Hologres テーブルへのデータの書き込みまたは更新が予想より遅い場合は、本トピックを参照して原因を特定できます。一般的な原因には、上流のデータ読み取りが遅いことや Hologres のリソースボトルネックがあります。原因を特定した後は、適切なチューニング手法を適用して、書き込みおよび更新パフォーマンスを向上させます。
背景情報
Hologres は、大規模なデータ量に対して高性能・低遅延でリアルタイムな書き込みおよび更新をサポートする、ワンストップのリアルタイムデータウェアハウスエンジンです。この機能により、ビッグデータシナリオにおける高性能および低レイテンシ要件が満たされます。
基本原則
書き込みおよび更新のチューニング手法について学ぶ前に、まず基本原則を理解することが重要です。この知識により、異なる書き込みモードにおける書き込みパフォーマンスをより正確に推定できます。
テーブルのストレージ形式ごとの書き込みおよび更新パフォーマンス
全列書き込みまたは更新の場合、パフォーマンスの順位は以下のとおりです。
行指向 > 列指向 > 行列ハイブリッド部分列書き込みまたは更新の場合、パフォーマンスの順位は以下のとおりです。
行指向 > 行列ハイブリッド > 列指向
異なる書き込みモードのパフォーマンス
サポートされている書き込みモードは以下のとおりです。
書き込みモード
説明
Insert
追加専用モードでデータを書き込みます。送信先テーブルにはプライマリキー (PK) がありません。
InsertOrIgnore
書き込み時に更新を無視します。送信先テーブルにはプライマリキーがあります。リアルタイム書き込み中にプライマリキーが重複した場合、後のデータレコードは破棄されます。
InsertOrReplace
書き込み時にデータを上書きします。送信先テーブルにはプライマリキーがあります。リアルタイム書き込み中にプライマリキーが重複した場合、プライマリキーに基づいてレコードが更新されます。書き込まれる行にすべての列が含まれていない場合、不足している列には NULL が入力されます。
InsertOrUpdate
書き込み時にデータを更新します。送信先テーブルにはプライマリキーがあります。リアルタイム書き込み中にプライマリキーが重複した場合、プライマリキーに基づいてレコードが更新されます。これには完全行更新および部分列更新が含まれます。部分列更新の場合、書き込まれる行にすべての列が含まれていない場合、不足している列は更新されません。
列指向テーブルの場合、異なる書き込みモードのパフォーマンス順位は以下のとおりです。
送信先テーブルにプライマリキーがない場合が最もパフォーマンスが高くなります。
送信先テーブルにプライマリキーがある場合:
InsertOrIgnore > InsertOrReplace >= InsertOrUpdate(完全行)> InsertOrUpdate(部分列)
行指向テーブルの場合、異なる書き込みモードのパフォーマンス順位は以下のとおりです。
InsertOrReplace = InsertOrUpdate(完全行)>= InsertOrUpdate(部分列)>= InsertOrIgnore
バイナリロギング (Binlog) が有効化されたテーブルの場合、書き込みおよび更新パフォーマンスの順位は以下のとおりです。
行指向 > 行列ハイブリッド > 列指向
書き込みボトルネックの特定
テーブルデータの書き込みまたは更新を行う際、書き込みパフォーマンスが遅い場合は、管理コンソールの CPU 使用率 メトリックを確認してパフォーマンスボトルネックを特定できます。
CPU 使用量が低いです。
これは、Hologres のリソースが十分に活用されていないことを示しています。パフォーマンスボトルネックは Hologres 側ではなく、上流のデータ読み取りが遅いなどの問題が発生している可能性があります。
CPU 使用率が高い場合(一貫して 100 %)
これは、Hologres のリソースボトルネックに達していることを示しています。この問題に対処するには、以下の方法があります。
