このトピックでは、Hologres と Delta Lake を使用してデータレイクハウスを構築するための背景情報、アーキテクチャ、準備、および手順について説明します。
背景情報
-
Delta Lake は Databricks 社が提供するデータレイクソリューションです。Delta Lake はデータ中心であり、データインジェスト、データ管理からデータクエリ、データエグレスまで、データストリームのための一連の機能を提供します。これにより、サードパーティの上流および下流のツールを使用して、高速で使いやすく、安全なデータレイクを構築できます。詳細については、「Delta Lake」をご参照ください。
-
E-MapReduce (EMR) は、Alibaba Cloud が提供するクラウドネイティブなオープンソースのビッグデータプラットフォームです。EMR は、Hadoop、Hive、Spark、Flink などのオープンソースのビッグデータコンピューティングエンジンとストレージエンジンを提供し、簡単に統合できます。これにより、Hadoop および Spark エコシステムの他のシステムを使用してデータを分析および処理できます。詳細については、「E-MapReduce とは」をご参照ください。
-
Data Lake Formation (DLF) は、クラウド上にデータレイクとデータレイクハウスを構築するのに役立つフルマネージドサービスです。DLF は、統一されたメタデータ管理、統一された権限とセキュリティの管理、便利なデータインジェスト、ワンクリックでのデータ探索を提供します。詳細については、「DLF 製品紹介」をご参照ください。
-
Hologres は、DLF と EMR とシームレスに統合されるワンストップのリアルタイムデータウェアハウスです。この統合により、データレイクとデータウェアハウスの間の障壁が取り払われ、完全なデータレイクハウスソリューションが構築されます。データレイクの柔軟性と豊富なエコシステムを、リアルタイムデータウェアハウスのパフォーマンス専有型で複雑なオンライン分析およびエンタープライズグレードの機能と組み合わせます。詳細については、「DLF を使用した OSS ベースのデータレイク内のデータのクエリの高速化」をご参照ください。
全体アーキテクチャ
このソリューションでは、EMR Spark を使用してデータの変換と処理を行います。メタデータは DLF に保存され、データは Object Storage Service (OSS) に保存されます。Hologres は DLF のメタデータ管理機能を使用して、Hudi、Delta、CSV、Parquet、ORC、SequenceFile などのさまざまな形式のデータレイクファイルのクエリを高速化します。これにより、統合されたデータレイクハウス分析が可能になります。データは、ビジネスインテリジェンス (BI) レポート、データ可視化ダッシュボード、および上流アプリケーションで使用できます。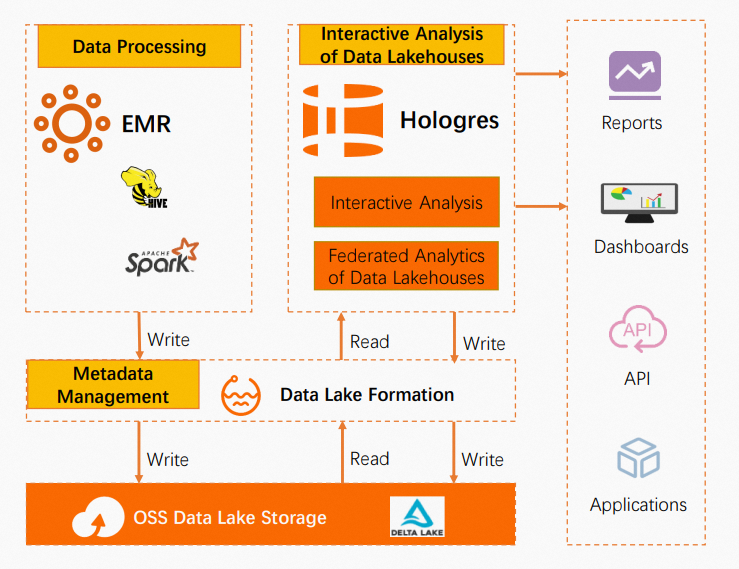
環境の準備
データソースを準備する
この手順は、EMR または OSS を初めて使用するユーザー向けです。EMR を使用して大量のビジネスデータがすでに OSS バケットに書き込まれている場合は、DLF のメタデータディスカバリー機能を直接使用してメタデータを自動的に生成できます。その後、Hologres はこのメタデータをクエリしてアクセスできます。メタデータディスカバリーの詳細については、「メタデータディスカバリー」をご参照ください。
-
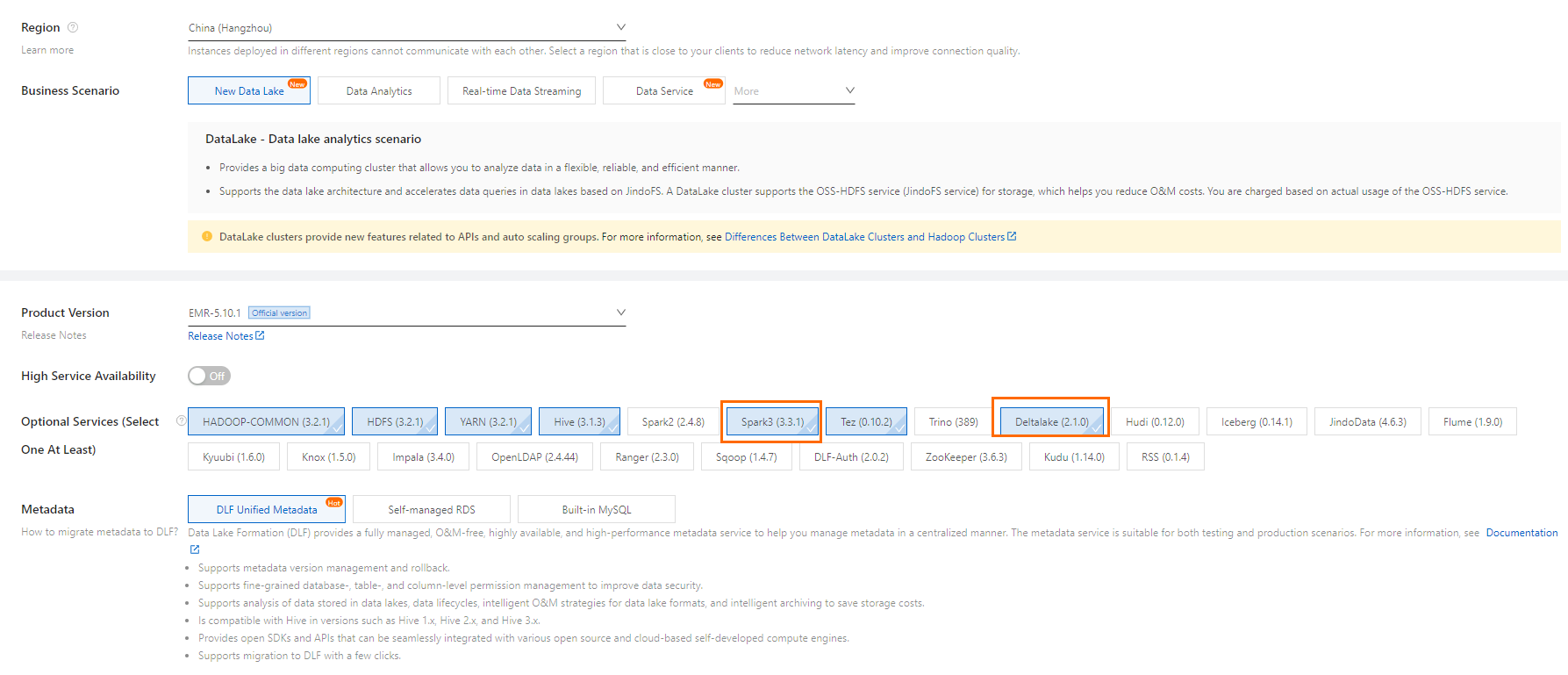
EMR の データレイククラスターをアクティブ化します。必要なサービスとストレージフォーマットを選択します。メタデータを管理するために DLF を選択します。このトピックでは、Spark、Hive、Delta を例として使用します。クラスターのアクティブ化方法の詳細については、「DataLake クラスターのクイック作成と使用」をご参照ください。
OSS をアクティブ化し、データを格納するバケットを作成します。 詳細については、「OSS をアクティブにする」をご参照ください。
-
EMR Spark を使用してデータを生成します。
-
EMR クラスターにログインします。Secure Shell (SSH) プロトコルを使用してマスターノードにログインするか、コアノードにパスワードなしでログインできます。詳細については、「クラスターへのログイン」をご参照ください。
-
100 GB の TPC-H テストデータを生成します。次のコマンドを実行します。
