このトピックでは、注文データ、IoV (Internet of Vehicles)、ログ、ユーザー行動という 4 つの実際のデータセットにおいて、Lindorm とオープンソースの HBase、MySQL、MongoDB のデータ圧縮パフォーマンスを比較します。
テスト環境
Lindorm は、デフォルトで zstd 圧縮アルゴリズムを使用するマルチモデル・ハイパーコンバージド・データベースサービスです。データエンコーディング中の辞書サンプリングを最適化することで圧縮率を向上させる、辞書ベースの圧縮をサポートしています。
次の表に、このテストで使用したデータベースのバージョンと圧縮設定を示します。
| データベース | バージョン | デフォルトの圧縮 | 注 |
|---|---|---|---|
| Lindorm | 最新 | zstd (最適化済み) | 辞書ベースの圧縮が利用可能 |
| オープンソース HBase | 2.3.4 | Snappy | 新しいバージョンの Hadoop では zstd がサポートされていますが、安定性の問題やコアダンプが発生しやすいため、ほとんどのデプロイメントでは Snappy が使用されています |
| オープンソース MySQL | 8.0 | なし (無効) | zlib が利用可能ですが、有効にするとクエリパフォーマンスが大幅に低下します |
| オープンソース MongoDB | 5.0 | Snappy | 代替として zstd が利用可能 |
このテストは、TPC ベンチマーク仕様の一部にのみ準拠しています。結果は、TPC ベンチマーク仕様に完全に準拠したテストの結果と同等または比較可能ではありません。
各シナリオでは、以下の構成をテストおよび比較します。
Lindorm (zstd、デフォルト)
Lindorm (辞書ベースの圧縮を有効)
オープンソース HBase (Snappy)
オープンソース MySQL (圧縮を無効)
オープンソース MongoDB (Snappy)
オープンソース MongoDB (zstd)
辞書ベースの圧縮を使用するケース
zstd と辞書ベースの圧縮の比較:
| アルゴリズム | 利点 | 最適な用途 |
|---|---|---|
| zstd (デフォルト) | 追加の設定なしでストレージを大幅に削減 | すべてのデータ型 |
| 辞書ベースの圧縮 | データインジェスト中に辞書トレーニングのステップが必要になりますが、zstd を超えるさらなる削減が可能 | 行ごとの繰り返しが多いデータセット |
辞書ベースの圧縮が最も効果的なデータ:ログエントリ、IoV テレメトリフィールド、行動イベントレコードなど、行間で構造が繰り返されるデータセット。
すべてのシナリオの統合結果については、「まとめ」をご参照ください。
注文データ
データセット