基本的なチューニング手法を適用し、不適切な基本設定がリソース負荷の増加および書き込みパフォーマンスへの影響を及ぼしていないか確認します。詳細については、「基本的なチューニング手法」をご参照ください。
基本的なチューニング手法を適用した後は、Flink や Data Integration などの書き込みチャネル、および Hologres 自体に対して高度なチューニング手法を適用できます。これにより、書き込みボトルネックをさらに特定および解決できます。詳細については、「Flink 書き込みのチューニング」「Data Integration のチューニング」「高度なチューニング手法」をご参照ください。
クエリは書き込みに影響を与える可能性があります。クエリと書き込みを同時に実行すると、CPU 使用率が高くなることがあります。スロークエリログを確認して、同時実行中のクエリの CPU 消費量を特定できます。クエリが書き込みに影響を与えている場合は、インスタンスに対して読み書き分離を実現する高可用性 (HA) デプロイメントを構成することを検討してください。詳細については、「読み書き分離のためのプライマリインスタンスとセカンダリインスタンスのデプロイメント(共有ストレージ)」をご参照ください。
すべてのチューニング手法を試しても書き込みパフォーマンスが期待通りでない場合は、必要に応じて Hologres インスタンスのスケールアウトを実施できます。
基本的なチューニング手法
Hologres は通常、非常に高い書き込みパフォーマンスを提供します。データ書き込み時のパフォーマンスが期待通りでない場合は、以下の手法を用いた日常的なチューニングを実施できます。
ネットワークオーバーヘッドを削減するため、パブリックネットワークの使用を避ける
Hologres では、VPC、クラシックネットワーク、パブリックネットワークなどのネットワークタイプが提供されています。各タイプの利用シーンについては、「ネットワーク構成」をご参照ください。特に Java Database Connectivity (JDBC) や psql を使用してアプリケーションから Hologres に接続する場合、パブリックネットワーク接続ではなく VPC 接続を使用してください。パブリックネットワークにはトラフィック制限があり、VPC よりも安定性が劣ります。
可能な限り Fixed Plan を書き込みに使用する
以下の図は、Hologres における SQL ステートメントの実行フローを示しています。原理の詳細については、「実行エンジン」をご参照ください。
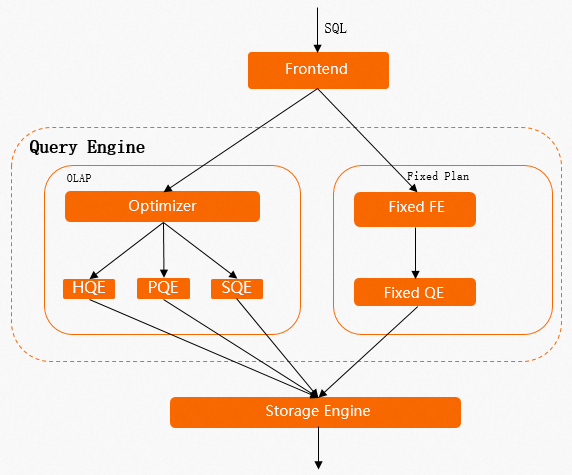
SQL ステートメントが通常のオンライン分析処理 (OLAP) 書き込みである場合、左側のパスに従います。クエリ オプテマイザー (QO) やクエリエンジン (QE) などのコンポーネントを経由します。データの書き込みまたは更新時には、テーブル全体にロックがかけられます。これはテーブルロックです。
INSERT、UPDATE、DELETEコマンドを並行して実行すると、SQL ステートメントが互いのロック解放を待つため、レイテンシが高くなります。SQL ステートメントがポイントクエリまたはポイント書き込みである場合、右側のパス(Fixed Plan)に従います。Fixed Plan を使用するクエリは、QO などのコンポーネントのオーバーヘッドをバイパスできるほどシンプルです。そのため、書き込みまたは更新時に行ロックを使用します。これにより、クエリの同時実行性およびパフォーマンスが大幅に向上します。
したがって、書き込みまたは更新パフォーマンスを最適化する際には、クエリが Fixed Plan を使用するよう優先的に調整してください。
クエリが Fixed Plan を使用するように保証する
SQL ステートメントが Fixed Plan を使用するには、一定の条件を満たす必要があります。Fixed Plan が使用されない代表的なシナリオは以下のとおりです。
マルチ行挿入および更新に
insert on conflict構文を使用する場合。INSERT INTO test_upsert(pk1, pk2, col1, col2) VALUES (1, 2, 5, 6), (2, 3, 7, 8) ON CONFLICT (pk1, pk2) DO UPDATE SET col1 = excluded.col1, col2 = excluded.col2;送信先テーブルの列と挿入データの列が対応していない部分更新に
insert on conflict構文を使用する場合。送信先テーブルに SERIAL 型の列が含まれている場合。
結果テーブルには、
Defaultプロパティが設定されています。updateまたはdelete操作がプライマリキーに基づいている場合。例:update table set col1 = ?, col2 = ? where pk1 = ? and pk2 = ?;Fixed Plan でサポートされていないデータ型を使用している場合。
SQL ステートメントが Fixed Plan を使用しない場合、管理コンソールの監視メトリック「
リアルタイムインポート RPS」には、挿入タイプとしてINSERTと表示されます。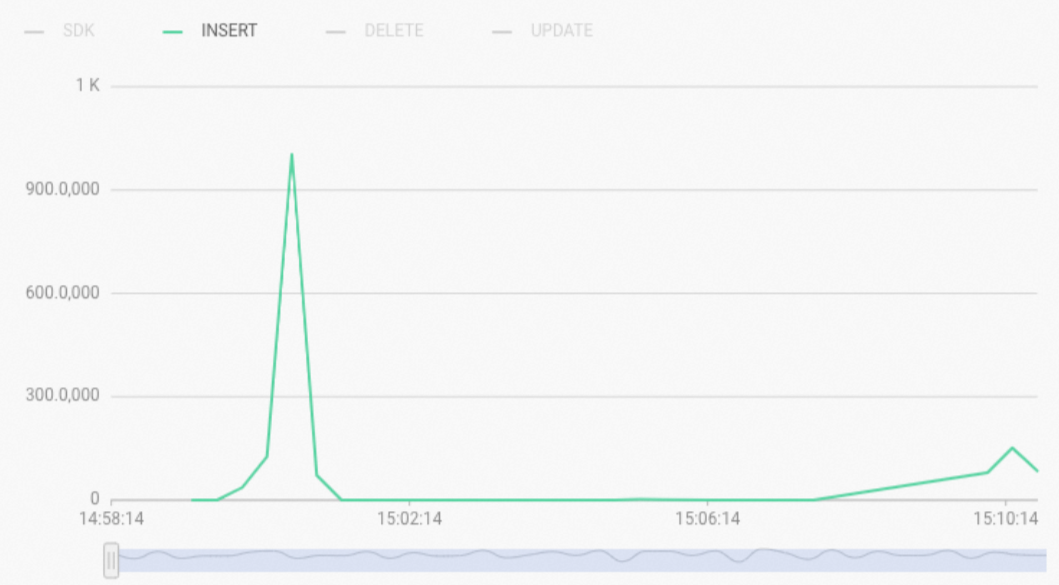 Fixed Plan を使用しない SQL ステートメントでは、実行エンジンタイプは HQE または PQE になります。ほとんどの場合、書き込み操作のエンジンタイプは HQE です。したがって、書き込みまたは更新操作が遅い場合は、以下のサンプルステートメントを実行してスロークエリログを照会し、クエリの実行エンジンタイプ (`engine_type`) を確認できます。
Fixed Plan を使用しない SQL ステートメントでは、実行エンジンタイプは HQE または PQE になります。ほとんどの場合、書き込み操作のエンジンタイプは HQE です。したがって、書き込みまたは更新操作が遅い場合は、以下のサンプルステートメントを実行してスロークエリログを照会し、クエリの実行エンジンタイプ (`engine_type`) を確認できます。-- この例では、過去 3 時間以内に Fixed Plan を使用しなかった挿入、更新、削除操作を照会します。 SELECT * FROM hologres.hg_query_log WHERE query_start >= now() - interval '3 h' AND command_tag IN ('INSERT', 'UPDATE', 'DELETE') AND ARRAY['HQE'] && engine_type ORDER BY query_start DESC LIMIT 500;パフォーマンスを向上させるには、HQE エンジンタイプのクエリを、Fixed Plan の条件を満たす SDK SQL ステートメントに書き直してください。以下の GUC パラメーターに注意してください。これらのパラメーターは、データベースレベルで有効化することを推奨します。「Fixed Plan の使用方法」の詳細については、「Fixed Plan を使用した SQL 実行の高速化」をご参照ください。
シナリオ
GUC 設定
説明
insert on conflict構文を使用した複数レコードの Fixed Plan 書き込みをサポートします。alter database <databasename> set hg_experimental_enable_fixed_dispatcher_for_multi_values =on;データベースレベルでの有効化を推奨します。
SERIAL 型の列を含むテーブルの Fixed Plan 書き込みをサポートします。
alter database <databasename> set hg_experimental_enable_fixed_dispatcher_autofill_series =on;テーブルに SERIAL 型を設定することは、書き込みパフォーマンスの低下を招くため推奨されません。この GUC パラメーターは、Hologres V1.3.25 以降でデフォルトで
onに設定されています。Default プロパティを持つ列の Fixed Plan 書き込みをサポートします。
Hologres V1.3 以降では、
insert on conflict構文を使用して Default プロパティを持つフィールドを含むデータを書き込む場合、書き込み操作はデフォルトで Fixed Plan を使用します。テーブルに Default プロパティを設定することは、書き込みパフォーマンスの低下を招くため推奨されません。Hologres V1.1 では、Default プロパティを持つフィールドに対する Fixed Plan はサポートされていません。この機能は Hologres V1.3 以降でサポートされています。
プライマリキーに基づく UPDATE 操作
alter database <databasename> set hg_experimental_enable_fixed_dispatcher_for_update =on;この GUC パラメーターは、Hologres V1.3.25 以降でデフォルトで
onに設定されています。プライマリキーに基づく DELETE 操作
alter database <databasename> set hg_experimental_enable_fixed_dispatcher_for_delete =on;この GUC パラメーターは、Hologres V1.3.25 以降でデフォルトで
onに設定されています。SQL ステートメントが Fixed Plan を使用する場合、「
リアルタイムインポート RPS」メトリックのタイプはSDKとなり、以下の図に示すとおりです。スロークエリログでは、SQL ステートメントのengine_typeもSDKとなります。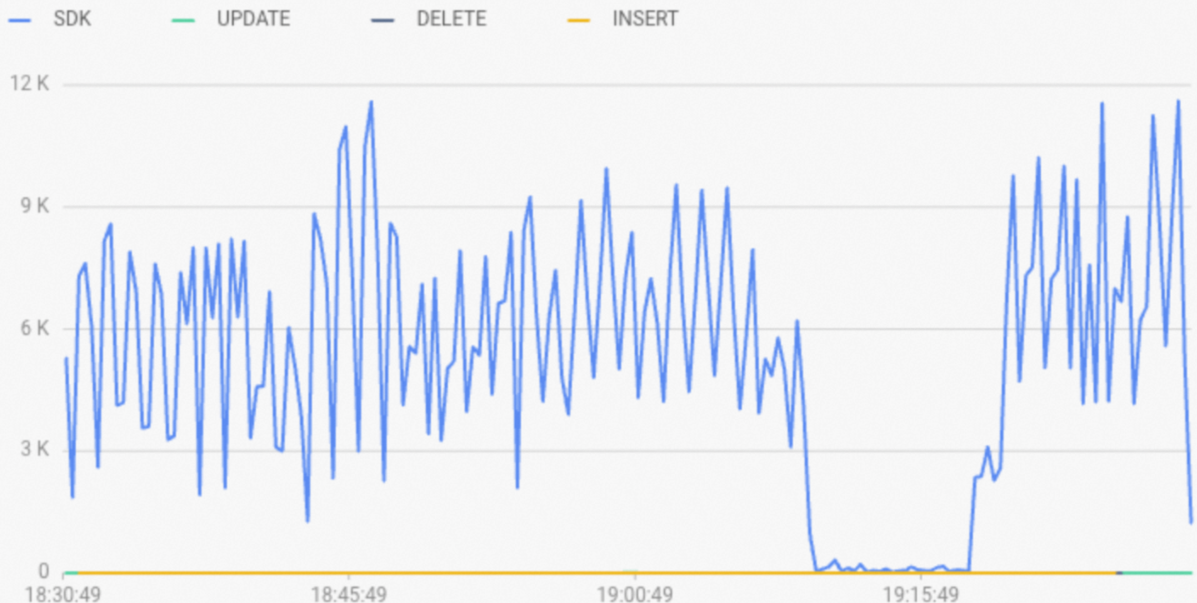
Fixed Plan が実行された後も書き込みパフォーマンスが依然として遅い場合
SQL ステートメントが既に Fixed Plan を使用しているにもかかわらず、実行に長い時間がかかる場合、考えられる原因は以下のとおりです。
通常、これは、テーブルに対して Fixed Plan SDK 書き込みまたは更新と HQE 書き込みまたは更新が混在している場合に発生します。HQE ではテーブルロックが使用されるため、SDK 書き込みがロックの解放を待つことになり、実行時間が長くなります。以下の SQL ステートメントを実行して、テーブルに HQE 操作が存在するかどうかを確認できます。その後、ビジネス要件に応じて、それらを SDK SQL ステートメントに最適化できます。また、HoloWeb の Query Insights を使用して、Fixed Plan クエリが HQE ロックの影響を受けているかどうかを迅速に特定することもできます。「Query Insights」をご参照ください。
-- 過去 3 時間以内に Fixed Plan を使用しなかったテーブルの挿入、更新、削除操作を照会します。 SELECT * FROM hologres.hg_query_log WHERE query_start >= now() - interval '3 h' AND command_tag IN ('INSERT', 'UPDATE', 'DELETE') AND ARRAY['HQE'] && engine_type AND table_write = '<table_name>' ORDER BY query_start DESC LIMIT 500;テーブルへの書き込みがすべて SDK 書き込みであるにもかかわらず依然として遅い場合は、
CPU 使用率メトリックを確認してください。CPU 使用率が一貫して高い場合、インスタンスがリソースボトルネックに達している可能性があります。この場合、必要に応じてインスタンスのスケールアウトを実施できます。
バイナリロギング (Binlog) の有効化は書き込みスループットを低下させます
Hologres Binlog は INSERT、UPDATE、DELETE などのデータ変更を記録します。各行の変更を完全に記録します。テーブルに対して Binlog を有効化する場合、以下の UPDATE ステートメントを例に考えてください。
update tbl set body =new_body where id='1';Binlog は行内のすべてのフィールドのデータを記録するため、フィルター用フィールド(例では
idフィールド)を使用して、送信先テーブルの該当行全体に対するポイントクエリを実行する必要があります。列指向テーブルでは、このようなポイントクエリは行指向テーブルよりも多くのリソースを消費します。したがって、Binlog が有効化されたテーブルでは、書き込みパフォーマンスの順位は以下のとおりです:行指向テーブル > 列指向テーブル同一テーブルへのリアルタイム書き込みとオフライン書き込みを同時に行わない
MaxCompute から Hologres への書き込みなどのオフライン書き込みではテーブルロックが使用されます。Flink や DataWorks データ統合などによるリアルタイム書き込みの多くは、行ロックを使用する Fixed Plan 書き込みです。リアルタイム書き込みとオフライン書き込みを同一テーブルに対して同時に行うと、オフライン書き込みによってテーブルロックが取得され、リアルタイム書き込みはそのロックを待機するため、書き込みパフォーマンスが低下します。したがって、同一テーブルへのリアルタイム書き込みとオフライン書き込みを同時に行わないようにしてください。
Holo Client または JDBC 書き込みのチューニング
Holo Client や JDBC などのクライアントを使用してデータを書き込む場合、以下の手法を用いて書き込みパフォーマンスを向上させることができます。
バッチ単位でデータを書き込む
クライアントを使用してデータを書き込む場合、単一レコードではなくバッチ単位で書き込む方がスループットが高くなり、書き込みパフォーマンスが向上します。
Holo Client は自動的にデータをバッチ処理します。Holo Client のデフォルト構成パラメーターの使用を推奨します。詳細については、「Holo Client」をご参照ください。
JDBC を使用する場合、JDBC 接続文字列に
WriteBatchedInserts=trueを設定することで、バッチ処理を有効化できます(以下に例を示します)。JDBC の詳細については、「JDBC」をご参照ください。jdbc:postgresql://{ENDPOINT}:{PORT}/{DBNAME}?ApplicationName={APPLICATION_NAME}&reWriteBatchedInserts=true
以下に、非バッチ処理の SQL ステートメントをバッチ処理の SQL ステートメントに変換する例を示します。
-- 2 つの非バッチ処理 SQL ステートメント insert into data_t values (1, 2, 3); insert into data_t values (2, 3, 4); -- バッチ処理 SQL ステートメント insert into data_t values (1, 2, 3), (4, 5, 6); -- バッチ処理 SQL ステートメントの別の書き方 insert into data_t select unnest(ARRAY[1, 4]::int[]), unnest(ARRAY[2, 5]::int[]), unnest(ARRAY[3, 6]::int[]);プリペアドステートメントモードを使用してデータを書き込む
Hologres は PostgreSQL エコシステムと互換性があります。PostgreSQL 拡張プロトコルに基づくプリペアドステートメントモードをサポートしており、サーバー側で SQL のコンパイル結果をキャッシュすることで、フロントエンド (FE) や QO などのコンポーネントのオーバーヘッドを削減し、書き込みパフォーマンスを向上させます。
JDBC および Holo Client を使用したプリペアドステートメントモードによるデータ書き込みの詳細については、「JDBC」をご参照ください。
Flink 書き込みのチューニング
異なるテーブルタイプについて以下の点に注意してください。
Binlog ソーステーブル
Flink が Hologres Binlog データを消費する場合、サポートされるデータ型は限定されています。SMAILLINT などの未サポートのデータ型を使用すると、そのフィールドを消費しなくてもジョブがオンライン化できない場合があります。Flink エンジン Ververica Runtime (VVR) 6.0.3-Flink-1.15 以降では、JDBC モードで Hologres Binlog データを消費できます。このモードでは、より多くのデータ型がサポートされます。
Binlog が有効化された Hologres テーブルでは、行指向テーブルの使用を推奨します。列指向テーブルで Binlog を有効化すると、より多くのリソースを消費し、書き込みパフォーマンスに影響を与えます。
ディメンションテーブル
ディメンションテーブルは、行指向または行列ハイブリッドテーブルである必要があります。列指向テーブルは、ポイントクエリシナリオにおいてパフォーマンスオーバーヘッドが高くなります。
行指向テーブルを作成する場合、プライマリキーを設定する必要があります。プライマリキーをクラスタリングキーとしても設定すると、パフォーマンスが向上します。
ディメンションテーブルのプライマリキーは、Flink の `JOIN ON` 句で使用されるフィールドである必要があります。`JOIN ON` 句のフィールドは、テーブルの完全なプライマリキーと一致する必要があります。両者は完全に一致する必要があります。
シンクテーブル
ワイドテーブルマージまたは部分更新の場合、対応する Hologres テーブルにはプライマリキーが必要です。各結果テーブルは、プライマリキーのフィールドを宣言し、書き込む必要があります。書き込みモードとして
InsertOrUpdateを使用する必要があります。各結果テーブルのignoredeleteプロパティは、再traction メッセージによって DELETE 要求が生成されないようにtrueに設定する必要があります。列指向テーブルのワイドテーブルマージシナリオでは、RPS(1 秒あたりのレコード数)が高くなると CPU 使用率が高くなることがあります。この場合、テーブルのフィールドに対して
Dictionary Encodingを無効化することを推奨します。結果テーブルにプライマリキーがある場合、
segment_keyを設定することを推奨します。これにより、書き込みおよび更新時にデータが格納されている基盤ファイルを迅速に特定できます。タイムスタンプまたは日付フィールドをsegment_keyとして使用することを推奨します。このフィールドのデータは、書き込み時間と強い相関関係がある必要があります。
推奨される Flink パラメーター設定
Hologres コネクタのパラメーターのデフォルト値は、ほとんどのシナリオで最適です。以下の問題が発生した場合、必要に応じてパラメーターを変更できます。
Binlog 消費のレイテンシが高い場合:
Binlog データの読み取りバッチサイズ (
binlogBatchReadSize) のデフォルト値は 100 です。単一行のbyte sizeが小さい場合、このパラメーターを増加させて消費レイテンシを最適化できます。ディメンションテーブルのポイントクエリのパフォーマンスが低い場合:
asyncパラメーターをtrueに設定して非同期モードを有効化します。このモードでは、複数のリクエストおよび応答を同時に処理でき、連続するリクエスト間のブロッキングを排除し、クエリスループットを向上させます。ただし、非同期モードではリクエストの絶対的な順序は保証されません。ディメンションテーブルに大量のデータが含まれており、更新頻度が低い場合、ディメンションテーブルキャッシュを使用してクエリパフォーマンスを最適化することを推奨します。対応するパラメーターは
cache = 'LRU'に設定されます。cacheSizeのデフォルト値は控えめな 10,000 行であり、実際の要件に応じてこの値を増加させることを推奨します。
接続数が不足している場合:
connectorはデフォルトで JDBC を使用します。多数の Flink ジョブを実行している場合、Hologres への接続数が不足する可能性があります。この場合、connectionPoolNameパラメーターを使用できます。このパラメーターにより、同じ TaskManager 内で接続プール名が同じテーブルが接続を共有できます。
ジョブ開発に関する推奨事項
DataStream と比較して、Flink SQL は保守性および移植性が高くなります。したがって、ジョブの実装には Flink SQL の使用を推奨します。ビジネス要件により DataStream を使用する必要がある場合は、Hologres DataStream コネクタの使用を推奨します。詳細については、「Hologres DataStream コネクタ」をご参照ください。カスタム DataStream ジョブを開発する場合は、JDBC ではなく Holo Client の使用を推奨します。推奨されるジョブ開発手法の順位は以下のとおりです:
Flink SQL > Flink DataStream(コネクタ)> Flink DataStream(holo-client)> Flink DataStream(JDBC)書き込みが遅い場合のトラブルシューティング
多くの場合、書き込みが遅い原因は、Flink ジョブの他のステップにあります。Flink ジョブのノードを分割してバックプレッシャーを確認できます。データソースまたは複雑な計算ノードでバックプレッシャーが発生している場合、Hologres 結果テーブルへのデータ流入速度が遅くなります。この場合、まず Flink 側での最適化機会を確認する必要があります。
Hologres インスタンスの CPU 使用率が高く(例:一貫して 100 %)、書き込みレイテンシも高い場合、問題は Hologres 側にある可能性があります。
その他の一般的なエラーおよびトラブルシューティング手法については、「Blink および Flink のよくある質問と診断」をご参照ください。
Data Integration のチューニング
同時実行数と接続数の関係
Data Integration では、ウィザードモードのジョブは並行スレッドごとに 3 つの接続を使用します。コードエディタモードのジョブでは、
maxConnectionCountパラメーターを使用してタスクの接続数の合計を設定したり、insertThreadCountパラメーターを使用して並行スレッドごとの接続数を設定したりできます。ほとんどの場合、同時実行数および接続設定を変更しなくても良好なパフォーマンスを得られます。必要に応じて変更できます。排他的リソースグループ
ほとんどの Data Integration ジョブでは、排他的リソースグループが必要です。排他的リソースグループの仕様が、タスクのパフォーマンスの上限を決定します。最適なパフォーマンスを得るには、排他的リソースグループのコア数ごとに 1 つの並行スレッドを推奨します。リソースグループが小さすぎると、タスクの同時実行数が高くなることで JVM メモリ不足などの問題が発生する可能性があります。同様に、排他的リソースグループの帯域幅が飽和すると、書き込みタスクのパフォーマンスの上限も影響を受けます。このような場合は、大規模なタスクを小さなタスクに分割し、異なるリソースグループに割り当てることを推奨します。Data Integration の排他的リソースグループの仕様およびメトリックの詳細については、「パフォーマンスメトリック」をご参照ください。
