MaxCompute のデータが 200 GB を超え、秒単位の応答時間が求められる複雑なクエリがある場合は、データを Hologres の内部テーブルに直接インポートします。内部テーブルにはインデックスを作成できるため、この方法は外部テーブルを介してデータをクエリするよりも効率的です。このトピックでは、さまざまなシナリオでデータをインポートする方法について説明し、よくある質問への回答を提供します。
注意事項
SQL を使用して MaxCompute のデータを Hologres にインポートする場合、次の点にご注意ください。
-
MaxCompute のパーティションと Hologres のパーティションの間には、強いマッピング関係はありません。MaxCompute のパーティションフィールドは、Hologres の通常のフィールドにマッピングされます。そのため、パーティション化された MaxCompute テーブルから、Hologres の非パーティションテーブルまたはパーティションテーブルのいずれかにデータをインポートできます。
-
Hologres は単一層のパーティション分割のみをサポートしています。多階層パーティション分割された MaxCompute テーブルからパーティション化された Hologres テーブルにデータをインポートする場合、1 つのパーティションフィールドのみをマッピングします。他のパーティションフィールドは、Hologres の通常のフィールドにマッピングされます。
-
インポート中に既存のデータを更新または上書きするには、INSERT ON CONFLICT (UPSERT) 構文を使用します。
-
MaxCompute と Hologres のデータ型のマッピングについては、「データ型の概要」をご参照ください。
-
MaxCompute テーブルのデータが更新された後、Hologres にはキャッシュの遅延があり、通常は 10 分以内です。データをインポートする前に、IMPORT FOREIGN SCHEMA コマンドを実行して外部テーブルを更新し、最新のデータを取得してください。
-
MaxCompute のデータを Hologres にインポートする場合、Data Integration ではなく SQL を使用してください。SQL でのインポートの方がパフォーマンスが優れています。
非パーティション MaxCompute テーブルから Hologres へのデータインポートとクエリ
-
非パーティション MaxCompute テーブルでのデータの準備
MaxCompute で非パーティションのソースデータテーブルを作成するか、既存のテーブルを使用します。
この例では、MaxCompute の public_data パブリックデータセットの customer テーブルを使用します。データセットへのログイン方法とクエリ方法の詳細については、「パブリックデータセットの使用」をご参照ください。テーブルの DDL 文とそのデータは次のとおりです。
-- MaxCompute パブリックデータセット内のテーブルの DDL CREATE TABLE IF NOT EXISTS public_data.customer( c_customer_sk BIGINT, c_customer_id STRING, c_current_cdemo_sk BIGINT, c_current_hdemo_sk BIGINT, c_current_addr_sk BIGINT, c_first_shipto_date_sk BIGINT, c_first_sales_date_sk BIGINT, c_salutation STRING, c_first_name STRING, c_last_name STRING, c_preferred_cust_flag STRING, c_birth_day BIGINT, c_birth_month BIGINT, c_birth_year BIGINT, c_birth_country STRING, c_login STRING, c_email_address STRING, c_last_review_date STRING, useless STRING); -- MaxCompute でテーブルをクエリしてデータを確認 SELECT * FROM public_data.customer;次の図にデータの一部を示します。

-
Hologres での外部テーブルの作成
Hologres で外部テーブルを作成し、MaxCompute のソースデータテーブルをマッピングします。次のサンプル SQL 文を使用します。
CREATE FOREIGN TABLE foreign_customer ( "c_customer_sk" int8, "c_customer_id" text, "c_current_cdemo_sk" int8, "c_current_hdemo_sk" int8, "c_current_addr_sk" int8, "c_first_shipto_date_sk" int8, "c_first_sales_date_sk" int8, "c_salutation" text, "c_first_name" text, "c_last_name" text, "c_preferred_cust_flag" text, "c_birth_day" int8, "c_birth_month" int8, "c_birth_year" int8, "c_birth_country" text, "c_login" text, "c_email_address" text, "c_last_review_date" text, "useless" text ) SERVER odps_server OPTIONS (project_name 'public_data', table_name 'customer');パラメーター
説明
Server
Hologres の基盤レイヤーに既に作成されている odps_server という名前の外部テーブルサーバーを直接呼び出すことができます。原理の詳細については、「Postgres FDW」をご参照ください。
Project_Name
MaxCompute テーブルが存在するプロジェクトの名前です。
Table_Name
クエリ対象の MaxCompute テーブルの名前です。
外部テーブルのフィールドのデータ型は、MaxCompute テーブルのフィールドのデータ型と一致している必要があります。データ型のマッピングの詳細については、「MaxCompute と Hologres 間のデータ型マッピング」をご参照ください。
-
Hologres でのストレージテーブルの作成
Hologres でストレージテーブルを作成し、MaxCompute のソーステーブルからデータを受け取ります。
これは基本的な DDL の例です。データをインポートする際は、より良いクエリパフォーマンスを実現するために、必要に応じてスキーマと適切なインデックスを持つテーブルを作成してください。テーブルのプロパティの詳細については、「CREATE TABLE」をご参照ください。
-- サンプルの列指向テーブルを作成 BEGIN; CREATE TABLE public.holo_customer ( "c_customer_sk" int8, "c_customer_id" text, "c_current_cdemo_sk" int8, "c_current_hdemo_sk" int8, "c_current_addr_sk" int8, "c_first_shipto_date_sk" int8, "c_first_sales_date_sk" int8, "c_salutation" text, "c_first_name" text, "c_last_name" text, "c_preferred_cust_flag" text, "c_birth_day" int8, "c_birth_month" int8, "c_birth_year" int8, "c_birth_country" text, "c_login" text, "c_email_address" text, "c_last_review_date" text, "useless" text ); CALL SET_TABLE_PROPERTY('public.holo_customer', 'orientation', 'column'); CALL SET_TABLE_PROPERTY('public.holo_customer', 'bitmap_columns', 'c_customer_id,c_salutation,c_first_name,c_last_name,c_preferred_cust_flag,c_birth_country,c_login,c_email_address,c_last_review_date,useless'); CALL SET_TABLE_PROPERTY('public.holo_customer', 'dictionary_encoding_columns', 'c_customer_id:auto,c_salutation:auto,c_first_name:auto,c_last_name:auto,c_preferred_cust_flag:auto,c_birth_country:auto,c_login:auto,c_email_address:auto,c_last_review_date:auto,useless:auto'); CALL SET_TABLE_PROPERTY('public.holo_customer', 'time_to_live_in_seconds', '3153600000'); CALL SET_TABLE_PROPERTY('public.holo_customer', 'storage_format', 'segment'); COMMIT; -
Hologres へのデータのインポート
説明Hologres V2.1.17 以降では、Serverless Computing がサポートされています。大規模なオフラインデータインポート、大規模な抽出・変換・書き出し (ETL) ジョブ、外部テーブルに対する大量のクエリなどのシナリオでは、Serverless Computing を使用してこれらのタスクを実行できます。この機能は、ご利用のインスタンス自身のリソースではなく、追加のサーバーレスリソースを使用します。インスタンスに追加の計算リソースを予約する必要はありません。これにより、インスタンスの安定性が大幅に向上し、Out-of-Memory (OOM) エラーの可能性が減少し、個々のタスクに対してのみ課金されます。Serverless Computing の詳細については、「Serverless Computing」をご参照ください。Serverless Computing の使用方法については、「Serverless Computing の使用ガイド」をご参照ください。
INSERT文を使用して、MaxCompute のソーステーブルから Hologres にデータをインポートします。一部またはすべてのフィールドからデータをインポートできます。一部のフィールドからデータをインポートする場合、フィールドは正しい順序でなければなりません。次のサンプル DDL 文を使用します。-- (オプション) Serverless Computing を使用して、大量のデータのオフラインインポートと ETL ジョブを実行します。 SET hg_computing_resource = 'serverless'; -- 一部のフィールドからデータをインポート INSERT INTO holo_customer (c_customer_sk,c_customer_id,c_email_address,c_last_review_date,useless) SELECT c_customer_sk, c_customer_id, c_email_address, c_last_review_date, useless FROM foreign_customer; -- すべてのフィールドからデータをインポート INSERT INTO holo_customer SELECT * FROM foreign_customer; -- 不要な SQL 文がサーバーレスリソースを使用しないように構成をリセットします。 RESET hg_computing_resource; -
Hologres での MaxCompute テーブルデータのクエリ
Hologres でインポートされた MaxCompute テーブルデータをクエリします。次のサンプル SQL 文を使用します。
SELECT * FROM holo_customer;
パーティション MaxCompute テーブルから Hologres へのデータインポートとクエリ
詳細については、「パーティション MaxCompute テーブルからのデータインポート」をご参照ください。
INSERT OVERWRITE のベストプラクティス
詳細については、「INSERT OVERWRITE」をご参照ください。
可視化ツールまたは定期的なスケジューリングによるデータ同期
一度に大量のデータを同期するには、可視化ツールまたはスケジューリングタスクを使用できます。
-
HoloWeb 可視化ツールを使用して MaxCompute データをワンクリックで同期するには、次の手順に従います。
-
HoloWeb ページに移動します。詳細については、「HoloWeb への接続とクエリの実行」をご参照ください。
-
HoloWeb 開発者ページの上部メニューバーで、 を選択し、Import MaxCompute Data をクリックします。
-
Create MaxCompute Data Import Task ページでパラメーターを設定します。
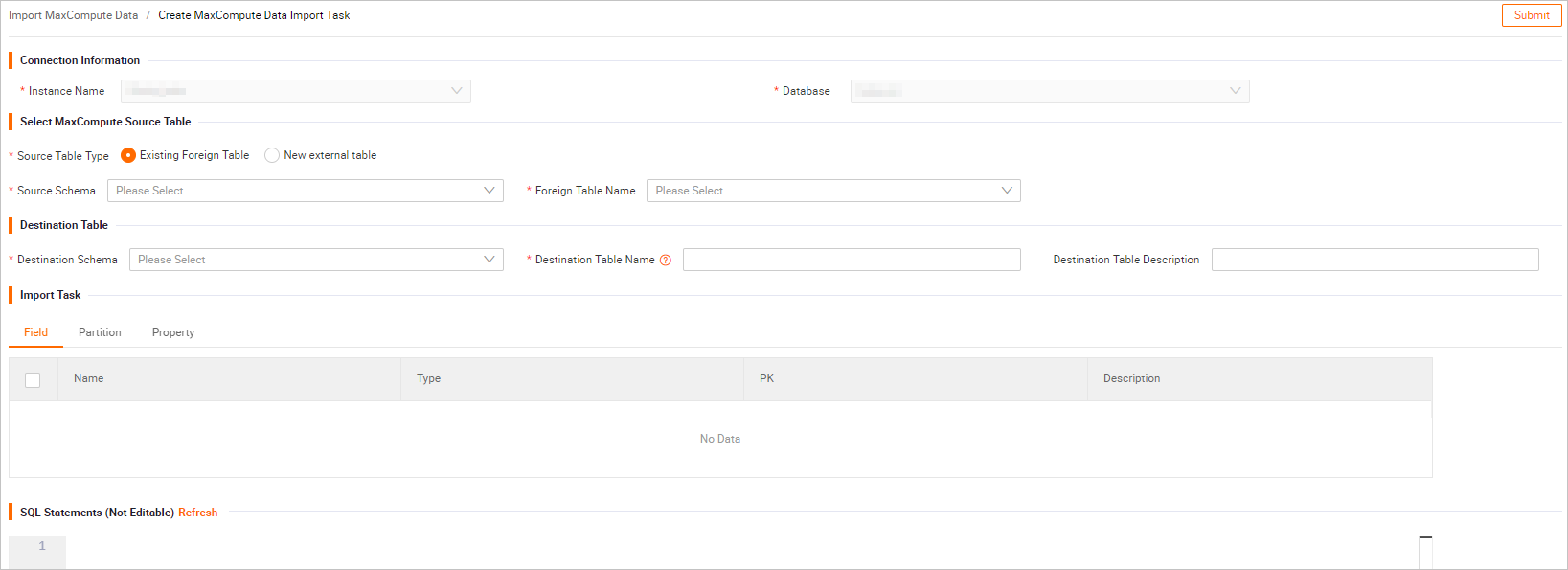 次の表にパラメーターを説明します。説明
次の表にパラメーターを説明します。説明[SQL スクリプト] は、現在の可視化操作に対応する SQL 文を自動的に解析します。[SQL スクリプト] 内の SQL 文は変更できません。文を変更するには、コピーして手動で変更し、SQL を使用してデータを同期します。
セクション
パラメーター
説明
インスタンス
インスタンス名
ログインしているインスタンスの名前です。
ソース MaxCompute テーブル
プロジェクト名
MaxCompute プロジェクトの名前です。
スキーマ名
MaxCompute のスキーマ名です。このパラメーターは、2 層モデルを使用する MaxCompute プロジェクトでは非表示になります。3 層モデルを使用するプロジェクトでは、権限を持つスキーマをドロップダウンリストから選択できます。
テーブル名
MaxCompute テーブルの名前です。プレフィックスによるあいまい検索がサポートされています。
宛先 Hologres テーブル
データベース名
内部テーブルが配置されている Hologres データベースの名前を選択します。
スキーマ名
Hologres のスキーマ名です。
デフォルト値は public です。権限を持つ別のスキーマを選択することもできます。
テーブル名
新しい Hologres 内部テーブルの名前です。
MaxCompute テーブルを選択すると、MaxCompute テーブルの名前が自動的に使用されます。テーブルの名前を変更することもできます。
宛先テーブルの説明
新しい Hologres 内部テーブルの説明です。説明はカスタマイズできます。
パラメーター設定
GUC パラメーター
設定したい Grand Unified Configuration (GUC) パラメーターを入力します。GUC パラメーターの詳細については、「GUC パラメーター」をご参照ください。
インポートタスク
フィールド
MaxCompute テーブルからインポートするフィールドです。
一部またはすべてのフィールドをインポートできます。
パーティション設定
パーティションフィールド
パーティションフィールドを選択します。Hologres はデフォルトでパーティションテーブルを作成します。
Hologres は単一層のパーティション分割のみをサポートしています。MaxCompute から多階層パーティションをインポートするには、Hologres で第一階層のパーティションのみを設定します。他のパーティションフィールドは、自動的に Hologres の通常のフィールドにマッピングされます。
データタイムスタンプ
MaxCompute テーブルが日付でパーティション分割されている場合、特定のパーティション日付を選択できます。システムは指定された日付のデータを Hologres テーブルにインポートします。
プロパティ
ストレージモード
列指向ストレージ:さまざまな複雑なクエリに適しています。
行指向ストレージ:プライマリキーに基づくポイントクエリとスキャンに適しています。
行列表ストレージ:ローストアと列のストアのすべてのシナリオをサポートし、プライマリキーに基づかないポイントクエリもサポートします。
ストレージモードを指定しない場合、デフォルトで 列指向ストレージ が使用されます。
データライフサイクル
テーブルデータのライフサイクルです。デフォルトでは、データは永続的に保存されます。
ライフサイクルを指定した場合、DPI エンジンは、指定された期間内にデータが変更されなければ、その期間が過ぎたある時点でデータを削除します。
Binlog
バイナリロギングを有効にするかどうかを指定します。詳細については、「Hologres Binlog のサブスクライブ」をご参照ください。
バイナリログのライフサイクル
バイナリログの生存時間 (TTL) です。デフォルト値は 30 日で、2,592,000 秒です。
分布列
Hologres は分布列に基づいてデータをシャードにシャッフルします。分布列に同じ値を持つ行は、同じシャードに保存されます。分布列をフィルター条件として使用すると、クエリのパフォーマンスが向上します。
列をセグメントキーとして指定できます。クエリ条件にセグメント列が含まれている場合、Hologres はセグメントキーを使用してデータの保存場所を迅速に見つけます。
クラスタリングキー
列をクラスタリングキーとして指定できます。インデックスのタイプは列の順序と密接に関連しています。クラスタリングインデックスは、インデックス列に対する範囲クエリとフィルタークエリを高速化します。
ディクショナリエンコーディング列
Hologres は、指定された列の値に対してディクショナリマッピングを作成することをサポートしています。ディクショナリエンコーディングは、文字列比較を数値比較に変換して、Group By クエリと Filter クエリを高速化します。
Hologres は、指定された列の値に対してディクショナリマッピングを構築します。ディクショナリエンコーディングは、文字列比較を数値比較に変換します。これにより、GROUP BY クエリとフィルタークエリが高速化されます。デフォルトでは、すべての text 列がディクショナリエンコーディング列として設定されます。
ビットマップ列
Hologres は、ビットマップ列でのビットエンコーディングをサポートしています。これにより、指定された条件に基づいてフィールド内のデータを迅速にフィルタリングできます。
Hologres は、指定された列にビットマップインデックスを構築します。ビットマップインデックスは、指定された条件に基づいてデータを迅速にフィルタリングします。デフォルトでは、すべての text 列がビットマップ列として設定されます。
-
Submit をクリックします。データがインポートされた後、Hologres で内部テーブルのデータをクエリできます。
-
-
HoloWeb でのワンクリック同期は、定期的なスケジューリングをサポートしていません。大量の既存データを同期したり、定期的にデータインポートをスケジュールしたりするには、DataWorks の DataStudio を使用します。詳細については、「DataWorks を使用した MaxCompute データの定期的なインポートのベストプラクティス」をご参照ください。
よくある質問
MaxCompute から Hologres にデータをインポートする際に Out-of-Memory (OOM) エラーが発生し、メモリ制限を超えたことを示す例外が報告されます。通常、Query executor exceeded total memory limitation xxxxx: yyyy bytes used エラーが報告されます。以下に、このエラーの考えられる 4 つの原因とその解決策を説明します。
-
トラブルシューティング手順 1
-
考えられる原因:
インポートクエリにサブクエリが含まれていますが、一部のテーブルで
analyzeコマンドが実行されていません。あるいは、analyzeコマンドは実行されたものの、データが更新されたため統計が不正確になっています。これにより、クエリオプティマイザーが結合順序について誤った判断を下し、高いメモリオーバーヘッドを引き起こします。 -
ソリューション:
関連するすべての内部テーブルと外部テーブルで
analyzeコマンドを実行して、それらの統計メタデータを更新します。これにより、クエリオプティマイザーがより良い実行計画を生成し、OOM エラーを解決するのに役立ちます。
-
-
手順 2
-
考えられる原因:
テーブルの列数が多く、1 行あたりのデータ量が大きいため、一度に読み取るデータ量が増加し、高いメモリオーバーヘッドにつながります。
-
ソリューション:
SQL 文の前に次のパラメーターを追加して、一度に読み取るデータ行数を制御します。これにより、OOM エラーの発生を効果的に減らすことができます。
SET hg_experimental_query_batch_size = 1024;-- デフォルト値は 8192 です。 INSERT INTO holo_table SELECT * FROM mc_table;
-
-
手順 3:トラブルシューティング
-
考えられる原因:
データインポート中の同時実行性が高く、CPU 消費量が大きいため、内部テーブルのクエリに影響を与えます。
-
ソリューション:
Hologres V1.1 より前のバージョンでは、hg_experimental_foreign_table_executor_max_dop パラメーターを使用して同時実行性を制御できます。デフォルト値はインスタンスのコア数です。インポート中に、hg_experimental_foreign_table_executor_max_dop をより小さい値に設定して、インポートのメモリ使用量を減らし、OOM エラーを解決できます。このパラメーターは、外部テーブルで実行されるすべてのジョブに有効です。次のサンプルコードを使用します。
SET hg_experimental_foreign_table_executor_max_dop = 8; INSERT INTO holo_table SELECT * FROM mc_table;
-
-
手順 4:トラブルシューティング
-
考えられる原因:
データインポート中の同時実行性が高く、CPU 消費量が大きいため、内部テーブルのクエリに影響を与えます。
-
ソリューション:
Hologres V1.1 以降では、hg_foreign_table_executor_dml_max_dop パラメーターを使用して同時実行性を制御できます。デフォルト値は 32 です。インポート中に、hg_foreign_table_executor_dml_max_dop をより小さい値に設定して、DML 文を実行するための同時実行性を減らします。特にデータインポートおよびエクスポートのシナリオで有効です。これにより、DML 文が過剰なリソースを消費するのを防ぎます。次のサンプルコードを使用します。
SET hg_foreign_table_executor_dml_max_dop = 8; INSERT INTO holo_table SELECT * FROM mc_table;
-