説明このトピックでの TPC-H の実装は、TPC-H ベンチマークに基づいています。このトピックのテストは、すべての TPC-H ベンチマーク要件を満たしているわけではないため、結果は公開されている TPC-H ベンチマーク結果とは比較できません。
# yum update を実行して、すべてのライブラリを更新します。 yum update # git と gcc をインストールします。 yum install git yum install gcc # TPC-H データ生成コードをダウンロードします。 git clone https://github.com/gregrahn/tpch-kit.git # データ生成ツールのコードディレクトリに移動します。 cd tpch-kit/dbgen # データ生成ツールのコードをコンパイルします。 make # 次のコードを実行してデータを生成します。 ./dbgen -vf -s 100 -
Hive 対話型シェルに入り、データベースとテーブルを作成し、生成されたデータをインポートします。
# Hive 対話型シェルに入ります。 hive # データベースを作成します。 CREATE DATABASE IF NOT EXISTS testdb_textfile location 'oss://oss-bucket-dlftest/testdb_textfile'; # 新しいデータベースに切り替えます。 USE testdb_textfile; # テーブルを作成します。 CREATE TABLE IF NOT EXISTS nation_textfile ( n_nationkey integer , n_name char(25) , n_regionkey integer , n_comment varchar(152) ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '|'; CREATE TABLE IF NOT EXISTS region_textfile ( r_regionkey integer , r_name char(25) , r_comment varchar(152) ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '|'; CREATE TABLE IF NOT EXISTS part_textfile ( p_partkey integer , p_name varchar(55) , p_mfgr char(25) , p_brand char(10) , p_type varchar(25) , p_size integer , p_container char(10) , p_retailprice decimal(15,2) , p_comment varchar(23) ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '|'; CREATE TABLE IF NOT EXISTS supplier_textfile ( s_suppkey integer , s_name char(25) , s_address varchar(40) , s_nationkey integer , s_phone char(15) , s_acctbal decimal(15,2) , s_comment varchar(101) ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '|'; CREATE TABLE IF NOT EXISTS partsupp_textfile ( ps_partkey integer , ps_suppkey integer , ps_availqty integer , ps_supplycost decimal(15,2) , ps_comment varchar(199) ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '|'; CREATE TABLE IF NOT EXISTS customer_textfile ( c_custkey integer , c_name varchar(25) , c_address varchar(40) , c_nationkey integer , c_phone char(15) , c_acctbal decimal(15,2) , c_mktsegment char(10) , c_comment varchar(117) ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '|'; CREATE