Hologres V3.0 以降のバージョンでは、クエリキュー機能をサポートしています。この機能により、リクエストの順序付き処理、負荷分散、リソース管理が可能になります。高い同時実行性の下で、システムの安定性と応答効率を確保します。
機能紹介
デフォルトでは、インスタンスに送信されたリクエストには同時実行制御がありません。エンジンのコーディネーターがリソースを割り当て、即座に実行します。クエリキュー機能が有効になっている場合、Hologres は受信した SQL リクエストを構成済みの分類ルールと照合し、異なるクエリキューにルーティングします。各クエリキューは最大同時実行数制限をサポートしています。この制限に達すると、新しいリクエストは計算リソースが利用可能になるまでキューで待機します。
注意事項
-
クエリキューとオプティマイザーの設定は、汎用インスタンスではインスタンスレベルで、計算グループインスタンスでは計算グループレベルで適用されます。インスタンスに複数のデータベースが含まれている場合、これらの設定はすべてのデータベースに影響します。
-
Hologres V3.0 以降のバージョンでは、General-purpose および Virtual Warehouse インスタンスのみがクエリキュー機能をサポートしています。
説明ご利用のインスタンスが V3.0 より前のバージョンを実行している場合は、インスタンスをアップグレードするか、Hologres DingTalk サポートグループに参加してアップグレードをリクエストできます。オンラインサポートの DingTalk グループへの参加方法の詳細については、「オンラインサポートをさらに受けるにはどうすればよいですか?」をご参照ください。
-
Hologres V3.0.10 以降のバージョンでは、クエリキューを構成して、そのすべての SQL クエリをサーバーレスコンピューティングリソースを使用して実行できます。同時実行数制限とキューイングメカニズムは、ローカルリソースにのみ適用されます。サーバーレスコンピューティングを使用するクエリは、これらの設定の影響を受けません。
-
各 General-purpose インスタンスと、Virtual Warehouse インスタンスの各計算グループには、
default_queueという名前のデフォルトのクエリキューがあります。このキューには、最大同時クエリ数または最大キューサイズに制限はありません。-
default_queueは分類子をサポートしていません。そのプロパティのみを構成できます。 -
default_queueは、他のどのクエリキューにも一致しないすべてのリクエストを処理します。
-
-
各 General-purpose インスタンスと Virtual Warehouse インスタンスの各計算グループは、
default_queueを含め、最大 10 個のクエリキューをサポートします。各クエリキューは、最大 10 個のクラシファイアをサポートします。 -
読み取り専用レプリカインスタンスでクエリキュー機能を個別に有効にすることはできません。読み取り専用レプリカインスタンスは、プライマリインスタンスからクエリキューのルールを継承します。
-
`engine_type` が
HQE、PQE、SQE、またはHiveQEのクエリのみがクエリキューにマッチングされます。サポートされているクエリタイプには、SELECT 文、INSERT 文、UPDATE 文、および DELETE 文、ならびに COPY コマンドまたは CTAS コマンドによって生成される INSERT 文が含まれます。 -
固定プランを使用するクエリはクエリキューをバイパスするため、同時実行やキューイングの制御を受けません。詳細については、「固定プランによる SQL 実行の高速化」をご参照ください。
-
1 つの分類子は 1 つのクエリキューにのみ属しますが、1 つのクエリキューは複数の分類子を持つことができます。
操作手順
クエリキューの作成
-
構文
-
General-purpose インスタンス
CALL hg_create_query_queue (query_queue_name, max_concurrency, max_queue_size); -
Virtual Warehouse インスタンス
CALL hg_create_query_queue (warehouse_name, query_queue_name, max_concurrency, max_queue_size);
-
-
パラメーター
-
warehouse_name:オプション。計算グループの名前。このパラメーターを指定しない場合、クエリキューは現在接続している計算グループに作成されます。
説明このパラメーターは、Virtual Warehouse インスタンスにのみ必要です。
-
query_queue_name:必須。クエリキューの名前。名前はインスタンスまたは計算グループ内で一意である必要があります。
-
max_concurrency:オプション。最大同時実行クエリ数。デフォルト値は -1 で、制限がないことを示します。値は [-1, 2147483647) の範囲内である必要があります。
-
max_queue_size:オプション。キューに入れられる SQL クエリの最大数。デフォルト値は -1 で、制限がないことを示します。値は [-1, 2147483647) の範囲内である必要があります。
説明クエリキューを作成する際には、max_concurrency と max_queue_size プロパティのみを構成できます。他のプロパティを構成するには、「クエリキュープロパティの設定」をご参照ください。
-
-
例
-
General-purposeインスタンス
-- insert_queue という名前のクエリキューを最大同時実行数 10 で作成します。同時実行数の値は単一引用符で囲まないでください。 CALL hg_create_query_queue ('insert_queue', 10); -
Virtual Warehouse インスタンス
-- init_warehouse 計算グループに、insert_queue という名前のクエリキューを最大同時実行数 10 で作成します。 CALL hg_create_query_queue ('init_warehouse', 'insert_queue', 10);
-
分類子の作成
-
構文
-
General-purpose インスタンス
CALL hg_create_classifier (query_queue_name, classifier_name, priority); -
Virtual Warehouseインスタンス
CALL hg_create_classifier (warehouse_name, query_queue_name, classifier_name, priority);
-
-
パラメーター
-
warehouse_name:オプション。計算グループの名前。このパラメーターを指定しない場合、現在の計算グループが使用されます。
説明このパラメーターは、Virtual Warehouse インスタンスでのみ必要です。
-
query_queue_name:必須。分類子が属するクエリキューの名前。
-
classifier_name:必須。分類子の名前。名前はインスタンスまたは計算グループ内で一意である必要があります。
-
priority:オプション。マッチング優先度。値が大きいほど優先度が高くなります。デフォルト値は 50 です。値は [1, 100] の範囲内である必要があります。分類子を作成する際にこのパラメーターを指定しない場合、後で構成できます。詳細については、「分類子プロパティの設定」をご参照ください。
説明-
priority の値が高い分類子が先にマッチングされます。
-
複数の分類子が同じ優先度を持つ場合、クエリキュー名と分類子名の辞書順に基づいてマッチングされます。たとえば、クエリは queue_b(classifier_1) よりも先に queue_a(classifier_1) にマッチングされます。
-
-
-
例
-
General-purpose インスタンス
-- insert_queue に、classifier_insert という名前の分類子を優先度 20 で作成します。優先度の値は単一引用符で囲まないでください。 CALL hg_create_classifier ('insert_queue', 'classifier_insert', 20); -
Virtual Warehouse インスタンス
-- init_warehouse 計算グループの insert_queue に、classifier_insert という名前の分類子を優先度 20 で作成します。 CALL hg_create_classifier ('init_warehouse', 'insert_queue', 'classifier_insert', 20);
-
分類子のマッチングルールの設定
クエリキュー機能では、分類子のマッチング規則を構成して、SQL クエリを適切なキューにルーティングできます。
-
構文
-
General-purposeインスタンス
CALL hg_set_classifier_rule_condition_value (query_queue_name, classifier_name, condition_name, condition_value); -
Virtual Warehouse インスタンス
CALL hg_set_classifier_rule_condition_value (warehouse_name, query_queue_name, classifier_name, condition_name, condition_value);
-
-
パラメーター
名前
説明
warehouse_name
オプション。計算グループ名。省略した場合、現在の計算グループが使用されます。
説明このパラメーターは、Virtual Warehouse インスタンスでのみ必要です。
query_queue_name
必須。クエリキュー名。
classifier_name
必須。構成する分類子名。
condition_name と condition_value
必須。サポートされている条件属性:
user_name:現在のアカウントの UID。
-
command_tag:リクエストタイプ。値:INSERT、SELECT、UPDATE、DELETE。
Hologres は、効率向上のため INSERT を使用して COPY 操作を実装します。したがって、INSERT の同時実行を制限すると、COPY の書き込み同時実行にも影響します。
db_name:データベース名。
-
engine_type:クエリエンジン。値:HQE、PQE、SQE、HiveQE。Hologres V3.1.18 以降で推奨。
-
digest:SQL 指紋。詳細については、「SQL 指紋」をご参照ください。
-
application_name:クエリを開始したアプリケーション。V3.0.9 以降でサポート。
-
storage_mode:ストレージモード。値:hot、cold。Hologres V3.1.18 または V3.1.8 以降で推奨。
-
write_table:クエリによって書き込まれるテーブル。フォーマット:
<db_name>.<schema_name>.<table_name>。V3.1 以降でサポート。 -
read_table:クエリによって読み取られるテーブル。V3.1 以降でサポート。
1 つの分類子は複数の属性を持つことができ、各属性は複数のマッチング規則を持つことができます。Hologres V3.1.18 以降のバージョンでは、属性と規則の関係は次のとおりです:
-
分類子が複数の属性の規則を持つ場合:
-
異なる属性の規則は AND 関係にあります。たとえば、分類子が user_name と command_tag 属性の規則を持つ場合、クエリはこの分類子に割り当てられるために両方の規則に一致する必要があります。
-
属性間に OR 関係を定義し、クエリがいずれかの属性の条件を満たした場合にマッチングされるようにするには、複数の分類子を作成し、それらを同じクエリキューに割り当てます。
-
-
分類子内で、同じプロパティのマッチング規則には、次の 3 種類の関係があります:
-
user_name/command_tag/db_name/digest/application_name:
-
構成された値は set_a という名前のセットを形成します。
-
クエリの属性値は set_b という名前のセットを形成し、これには単一の値が含まれます。
-
クエリは
set_b ⊆ set_aの場合にマッチングされます。
-
-
storage_mode:
-
同じプロパティ (現在は storage_mode に限定) について、set_a はマッチング規則で構成された値のコレクションです。
-
クエリに対応するプロパティコレクションは set_b であり、「hot」、「cold」、または「hot, cold」の値を受け入れます。
-
クエリは
set_a == set_bの場合にのみマッチングされます。
-
-
engine_type/write_table/read_table:
-
構成された値は set_a という名前のセットを形成します。
-
クエリに関与するテーブルは set_b という名前のセットを形成し、これには任意の数のテーブルを含めることができます。
-
クエリは
(set_a ∩ set_b) != ∅の場合にマッチングされます。
-
-
説明-
一度に 1 つの条件属性のみを構成できます。条件値が大文字と小文字を区別する場合は、二重引用符 ("") で囲んでください。
-
同じ条件属性に対して複数の値をマッチングさせるには、プロシージャを複数回呼び出します。たとえば、command_tag に対して SELECT と INSERT の両方をマッチングさせるには、2 つの別々の文を実行します。
-
例
この例では、計算グループインスタンスを使用して、デフォルトの計算グループ `init_warehouse` のためにクエリキュー `test_queue` を作成します。汎用インスタンスの場合、最初の入力パラメーターを省略します。
CALL hg_create_query_queue ('init_warehouse', 'test_queue');-
例 1:p4_123 または p4_456 ユーザーによって開始されたクエリ、または SQL 指紋が xxx または yyy であるクエリを test_queue に割り当てます。
-- user と digest 属性の間に OR 関係を定義するには、2 つの分類子を作成します。 -- classifier_user を作成し、test_queue にバインドします CALL hg_create_classifier ('init_warehouse', 'test_queue', 'classifier_user'); -- ユーザー "p4_123" または "p4_456" のためのユーザーベースのマッチング規則を設定します CALL hg_set_classifier_rule_condition_value ('init_warehouse','test_queue', 'classifier_user', 'user_name', 'p4_123'); CALL hg_set_classifier_rule_condition_value ('init_warehouse','test_queue', 'classifier_user', 'user_name', 'p4_456'); -- classifier_digest を作成し、test_queue にバインドします CALL hg_create_classifier ('init_warehouse', 'test_queue', 'classifier_digest'); -- 指紋 "xxx" または "yyy" のためのダイジェストベースのマッチング規則を設定します CALL hg_set_classifier_rule_condition_value ('init_warehouse','test_queue', 'classifier_digest', 'digest', 'xxx'); CALL hg_set_classifier_rule_condition_value ('init_warehouse','test_queue', 'classifier_digest', 'digest', 'yyy'); -
例 2:xx_bi アプリケーションによって開始され、ホットストレージとコールドストレージの両方にアクセスするクエリを test_queue に割り当てます。
-- アプリケーションとストレージモードの間に AND 関係を定義するには、両方の属性を 1 つの分類子で構成します。 -- classifier_3 を作成し、test_queue にバインドします CALL hg_create_classifier ('init_warehouse', 'test_queue', 'classifier_3'); -- アプリケーションベースのマッチング規則を設定します CALL hg_set_classifier_rule_condition_value ('init_warehouse','test_queue', 'classifier_3', 'application_name', 'xx_bi'); -- ストレージモードの規則を設定します。クエリが両方にアクセスする場合にのみマッチングされるように、"hot" と "cold" の両方を設定する必要があります。 CALL hg_set_classifier_rule_condition_value ('init_warehouse','test_queue', 'classifier_3', 'storage_mode', 'hot'); CALL hg_set_classifier_rule_condition_value ('init_warehouse','test_queue', 'classifier_3', 'storage_mode', 'cold'); -
例 3:コールドストレージにアクセスするすべてのクエリを test_queue に割り当てます。
-- storage_mode は完全一致を要求するため、「コールドストレージへのアクセス」を 2 つのケースに分割します。 -- classifier_cold_1 を作成し、test_queue にバインドします CALL hg_create_classifier ('init_warehouse', 'test_queue', 'classifier_cold_1'); -- storage_mode = cold のクエリはここに移動します CALL hg_set_classifier_rule_condition_value ('init_warehouse','test_queue', 'classifier_cold_1', 'storage_mode', 'cold'); -- classifier_cold_2 を作成し、test_queue にバインドします CALL hg_create_classifier ('init_warehouse', 'test_queue', 'classifier_cold_2'); -- storage_mode = hot,cold のクエリはここに移動します CALL hg_set_classifier_rule_condition_value ('init_warehouse','test_queue', 'classifier_cold_2', 'storage_mode', 'hot'); CALL hg_set_classifier_rule_condition_value ('init_warehouse','test_queue', 'classifier_cold_2', 'storage_mode', 'cold'); -
例 4:テーブル a からデータを読み取り、テーブル b にデータを書き込むクエリを test_queue に割り当てます。
-- read_table と write_table の間に AND 関係を定義するには、両方を 1 つの分類子で構成します。 -- classifier_table を作成し、test_queue にバインドします CALL hg_create_classifier ('init_warehouse', 'test_queue', 'classifier_table'); -- read_table 規則を設定します。テーブル a を読み取るクエリは、他の読み取りテーブルに関係なくマッチングします。 CALL hg_set_classifier_rule_condition_value ('init_warehouse','test_queue', 'classifier_table', 'read_table', 'db_name.schema_name.a'); -- write_table 規則を設定します。テーブル b に書き込むクエリがマッチングします。 CALL hg_set_classifier_rule_condition_value ('init_warehouse','test_queue', 'classifier_table', 'write_table', 'db_name.schema_name.b');
-
追加の操作
大規模クエリ制御
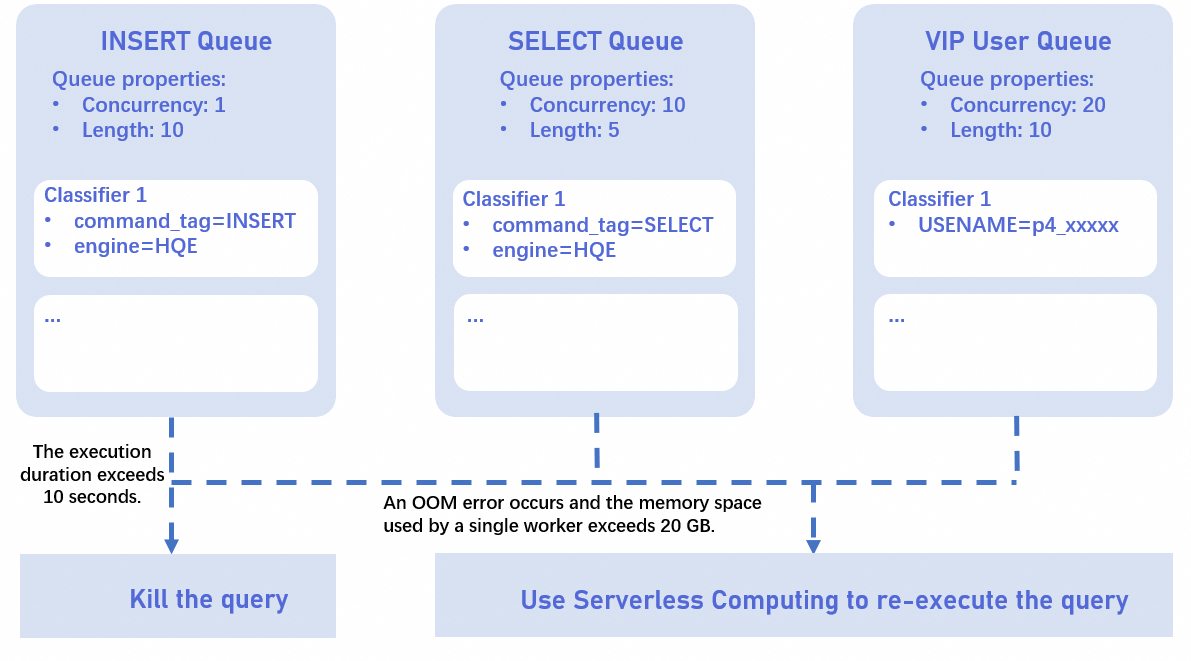
大規模クエリの影響を制限するために、クエリキュー機能を使用して実行時間と Out-of-Memory (OOM) 状態を管理できます。構成されたしきい値を超えたクエリについては、それらを終了させるか、サーバーレスコンピューティングリソースを使用して再実行することができます。
-
Hologres V3.0 は SELECT クエリの再実行のみをサポートします。FETCH を使用してデータを取得する場合、FETCH 操作がデータを返さない場合にのみクエリが再実行されます。これにより、結果の正確性が保証されます。
-
クエリの実行には、optimization_cost (実行計画の生成)、start_query_cost (クエリの開始)、get_next_cost (クエリの実行) の 3 つのフェーズが含まれます。詳細については、「スロークエリログの表示と分析」をご参照ください。クエリキュー機能の大規模クエリ制御は、get_next_cost フェーズのみを考慮します。キューの待機時間とロックの待機時間は含まれません。
-
実行時間制御
big_query_execution_time_threshold_sec パラメーターを設定できます。単位は秒です。デフォルト値は -1 で、制限がないことを示します。値は [-1, 2147483647) の範囲内である必要があります。以下の例は、実行時間を制御する方法を示しています:
-
シナリオ 1:長時間実行されるクエリを終了する
select_queue 内のクエリはローカルリソースで実行されます。クエリの実行時間が 10 秒を超えた場合、クエリは終了します。
CALL hg_set_query_queue_property ('select_queue', 'big_query_execution_time_threshold_sec', '10'); -
シナリオ 2:長時間実行されるクエリを再実行する
select_queue 内のクエリはローカルリソースで実行されます。クエリの実行時間が 10 秒を超えた場合、クエリは終了し、その後サーバーレスコンピューティングを使用して再実行されます。
CALL hg_set_query_queue_property ('select_queue', 'big_query_execution_time_threshold_sec', '10'); CALL hg_set_query_queue_property ('select_queue', 'enable_rerun_as_big_query_when_exceeded_execution_time_threshold', 'true'); CALL hg_set_query_queue_property ('select_queue', 'rerun_big_query_on_computing_resource', 'serverless');説明-
enable_rerun_as_big_query_when_exceeded_execution_time_threshold:タイムアウトによりクエリが終了した後、他のリソースを使用してクエリを再実行するかどうかを指定します。デフォルト値は false です。
-
rerun_big_query_on_computing_resource:クエリの再実行に使用されるサーバーレスコンピューティングリソースの名前。
-
-
-
OOM に基づく再実行
select_queue 内のクエリはローカルリソースで実行されます。クエリが OOM エラーをトリガーし、単一のワーカーノードで 10 GB を超えるメモリを使用した場合、クエリはサーバーレスコンピューティングを使用して再実行されます。big_query_mem_threshold_when_oom_gb パラメーターは OOM メモリのしきい値を設定します。デフォルト値は -1 で、制限がないことを示します。値は [-1, 64) の範囲内である必要があります。以下の例は、OOM エラーに基づいてクエリを再実行する方法を示しています:
CALL hg_set_query_queue_property ('select_queue', 'big_query_mem_threshold_when_oom_gb', '10'); CALL hg_set_query_queue_property ('select_queue', 'enable_rerun_as_big_query_when_oom_exceeded_mem_threshold', 'true'); CALL hg_set_query_queue_property ('select_queue', 'rerun_big_query_on_computing_resource', 'serverless');
クエリキューの管理
クエリキューの削除
-
構文
-
General-purpose インスタンス
CALL hg_drop_query_queue (query_queue_name); -
Virtual Warehouse インスタンス
CALL hg_drop_query_queue (warehouse_name, query_queue_name);
-
-
パラメーター
-
warehouse_name:オプション。計算グループの名前。このパラメーターを指定しない場合、現在の計算グループが使用されます。
説明このパラメーターは、Virtual Warehouse インスタンスの場合のみ必須です。
-
query_queue_name:必須。クエリキューの名前。
-
例
-
General-purpose インスタンス
-- insert_queue クエリキューを削除します CALL hg_drop_query_queue ('insert_queue'); -
Virtual Warehouse インスタンス
-- init_warehouse 計算グループで、insert_queue クエリキューを削除します CALL hg_drop_query_queue ('init_warehouse', 'insert_queue');
クエリキュープロパティの削除
-
構文
-
General-purposeインスタンス
CALL hg_remove_query_queue_property (query_queue_name, property_key); -
Virtual Warehouse インスタンス
CALL hg_remove_query_queue_property (warehouse_name, query_queue_name, property_key);
-
-
パラメーター
-
warehouse_name:オプション。計算グループの名前。このパラメーターを指定しない場合、現在の計算グループが使用されます。
説明このパラメーターは、Virtual Warehouse インスタンスのみで必要です。
-
query_queue_name:必須。クエリキューの名前。
-
property_key:必須。プロパティの名前。有効な値:max_concurrency、max_queue_size、queue_timeout_ms。詳細については、「クエリキュープロパティの設定」をご参照ください。
-
-
例
-
General-purposeインスタンス
-- insert_queue の max_concurrency プロパティを削除します CALL hg_remove_query_queue_property('insert_queue', 'max_concurrency'); -- insert_queue の max_queue_size プロパティを削除します CALL hg_remove_query_queue_property('insert_queue', 'max_queue_size'); -- insert_queue の queue_timeout_ms プロパティを削除します CALL hg_remove_query_queue_property('insert_queue', 'queue_timeout_ms'); -
Virtual Warehouse インスタンス
-- init_warehouse 計算グループで、insert_queue の max_concurrency プロパティを削除します CALL hg_remove_query_queue_property('init_warehouse', 'insert_queue', 'max_concurrency'); -- init_warehouse 計算グループで、insert_queue の max_queue_size 設定を削除します CALL hg_remove_query_queue_property('init_warehouse', 'insert_queue', 'max_queue_size'); -- init_warehouse 計算グループで、insert_queue の queue_timeout_ms プロパティを削除します CALL hg_remove_query_queue_property('init_warehouse', 'insert_queue', 'queue_timeout_ms');
-
クエリキューのメタデータの表示
クエリキューのメタデータは、hologres.hg_query_queues システムテーブルに格納されます。主要なフィールドは次の表に記載されています。
フィールド名 |
データ型 |
説明 |
warehouse_id |
INT |
計算グループの ID。 説明
General-purpose インスタンスの場合、warehouse_id は 0 です。 |
warehouse_name |
TEXT |
計算グループ名。 説明
[General-purpose] インスタンスの場合、warehouse_name は Empty です。 |
query_queue_name |
TEXT |
キューの名前。 |
property_key | TEXT | プロパティ名。 |
property_value | TEXT | プロパティ値。 |
クエリキュープロパティの設定
-
構文
-
General-purposeインスタンス
CALL hg_set_query_queue_property (query_queue_name, property_key, property_value); -
Virtual Warehouse インスタンス
CALL hg_set_query_queue_property (warehouse_name, query_queue_name, property_key, property_value);
-
-
パラメーター
-
warehouse_name:オプション。計算グループの名前。このパラメーターを指定しない場合、現在の計算グループが使用されます。
説明このパラメーターは、Virtual Warehouse インスタンスにのみ必要です。
-
query_queue_name:必須。クエリキューの名前。
-
property_key と property_value:必須。サポートされているプロパティは次のとおりです:
-
max_concurrency:最大同時実行クエリ数。デフォルト値は -1 で、制限がないことを示します。値は [-1, 2147483647) の範囲内である必要があります。
-
max_queue_size:キューに入れられる SQL クエリの最大数。デフォルト値は -1 で、制限がないことを示します。値は [-1, 2147483647) の範囲内である必要があります。
-
queue_timeout_ms:最大キュー待機時間。単位:ミリ秒 (ms)。この時間を超えたクエリは終了します。デフォルト値は -1 で、制限がないことを示します。値は [-1, 2147483647) の範囲内である必要があります。
-
-
-
例
-
General-purpose インスタンス
-- insert_queue の max_concurrency を 15 に設定します CALL hg_set_query_queue_property('insert_queue', 'max_concurrency', '15'); -- insert_queue の max_queue_size を 15 に設定します CALL hg_set_query_queue_property('insert_queue', 'max_queue_size', '15'); -- insert_queue の queue_timeout_ms を 3000 ms に設定します CALL hg_set_query_queue_property('insert_queue', 'queue_timeout_ms', '3000'); -
Virtual Warehouse インスタンス
-- init_warehouse 計算グループで、insert_queue の max_concurrency を 15 に設定します CALL hg_set_query_queue_property('init_warehouse', 'insert_queue', 'max_concurrency', '15'); -- init_warehouse 計算グループで、insert_queue の max_queue_size を 15 に設定します CALL hg_set_query_queue_property('init_warehouse', 'insert_queue', 'max_queue_size', '15'); -- init_warehouse 計算グループで、insert_queue の queue_timeout_ms を 3000 ms に設定します CALL hg_set_query_queue_property('init_warehouse', 'insert_queue', 'queue_timeout_ms', '3000');
-
クエリキューからキューイングされたリクエストをクリア
-
構文
-
General-purpose インスタンス
CALL hg_clear_query_queue (query_queue_name); -
Virtual Warehouse インスタンス
CALL hg_clear_query_queue (warehouse_name, query_queue_name);
-
-
パラメーター
-
warehouse_name:オプション。計算グループの名前。このパラメーターを指定しない場合、現在の計算グループが使用されます。
説明このパラメーターは、Virtual Warehouse インスタンスのみで必要です。
-
query_queue_name:必須。クエリキューの名前。
-
-
例
-
General-purpose インスタンス
-- select_queue 内のすべてのキューイングされたリクエストをクリアします CALL hg_clear_query_queue ('select_queue'); -
Virtual Warehouse インスタンス
-- init_warehouse 計算グループの select_queue 内のすべてのキューイングされたリクエストをクリアします CALL hg_clear_query_queue ('init_warehouse', 'select_queue');
-
分類子の管理
分類子の削除
-
構文
-
General-purposeインスタンス
CALL hg_drop_classifier (query_queue_name, classifier_name); -
Virtual Warehouse インスタンス
CALL hg_drop_classifier (warehouse_name, query_queue_name, classifier_name);
-
-
パラメーター
-
warehouse_name:オプション。計算グループの名前。このパラメーターを指定しない場合、現在の計算グループが使用されます。
説明このパラメーターは、Virtual Warehouse インスタンスの場合にのみ必要です。
-
query_queue_name:必須。クエリキューの名前。
-
classifier_name:必須。分類子の名前。
-
-
例
-
General-purpose インスタンス
-- insert_queue で、classifier_insert 分類子を削除します CALL hg_drop_classifier ('insert_queue', 'classifier_insert'); -
Virtual Warehouse インスタンス
-- init_warehouse 計算グループの insert_queue で、classifier_insert 分類子を削除します CALL hg_drop_classifier ('init_warehouse', 'insert_queue', 'classifier_insert');
-
分類子プロパティの削除
-
構文
-
General-purpose インスタンス
CALL hg_remove_classifier_property (query_queue_name, classifier_name, property_key); -
Virtual Warehouse インスタンス
CALL hg_remove_classifier_property (warehouse_name, query_queue_name, classifier_name, property_key);
-
-
パラメーター
-
warehouse_name:オプション。計算グループの名前。このパラメーターを指定しない場合、現在の計算グループが使用されます。
説明このパラメーターは、Virtual Warehouse インスタンスの場合にのみ必要です。
-
query_queue_name:必須。クエリキューの名前。
-
classifier_name:必須。分類子の名前。
-
property_key:必須。サポートされているプロパティは priority です。詳細については、「分類子プロパティの設定」をご参照ください。
-
-
例
-
General-purposeインスタンス
-- insert_queue で、classifier_insert の priority プロパティを削除します CALL hg_remove_classifier_property ('insert_queue', 'classifier_insert', 'priority'); -
Virtual Warehouse インスタンス
-- init_warehouse 計算グループの insert_queue で、classifier_insert の priority プロパティを削除します CALL hg_remove_classifier_property ('init_warehouse', 'insert_queue', 'classifier_insert', 'priority');
-
分類子プロパティの設定
-
構文
-
General-purposeインスタンス
CALL hg_set_classifier_property (query_queue_name, classifier_name, property_key, property_value); -
Virtual Warehouse インスタンス
CALL hg_set_classifier_property (warehouse_name, query_queue_name, classifier_name, property_key, property_value);
-
-
パラメーター
-
warehouse_name:オプション。計算グループの名前。このパラメーターを指定しない場合、現在の計算グループが使用されます。
説明このパラメーターは、Virtual Warehouse インスタンスでのみ必要です。
-
query_queue_name:必須。クエリキューの名前。
-
classifier_name:必須。分類子の名前。
-
property_key と property_value:必須。サポートされているプロパティは次のとおりです:
priority:分類子のマッチング優先度。値が大きいほど優先度が高くなります。デフォルト値は 50 です。値は [1, 100] の範囲内である必要があります。
説明-
priority の値が高い分類子が先にマッチングされます。
-
複数の分類子が同じ優先度を持つ場合、クエリキュー名と分類子名の辞書順に基づいてマッチングされます。たとえば、クエリは queue_b(classifier_1) よりも先に queue_a(classifier_1) にマッチングされます。
-
-
-
例
-
General-purposeインスタンス
-- insert_queue で、classifier_insert の優先度を 30 に設定します CALL hg_set_classifier_property ('insert_queue', 'classifier_insert', 'priority', '30'); -
Virtual Warehouse インスタンス
-- init_warehouse 計算グループの insert_queue で、classifier_insert の優先度を 30 に設定します CALL hg_set_classifier_property ('init_warehouse', 'insert_queue', 'classifier_insert','priority', '30');
-
分類子のマッチングルールの削除
-
分類子内の特定の条件属性 (condition_name) のマッチング規則を削除する
-
構文
-
General-purposeインスタンス
CALL hg_remove_classifier_rule_condition_value (query_queue_name, classifier_name, condition_name, condition_value); -
Virtual Warehouse インスタンス
CALL hg_remove_classifier_rule_condition_value (warehouse_name, query_queue_name, classifier_name, condition_name, condition_value);
-
-
パラメーター
-
warehouse_name:オプション。計算グループの名前。このパラメーターを指定しない場合、現在の計算グループが使用されます。
説明このパラメーターは、Virtual Warehouse インスタンスにのみ必要です。
-
query_queue_name:必須。クエリキューの名前。
-
classifier_name:必須。分類子の名前。
-
condition_name と condition_value:必須。削除したい条件属性とその値。condition_name の有効な値:user_name、command_tag、db_name、engine_type、digest、storage_mode。詳細については、「分類子のマッチング規則の設定」をご参照ください。
-
-
例
-
General-purposeインスタンス
-- insert_queue で、classifier_insert から command_tag = INSERT 規則を削除します CALL hg_remove_classifier_rule_condition_value ('insert_queue', 'classifier_insert', 'command_tag', 'INSERT'); -- insert_queue で、classifier_insert から user_name = p4_12345 規則を削除します CALL hg_remove_classifier_rule_condition_value ('insert_queue', 'classifier_insert', 'user_name', 'p4_12345'); -- insert_queue で、classifier_insert から db_name = prd_db 規則を削除します CALL hg_remove_classifier_rule_condition_value ('insert_queue', 'classifier_insert', 'db_name', 'prd_db'); -- insert_queue で、classifier_insert から engine_type = HQE 規則を削除します CALL hg_remove_classifier_rule_condition_value ('insert_queue', 'classifier_insert', 'engine_type', 'HQE'); -- insert_queue で、classifier_insert から digest = md5edb3161000a003799a5d3f2656b70b4c 規則を削除します CALL hg_remove_classifier_rule_condition_value ('insert_queue', 'classifier_insert', 'digest', 'md5edb3161000a003799a5d3f2656b70b4c'); -- insert_queue で、classifier_insert から storage_mode = hot 規則を削除します CALL hg_remove_classifier_rule_condition_value ('insert_queue', 'classifier_insert', 'storage_mode', 'hot'); -
Virtual Warehouse インスタンス
-- init_warehouse の insert_queue で、classifier_insert から command_tag = INSERT 規則を削除します CALL hg_remove_classifier_rule_condition_value ('init_warehouse', 'insert_queue', 'classifier_insert', 'command_tag', 'INSERT'); -- init_warehouse の insert_queue で、classifier_insert から user_name = p4_12345 規則を削除します CALL hg_remove_classifier_rule_condition_value ('init_warehouse', 'insert_queue', 'classifier_insert', 'user_name', 'p4_12345'); -- init_warehouse の insert_queue で、classifier_insert から db_name = prd_db 規則を削除します CALL hg_remove_classifier_rule_condition_value ('init_warehouse', 'insert_queue', 'classifier_insert', 'db_name', 'prd_db'); -- init_warehouse の insert_queue で、classifier_insert から engine_type = HQE 規則を削除します CALL hg_remove_classifier_rule_condition_value ('init_warehouse', 'insert_queue', 'classifier_insert', 'engine_type', 'HQE'); -- init_warehouse の insert_queue で、classifier_insert から digest = md5edb3161000a003799a5d3f2656b70b4c 規則を削除します CALL hg_remove_classifier_rule_condition_value ('init_warehouse', 'insert_queue', 'classifier_insert', 'digest', 'md5edb3161000a003799a5d3f2656b70b4c'); -- init_warehouse の insert_queue で、classifier_insert から storage_mode = hot 規則を削除します CALL hg_remove_classifier_rule_condition_value ('init_warehouse', 'insert_queue', 'classifier_insert', 'storage_mode', 'hot');
-
-
-
分類子内の特定の条件属性 (condition_name) のすべてのマッチング規則を削除する
-
構文
-
General-purposeインスタンス
CALL hg_remove_classifier_rule_condition (query_queue_name, classifier_name, condition_name); -
Virtual Warehouse インスタンス
CALL hg_remove_classifier_rule_condition (warehouse_name, query_queue_name, classifier_name, condition_name);
-
-
パラメーター
-
warehouse_name:オプション。計算グループの名前。このパラメーターを指定しない場合、現在の計算グループが使用されます。
説明このパラメーターは、Virtual Warehouse インスタンスの場合にのみ必要です。
-
query_queue_name:必須。クエリキューの名前。
-
classifier_name:必須。分類子の名前。
-
condition_name:必須。規則を削除したい条件属性。有効な値:user_name、command_tag、db_name、engine_type、digest、storage_mode。詳細については、「分類子のマッチング規則の設定」をご参照ください。
-
-
例
-
General-purpose インスタンス
-- insert_queue で、classifier_insert からすべての command_tag 規則を削除します CALL hg_remove_classifier_rule_condition ('insert_queue', 'classifier_insert', 'command_tag'); -- insert_queue で、classifier_insert からすべての user_name 規則を削除します CALL hg_remove_classifier_rule_condition ('insert_queue', 'classifier_insert', 'user_name'); -- insert_queue で、classifier_insert からすべての db_name 規則を削除します CALL hg_remove_classifier_rule_condition ('insert_queue', 'classifier_insert', 'db_name'); -- insert_queue で、classifier_insert からすべての engine_type 規則を削除します CALL hg_remove_classifier_rule_condition ('insert_queue', 'classifier_insert', 'engine_type'); -- insert_queue で、classifier_insert からすべての digest 規則を削除します CALL hg_remove_classifier_rule_condition ('insert_queue', 'classifier_insert', 'digest'); -- insert_queue で、classifier_insert からすべての storage_mode 規則を削除します CALL hg_remove_classifier_rule_condition ('insert_queue', 'classifier_insert', 'storage_mode'); -
Virtual Warehouse インスタンス
-- init_warehouse の insert_queue で、classifier_insert からすべての command_tag 規則を削除します CALL hg_remove_classifier_rule_condition ('init_warehouse', 'insert_queue', 'classifier_insert', 'command_tag'); -- init_warehouse の insert_queue で、classifier_insert からすべての user_name 規則を削除します CALL hg_remove_classifier_rule_condition ('init_warehouse', 'insert_queue', 'classifier_insert', 'user_name'); -- init_warehouse の insert_queue で、classifier_insert からすべての db_name 規則を削除します CALL hg_remove_classifier_rule_condition ('init_warehouse', 'insert_queue', 'classifier_insert', 'db_name'); -- init_warehouse の insert_queue で、classifier_insert からすべての engine_type 規則を削除します CALL hg_remove_classifier_rule_condition ('init_warehouse', 'insert_queue', 'classifier_insert', 'engine_type'); -- init_warehouse の insert_queue で、classifier_insert からすべての digest 規則を削除します CALL hg_remove_classifier_rule_condition ('init_warehouse', 'insert_queue', 'classifier_insert', 'digest'); -- init_warehouse の insert_queue で、classifier_insert からすべての storage_mode 規則を削除します CALL hg_remove_classifier_rule_condition ('init_warehouse', 'insert_queue', 'classifier_insert', 'storage_mode');
-
-
分類子メタデータの表示
分類子のメタデータは、hologres.hg_classifiers システムテーブルに格納されます。主要なフィールドは次の表に記載されています。
フィールド |
データ型 |
説明 |
warehouse_id |
INT |
計算グループの ID。 説明
General-purpose インスタンスの場合、warehouse_id は 0 です。 |
warehouse_name |
TEXT |
計算グループ名。 説明
General-purpose インスタンスの場合、 warehouse_name は空です。 |
query_queue_name |
TEXT |
クエリしたいキューの名前。 |
classifier_name |
TEXT |
分類子名。 |
property_key | TEXT | プロパティ名。 |
property_value | TEXT | プロパティ値。 |
サーバーレスコンピューティングリソースを使用したクエリキュークエリの実行
Hologres V3.0.10 以降のバージョンでは、クエリキューを構成して、そのすべてのクエリをサーバーレスコンピューティングリソースを使用して実行できます。構成後、キュー内のクエリは送信順序と優先度に基づいてサーバーレスリソースを要求します。これらのクエリは、キューの同時実行数制限やキューイングメカニズムの影響を受けなくなります。詳細については、「サーバーレスコンピューティングユーザーガイド」をご参照ください。
インスタンスが存在するゾーンでサーバーレスコンピューティングが利用できない場合、クエリはローカルの計算リソースで実行されます。
-
汎用インスタンス
-
構文
-- ターゲットキュー内のすべてのクエリをサーバーレスリソースを使用して実行します CALL hg_set_query_queue_property('<query_queue_name>', 'computing_resource', 'serverless'); -- (オプション) サーバーレスリソース使用時のクエリ優先度を設定します。値:1-5。デフォルト:3 CALL hg_set_query_queue_property('<query_queue_name>', 'query_priority_when_using_serverless_computing', '<priority>'); -
パラメーター
-
query_queue_name:必須。クエリキューの名前。
priority:優先度。デフォルト値は 3 です。値は
[1, 5]の範囲内である必要があります。
-
-
例
-- ターゲットキュー内のすべてのクエリをサーバーレスリソースを使用して実行します CALL hg_set_query_queue_property('insert_queue', 'computing_resource', 'serverless'); -- サーバーレスクエリの優先度を 2 に設定します CALL hg_set_query_queue_property('insert_queue', 'query_priority_when_using_serverless_computing', '2');
-
-
計算グループインスタンス
-
構文
-- ターゲットキュー内のすべてのクエリをサーバーレスリソースを使用して実行します CALL hg_set_query_queue_property('<warehouse_name>', '<query_queue_name>', 'computing_resource', 'serverless'); -- (オプション) サーバーレスリソース使用時のクエリ優先度を設定します。値:1-5。デフォルト:3 CALL hg_set_query_queue_property('<warehouse_name>', '<query_queue_name>', 'query_priority_when_using_serverless_computing', '<priority>'); -
パラメーター
-
warehouse_name:必須。計算グループの名前。
-
query_queue_name:必須。クエリキューの名前。
-
priority:必須。優先度。デフォルト値は 3 です。値は
[1, 5]の範囲内である必要があります。
-
-
例
-- ターゲットキュー内のすべてのクエリをサーバーレスリソースを使用して実行します CALL hg_set_query_queue_property('init_warehouse', 'insert_queue', 'computing_resource', 'serverless'); -- サーバーレスクエリの優先度を 2 に設定します CALL hg_set_query_queue_property('init_warehouse', 'insert_queue', 'query_priority_when_using_serverless_computing', '2');
-
利用シーン
特定の SQL 文で使用されるクエリキューの表示
EXPLAIN 文を使用してクエリキューを表示できます。結果の Query Queue フィールドは、割り当てられたキューを示します。以下に例を示します:
-- 同時実行数 10、最大キューサイズ 20 のクエリキューを作成します
CALL hg_create_query_queue ('select_queue', 10, 20);
-- 分類子を作成し、command_tag 属性をバインドします
CALL hg_create_classifier ('select_queue', 'classifier_1');
CALL hg_set_classifier_rule_condition_value ('select_queue', 'classifier_1', 'command_tag', 'select');
-- Explain Analyze を使用して、マッチングした分類子とクエリキューを表示します
EXPLAIN ANALYZE SELECT * FROM hg_stat_activity;結果は次のとおりです。
QUERY PLAN
Gather (cost=0.00..14.96 rows=1000 width=408)
[4:1 id=100003 dop=1 time=16/16/16ms rows=142(142/142/142) mem=43/43/43KB open=0/0/0ms get_next=16/16/16ms]
-> Forward (cost=0.00..12.19 rows=1000 width=408)
[0:4 id=100002 dop=4 time=16/8/5ms rows=142(39/35/33) mem=6/6/6KB open=16/8/5ms get_next=0/0/0ms scan_rows=142(39/35/33)]
-> ExecuteExternalSQL on PQE (cost=0.00..10.04 rows=0 width=408)
" External SQL: SELECT "datid" AS c_d2adb610_0, "datname" AS c_d2adb760_1, "pid" AS c_d2adb8a0_2, "usesysid" AS c_d2adba10_3, "usename" AS c_d2adbb60_4, "application_name" AS c_d2adbd10_5, "client_addr" AS c_d2adbe80_6, "client_hostname" AS c_d2df1020_7, "client_port" AS c_d2df1190_8, "backend_start" AS c_d2df1300_9, "xact_start" AS c_d2df1470_10, "query_start" AS c_d2df15e0_11, "state_change" AS c_d2df1750_12, "wait_event_type" AS c_d2df18c0_13, "wait_event" AS c_d2df1a30_14, "state" AS c_d2df1b80_15, "backend_xid" AS c_d2df1cf0_16, "backend_xmin" AS c_d2df1e60_17, "query" AS c_d2df1fb0_18, "backend_type" AS c_d2df2120_19, "query_id" AS c_d2df2290_20, "transaction_id" AS c_d2df2400_21, "extend_info" AS c_d2df2570_22, "running_info" AS c_d2df26e0_23 FROM pg_catalog."hg_stat_activity""
Query id:[1001002491453065719]
Query Queue: init_warehouse.select_queue.classifier_1アクティブなクエリのクエリキューの表示
次の SQL 文を実行して、アクティブなクエリのクエリキュー名、ステータス、キュー時間を表示できます。
SELECT
running_info::json -> 'current_stage' ->> 'stage_name' AS stage_name,
running_info::json -> 'current_stage' ->> 'queue_time_ms' AS queue_time_ms,
running_info::json ->> 'query_queue' AS query_queue,
*
FROM
hg_stat_activity;クエリログでのクエリキューの表示
次の SQL 文を使用して、クエリログでクエリキュー、ステータス、キュー時間を表示できます。query_detail フィールドには、クエリキューに関する情報が記録されます。hologres.hg_query_log システムテーブルの詳細については、「query_log テーブルの表示」をご参照ください。
SELECT * FROM hologres.hg_query_log WHERE query_detail like '%query_queue = <warehouse_name>.<queue_name>%';-- 計算グループインスタンスのみ warehouse_name が必要です結果の extended_info フィールドには、次の情報が含まれます:
-
serverless_computing_source:サーバーレスコンピューティングを使用して実行される SQL 文のソースを示します。有効な値:-
user_submit:SQL 文は明示的にサーバーレスリソースで実行するように送信され、クエリキュー機能とは関係ありません。 -
query_queue:SQL 文は、全体がサーバーレスリソースで実行されるように構成されたクエリキューからのものです。 -
query_queue_rerun:SQL 文は、クエリキュー機能の大規模クエリ制御を使用して、サーバーレスリソースで自動的に再実行されます。
-
-
query_id_of_triggered_rerun:このパラメーターは、serverless_computing_source の値が query_queue_rerun の場合にのみ返されます。再実行された SQL 文の元のクエリ ID を示します。
異なるマッチングルールを持つクエリキューの作成
-
例 1:INSERT リクエスト用のクエリキューを作成します。
クエリキューが作成された後、すべての INSERT SQL リクエストは classifier_1 によってマッチングされ、insert_queue に割り当てられます。
-- 同時実行数 10、最大キューサイズ 20 のクエリキューを作成します CALL hg_create_query_queue ('insert_queue', 10, 20); -- 分類子を作成し、command_tag 属性をバインドします CALL hg_create_classifier ('insert_queue', 'classifier_1'); CALL hg_set_classifier_rule_condition_value ('insert_queue', 'classifier_1', 'command_tag', 'INSERT'); -
ユーザー p4_123 と p4_345 のためのクエリキューを作成します。
クエリキューが作成された後、p4_123 と p4_345 ユーザーによって開始された SQL リクエストは classifier_2 によってマッチングされ、user_queue に割り当てられます。
-- 同時実行数 3、キューサイズ無制限のクエリキューを作成します CALL hg_create_query_queue ('user_queue', 3); CALL hg_set_query_queue_property('user_queue','max_queue_size', -1); -- 分類子を作成し、user_name マッチング規則を設定します CALL hg_create_classifier ('user_queue', 'classifier_2'); CALL hg_set_classifier_rule_condition_value ('user_queue', 'classifier_2', 'user_name', 'p4_123'); CALL hg_set_classifier_rule_condition_value ('user_queue', 'classifier_2', 'user_name', 'p4_345');説明ユーザーアカウントがカスタムアカウントの場合、アカウント名を二重引用符 ("") で囲んでください。例:
CALL hg_set_classifier_rule_condition_value ('user_queue', 'classifier_2', 'user_name', '"BASIC$xxx"');。 -
データベース test と postgres のためのクエリキューを作成します。
クエリキューが作成されると、test および postgres データベースの SQL リクエストは classifier_3 によって照合され、db_queue に割り当てられます。
-- 同時実行数が 5 のクエリキューを作成します CALL hg_create_query_queue ('db_queue', 5); -- 最大キュー時間を 600000 ms に設定します。この時間を超えるクエリは失敗します。 CALL hg_set_query_queue_property ('db_queue', 'queue_timeout_ms', '600000'); -- 分類子を作成し、db_name 属性をバインドします CALL hg_create_classifier ('db_queue', 'classifier_3'); CALL hg_set_classifier_rule_condition_value ('db_queue', 'classifier_3', 'db_name', 'test'); CALL hg_set_classifier_rule_condition_value ('db_queue', 'classifier_3', 'db_name', 'postgres'); -
HQE エンジンリクエスト用のクエリキューを作成します。
クエリキューが作成された後、HQE エンジンによって処理される SQL リクエストは classifier_4 によってマッチングされ、hqe_queue に割り当てられます。
-- 同時実行数 10 のクエリキューを作成します CALL hg_create_query_queue ('hqe_queue', 10); -- 分類子を作成し、engine_type 属性をバインドします CALL hg_create_classifier ('hqe_queue', 'classifier_4'); CALL hg_set_classifier_rule_condition_value ('hqe_queue', 'classifier_4', 'engine_type', 'HQE');
すべてのタスクのブロック (極端なシナリオ)
insert_queue の同時実行数とキューサイズを 0 に設定できます。以下に例を示します:
CALL hg_set_query_queue_property ('insert_queue', 'max_concurrency', '0');
CALL hg_set_query_queue_property ('insert_queue', 'max_queue_size', '0');