Hologres ダイナミックテーブルは、1 つ以上のベーステーブルから集約された結果を自動的に処理および格納する宣言型のデータ処理アーキテクチャです。設定可能な組み込みのデータリフレッシュポリシーが含まれており、ベーステーブルからダイナミックテーブルへの自動データ転送を可能にします。ダイナミックテーブルは、統一された開発、自動データ転送、およびタイムリーなデータ処理のニーズに対応します。
背景情報
リアルタイムデータウェアハウスのシナリオでは、複数テーブルの結合や大規模テーブルの集約など、複雑なビジネスロジックが伴うことがよくあります。これらの操作は通常、テラバイトからペタバイトまでの大量のデータを処理し、タイムライン性に関する要件もさまざまです。このようなシナリオでのデータ変換には、一般的に次の課題があります:
過度に冗長な Lambda アーキテクチャ:リソースコスト、開発効率、およびビジネスのタイムライン性のバランスを取るために、Lambda アーキテクチャが広く採用されていました。しかし、このアーキテクチャはさまざまなシナリオで多岐にわたるプロダクトに依存しているため、アーキテクチャとストレージの冗長性、非効率な開発と運用保守 (O&M)、およびデータ定義の不整合につながります。
タイムライン性が低い、反復的なオフライン ETL スケジューリング:Hive などのオフラインコンピューティングエンジンを使用して ETL (抽出・変換・書き出し) を行うことは、一般的なデータ変換方法です。このアプローチは、大量データの高スループット処理には適していますが、リアルタイムコンピューティング機能がありません。データの鮮度を向上させるために、定期的なスケジューリングによってデータが繰り返し再計算されることがよくあります。これにより、大量のリソースが無駄になり、ビジネスのタイムライン性要件を完全に満たすことができません。
リアルタイムコンピューティングの高コスト:データ処理のタイムライン性を向上させるために、リアルタイムコンピューティングエンジンを使用してリアルタイム変換を行うことが新しいトレンドになっています。しかし、データウェアハウス内のすべてのサービスがリアルタイムコンピューティングを必要とするわけではありません。ビジネスインテリジェンス (BI) レポートのクエリなど、多くのシナリオでは、分単位のニアリアルタイム処理で十分です。これらのシナリオでリアルタイムコンピューティングを使用すると、リソースコストが過度に高くなります。
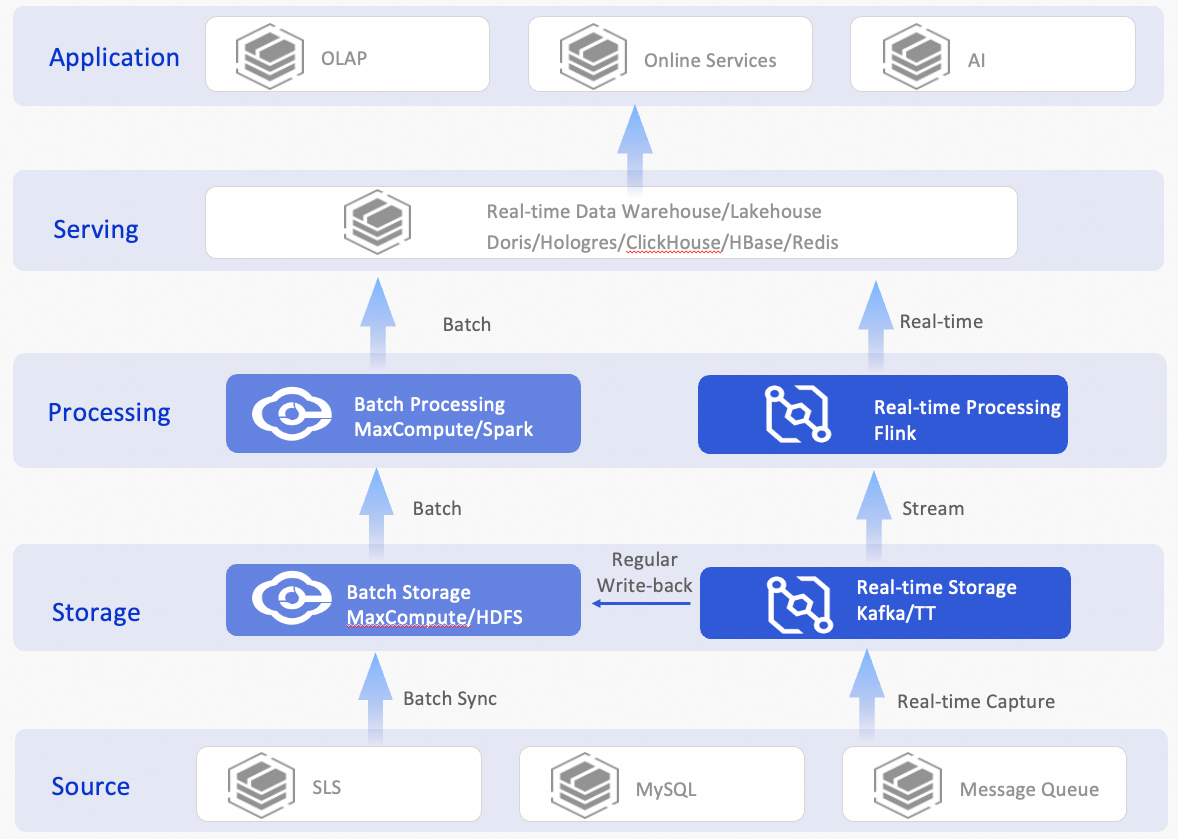
これらのデータ変換の課題に対処するため、Hologres はダイナミックテーブルを導入しました。ダイナミックテーブルは、完全コンピューティングモードと増分コンピューティングモードをサポートしています。これにより、大量データのオフライン完全処理に対応し、増分コンピューティングを使用してリアルタイムコンピューティングよりも低コストでデータのタイムライン性を向上させることができます。ダイナミックテーブルは、データの自動計算と結果の更新を可能にし、より効率的でコスト効率の高い自動データフローとデータウェアハウスの階層化を実現します。Hologres のネイティブ機能と組み合わせることで、ダイナミックテーブルはストレージ、コンピューティング、データ変換、およびデータウェアハウスサービスレイヤーを統合し、開発効率とタイムライン性の要件を満たします。
ダイナミックテーブルの利点
データウェアハウスアーキテクチャの簡素化