TABLE IF NOT EXISTS orders_textfile ( o_orderkey integer , o_custkey integer , o_orderstatus char(1) , o_totalprice decimal(15,2) , o_orderdate date , o_orderpriority char(15) , o_clerk char(15) , o_shippriority integer , o_comment varchar(79) ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '|'; CREATE TABLE IF NOT EXISTS lineitem_textfile ( l_orderkey integer , l_partkey integer , l_suppkey integer , l_linenumber integer , l_quantity decimal(15,2) , l_extendedprice decimal(15,2) , l_discount decimal(15,2) , l_tax decimal(15,2) , l_returnflag char(1) , l_linestatus char(1) , l_shipdate date , l_commitdate date , l_receiptdate date , l_shipinstruct char(25) , l_shipmode char(10) , l_comment varchar(44) ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '|'; # データをインポートします。 LOAD DATA LOCAL INPATH '${YOUR_PATH}/nation.tbl*' OVERWRITE INTO TABLE nation_textfile; LOAD DATA LOCAL INPATH '${YOUR_PATH}/region.tbl*' OVERWRITE INTO TABLE region_textfile; LOAD DATA LOCAL INPATH '${YOUR_PATH}/supplier.tbl*' OVERWRITE INTO TABLE supplier_textfile; LOAD DATA LOCAL INPATH '${YOUR_PATH}/customer.tbl*' OVERWRITE INTO TABLE customer_textfile; LOAD DATA LOCAL INPATH '${YOUR_PATH}/part.tbl*' OVERWRITE INTO TABLE part_textfile; LOAD DATA LOCAL INPATH '${YOUR_PATH}/partsupp.tbl*' OVERWRITE INTO TABLE partsupp_textfile; LOAD DATA LOCAL INPATH '${YOUR_PATH}/orders.tbl*' OVERWRITE INTO TABLE orders_textfile; LOAD DATA LOCAL INPATH '${YOUR_PATH}/lineitem.tbl*' OVERWRITE INTO TABLE lineitem_textfile; -
spark-sqlコマンドを実行して対話型シェルに入ります。次に、Delta 形式でデータベースとテーブルを作成します。# spark-sql 対話型シェルに入ります。 spark-sql --conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' --conf 'spark.sql.delta.mergeSchema=true' --conf 'autoMerge.enable=true' --conf 'spark.sql.parquet.writeLegacyFormat=true' # データベースを作成します。 CREATE DATABASE IF NOT EXISTS test_spark_delta LOCATION 'oss://oss-bucket-dlftest/test_spark_delta'; # 新しいデータベースに切り替えて、テーブルを作成します。 