LindormTable は、検索インデックスという新しい検索タイプを提供します。このトピックでは、オープンソースの HBase API と Elasticsearch API を使用して検索インデックスにアクセスし、使用する方法について説明します。
背景情報
検索インデックスは、オープンソースの HBase API をサポートする LindormTable とオープンソースの Elasticsearch API をサポートする LindormSearch の機能を統合することにより、統一されたアクセス方法を提供します。このようにして、検索インデックスを使用してさまざまな種類のクエリを実行できます。 Lindorm SQL ステートメントを実行して、検索インデックスに接続して使用できます。この標準的な方法に加えて、オープンソースクライアントを使用して検索インデックスを使用することもできます。検索インデックスの詳細については、「概要」をご参照ください。
Lindorm SQL ステートメントを実行してテーブルを作成する場合は、SQL ステートメントを実行して検索インデックスを使用します。
前提条件
Java Development Kit(JDK)V1.8 以降がインストールされている。
クライアントの IP アドレスが Lindorm インスタンスのホワイトリストに追加されている。詳細については、「ホワイトリストの構成」をご参照ください。
概要
手順
SQL ステートメントを実行して検索インデックスを作成および使用する(推奨)
HBase API を使用してテーブルを作成する場合、利便性を高めるために、Lindorm SQL を使用してテーブルの検索インデックスを作成できます。この方法では、オープンソースクライアントを使用して検索インデックスを作成および使用できます。
Lindorm Shell を使用して LindormTable に接続します。詳細については、「Lindorm Shell を使用して LindormTable に接続する」をご参照ください。
testTableという名前のワイドテーブルを作成します。create 'testTable', {NAME => 'f'}Lindorm SQL を使用して、ワイドテーブルの列をインデックステーブルの列にマッピングします。
ALTER TABLE testTable MAP DYNAMIC COLUMN f:name HSTRING;データ型のマッピングの詳細については、「データ型のマッピング」をご参照ください。
idxという名前の検索インデックスを作成します。CREATE INDEX idx USING SEARCH ON testTable (f:name);testTableにデータの行を挿入します。put 'testTable', 'row1', 'f:name', 'foo'説明作成された検索インデックスのステータスが
ACTIVEになると、ワイドテーブルに挿入されたデータはインデックステーブルに自動的に同期されます。インデックスのステータスの確認方法については、「SHOW INDEX」をご参照ください。検索インデックスが作成される前にワイドテーブルに挿入されたデータについては、ALTER INDEXステートメントを実行して再構築する必要があります。この例では、ALTER INDEX idx ON test REBUILD;ステートメントを実行してデータを再構築できます。ステートメントでは、idxはワイドテーブルに作成された検索インデックスの名前です。詳細については、「ALTER INDEX」をご参照ください。インデックス付きデータをクエリします。
LindormSearch を使用して、検索インデックステーブルのプライマリキー ID をクエリします。
説明検索インデックステーブルの名前は、
<名前空間名>.<ワイドテーブル名>.<インデックス名>の形式で連結されます。検索インデックステーブルのフィールド名は、次のルールに基づいて連結されます。
ワイドテーブルの列ファミリが
fの場合、検索インデックステーブルのフィールド名は、ワイドテーブルの対応する列名と同じです。たとえば、ワイドテーブルのf:name列に対応するフィールドの名前はnameです。ワイドテーブルの列ファミリが
fでない場合、検索インデックステーブルのフィールド名は、<列ファミリ名>_<列名>の形式で連結されます。たとえば、ワイドテーブルのf1:name列に対応するフィールドの名前はf1_nameです。
GET /default.testTable.idx/_search { "size": 10, "query": { "match": { "name": "foo" } } }次の結果が返されます。
{ "took" : 4, "timed_out" : false, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 1, "relation" : "eq" }, "max_score" : 1.0, "hits" : [ { "_index" : "default.testTable.idx", "_id" : "726f7731", "_score" : 1.0, "_source" : { "update_version_l" : 1720072175536 } } ] } }返された結果の _id フィールドで示されているプライマリキー ID を取得します。
Lindorm Shell で次のコマンドを実行して、ワイドテーブルのデータをクエリします。SQL ステートメントを実行して検索インデックスが作成された場合、検索インデックステーブルのプライマリキー ID は、ワイドテーブルのプライマリキー ID を HEX エンコードしたものです。したがって、検索インデックステーブルのプライマリキー ID を使用してワイドテーブルのデータをクエリする場合は、プライマリキー ID を HEX 形式で指定します。詳細については、「rowkeyFormatterType」をご参照ください。
get 'testTable', "\x72\x6f\x77\x31"次の結果が返されます。
COLUMN CELL f:name timestamp=1644462597661, value=foo 1 row(s) Took 0.0942 seconds
Lindorm Shell を使用して検索インデックスを作成する
Lindorm Shell を使用して LindormTable に接続します。詳細については、「Lindorm Shell を使用して LindormTable に接続する」をご参照ください。
Lindorm Shell で
testTableという名前のワイドテーブルを作成します。create 'testTable', {NAME => 'f'}LindormSearch で
democollectionという名前の検索インデックステーブルを作成します。詳細については、「LindormSearch への接続」をご参照ください。説明特定のフィールド値を取得する必要がない場合は、リソースを節約するために
_sourceをfalseに設定できます。ワイドテーブルの列をインデックステーブルの列にマッピングします。たとえば、
testTableテーブルのf:name列をdemocollectionインデックステーブルのname_s列にマッピングします。 f:name 列では、f は列ファミリ名を指定し、name は列の名前を指定します。HBase シェルパッケージから抽出されたファイルの
binディレクトリに、schemaという名前の JSON ファイルを作成します。次のサンプルコードを JSON ファイルにコピーします。{ "sourceNamespace": "default", "sourceTable": "testTable", "targetIndexName": "democollection", "indexType": "ES", "rowkeyFormatterType": "STRING", "fields": [ { "source": "f:name", "targetField": "name_s", "type": "STRING" } ] }説明マッピングで指定されたすべての列が LindormSearch で明示的に定義されており、それらの名前とデータ型が実際の列と同じであることを確認します。
JSON ファイルのパラメータの詳細については、「列マッピングの構成」をご参照ください。
Lindorm Shell で次のコマンドを実行して、ワイドテーブルの列をインデックステーブルの列にマッピングします。
alter_external_index 'testTable', 'schema.json'説明ワイドテーブルとインデックステーブル間の列マッピングを管理する方法の詳細については、「列マッピング関係の管理」をご参照ください。
testTableにデータの行を書き込みます。ワイドテーブルとインデックステーブル間の列マッピングが構成されると、ワイドテーブルに書き込まれたデータはリアルタイムでインデックステーブルに自動的に同期されます。マッピングが構成される前にワイドテーブルに挿入されたデータについては、すべてのデータを同期するために、フルデータのインデックスを手動で作成する必要があります。詳細については、「フルデータのインデックスの作成」をご参照ください。put 'testTable', 'row1', 'f:name', 'foo'インデックス付きデータをクエリします。
LindormSearch を使用して、検索インデックステーブルのプライマリキー ID をクエリします。
GET /democollection/_search { "size": 10, "query": { "match": { "name_s": "foo" } } }次の結果が返されます。
{ "took" : 4, "timed_out" : false, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 1, "relation" : "eq" }, "max_score" : 1.0, "hits" : [ { "_index" : "democollection", "_id" : "row1", "_score" : 1.0, "_source" : { "update_version_l" : 1720072175536 } } ] } }返された結果の _id フィールドで示されているプライマリキー ID を取得します。
マッピングで定義されている rowkeyFormatterType パラメーターに基づいて、検索インデックステーブルのプライマリキー ID をワイドテーブルのプライマリキー
row1に変換します。詳細については、「rowkeyFormatterType」をご参照ください。この例では、STRING メソッドを使用して、検索インデックステーブルのプライマリキー ID を変換します。そのため、検索インデックステーブルのプライマリキー ID は、ワイドテーブルのプライマリキー ID と同じです。Lindorm Shell で次のコマンドを実行して、ワイドテーブルのデータをクエリします。
get 'testTable','row1'次の結果が返されます。
COLUMN CELL f:name timestamp=1644462597661, value=foo 1 row(s) Took 0.0942 seconds
Lindorm Tunnel Service(LTS)Web UI でリアルタイムデータ同期タスクのステータスを表示します。ワイドテーブルとインデックステーブル間の列マッピングが構成されると、ワイドテーブルに書き込まれたデータはリアルタイムでインデックステーブルに自動的に同期されます。
LTS Web UI にログオンするには、Lindorm コンソールでインスタンス ID をクリックします。左側のナビゲーションペインで、 を選択します。 [ データ同期管理 ] セクションで、[ Clustermanager インターネット ] または [ Clustermanager VPC ] をクリックします。
左側のナビゲーションペインで、 を選択します。
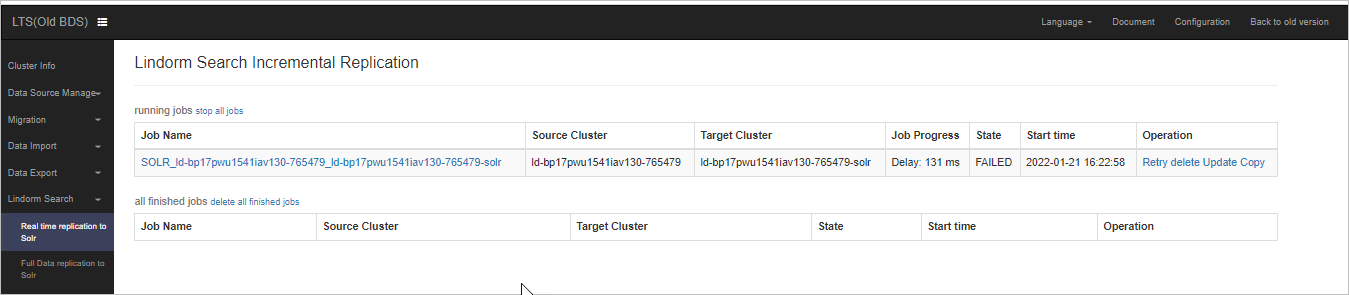 説明
説明CloudMonitor コンソールでリアルタイムデータ同期のレイテンシメトリックを構成できます。最大タスクレイテンシのアラートしきい値は 600,000 ミリ秒に設定できます。詳細については、「クラウドサービスモニタリング」をご参照ください。