:
sql=f.read()
f.closed
return sql
# ジョブスケジューリング
def get_time():
print 'Current time {}'.format(time.time())
return time.time()
# ジョブスケジューリング
def mc_job ():
project = odps.get_project() # デフォルトプロジェクトの情報を取得します。
instance=odps.run_sql("select * from long_chinese;")
print(instance.get_logview_address())
instance.wait_for_success()
with instance.open_reader() as reader:
count = reader.count
print("Number of data records in the table: {}".format(count))
for record in reader:
print record
return count
t1 = PythonOperator (
task_id = 'get_time' ,
provide_context = False ,
python_callable = get_time,
dag = dag )
t2 = PythonOperator (
task_id = 'mc_job' ,
provide_context = False ,
python_callable = mc_job ,
dag = dag )
t2.set_upstream(t1)ステップ 2:ジョブスケジューリング用のスクリプトを送信する
コマンドラインウィンドウで、次のコマンドを実行して、ステップ 1 で作成した Python スクリプトを送信します。
python Airflow_MC.pyコマンドラインウィンドウで、次のコマンドを実行して、スケジューリングワークフローを生成し、テストジョブを実行します。
# アクティブな DAG のリストを出力します airflow list_dags # "tutorial" dag_id のタスクリストを出力します airflow list_tasks Airflow_MC # tutorial DAG 内のタスクの階層を出力します airflow list_tasks Airflow_MC --tree # テストジョブを実行します。 airflow test Airflow_MC get_time 2010-01-16 airflow test Airflow_MC mc_job 2010-01-16
ステップ 3:ジョブを実行する
Apache Airflow の Web UI にログインできます。 [DAG] ページで、送信したワークフローを見つけ、![]() [リンク] 列の アイコンをクリックしてジョブを実行します。
[リンク] 列の アイコンをクリックしてジョブを実行します。
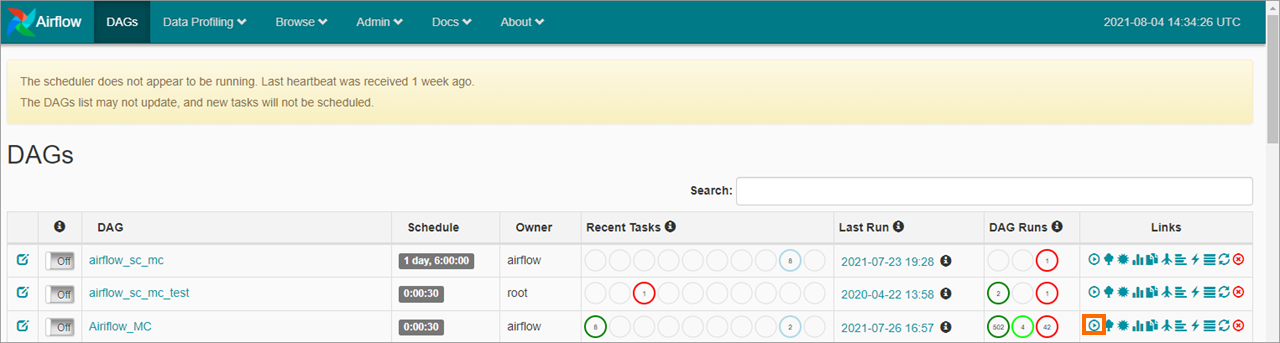
ステップ 4:ジョブの実行結果を表示する
[グラフビュー] タブで、ジョブ名をクリックしてワークフローを表示できます。 次に、ワークフロー内のジョブ(mc_job など)をクリックします。 表示されるダイアログボックスで、[ログの表示] をクリックして、ジョブの実行結果を表示します。