USE test_spark_delta; CREATE TABLE nation_delta USING delta AS SELECT * FROM ${SOURCE}.nation_textfile; CREATE TABLE region_delta USING delta AS SELECT * FROM ${SOURCE}.region_textfile; CREATE TABLE supplier_delta USING delta AS SELECT * FROM ${SOURCE}.supplier_textfile; CREATE TABLE customer_delta USING delta partitioned BY (c_mktsegment) AS SELECT * FROM ${SOURCE}.customer_textfile; CREATE TABLE part_delta USING delta partitioned BY (p_brand) AS SELECT * FROM ${SOURCE}.part_textfile; CREATE TABLE partsupp_delta USING delta AS SELECT * FROM ${SOURCE}.partsupp_textfile; CREATE TABLE orders_delta USING delta partitioned BY (o_orderdate) AS SELECT * FROM ${SOURCE}.orders_textfile; CREATE TABLE lineitem_delta USING delta partitioned BY (l_shipdate) AS SELECT * FROM ${SOURCE}.lineitem_textfile;
-
Hologres のデータレイクアクセラレーションの有効化
Hologres コンソールに移動し、Instances ページで対象インスタンスの Actions 列にある Lake Acceleration をクリックしてこの機能を有効にします。
利用手順
Hologres のデータレイクアクセラレーション機能は、次の 2 つのシナリオをサポートしています。必要に応じてシナリオを選択してください。
シナリオ 1:OSS 内のテーブルデータに対するクエリを直接高速化する
例:
-- dlf_fdw 拡張機能を作成します。
CREATE EXTENSION IF NOT EXISTS dlf_fdw;
-- 外部サーバーを作成します。
CREATE SERVER IF NOT EXISTS dlf_server FOREIGN data wrapper dlf_fdw options
(
dlf_region 'cn-beijing',
dlf_endpoint 'dlf-share.cn-beijing.aliyuncs.com',
oss_endpoint 'oss-cn-beijing-internal.aliyuncs.com'
);
-- 外部テーブルの定義をインポートします。
IMPORT FOREIGN SCHEMA "test_spark_delta" LIMIT TO
(
customer_delta,
lineitem_delta,
nation_delta,
orders_delta,
part_delta,
partsupp_delta,
region_delta,
supplier_delta
)
FROM SERVER dlf_server INTO oss_ext_tables options (if_table_exist 'update');
-- テーブルデータをクエリします。Q22 を例として使用します。
SELECT
cntrycode,
count(*) AS numcust,
sum(c_acctbal) AS totacctbal
FROM
(
SELECT
substring(c_phone FROM 1 FOR 2) AS cntrycode,
c_acctbal
FROM
customer_delta
WHERE
substring(c_phone FROM 1 FOR 2) IN
('24', '32', '17', '18', '12', '14', '22')
AND c_acctbal > (
SELECT
avg(c_acctbal)
FROM
customer_delta
WHERE
c_acctbal > 0.00
AND substring(c_phone FROM 1 FOR 2) IN
('24', '32', '17', '18', '12', '14', '22')
)
AND NOT EXISTS (
SELECT
*
FROM
orders_delta
WHERE
o_custkey = c_custkey
)
) AS custsale
GROUP BY
cntrycode
ORDER BY