ダイナミックテーブルは、完全更新モードと増分更新モードをサポートしています。これにより、オフラインデータ変換 (完全コンピューティング) とニアリアルタイムデータ変換 (増分コンピューティング) の両方が可能になり、さまざまなクエリのタイムライン性要件を満たすことができます。リアルタイムデータとオフラインデータの両方に対応する Hologres の統合ストレージに基づき、ダイナミックテーブルは、オンライン分析処理 (OLAP) クエリ、オンラインサービス、AI および大規模モデルなど、複数のアプリケーションシナリオからのクエリ要件を直接サポートします。単一のエンジン、単一の計算、および複数のコンピューティングモードを持つ単一の SQL 文で Lambda アーキテクチャを置き換えることができます。これにより、データウェアハウスアーキテクチャが簡素化され、開発および運用保守 (O&M) コストが削減されます。
データウェアハウスの自動階層化
ダイナミックテーブルは、ベーステーブルデータの鮮度に基づいて自動的にリフレッシュをトリガーできます。これにより、オペレーションデータストア (ODS) > データウェアハウス詳細 (DWD) > データウェアハウスサービス (DWS) > アプリケーションデータサービス (ADS) の各レイヤーへの自動データ転送が可能になり、データウェアハウスの階層化における開発エクスペリエンスが向上します。
データ処理 (ETL) 効率の向上
ダイナミックテーブルの増分更新では、リフレッシュごとにベーステーブルの新しいデータのみが処理されます。これにより、各 ETL プロセスで計算されるデータ量が効果的に削減され、データ処理効率が大幅に向上します。ストリームコンピューティングのようにリソースを常にアクティブにしておく必要はありません。データの鮮度によってトリガーされる自動リフレッシュにより、コストを効果的に削減できます。
開発および運用保守 (O&M) コストの削減
ダイナミックテーブルのすべてのリフレッシュモードは、統一された SQL インターフェイスを使用します。ダイナミックテーブルは、リフレッシュタスクとデータ間の階層的な依存関係を自動的に管理します。これにより、複雑な開発と運用保守 (O&M) が簡素化され、開発効率が向上します。

用語
ベーステーブル
ベーステーブルは、ダイナミックテーブルのデータソースです。単一の内部テーブルまたは外部テーブル、あるいは複数テーブルの結合が可能です。サポートされるベーステーブルの種類は、リフレッシュモードによって異なります。詳細については、「ダイナミックテーブルでサポートされる機能と制限事項」をご参照ください。
クエリ
ダイナミックテーブルの作成時に指定するクエリは、ETL プロセスと同様に、ベーステーブルのデータを処理するクエリです。サポートされるクエリの種類は、リフレッシュモードによって異なります。詳細については、「ダイナミックテーブルでサポートされる機能と制限事項」をご参照ください。
リフレッシュ
ベーステーブルのデータが変更されると、その変更を反映するためにダイナミックテーブルをリフレッシュする必要があります。ダイナミックテーブルは、設定されたリフレッシュ開始時刻と間隔に基づいて、バックグラウンドでリフレッシュタスクを自動的に実行します。リフレッシュタスクの監視と管理方法の詳細については、「ダイナミックテーブルのリフレッシュタスクの管理」をご参照ください。
仕組み