このシナリオでは、分析クエリのパフォーマンスを評価するために TPC (Transaction Processing Performance Council) によって定義された TPC-H ベンチマークデータセットを使用します。
TPC-H ツールのダウンロード: TPC-H_Tools_v3.0.0.zip
10 GB のテストデータを生成します。
# データジェネレーターを解凍してビルド
unzip TPC-H_Tools_v3.0.0.zip
cd TPC-H_Tools_v3.0.0/dbgen
cp makefile.suite makefile
# makefile を編集:以下のフィールドを設定
# CC = gcc
# DATABASE = ORACLE
# MACHINE = LINUX
# WORKLOAD = TPCH
make
# 10 GB のテストデータを生成
./dbgen -s 10これにより、8 つの .tbl ファイルが生成されます。このテストでは ORDERS.tbl を使用します:1,500 万行、1.76 GB。
| フィールド | 型 |
|---|---|
| O_ORDERKEY | INT |
| O_CUSTKEY | INT |
| O_ORDERSTATUS | CHAR(1) |
| O_TOTALPRICE | DECIMAL(15,2) |
| O_ORDERDATE | DATE |
| O_ORDERPRIORITY | CHAR(15) |
| O_CLERK | CHAR(15) |
| O_SHIPPRIORITY | INT |
| O_COMMENT | VARCHAR(79) |
テストテーブルの作成
HBase
create 'ORDERS', {NAME => 'f', DATA_BLOCK_ENCODING => 'DIFF', COMPRESSION => 'SNAPPY', BLOCKSIZE => '32768}MySQL
CREATE TABLE ORDERS (
O_ORDERKEY INTEGER NOT NULL,
O_CUSTKEY INTEGER NOT NULL,
O_ORDERSTATUS CHAR(1) NOT NULL,
O_TOTALPRICE DECIMAL(15,2) NOT NULL,
O_ORDERDATE DATE NOT NULL,
O_ORDERPRIORITY CHAR(15) NOT NULL,
O_CLERK CHAR(15) NOT NULL,
O_SHIPPRIORITY INTEGER NOT NULL,
O_COMMENT VARCHAR(79) NOT NULL
);MongoDB
db.createCollection("ORDERS")Lindorm
-- lindorm-cli
CREATE TABLE ORDERS (
O_ORDERKEY INTEGER NOT NULL,
O_CUSTKEY INTEGER NOT NULL,
O_ORDERSTATUS CHAR(1) NOT NULL,
O_TOTALPRICE DECIMAL(15,2) NOT NULL,
O_ORDERDATE DATE NOT NULL,
O_ORDERPRIORITY CHAR(15) NOT NULL,
O_CLERK CHAR(15) NOT NULL,
O_SHIPPRIORITY INTEGER NOT NULL,
O_COMMENT VARCHAR(79) NOT NULL,
PRIMARY KEY(O_ORDERKEY)
);圧縮結果
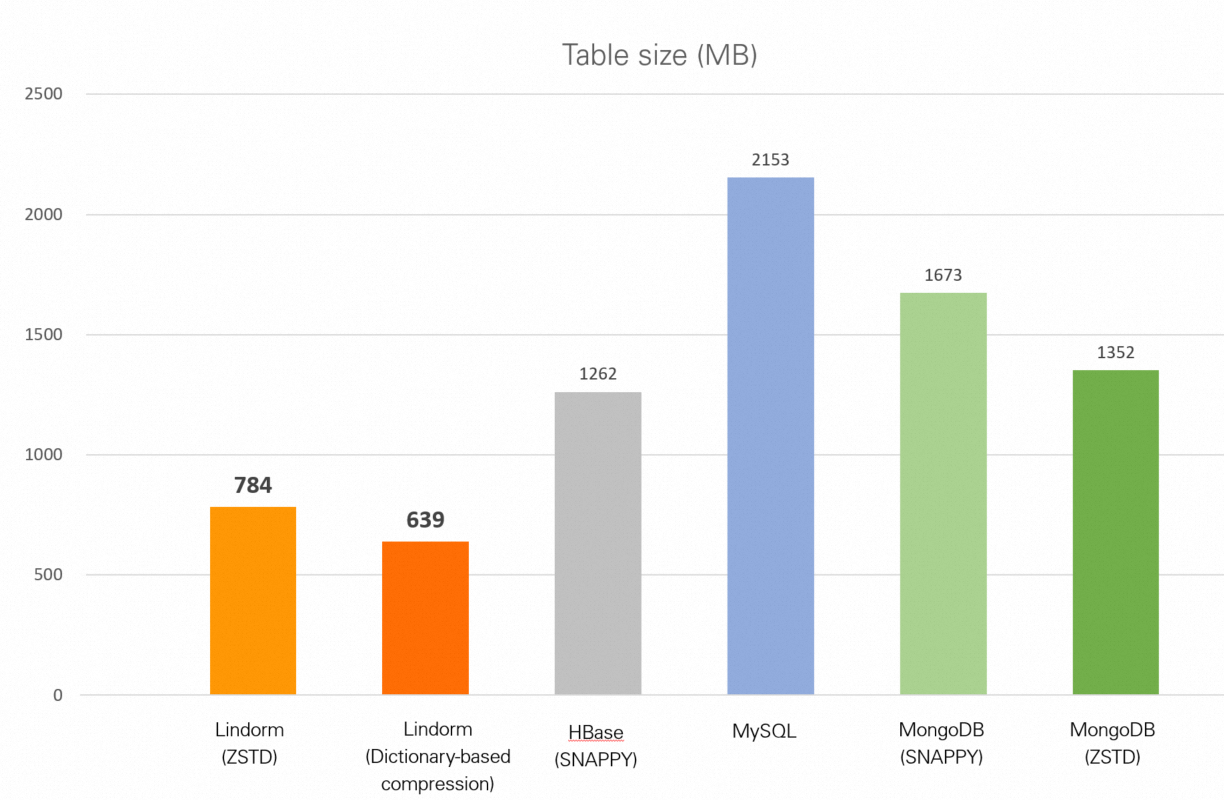
| データベース | テーブルサイズ |
|---|---|
| Lindorm (zstd) | 784 MB |
| Lindorm (辞書ベースの圧縮) | 639 MB |
| HBase (Snappy) | 1.23 GB |
| MySQL (圧縮なし) | 2.10 GB |
| MongoDB (Snappy) | 1.63 GB |
| MongoDB (zstd) | 1.32 GB |
車両インターネット
データセット
このシナリオでは、米国連邦道路局が国道 101 号線の車両軌跡から収集した NGSIM (Next Generation Simulation) データセットを使用します。NGSIM は、運転行動研究、交通流分析、車両軌跡予測、自動運転の意思決定計画などで広く使用されています。
NGSIM_Data.csv をダウンロードします:1,185 万行、1.54 GB、1 行あたり 25 列。
テストテーブルの作成
HBase
create 'NGSIM', {NAME => 'f', DATA_BLOCK_ENCODING => 'DIFF', COMPRESSION => 'SNAPPY', BLOCKSIZE => '32768}MySQL
CREATE TABLE NGSIM (
ID INTEGER NOT NULL,
Vehicle_ID INTEGER NOT NULL,
Frame_ID INTEGER NOT NULL,
Total_Frames INTEGER NOT NULL,
Global_Time BIGINT NOT NULL,
Local_X DECIMAL(10,3) NOT NULL,
Local_Y DECIMAL(10,3) NOT NULL,
Global_X DECIMAL(15,3) NOT NULL,
Global_Y DECIMAL(15,3) NOT NULL,
v_length DECIMAL(10,3) NOT NULL,
v_Width DECIMAL(10,3) NOT NULL,
v_Class INTEGER NOT NULL,
v_Vel DECIMAL(10,3) NOT NULL,
v_Acc DECIMAL(10,3) NOT NULL,
Lane_ID INTEGER NOT NULL,
O_Zone CHAR(10),
D_Zone CHAR(10),
Int_ID CHAR(10),
Section_ID CHAR(10),
Direction CHAR(10),
Movement CHAR(10),
Preceding INTEGER NOT NULL,
Following INTEGER NOT NULL,
Space_Headway DECIMAL(10,3) NOT NULL,
Time_Headway DECIMAL(10,3) NOT NULL,
Location CHAR(10) NOT NULL,
PRIMARY KEY(ID)
);MongoDB
db.createCollection("NGSIM")Lindorm
-- lindorm-cli
CREATE TABLE NGSIM (
ID INTEGER NOT NULL,
Vehicle_ID INTEGER NOT NULL,
Frame_ID INTEGER NOT NULL,
Total_Frames INTEGER NOT NULL,
Global_Time BIGINT NOT NULL,
Local_X DECIMAL(10,3) NOT NULL,
Local_Y DECIMAL(10,3) NOT NULL,
Global_X DECIMAL(15,3) NOT NULL,
Global_Y DECIMAL(15,3) NOT NULL,
v_length DECIMAL(10,3) NOT NULL,
v_Width DECIMAL(10,3) NOT NULL,
v_Class INTEGER NOT NULL,
v_Vel DECIMAL(10,3) NOT NULL,
v_Acc DECIMAL(10,3) NOT NULL,
Lane_ID INTEGER NOT NULL,
O_Zone CHAR(10),
D_Zone CHAR(10),
Int_ID CHAR(10),
Section_ID CHAR(10),
Direction CHAR(10),
Movement CHAR(10),
Preceding INTEGER NOT NULL,
Following INTEGER NOT NULL,
Space_Headway DECIMAL(10,3) NOT NULL,
Time_Headway DECIMAL(10,3) NOT NULL,
Location CHAR(10) NOT NULL,
PRIMARY KEY(ID)
);圧縮結果
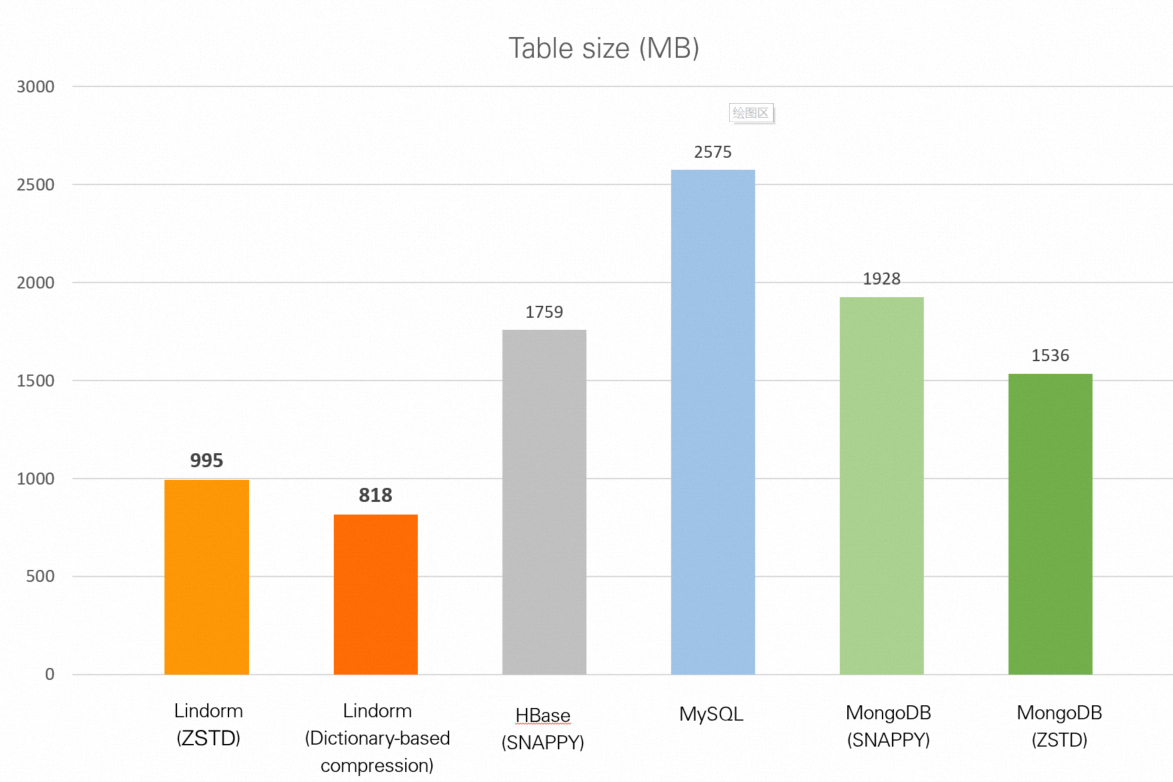
| データベース | テーブルサイズ |
|---|---|
| Lindorm (zstd) | 995 MB |
| Lindorm (辞書ベースの圧縮) | 818 MB |
| HBase (Snappy) | 1.72 GB |
| MySQL (圧縮なし) | 2.51 GB |
| MongoDB (Snappy) | 1.88 GB |
| MongoDB (zstd) | 1.50 GB |
ログデータ
データセット
このシナリオでは、Online Shopping Store - Web Server Logs データセット (Zaker, Farzin, 2019, Harvard Dataverse, V1) を使用します。
access.log をダウンロードします:1,036 万行、3.51 GB。各行は単一のログエントリです。例:
54.36.149.41 - - [22/Jan/2019:03:56:14 +0330] "GET /filter/27|13%20%D9%85%DA%AF%D8%A7%D9%BE%DB%8C%DA%A9%D8%B3%D9%84,27|%DA%A9%D9%85%D8%AA%D8%B1%20%D8%A7%D8%B2%205%20%D9%85%DA%AF%D8%A7%D9%BE%DB%8C%DA%A9%D8%B3%D9%84,p53 HTTP/1.1" 200 30577 "-" "Mozilla/5.0 (compatible; AhrefsBot/6.1; +http://ahrefs.com/robot/)" "-"ログデータは行間で構造的に繰り返されるため、このシナリオでは辞書ベースの圧縮による圧縮効果が最も高くなります。
テストテーブルの作成
HBase
create 'ACCESS_LOG', {NAME => 'f', DATA_BLOCK_ENCODING => 'DIFF', COMPRESSION => 'SNAPPY', BLOCKSIZE => '32768}MySQL
CREATE TABLE ACCESS_LOG (
ID INTEGER NOT NULL,
CONTENT VARCHAR(10000),
PRIMARY KEY(ID)
);MongoDB
db.createCollection("ACCESS_LOG")Lindorm
-- lindorm-cli
CREATE TABLE ACCESS_LOG (
ID INTEGER NOT NULL,
CONTENT VARCHAR(10000),
PRIMARY KEY(ID)
);圧縮結果
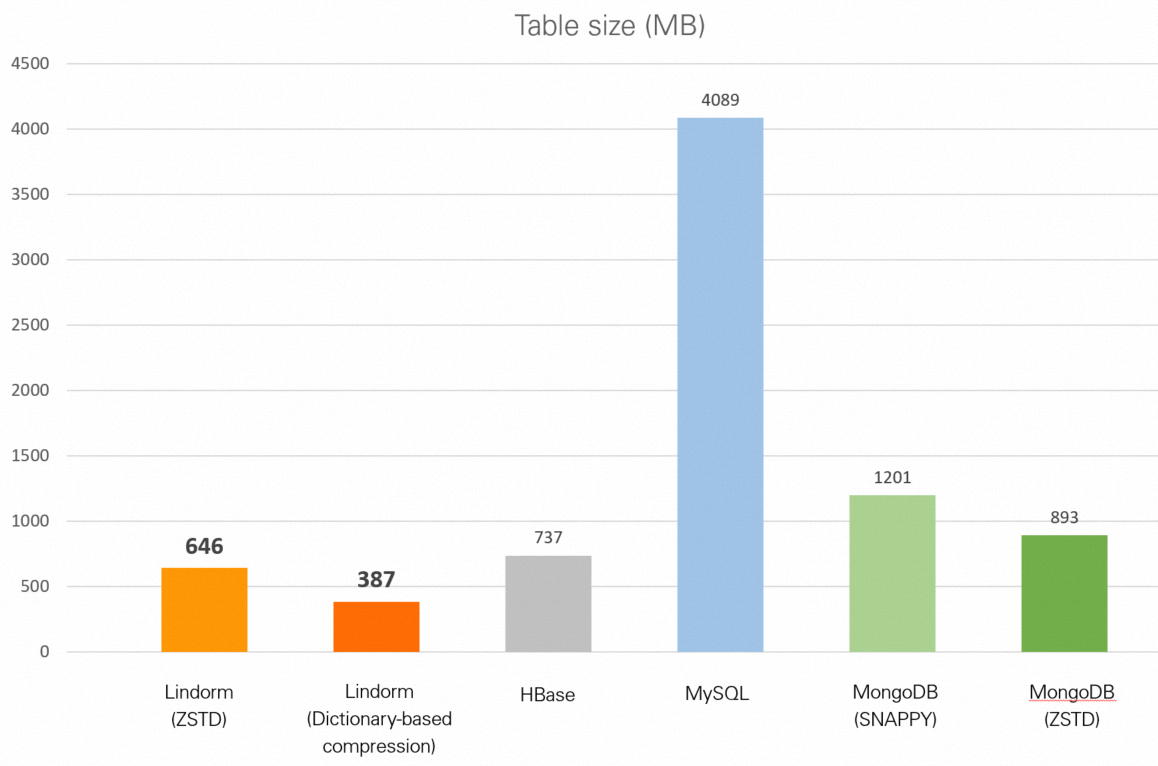
| データベース | テーブルサイズ |
|---|---|
| Lindorm (zstd) | 646 MB |
| Lindorm (辞書ベースの圧縮) | 387 MB |
| HBase (Snappy) | 737 MB |
| MySQL (圧縮なし) | 3.99 GB |
| MongoDB (Snappy) | 1.17 GB |
| MongoDB (zstd) | 893 MB |
ユーザーの動作
データセット
このシナリオでは、Alibaba Cloud Tianchi の Shop Info and User Behavior data from IJCAI-15 データセットを使用します。
data_format1.zip をダウンロードし、user_log_format1.csv を使用します:5,492 万行、1.91 GB。
| 列 | サンプル値 |
|---|---|
| user_id | 328862 |
| item_id | 323294, 844400, 575153 |
| cat_id | 833, 1271 |
| seller_id | 2882 |
| brand_id | 2661 |
| time_stamp | 829 |
| action_type | 0 |
テストテーブルの作成
HBase
create 'USER_LOG', {NAME => 'f', DATA_BLOCK_ENCODING => 'DIFF', COMPRESSION => 'SNAPPY', BLOCKSIZE => '32768}MySQL
CREATE TABLE USER_LOG (
ID INTEGER NOT NULL,
USER_ID INTEGER NOT NULL,
ITEM_ID INTEGER NOT NULL,
CAT_ID INTEGER NOT NULL,
SELLER_ID INTEGER NOT NULL,
BRAND_ID INTEGER,
TIME_STAMP CHAR(4) NOT NULL,
ACTION_TYPE CHAR(1) NOT NULL,
PRIMARY KEY(ID)
);MongoDB
db.createCollection("USER_LOG")Lindorm
-- lindorm-cli
CREATE TABLE USER_LOG (
ID INTEGER NOT NULL,
USER_ID INTEGER NOT NULL,
ITEM_ID INTEGER NOT NULL,
CAT_ID INTEGER NOT NULL,
SELLER_ID INTEGER NOT NULL,
BRAND_ID INTEGER,
TIME_STAMP CHAR(4) NOT NULL,
ACTION_TYPE CHAR(1) NOT NULL,
PRIMARY KEY(ID)
);圧縮結果
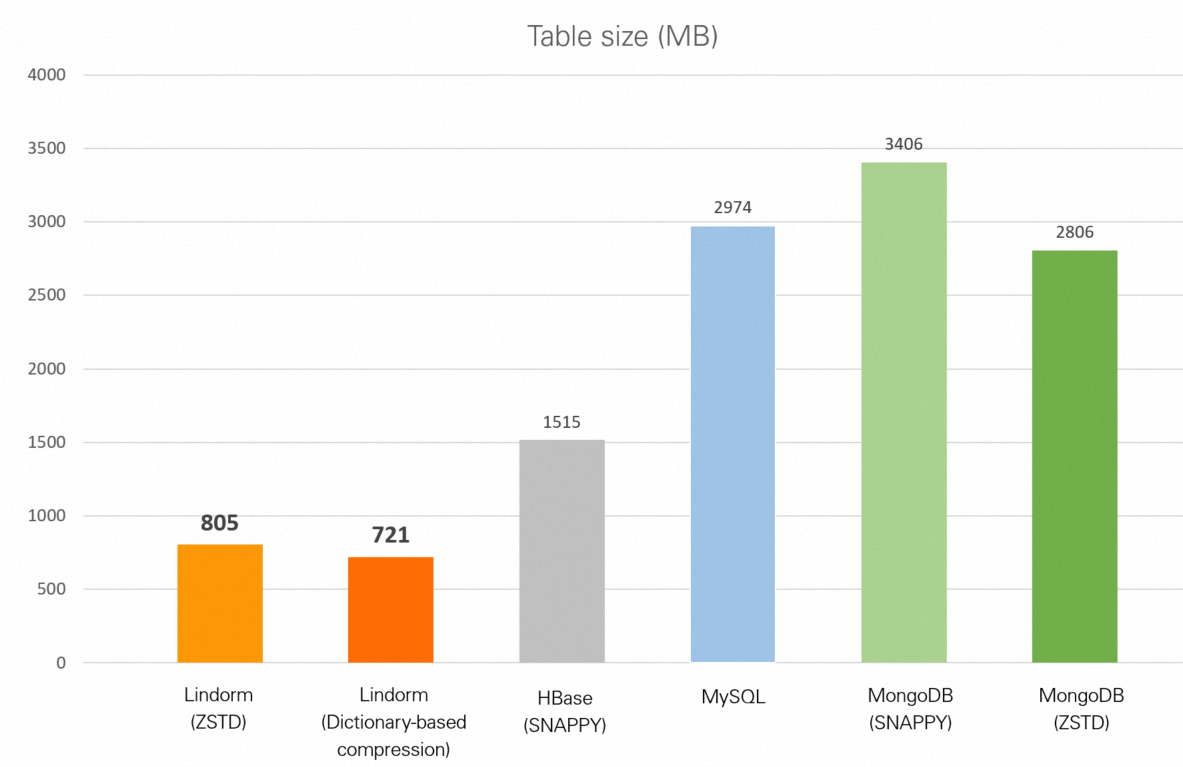
| データベース | テーブルサイズ |
|---|---|
| Lindorm (zstd) | 805 MB |
| Lindorm (辞書ベースの圧縮) | 721 MB |
| HBase (Snappy) | 1.48 GB |
| MySQL (圧縮なし) | 2.90 GB |
| MongoDB (Snappy) | 3.33 GB |
| MongoDB (zstd) | 2.74 GB |
まとめ
Lindorm は、辞書ベースの圧縮を有効にしなくても、オープンソースのデータベースよりも高い圧縮率を実現します。辞書ベースの圧縮を有効にすると、Lindorm は 4 つすべてのシナリオで最高の圧縮率を達成します。各オープンソースデータベースで使用されるデフォルト設定と比較して、辞書ベースの圧縮を使用した Lindorm は、保存データサイズを以下のように削減します。
オープンソース HBase (Snappy) よりも 1~2 倍
オープンソース MongoDB (Snappy または zstd) よりも 2~4 倍
オープンソース MySQL (非圧縮) よりも 3~10 倍
次の表に、すべてのテスト結果をまとめます。
| データセット | 元のサイズ | Lindorm (zstd) | Lindorm (辞書) | HBase (Snappy) | MySQL | MongoDB (Snappy) | MongoDB (zstd) |
|---|---|---|---|---|---|---|---|
| 注文データ (TPC-H) | 1.76 GB | 784 MB | 639 MB | 1.23 GB | 2.10 GB | 1.63 GB | 1.32 GB |
| IoV データ (NGSIM) | 1.54 GB | 995 MB | 818 MB | 1.72 GB | 2.51 GB | 1.88 GB | 1.50 GB |
| ログデータ (Web サーバー) | 3.51 GB | 646 MB | 387 MB | 737 MB | 3.99 GB | 1.17 GB | 893 MB |
| ユーザー行動データ (IJCAI-15) | 1.91 GB | 805 MB | 721 MB | 1.48 GB | 2.90 GB | 3.33 GB | 2.74 GB |
zstd と辞書ベースの圧縮の選択:zstd はデフォルトで有効になっており、追加の設定なしですべてのデータ型のストレージコストを削減します。辞書ベースの圧縮は、データインジェスト中に辞書トレーニングのステップが必要になりますが、さらなる削減を提供します。この効果は、ログデータで最も顕著 (646 MB 対 387 MB) であり、数値データが多い IoV データでは最も控えめです。