Data Integration、上流、または Hologres のいずれが書き込みの遅さの原因かを判断する方法
Data Integration が Hologres に書き込む場合、読み取り側の待機時間が書き込み側の待機時間より長い場合、原因は通常、読み取り側が遅いことです。
Hologres インスタンスの CPU 使用率が高く(例:一貫して 100 %)、書き込みレイテンシも高い場合、問題は Hologres 側にある可能性があります。
高度なチューニング手法
基本的なチューニング手法は、書き込みパフォーマンスを向上させるための根本的な手法をカバーしています。正しく適用すれば、優れた書き込みパフォーマンスを実現できます。しかし、実際には、インデックス設定やデータ分散など、他の要因がパフォーマンスに影響を与えることがあります。本セクションで説明する高度なチューニング手法は、基本的な手法を基盤としており、書き込みパフォーマンスをさらにトラブルシューティングおよび向上させる方法を説明します。これらの手法は、Hologres の原理についてより深い理解を持つユーザー向けです。
データスキューによる書き込みの遅さ
データが偏っている場合や分散キーの設定が不適切な場合、Hologres インスタンスの計算リソースが偏り、効率的なリソース利用が妨げられ、書き込みパフォーマンスに影響を与えます。データスキューの確認および関連する問題の解決方法については、「ワーカーのスキュー関係の表示」をご参照ください。
不適切な segment_key による書き込みの遅さ
列指向テーブルに書き込む場合、不適切な segment_key は書き込みパフォーマンスを著しく低下させます。テーブル内のデータ量が増加するにつれて、このパフォーマンス低下はより顕著になります。これは、segment_key が基盤ファイルのセグメント化に使用されるためです。書き込みまたは更新時に、Hologres はプライマリキーに基づいて古いデータを検索します。列指向テーブルでは、この検索操作に segment_key を使用して、データが格納されている基盤ファイルを迅速に特定する必要があります。列指向テーブルに segment_key が設定されていない場合、segment_key が不適切なフィールドに設定されている場合、または segment_key フィールドのデータが書き込み時間と強い相関関係を持たない場合(例:大部分が時系列順でない場合)、検索には非常に多数のファイルをスキャンする必要があります。このプロセスでは、多数の I/O 操作が発生するだけでなく、大量の CPU も消費されます。これにより、書き込みパフォーマンスおよびインスタンス全体の負荷に影響を与えます。この場合、コンソールのモニタリングページの
I/O スループットメトリックには、書き込み作業が主であるにもかかわらず、Read値が高くなることが表示されます。したがって、タイムスタンプまたは日付フィールドを segment_key として使用することを推奨します。このフィールドのデータは、書き込み時間と強い相関関係がある必要があります。
不適切なクラスタリングキーによる書き込みの遅さ
テーブルにプライマリキー (PK) がある場合、Hologres は書き込みまたは更新時にプライマリキーに基づいて古いデータを検索します。
行指向テーブルの場合、クラスタリングキーが PK と異なる場合、検索操作が 2 回実行されます。1 回目は PK インデックスを使用し、2 回目はクラスタリングキーインデックスを使用します。この動作により、書き込みレイテンシが増加します。したがって、行指向テーブルでは、クラスタリングキーと PK を一致させることを推奨します。
列指向テーブルの場合、クラスタリングキーの設定は主にクエリパフォーマンスに影響を与え、書き込みパフォーマンスには影響しません。この設定は、現時点では無視できます。