このドキュメントでは、Hologres におけるメモリ不足 (OOM) エラーの原因と解決策について説明します。OOM エラーは、クエリのメモリ消費量が利用可能なシステムメモリを超え、例外がトリガーされたときに発生します。このドキュメントでは、Hologres でのメモリ消費量の監視方法、メモリ使用率が高いシナリオの分析、OOM エラーとその原因の特定方法、および解決策を提示します。
メモリ消費量の分析
メモリ消費量の表示
合計消費量:Hologres コンソールでは、インスタンスのメモリ消費量の概要が提供されます。これは、すべてのノードからの値を集約したものです。詳細については、「監視メトリック」をご参照ください。
クエリごとの消費量:
memory_bytesフィールドは、単一クエリのメモリ消費量を概算します。なお、この値は概算値であり、不正確な場合があります。詳細については、「スロークエリログの表示と分析」をご参照ください。
高いメモリ使用量への対処
Hologres コンソールのメトリックを使用して、ご利用の Hologres インスタンス全体のメモリ使用量を監視します (詳細については、「監視メトリック」をご参照ください)。メモリ使用率が継続的に 80% を超える状態は、高いと見なされます。Hologres は、計算速度を向上させるためにメタデータとキャッシュ用のメモリを事前に割り当てます。その結果、通常のアイドル時の使用率は 30〜50% になります。しかし、使用率が 100% に近づくと、システムの安定性とパフォーマンスに影響を与える問題を示しています。以下のセクションでは、高いメモリ使用量の原因、影響、および解決策について詳しく説明します。
原因
メタデータによる高いメモリ消費量
メタデータのメモリ使用率の高さが、この問題の主要な指標です。テーブル内のデータ量が増加するにつれて、それを管理するために必要なメタデータも増加し、より多くのメモリを消費します。これにより、タスクが実行されていない場合でもメモリ使用率が高くなる可能性があります。ベストプラクティスとして、単一の Table Group には 10,000 テーブル (パーティションを含むが、外部テーブルは除く) を超えないようにしてください。さらに、Table Group 内のシャード数が多いと、ファイルの断片化とメタデータの蓄積が増加し、それによって追加のメモリが消費される可能性があります。
計算による高いメモリ消費量
高いクエリのメモリ使用量はこの問題の主要な指標であり、通常、クエリが大量のデータボリュームをスキャンする場合や、多数の
COUNT DISTINCT関数、複雑なJOIN操作、複数の列に対するGROUP BY、またはウィンドウ関数などの複雑な計算ロジックを伴う場合に発生します。
主な影響
安定性
特にメタデータによる過剰なメモリ消費は、クエリに使用できるメモリを直接減少させます。これにより、
SERVER_INTERNAL_ERROR、ERPC_ERROR_CONNECTION_CLOSED、またはTotal memory used by all existing queries exceeded memory limitationなどの散発的なエラーが発生する可能性があります。パフォーマンス
高いメモリ使用率、特に過剰なメタデータによるものは、クエリに必要なキャッシュスペースを枯渇させます。これにより、キャッシュヒット率が低下し、結果としてクエリレイテンシーが増加します。
解決策
過剰なメタデータが原因でメモリ使用量が多くなっている場合:
hg_table_infoテーブルを使用してテーブルを管理します。 詳細については、「テーブル統計のクエリと分析」をご参照ください。 メモリを解放するために、クエリされなくなったデータやテーブルの削除、および不要なパーティションテーブル設計の削減を検討してください。計算が原因でメモリ使用率が高い場合:書き込みとクエリのユースケースに合わせて SQL を個別に最適化します。詳細については、「クエリ中の OOM エラーの解決方法」および「データインポート・エクスポート中の OOM エラーの解決方法」をご参照ください。
一般的な解決策:インスタンスの計算リソースとストレージリソースをスケールアップします。詳細については、「インスタンスリスト」をご参照ください。
OOM エラーの特定
OOM エラーは、計算メモリが割り当てられた制限 (例:20 GB 以上) を超えたときに発生します。一般的なエラーメッセージを以下に示します。
既存のすべてのクエリで使用される合計メモリがメモリ制限を超えました。
既存のクエリのメモリ使用量 =(2031xxxx、184yy)(2021yyyy、85yy)(1021121xxxx、6yy)(2021xxx、18yy)(202xxxx、14yy)。使用/制限:xy1 / xy2 クォータ/合計クォータ:zz / 100エラーメッセージは次のように解釈します。
queries=(query_id, memory_used_by_query)queries=(2031xxxx,184yy)のようなこのセクションは、個々のクエリのメモリ消費量を示します。たとえば、queries=(2031xxxx,18441803528)は、query_id=2031xxxxのクエリが実行中にシングルノードで約 18 GB のメモリを消費したことを意味します。エラーメッセージには通常、メモリを大量に消費するクエリの上位 5 件が一覧表示されるため、主な原因の特定に役立ちます。詳細については、スロークエリログの表示と分析をご参照ください。Used/Limit: xy1/xy2このセグメントには、
compute_memory_used_on_nodeとcompute_memory_limit_on_nodeの比率がバイト単位で表示されます。Usedの値は、その特定のノードで現在実行中のすべてのクエリによって消費される合計計算メモリを表します。たとえば、Used/Limit: 33288093696/33114697728は、ノード上のクエリによって使用された合計メモリが 33.2 GB に達し、ノードのエラスティックメモリ制限である 33.1 GB を超えたため、OOM エラーがトリガーされたことを意味します。quota/sum_quota: zz/100ここで、
zzは、インスタンスの総リソースのうち、特定のリソースグループに割り当てられる割合を表します。たとえば、quota/sum_quota: 50/100は、リソースグループが設定され、インスタンスの総リソースの 50% を使用することを示します。
OOM エラーの基本的な原因
メモリが不足した場合に「ディスクへのスピル」を行う一部のシステムとは異なり、Hologres は最適なクエリ効率を確保するために、デフォルトでインメモリコンピューティングを優先します。この基本的な設計思想により、クエリのメモリ要求が利用可能なリソースを超えた場合、ディスク使用によるパフォーマンス低下ではなく、直接 OOM エラーが発生します。
メモリ割り当てと制限
Hologres インスタンスは分散システムとして動作し、複数のノードで構成されます。ノードの数はインスタンス仕様によって異なります。詳細については、「インスタンス管理」をご参照ください。
Hologres インスタンスの各ノードは、通常 16 vCPU と 64 GB のメモリを備えています。クエリに関与するいずれかの単一ノードがメモリを使い果たすと、OOM エラーがトリガーされます。この 64 GB は、クエリ計算、バックエンドプロセス、キャッシュ、メタデータなど、さまざまな目的のために分割されます。以前のバージョン (V1.1.24 以前) では、計算ノードに 20 GB の固定メモリ制限が課されていましたが、Hologres V1.1.24 以降のバージョンではこの制約が撤廃されました。メモリは現在、動的に調整されます。システムはメモリ使用量を継続的に監視し、メタデータの消費が少ない場合、残りの利用可能なメモリをクエリ実行にインテリジェントに割り当て、ランタイムパフォーマンスを最大化します。
クエリ中の OOM エラーの解決方法
原因
不適切な実行計画:不正確な統計情報、不適切な結合順序、またはその他の最適化の問題が原因である可能性があります。
高いクエリ同時実行数:多くのクエリが同時に大量のメモリを消費しています。
複雑なクエリ:本質的に複雑なクエリ、または大量のデータをスキャンするクエリです。
UNION ALL操作:UNION ALLを含むクエリは、エグゼキュータの並列度を高め、メモリ使用量の増加につながる可能性があります。不十分なリソースグループの割り当て:リソースグループが構成されているものの、割り当てられたリソースが不十分です。
データスキューまたはシャードプルーニング:これらは、特定のノードに負荷が不均衡に集中し、高いメモリプレッシャーを引き起こす可能性があります。
分析と解決策:
原因:不十分なリソースグループの割り当て
解決策:不十分なリソース割り当てに起因する OOM エラーに対処するには、Serverless Computing 機能を利用します。これにより、インスタンスの専用リソースに加えて、豊富なサーバーレスコンピューティングリソースを利用でき、リソース競合を効果的に回避し、より多くの計算容量を提供します。概要と使用方法については、「Serverless Computing」および「Serverless Computing ガイド」をご参照ください。
Hologres V3.0 以降では、クエリキューが自動化されたソリューションを提供します。OOM クエリは、手動で定義する必要なく、サーバーレスコンピューティングリソースを使用して自動的に再実行できます。詳細については、「大規模クエリの制御」をご参照ください。
原因:不適切な実行計画
タイプ 1:不正確な統計情報
EXPLAIN <SQL>を実行して実行計画を表示します。下の図に示すように、rows=1000は統計情報が欠落しているか不正確であることを示しており、非効率な実行計画が過剰なリソースを消費し、OOM エラーをトリガーします。
解決策には以下が含まれます。
ANALYZE <tablename>コマンドを実行してテーブルの統計情報を更新します。自動分析を有効にして、統計情報を自動的に更新します。詳細については、「ANALYZE と AUTO ANALYZE」をご参照ください。
タイプ 2:不適切な結合順序
ハッシュ結合を使用する場合、小さい方のテーブルを「ビルド」側としてハッシュテーブルを構築することで、メモリ使用量を最適化するのが理想的です。
EXPLAIN <SQL>を使用して実行計画を調べます。 実行計画で、大きい方のテーブルがハッシュテーブルの構築に使用されていることが示された場合、これは非効率な結合順序を意味し、OOM エラーが発生しやすくなります。 一般的な理由として、以下が挙げられます。古いテーブル統計情報。例えば、下の図では、上のテーブルの統計情報が更新されていなかったため、
rows=1000となっています。
オプティマイザーが最適な実行計画を生成できませんでした。
解決策:
結合に関与するすべてのテーブルで
ANALYZE <tablename>を実行して、最新の統計情報を確保します。これにより、オプティマイザーが正しい結合順序を決定するのに役立ちます。ANALYZE <tablename>を実行しても結合順序が正しくない場合は、GUC パラメーターを調整します。Setoptimizer_join_order = queryを設定して、オプティマイザーが SQL 文で指定された結合順序に強制的にフォローするようにします。このアプローチは、特に複雑なクエリに適しています。SET optimizer_join_order = query; SELECT * FROM a JOIN b ON a.id = b.id; -- テーブル b がハッシュテーブルのビルド側として使用されます。必要に応じて結合順序ポリシーを調整することもできます。
パラメーター
説明
set optimizer_join_order = <value>
このパラメーターは、オプティマイザーの結合順序アルゴリズムを制御します。有効な値:
query:結合順序の変換を実行しません。結合は、SQL クエリで指定された順序で厳密に実行されます。この設定は、オプティマイザーのオーバーヘッドが最も低くなります。greedy:貪欲法を使用して、可能な結合順序を探索します。このオプションは、中程度のオプティマイザーオーバーヘッドになります。exhaustive(デフォルト):結合順序の変換に動的計画法を使用します。最適な実行計画を生成することを目指しますが、オプティマイザーのオーバーヘッドが最も高くなります。
タイプ 3:不正確なハッシュテーブルの推定
ハッシュ結合中、理想的には小さい方の入力 (テーブルまたはサブクエリ) がビルド入力として指定され、ハッシュテーブルを構築してパフォーマンスを最適化し、メモリを節約します。しかし、クエリの複雑さや不正確な統計情報のために、システムがデータ量を誤って推定し、誤って大きい方のリレーションをビルド入力として選択することがあります。これにより、過度に大きなハッシュテーブルが構築され、大量のメモリを消費して OOM エラーがトリガーされます。
下の図に示すように、
Hash (cost=727353.45..627353.35 , rows=970902134 width=94)はビルド入力を表し、rows=970902134はハッシュテーブルを構築するための推定データ量を示します。実際のテーブルに含まれるデータが少ない場合、推定は不正確です。
解決策:
統計情報の検証: サブクエリのテーブルの統計情報が最新かつ正確であるかを確認します。そうでない場合は、
ANALYZE <tablename>を実行して統計情報を更新します。ハッシュテーブル推定の無効化:次のパラメーターを使用して、実行エンジンのハッシュテーブル推定をオフにします。
説明このパラメーターのデフォルトは
offです。ただし、特定のチューニングシナリオで有効になっている場合があります。現在有効になっている場合は、必ずoffに設定し直してください。SET hg_experimental_enable_estimate_hash_table_size = off;
タイプ 4:大きなテーブルのブロードキャスト
ブロードキャストは、すべてのシャードにデータをコピーする処理です。テーブルと全体のシャード数が小さい場合にのみ効率的です。結合操作では、実行計画はまずビルド入力データをブロードキャストし、次にハッシュテーブルを構築します。これは、すべてのシャードがビルド入力データセット全体を受信して処理することを意味します。大きなデータセットや過剰なシャード数は、大量のメモリを消費し、しばしば OOM エラーにつながります。
例えば、8,000 万行のテーブルが実行計画では推定 1 行として表示され、ブロードキャストに関与するのはわずか 80 行であるかのように見えることがあります。これは明らかな矛盾です。しかし、実際の実行では 8,000 万行すべてがブロードキャストされ、過剰なメモリを消費して OOM エラーがトリガーされます。

解決策:
実行計画の推定行数が実態と一致しているかを確認します。一致していない場合は、
ANALYZE tablenameを実行して統計情報を更新します。次の GUC パラメーターを使用して、ブロードキャストを無効にし、再配布オペレーターとして書き換えます。
SET optimizer_enable_motion_broadcast = off;
原因:高いクエリ同時実行数
QPS (Queries Per Second) メトリックが大幅に急上昇した場合、または OOM エラーレポートで
HGERR_detl memory usage for existing queries=(2031xxxx,184yy)(2021yyyy,85yy)(1021121xxxx,6yy)(2021xxx,18yy)(202xxxx,14yy);と表示され、各クエリが比較的小さなメモリしか使用していない場合、高いクエリ同時実行数が原因である可能性が高いです。解決策:書き込み同時実行数の削減:書き込み操作が原因である場合は、その同時実行数を減らします。詳細については、「データインポート・エクスポート中の OOM エラーの解決方法」をご参照ください。
読み書き分離の実装:プライマリインスタンスとセカンダリインスタンス (共有ストレージ) を使用した読み書き分離アーキテクチャを導入します。
ご利用のインスタンスの計算仕様を増強します。
原因:複雑なクエリ
単一のクエリが、その本質的な複雑さやスキャンするデータ量が原因で OOM エラーをトリガーする場合、次のアプローチを検討してください。
データの事前計算:事前計算を実行し、クレンジングされたデータを Hologres に書き込むことで、Hologres 内で直接大規模な ETL 操作を行うのを避けます。
フィルター条件の追加。
SQL の最適化:固定プランや Count Distinct の最適化などの手法を使用して、SQL 文自体を最適化します。詳細については、「クエリパフォーマンスの最適化」をご参照ください。
原因:UNION ALL
以下に示すように、SQL 文に多くの
UNION ALLサブクエリが含まれている場合、エグゼキュータはそれらを同時に処理します。これにより、メモリが過負荷になり、OOM エラーが発生する可能性があります。subquery1 UNION ALL subquery2 UNION ALL subquery3 ...解決策:次のパラメーターを使用してシリアル実行を強制し、OOM エラーを軽減します。これによりクエリのパフォーマンスが低下することにご注意ください。
SET hg_experimental_hqe_union_all_type = 1; SET hg_experimental_enable_fragment_instance_delay_open = on;原因:不合理なリソースグループ構成
OOM エラーレポート:
memory usage for existing queries=(3019xxx,37yy)(3022xxx,37yy)(3023xxx,35yy)(4015xxx,30yy)(2004xxx,2yy); Used/Limit: xy1/xy2 quota/sum_quota: zz/100。もし zz が小さい場合、例えば 10 (インスタンスの総リソースの 10% のみがリソースグループに割り当てられていることを示す) の場合、この限られた割り当ては、そのグループ内で実行されるクエリに利用可能なメモリを大幅に制限し、OOM エラーの可能性を高めます。
解決策: リソースグループのクォータをリセットします。各リソースグループに、インスタンスの総リソースの少なくとも
30%を割り当て、十分なメモリ容量を確保します。原因:データスキューまたはシャードプルーニング
インスタンス全体のメモリ使用率が低いにもかかわらず OOM エラーが発生する場合、原因は通常、データスキューまたはシャードプルーニングであり、これによりメモリプレッシャーが 1 つまたは少数のノードに集中します。
説明シャードプルーニングは、すべてのシャードではなく、シャードのサブセットのみをスキャンするクエリ最適化技術です。
データスキューの確認:次の SQL クエリを使用します。
hg_shard_idは、各行がどのシャードに存在するかを示す、すべてのテーブルに組み込まれた隠しフィールドです。SELECT hg_shard_id, count(1) FROM t1 GROUP BY hg_shard_id;シャードプルーニングの確認:実行計画でシャードプルーニングの兆候を確認します。たとえば、シャードセレクターに
l0[1]と表示されている場合、クエリに対して特定の 1 つのシャードのデータのみが選択されたことを意味します。-- 分散キーは x です。フィルター条件 x=1 に基づいて、シャードを迅速に特定できます。 SELECT count(1) FROM bbb WHERE x=1 GROUP BY y;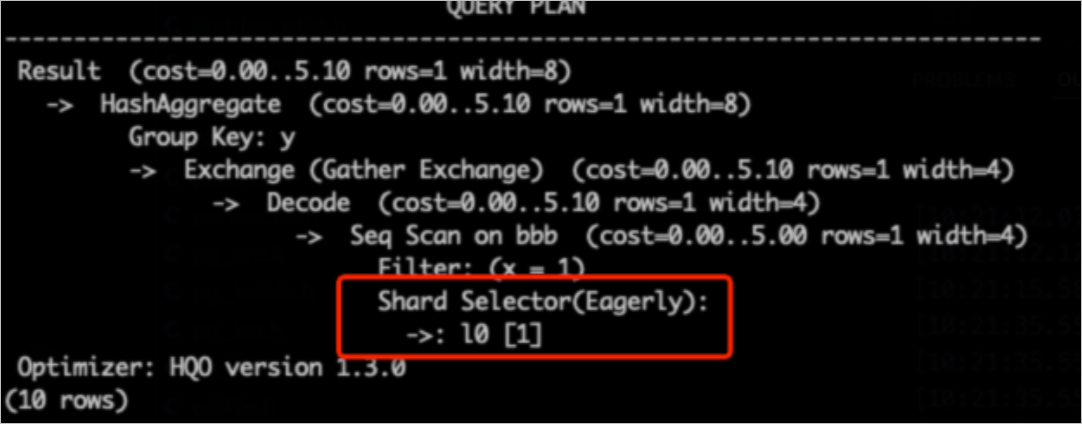
解決策:
データスキューを防ぐために、適切な分散キーを設計します。
ビジネスロジック上、本質的にデータスキューが発生する場合は、アプリケーションロジックを適宜修正してください。
原因:高カーディナリティの多段階 GROUP BY
Hologres V3.0 以降、高カーディナリティデータに対する多段階集約では OOM エラーが発生しやすくなります。これは、
GROUP BY列がデータ分布と一致しない (つまり、分散キーがGROUP BYキーのサブセットではない) 場合に多く発生します。このような状況では、初期集約ステージの各同時実行インスタンスは、グループ化のために非常に大きなハッシュテーブルを維持する必要があり、高いメモリプレッシャーが発生します。これを緩和するには、次のパラメーターを設定して段階的な集約を有効にします。-- GUC パラメーターを使用して、集約ハッシュテーブルの最大行数を設定します。次の SQL 文は、partial_agg_hash_table が最大 8192 行を持つことができることを示します。デフォルト値は 0 で、制限がないことを示します。 SET hg_experimental_partial_agg_hash_table_size = 8192;
データインポート・エクスポート中の OOM エラーの解決方法
Hologres 内でのデータ転送操作中に OOM エラーが発生することがあります。これは、内部テーブル間の転送だけでなく、外部テーブルとのやり取りにも適用されます。このようなエラーが発生する頻繁なシナリオは、MaxCompute から Hologres へのデータインポート時です。
解決策 1:インポートおよびエクスポートに Serverless Computing を使用する
Serverless Computing 機能を使用すると、インスタンスの専用リソースを補完するために、インポートおよびエクスポートタスクに追加のサーバーレスリソースを活用できます。これにより、より大きな計算容量が提供され、リソース競合を回避するのに役立ち、データ転送中の OOM 問題を解決するための効果的なソリューションとなります。概要については、「Serverless Computing」をご参照ください。詳細な使用方法については、「Serverless Computing ガイド」をご参照ください。
解決策 2:ワイドテーブルまたはワイドカラムのスキャン同時実行数を制御する
MaxCompute のインポートシナリオでは、ワイドテーブルまたはワイドカラムが高いスキャン同時実行数と組み合わされると、書き込み中に OOM エラーが発生する可能性があります。次のパラメーターを使用してインポートの同時実行数を制御し、これらの OOM エラーを軽減します。
ワイドテーブルのスキャン同時実行数を制御する (一般的なシナリオ)
説明SQL 文と一緒に次のパラメーターを適用してください。最初の 2 つのパラメーターを優先します。OOM エラーが解決しない場合は、それらの値をさらに減らしてください。
-- 外部テーブルへのアクセスに対する最大同時実行数を設定します。デフォルト値はインスタンスの vCPU 数と同じです。最大値は 128 です。外部テーブルへのクエリ、特にデータインポートシナリオで、他のクエリに影響を与え、システムビジーエラーを引き起こさないように、大きな値を設定しないでください。このパラメーターは Hologres V1.1 以降で有効です。 SET hg_foreign_table_executor_max_dop = 32; -- MaxCompute テーブルからの各読み取りのバッチサイズを調整します。デフォルト値は 8192 です。 SET hg_experimental_query_batch_size = 4096; -- 外部テーブルにアクセスする際の DML 文の最大実行同時実行数を設定します。デフォルト値は 32 です。このパラメーターは、インポート操作が過剰なシステムリソースを消費するのを防ぐために、データインポートおよびエクスポートシナリオ向けに最適化されています。このパラメーターは Hologres V1.1 以降で有効です。 SET hg_foreign_table_executor_dml_max_dop = 16; -- MaxCompute テーブルにアクセスするための分割サイズを設定します。このパラメーターで同時実行数を調整できます。デフォルト値は 64 MB です。テーブルが大きい場合は、この値を増やして、分割が多すぎてパフォーマンスに影響を与えるのを防ぎます。このパラメーターは Hologres V1.1 以降で有効です。 SET hg_foreign_table_split_size = 128;ワイドカラムのスキャン同時実行数を制御する
すでにワイドテーブルのパラメーターを調整しても OOM エラーが発生する場合は、データにワイドカラムが含まれているかどうかを確認してください。含まれている場合は、次のパラメーターを調整して問題を解決します。
-- ワイドカラムのシャッフル並列度を調整して、データの蓄積を減らします。 SET hg_experimental_max_num_record_batches_in_buffer = 32; -- MaxCompute テーブルからの各読み取りのバッチサイズを調整します。デフォルト値は 8192 です。 SET hg_experimental_query_batch_size=128;
原因:外部テーブル内の過剰な重複データ
外部テーブルに大量の重複データが含まれている場合、インポートのパフォーマンスが大幅に低下し、しばしば OOM エラーにつながります。「大量の重複データ」の定義は文脈に依存し、ユースケースによって異なります。例えば、1 億行のテーブルに 8,000 万の重複がある場合、通常は非常に重複度が高いと見なされます。これは、特定のビジネスコンテキストに基づいて評価する必要があります。
解決策:インポートする前にデータを重複排除するか、大量の重複データを同時にロードしないように、より小さなバッチでインポートします。