ベーステーブルのデータは、ダイナミックテーブルのクエリで定義されたデータ処理フローに従って、リフレッシュプロセスを通じてダイナミックテーブルに書き込まれます。このセクションでは、リフレッシュモード、計算リソース、データストレージ、およびテーブルインデックスに焦点を当て、ダイナミックテーブルの背後にある技術的な仕組みについて説明します。
リフレッシュモード
ダイナミックテーブルは現在、完全更新と増分更新の 2 つのリフレッシュモードをサポートしています。基盤となる技術的な仕組みは、設定されたリフレッシュモードによって異なります。
完全更新
完全更新は、実行のたびにすべてのデータを処理します。ベーステーブルの集約結果をマテリアライズし、ダイナミックテーブルに書き込みます。その技術的な仕組みは、`INSERT OVERWRITE` 操作の仕組みに似ています。
増分更新
増分更新モードでは、各リフレッシュでベーステーブルの新しいデータのみが読み取られます。中間集約状態と増分データに基づいて最終結果を計算し、ダイナミックテーブルを更新します。完全更新と比較して、増分更新は実行ごとに処理するデータ量が少ないため、効率が高くなります。これにより、リフレッシュタスクのタイムライン性が大幅に向上し、計算リソースの使用量も削減されます。
技術的な仕組み
増分更新でダイナミックテーブルを作成すると、システムは Stream メソッドまたは Binlog メソッドを使用してベーステーブルから増分データを読み取ります。次に、バックグラウンドで列指向の状態テーブルを作成します。この状態テーブルには、クエリの中間集約状態が格納されます。DPI エンジンは、この中間状態のエンコーディングとストレージを最適化し、その読み取りと更新を高速化します。増分データはメモリ内でマイクロバッチで集約され、状態テーブルのデータとマージされます。最新の集約結果は、BulkLoad メソッドを使用して効率的にダイナミックテーブルに書き込まれます。このマイクロバッチ増分処理により、1 回のリフレッシュで処理されるデータ量が削減され、計算のタイムライン性が大幅に向上します。
増分データを読み取るための Stream メソッドと Binlog メソッドの比較
増分データを読み取るメソッド
仕組み
読み取りパフォーマンス
特徴
注
Stream (推奨)
ファイルレベルでデータの変更を検出し、ベーステーブルの増分データを計算します。
Binlog メソッドの 10 倍以上高いです。
より簡単に使用できます。
増分変更を個別に記録しません。つまり、追加のストレージオーバーヘッドがなく、バイナリログのストレージライフサイクルを管理する必要もありません。
行指向テーブルをベーステーブルとして使用することはサポートされていません。
Binlog
バイナリロギングは、データ操作言語 (DML) によるベーステーブルへの変更を記録し、バックグラウンドでバイナリログとして保存します。ベーステーブルから増分データを消費する際、システムはバイナリログを読み取ってデータの変更を検出します。
より低いです。
DML の変更を記録するため、追加のストレージオーバーヘッドが発生します。
バイナリログのストレージライフサイクル (TTL) の管理が必要です。そうしないと、データの変更や増加に伴い、ストレージ使用量が増え続けます。
なし。
注
増分更新モードでサポートされるベーステーブルには特定の制限があります。詳細については、「ダイナミックテーブルでサポートされる機能と制限事項」をご参照ください。
増分更新用の組み込み状態テーブルは、一部のストレージ領域を占有します。システムは TTL を設定して定期的にデータをクリーンアップします。関数を使用して状態テーブルのストレージサイズを表示できます。詳細については、「状態テーブルの管理」をご参照ください。
計算リソース
リフレッシュタスクを実行するための計算リソースは、現在のインスタンスまたは Serverless リソースから提供されます:
Serverless リソース (デフォルト):Hologres V3.1 以降では、新しいダイナミックテーブルはデフォルトで Serverless リソースを使用してリフレッシュを実行します。クエリが複雑で大量のデータを処理する場合、Serverless リソースを使用すると、リフレッシュタスクの安定性が向上し、インスタンス内の複数のタスク間のリソース競合を回避できます。また、単一のリフレッシュタスクの計算リソースを変更して、Serverless リソースの使用を最適化することもできます。
現在のインスタンスリソース:リフレッシュタスクは現在のインスタンスのリソースを使用し、インスタンス内の他のタスクと共有します。これにより、ピーク時にリソース競合が発生する可能性があります。
データストレージ
ダイナミックテーブルのデータストレージは標準テーブルと同じで、デフォルトではホットストレージモードを使用します。ストレージコストを削減するために、クエリ頻度の低いデータをコールドストレージに移動できます。
テーブルインデックス
クエリを実行する際、ダイナミックテーブルを直接クエリできます。これは集約結果を直接クエリすることに相当し、クエリパフォーマンスを大幅に向上させることができます。標準テーブルと同様に、ダイナミックテーブルもローストアや列ストア、Distribution Key、Clustering Key などのテーブルインデックスの設定をサポートしています。通常、DPI エンジンは、ダイナミックテーブルのクエリに基づいて適切なインデックスを推測します。さらなる最適化が必要な場合は、新しいインデックスを設定してクエリパフォーマンスをさらに向上させることができます。
マテリアライズドビューとの比較
ダイナミックテーブルと Hologres リアルタイムマテリアライズドビューの比較
Hologres は V1.3 でSQL 管理のマテリアライズドビューを導入しましたが、その機能は比較的限定的です。SQL 管理のマテリアライズドビューとダイナミックテーブルの違いは次のとおりです:
機能カテゴリ | Hologres ダイナミックテーブル | Hologres リアルタイムマテリアライズドビュー |
ベーステーブルの種類 |
| 単一の内部テーブル |
ベーステーブルの操作 |
| 追記のみの書き込み |
リフレッシュの仕組み | 非同期リフレッシュ (完全更新、増分更新) | 同期 |
更新の適時性 |
| リアルタイム |
クエリの種類 |
説明 サポートされるクエリの種類は、リフレッシュモードによって異なります。詳細については、「ダイナミックテーブルでサポートされる機能と制限事項」をご参照ください。 | 限定的なオペレーターサポート (AGG、RB 関数など) |
要求モード | ダイナミックテーブルを直接クエリ |
|
ダイナミックテーブルと非同期マテリアライズドビューの比較
市場の他のプロダクトも、OLAP プロダクトの非同期マテリアライズドビューや Snowflake のダイナミックテーブルなど、ダイナミックテーブルに類似した機能を提供しています。違いは次のとおりです:
機能カテゴリ | Hologres ダイナミックテーブル | OLAP プロダクトの非同期マテリアライズドビュー | Snowflake ダイナミックテーブル |
ベーステーブルの種類 |
説明 サポートされるクエリの種類は、リフレッシュモードによって異なります。詳細については、「ダイナミックテーブルでサポートされる機能と制限事項」をご参照ください。 |
|
|
リフレッシュモード |
|
|
|
更新の適時性 |
| 時間単位 |
|
クエリの種類 |
説明 サポートされるクエリの種類は、リフレッシュモードによって異なります。詳細については、「ダイナミックテーブルでサポートされる機能と制限事項」をご参照ください。 |
|
|
要求モード | ダイナミックテーブルを直接クエリ |
| ダイナミックテーブルを直接クエリ |
監視/運用保守 (O&M) |
| 豊富な監視メトリック | 可視化インターフェイス |
利用シーン
ダイナミックテーブルは、データ変換とストレージを自動的に完了させます。ダイナミックテーブルを使用して、データクエリを高速化し、ビジネスのタイムライン性を向上させることができます。推奨される利用シーンは次のとおりです:
Lambda アーキテクチャのアップグレード
ビジネスデータ処理のさまざまなタイムライン性要件を満たすために、Lambda アーキテクチャはさまざまなプロダクトコンポーネントを使用します。これにより、アーキテクチャの冗長性、データ定義の不整合、システムメンテナンスの困難さ、およびストレージの冗長性が発生します。Hologres ダイナミックテーブルは、バッチデータ変換とニアリアルタイム処理をサポートしています。OLAP クエリとキーバリュー (KV) ポイントクエリをサポートする Hologres の統合ストレージと統合データサービスと組み合わせることで、単一のプロダクト内で複数のアプリケーションシナリオをサポートできます。これにより、アーキテクチャが簡素化され、開発の複雑さ、学習曲線、およびストレージコストが削減されます。
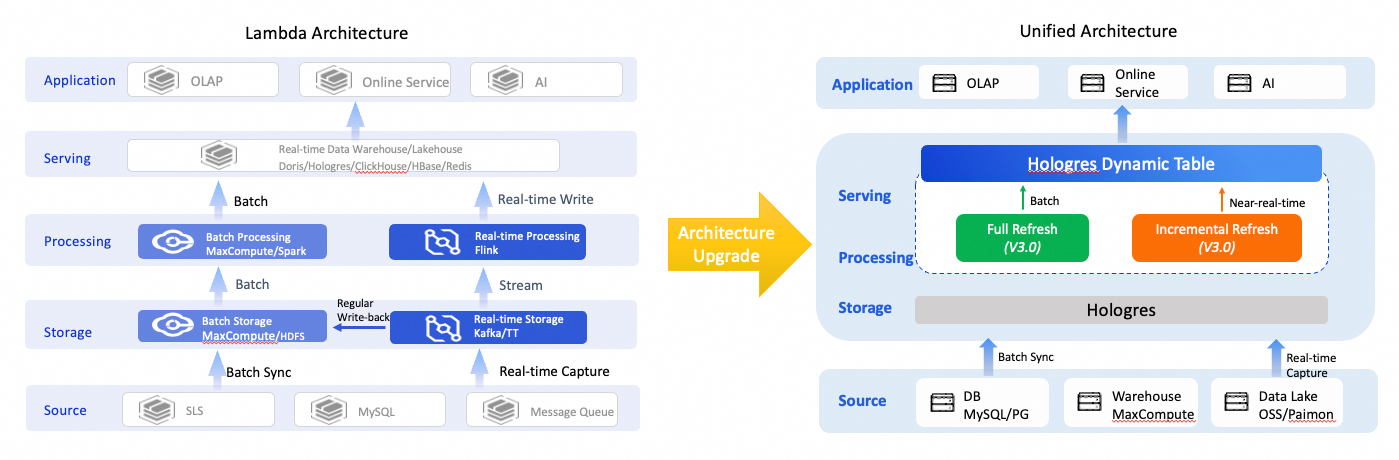
ニアリアルタイムのデータ処理
ベーステーブルに大量のデータが含まれ、ビジネスのタイムライン性要件を満たすために複雑な ETL 処理が必要な場合、一般的な方法はデータウェアハウスの階層化です。リアルタイムデータウェアハウスの場合、マテリアライズドビューの使用や定期的なスケジューリングなど、階層化のための多くのソリューションが存在します。これらのソリューションはいくつかの問題を解決できますが、データのタイムライン性や開発の複雑さに関する問題も引き起こします。Hologres ダイナミックテーブルには、自動データ処理機能が組み込まれており、データウェアハウスの階層化を簡単に実装できます。
推奨される方法は次のとおりです:
ダイナミックテーブルを使用して、Hologres に DWD > DWS > ADS レイヤーを構築します:
各レイヤー間のデータ同期には増分更新モードを使用します。これにより、各レイヤーで処理されるデータが少なくなり、不要な繰り返し計算が削減され、同期速度が向上します。また、リフレッシュタスクを Serverless コンピューティングに送信して、リフレッシュのタイムライン性と安定性を向上させることもできます。
各レイヤーのデータをリフレッシュするには、1 回限りの完全更新を実行して、レイヤー間のデータ整合性を確保できます。また、リフレッシュタスクを Serverless コンピューティングに送信して、タイムライン性と安定性を向上させることもできます。
各レイヤーは Hologres に構築され、データウェアハウスの階層化が明確になります。各レイヤーは必要に応じてクエリでき、データの可視性と再利用性が確保されます。
Hologres ダイナミックテーブルソリューションは、データ変換とアプリケーションシナリオの両方を処理でき、データウェアハウスの開発および運用保守 (O&M) 効率を大幅に向上させます。

レイクハウスの高速化
ダイナミックテーブルのベーステーブルデータは、Hologres テーブル、MaxCompute などのデータウェアハウス、または OSS や Paimon などのデータレイクから取得できます。ベーステーブルデータに対して完全更新または増分更新を実行することで、タイムライン性要件が異なるさまざまなデータクエリおよび探索のニーズを満たすことができます。推奨される利用シーンは次のとおりです:
定期レポートのクエリ
定期レポートなどの定期的な観測シナリオでは、データ量が少ないか、クエリが複雑でない場合は、完全更新または増分更新モードを使用できます。レイクハウスデータの集約および分析結果を定期的にダイナミックテーブルにリフレッシュします。その後、アプリケーション側はダイナミックテーブルを直接クエリして分析結果を取得し、レポートクエリを高速化できます。
リアルタイムダッシュボード/レポート
リアルタイムダッシュボードやレポートなどのシナリオでは、データのタイムライン性要件が高くなります。増分更新モードを使用することをお勧めします。Paimon またはリアルタイムデータからの集約および分析結果をダイナミックテーブルにリフレッシュします。これにより、リアルタイムデータの処理が高速化されます。アプリケーション側はダイナミックテーブルを直接クエリしてデータ分析結果を取得し、ニアリアルタイム分析を実現できます。

オフラインの定期的かつ反復的なスケジューリングの置き換え
一般的なオフライン処理シナリオでは、データ量が多く、計算サイクルが長くなります。計算のタイムライン性を向上させるための一般的なアプローチは、定期的なスケジューリングソリューションです:
DWD から DWS、ADS へと、過去数日間のデータが T+H ベースで処理されます。たとえば、30 分ごとにスケジューリングされます。データの正確性を確保するために、別のオフラインパイプラインも T+1 ベースで実行され、過去数日間のデータを処理します。これはデータのリフレッシュに相当し、大量の冗長な計算、リソースの無駄、およびデータの冗長性につながります。さらに、システムは各スケジュールされたタスクが完了することを保証できないため、後続のタスクがブロックされ、ビジネスの計算が遅延し、タイムライン性の保証を満たせなくなる可能性があります。
Hologres を使用すると、DWD から DWS、ADS までの各レイヤーで T+H 増分更新を使用できます。元のジョブは単一の増分コンピューティングジョブにマージできます。特定のデータクエリ範囲を気にする必要はなく、リフレッシュを管理するだけで済みます。SQL はよりシンプルになり、ダイナミックテーブルがスケジューリングを自動的に処理するため、外部のスケジューリングジョブを維持する必要がなくなります。毎回増分データのみが計算されます。これにより、冗長な計算が回避され、計算が高速化され、タスクのバックログが防止され、計算リソースの使用量が大幅に削減されます。