cntrycode;次の結果が返されます。
+------------+-------------+---------------+
| cntrycode | numcust | totacctbal |
+------------+-------------+---------------+
| 12 | 90805 | 681136537.68 |
| 14 | 91459 | 685826271.21 |
| 17 | 91313 | 685025263.11 |
| 18 | 91292 | 684588251.63 |
| 22 | 90399 | 677402363.79 |
| 24 | 90635 | 680033065.67 |
| 32 | 90668 | 680459221.16 |
+------------+-------------+---------------+シナリオ 2:クエリパフォーマンスを向上させるために、データを Hologres 標準ストレージにインポートする
Hologres 標準ストレージは SSD (NVMe) ディスクを使用しており、より高いランダム読み書き性能を実現します。OSS 外部テーブルから Hologres 標準ストレージの内部テーブルにデータをインポートできます。その後、インデックスの作成、適切な Shard Count の設定、および適切な分布列の選択によって、クエリパフォーマンスを最適化できます。クエリ 2 (Q2) では、これによりパフォーマンスが 18 倍以上向上する可能性があります。詳細については、「内部テーブルのパフォーマンスの最適化」をご参照ください。
-
Hologres に同じ構造の内部テーブルを作成し、データをインポートします。
次のコードは例です。その他の CREATE TABLE 文については、「Hologres クエリ体験クイックスタート」をご参照ください。
-- 内部テーブルを作成します。 BEGIN; CREATE TABLE region ( R_REGIONKEY INT NOT NULL PRIMARY KEY, R_NAME TEXT NOT NULL, R_COMMENT TEXT ); CALL set_table_property('region', 'distribution_key', 'R_REGIONKEY'); CALL set_table_property('region', 'bitmap_columns', 'R_REGIONKEY,R_NAME,R_COMMENT'); CALL set_table_property('region', 'dictionary_encoding_columns', 'R_NAME,R_COMMENT'); CALL set_table_property('region', 'time_to_live_in_seconds', '31536000'); COMMIT; -- データをインポートします。 INSERT INTO public.region SELECT * FROM region_delta ; -
内部テーブルのクエリ結果。
SELECT cntrycode, count(*) AS numcust, sum(c_acctbal) AS totacctbal FROM ( SELECT substring(c_phone FROM 1 FOR 2) AS cntrycode, c_acctbal FROM customer WHERE substring(c_phone FROM 1 FOR 2) IN ('24', '32', '17', '18', '12', '14', '22') AND c_acctbal > ( SELECT avg(c_acctbal) FROM customer WHERE c_acctbal > 0.00 AND substring(c_phone FROM 1 FOR 2) IN ('24', '32', '17', '18', '12', '14', '22') ) AND NOT EXISTS ( SELECT * FROM orders WHERE o_custkey = c_custkey ) ) AS custsale GROUP BY cntrycode ORDER BY cntrycode;
パフォーマンス比較
32 コアの専用型インスタンスの場合、Hologres 内部テーブルに対するクエリは、OSS 外部テーブルに対するクエリよりも約 100 倍高速です。
-
OSS外部テーブル
-
クエリ時間:17.24 秒。
実行プラン:

-
Hologres内部テーブル
クエリ時間: 106.67ミリ秒
実行プラン:
