`GROUP BY` や `JOIN` 操作を頻繁に実行するテーブルがある場合や、データスキューを防ぎたい場合は、テーブル作成時に分散キーを設定できます。適切な分散キーを設定すると、データがすべてのコンピューティングノードに均等に分散され、コンピューティングとクエリのパフォーマンスが大幅に向上します。このトピックでは、Hologres のテーブルに分散キーを設定する方法について説明します。
分散キーの概要
Hologres では、分散キープロパティはテーブルのデータ分散ポリシーを指定します。システムは、同じ分散キーを持つレコードが同じシャードに割り当てられることを保証します。テーブル作成時に分散キーを設定する構文は次のとおりです。
-- Hologres V2.1 以降でサポートされる構文
CREATE TABLE <table_name> (...) WITH (distribution_key = '[<columnName>[,...]]');
-- すべてのバージョンでサポートされる構文
BEGIN;
CREATE TABLE <table_name> (...);
call set_table_property('<table_name>', 'distribution_key', '[<columnName>[,...]]');
COMMIT;次の表にパラメーターを示します。
パラメーター | 説明 |
table_name | 分散キーを設定するテーブルの名前。 |
columnName | 分散キーとして設定するフィールドの名前。 |
分散キーは分散システムにおける重大な概念です。適切に設定された分散キーは、次の利点をもたらします。
コンピューティングパフォーマンスを大幅に向上させます。
シャードは並列で計算を実行できるため、コンピューティングパフォーマンスが向上します。
クエリ/秒 (QPS) を大幅に向上させます。
分散キーをフィルター条件として使用すると、Hologres は関連するシャードのみをスキャンできます。そうでない場合、Hologres はすべてのシャードをスキャンする必要があり、QPS が低下します。
JOIN パフォーマンスを大幅に向上させます。
2 つのテーブルが同じテーブルグループにあり、それらの `JOIN` フィールドが分散キーである場合、データ分散により、両方のテーブルの対応するデータが同じシャードに配置されることが保証されます。これにより、各ノード内のデータに対して Local Join を実行でき、実行効率が大幅に向上します。
利用推奨
分散キーを設定する際は、次の原則に従ってください。
データ分布が均一なフィールドを分散キーとして選択してください。そうしないと、データスキューによって負荷の不均衡が生じ、クエリ効率が低下する可能性があります。データスキューの確認方法の詳細については、「ワーカースキュー関係の表示」をご参照ください。
頻繁に
GROUP BY句で使用されるフィールドを分散キーとして選択してください。`JOIN` シナリオでは、`JOIN` フィールドを分散キーとして設定して Local Join を有効にし、データシャッフルを回避します。結合するテーブルは、同じテーブルグループに属している必要があります。
分散キーとして設定するフィールドが多すぎないようにしてください。2 つ以下のフィールドを使用することを推奨します。複数のフィールドを分散キーとして設定した場合、クエリがすべてのフィールドにヒットしないと、データシャッフルが発生する可能性があります。列の値が同一である複合分散キーの使用は避けてください。これにより、すべてのデータが単一のシャードに分散され、データスキューが発生します。
1 つ以上の列を分散キーとして設定できます。複数の列を指定する場合は、カンマ (,) で区切ります。複数の列を分散キーとして指定した場合、列の順序はデータレイアウトやクエリのパフォーマンスに影響しません。
テーブルにプライマリキー (PK) がある場合、分散キーは PK または PK フィールドのサブセットである必要があります。分散キーは空にできません。少なくとも 1 つの列を指定する必要があります。分散キーを指定しない場合、デフォルトで PK が分散キーとして使用されます。
制限事項
分散キーはテーブル作成時に設定する必要があります。分散キーを変更するには、テーブルを再作成してデータをインポートする必要があります。
分散キー列の値を変更することはできません。変更するには、テーブルを再作成する必要があります。
Float、Double、Numeric、Array、JSON、またはその他の複雑なデータ型のフィールドを分散キーとして設定することはできません。
テーブルに PK がない場合、分散キーは空にすることができます。つまり、列が指定されていない状態です。分散キーが空の場合、データはランダムにシャッフルされ、異なるシャードに分散されます。Hologres V1.3.28 以降、分散キーを空にすることはできません。次の例は、サポートされなくなった構文を示しています。
--V1.3.28 以降、この構文は禁止されています。 CALL SET_TABLE_PROPERTY('<tablename>', 'distribution_key', '');分散キー列に
null値が含まれている場合、その値はハッシュ化の目的で空の文字列 ("") として扱われます。
技術的原則
分散キーは、テーブルの分散ポリシーを指定します。適切なポリシーは、ビジネスシナリオによって異なります。
分散キーの設定
テーブルに分散キーを設定すると、データは分散キーに基づいて各シャードに割り当てられます。アルゴリズムは Hash(distribution_key)%shard_count です。この計算結果によって、レコードのターゲットシャードが決まります。システムは、同じ分散キーを持つレコードが同じシャードに割り当てられることを保証します。次の例は、分散キーの設定方法を示しています。
テーブル作成構文 (Hologres V2.1 以降でサポート):
--列 a を分散キーとして設定します。システムは列 a の値に対してハッシュ操作を行い、次に剰余演算を行います。数式は hash(a) % shard_count = shard_id です。同じ結果のデータは同じシャードに分散されます。 CREATE TABLE tbl ( a int NOT NULL, b text NOT NULL ) WITH ( distribution_key = 'a' ); --列 a と b を分散キーとして設定します。システムは列 a と b の値に対してハッシュ操作を行い、次に剰余演算を行います。数式は hash(a,b) % shard_count = shard_id です。同じ結果のデータは同じシャードに分散されます。 CREATE TABLE tbl ( a int NOT NULL, b text NOT NULL ) WITH ( distribution_key = 'a,b' );テーブル作成構文 (すべてのバージョンでサポート):
--列 a を分散キーとして設定します。システムは列 a の値に対してハッシュ操作を行い、次に剰余演算を行います。数式は hash(a) % shard_count = shard_id です。同じ結果のデータは同じシャードに分散されます。 begin; create table tbl ( a int not null, b text not null ); call set_table_property('tbl', 'distribution_key', 'a'); commit; --列 a と b を分散キーとして設定します。システムは列 a と b の値に対してハッシュ操作を行い、次に剰余演算を行います。数式は hash(a,b) % shard_count = shard_id です。同じ結果のデータは同じシャードに分散されます。 begin; create table tbl ( a int not null, b text not null ); call set_table_property('tbl', 'distribution_key', 'a,b'); commit;
次の図は、データ分散を示しています。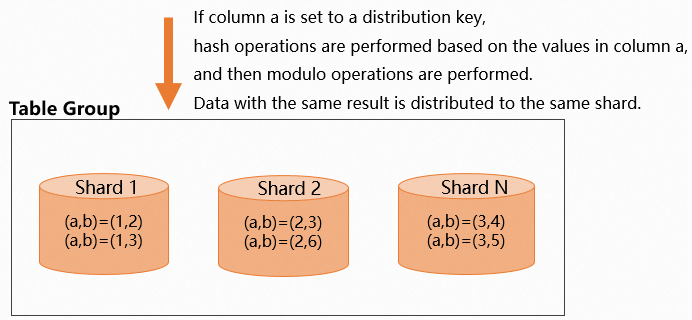 分散キーを設定する際は、指定したフィールドのデータが均等に分散されていることを確認してください。Hologres のシャード数は、ワーカーノードの数に関連しています。詳細については、「用語」をご参照ください。データ分布が不均一なフィールドを分散キーとして設定すると、データが少数のシャードに集中します。これにより、計算の大部分が少数のワーカーノードによって実行されることになり、ロングテール効果を引き起こし、クエリ効率を低下させる可能性があります。データスキューのトラブルシューティングと対処方法の詳細については、「ワーカースキュー関係の表示」をご参照ください。
分散キーを設定する際は、指定したフィールドのデータが均等に分散されていることを確認してください。Hologres のシャード数は、ワーカーノードの数に関連しています。詳細については、「用語」をご参照ください。データ分布が不均一なフィールドを分散キーとして設定すると、データが少数のシャードに集中します。これにより、計算の大部分が少数のワーカーノードによって実行されることになり、ロングテール効果を引き起こし、クエリ効率を低下させる可能性があります。データスキューのトラブルシューティングと対処方法の詳細については、「ワーカースキュー関係の表示」をご参照ください。
分散キーを設定しない
分散キーを設定しない場合、データはすべてのシャードにランダムに分散されます。これは、同一のレコードが同じシャードまたは異なるシャードに格納される可能性があることを意味します。以下に例を示します。
--分散キーを設定しません。
begin;
create table tbl (
a int not null,
b text not null
);
commit;次の図は、データ分散を示しています。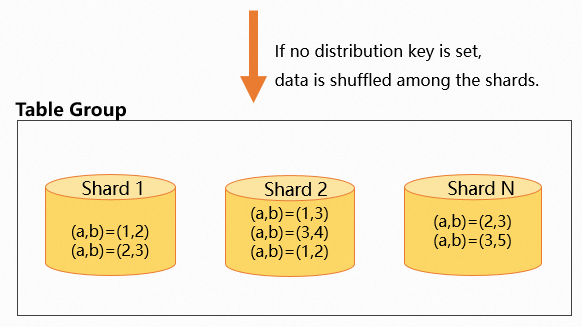
GROUP BY 集計シナリオでの分散キーの設定
`GROUP BY` 集計シナリオでは、グループ化されたフィールドが分散キーでない場合、計算中にデータを再分散する必要があります。したがって、`GROUP BY` 句で頻繁に使用されるフィールドを分散キーとして設定できます。これにより、データはすでにシャード内で集約されているため、シャード間のデータ再分散が減り、クエリパフォーマンスが向上します。次の例は、`GROUP BY` 集計シナリオで分散キーを設定する方法を示しています。
テーブル作成構文 (Hologres V2.1 以降でサポート):
CREATE TABLE agg_tbl ( a int NOT NULL, b int NOT NULL ) WITH ( distribution_key = 'a' ); --クエリ例: 列 a に対して集計クエリを実行します。 select a,sum(b) from agg_tbl group by a;テーブル作成構文 (すべてのバージョンでサポート):
begin; create table agg_tbl ( a int not null, b int not null ); call set_table_property('agg_tbl', 'distribution_key', 'a'); commit; --クエリ例: 列 a に対して集計クエリを実行します。 select a,sum(b) from agg_tbl group by a;
`EXPLAIN SQL` 文を実行して実行計画を表示します。実行計画の結果には redistribution オペレーターが含まれていません。これは、データが再分散されていないことを示します。
2 つのテーブルの結合シナリオでの分散キーの設定
2 つのテーブルの JOIN フィールドを分散キーとして設定
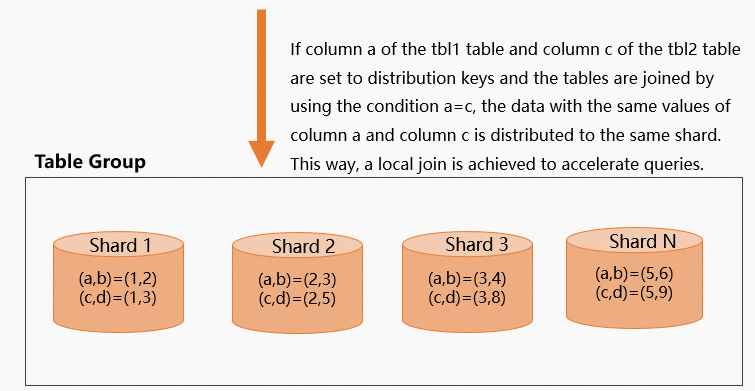
2 つのテーブルの結合シナリオでは、各テーブルの `JOIN` フィールドをその分散キーとして設定すると、同じ `JOIN` フィールド値を持つデータが同じシャードに分散されます。これにより、Local Join が有効になり、クエリが高速化されます。次の例は、`JOIN` フィールドを分散キーとして設定する方法を示しています。
テーブル作成用の DDL 文。
テーブル作成構文 (Hologres V2.1 以降でサポート):
--tbl1 は列 a で分散され、tbl2 は列 c で分散されます。tbl1 と tbl2 が a=c の条件で結合されると、対応するデータは同じシャードに分散されます。このクエリは Local Join によって高速化できます。 BEGIN; CREATE TABLE tbl1 ( a int NOT NULL, b text NOT NULL ) WITH ( distribution_key = 'a' ); CREATE TABLE tbl2 ( c int NOT NULL, d text NOT NULL ) WITH ( distribution_key = 'c' ); COMMIT;テーブル作成構文 (すべてのバージョンでサポート):
--tbl1 は列 a で分散され、tbl2 は列 c で分散されます。tbl1 と tbl2 が a=c の条件で結合されると、対応するデータは同じシャードに分散されます。このクエリは Local Join によって高速化できます。 begin; create table tbl1( a int not null, b text not null ); call set_table_property('tbl1', 'distribution_key', 'a'); create table tbl2( c int not null, d text not null ); call set_table_property('tbl2', 'distribution_key', 'c'); commit;
クエリ文。
select * from tbl1 join tbl2 on tbl1.a=tbl2.c;
次の図は、データ分散を示しています。
 `EXPLAIN SQL` 文を実行して実行計画を表示します。実行計画の結果には
`EXPLAIN SQL` 文を実行して実行計画を表示します。実行計画の結果には redistributionオペレーターが含まれていません。これは、データが再分散されていないことを示します。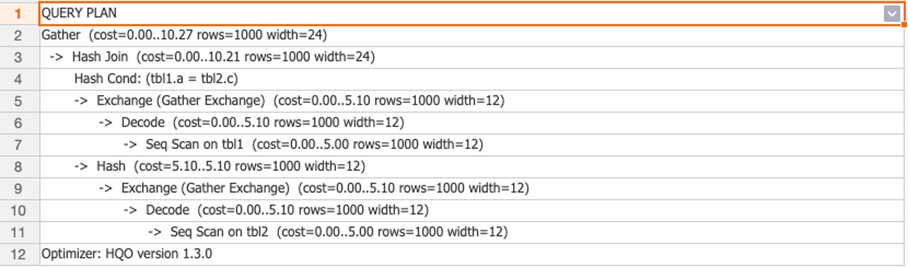
JOIN フィールドが両方のテーブルの分散キーとして使用されていない場合
2 つのテーブルの結合シナリオで、各テーブルの `JOIN` フィールドがその分散キーとして設定されていない場合、クエリ中にデータがシャード間でシャッフルされます。実行計画は、2 つのテーブルのサイズに基づいて、シャッフルを実行するかブロードキャストを実行するかを決定します。次の例では、
tbl1の分散キーはフィールドaで、tbl2の分散キーはフィールドdです。`JOIN` 条件はa=cです。フィールドcのデータは各シャード間でシャッフルされるため、クエリ効率が低下します。テーブル作成用の DDL 文。
テーブル作成構文 (Hologres V2.1 以降でサポート):
BEGIN; CREATE TABLE tbl1 ( a int NOT NULL, b text NOT NULL ) WITH ( distribution_key = 'a' ); CREATE TABLE tbl2 ( c int NOT NULL, d text NOT NULL ) WITH ( distribution_key = 'd' ); COMMIT;テーブル作成構文 (すべてのバージョンでサポート):
begin; create table tbl1( a int not null, b text not null ); call set_table_property('tbl1', 'distribution_key', 'a'); create table tbl2( c int not null, d text not null ); call set_table_property('tbl2', 'distribution_key', 'd'); commit;
クエリ文。
select * from tbl1 join tbl2 on tbl1.a=tbl2.c;
次の図は、データ分散を示しています。
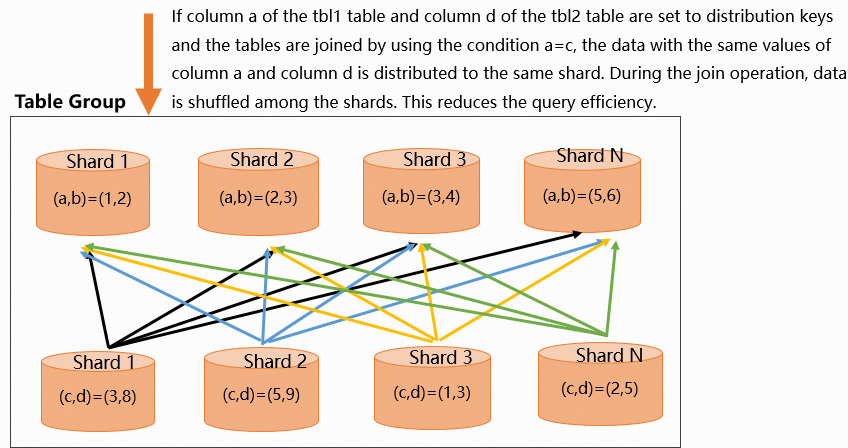 `EXPLAIN SQL` 文を実行して実行計画を表示します。実行計画の結果には
`EXPLAIN SQL` 文を実行して実行計画を表示します。実行計画の結果には redistributionオペレーターが含まれています。これは、データが再分散されており、分散キーが適切に設定されていないことを示します。分散キーの再設定を検討する必要があります。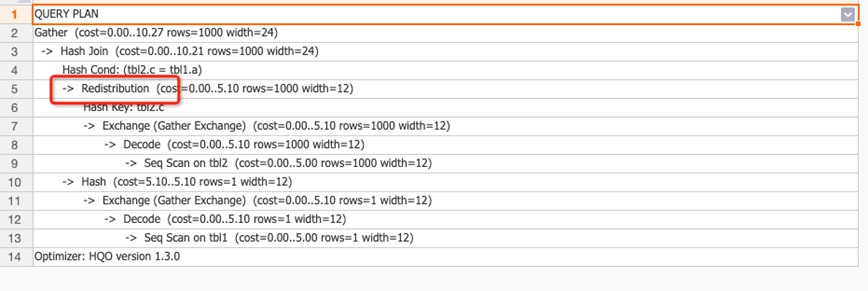
複数テーブルの結合シナリオでの分散キーの設定
複数テーブルの結合シナリオは複雑です。次の原則に従うことができます。
すべてのテーブルの `JOIN` フィールドが同じ場合は、各テーブルの `JOIN` フィールドをその分散キーとして設定します。
テーブルの `JOIN` フィールドが異なる場合は、大きなテーブル間の `JOIN` を優先します。大きなテーブルの `JOIN` フィールドをそれらの分散キーとして設定します。
次の例では、いくつかのケースについて説明します。このトピックでは、3 つのテーブルの結合を例として使用します。同じ原則が、3 つ以上のテーブルが関与する結合にも適用されます。
ケース 1:3 つのテーブルすべての JOIN フィールドが同じ
`JOIN` フィールドが同じ 3 つのテーブルの結合シナリオでは、各テーブルの `JOIN` フィールドをその分散キーとして設定するだけで、Local Join を有効にできます。
テーブル作成構文 (Hologres V2.1 以降でサポート):
BEGIN; CREATE TABLE join_tbl1 ( a int NOT NULL, b text NOT NULL ) WITH ( distribution_key = 'a' ); CREATE TABLE join_tbl2 ( a int NOT NULL, d text NOT NULL, e text NOT NULL ) WITH ( distribution_key = 'a' ); CREATE TABLE join_tbl3 ( a int NOT NULL, e text NOT NULL, f text NOT NULL, g text NOT NULL ) WITH ( distribution_key = 'a' ); COMMIT; --3 テーブル結合クエリ SELECT * FROM join_tbl1 INNER JOIN join_tbl2 ON join_tbl2.a = join_tbl1.a INNER JOIN join_tbl3 ON join_tbl2.a = join_tbl3.a;テーブル作成構文 (すべてのバージョンでサポート):
begin; create table join_tbl1( a int not null, b text not null ); call set_table_property('join_tbl1', 'distribution_key', 'a'); create table join_tbl2( a int not null, d text not null, e text not null ); call set_table_property('join_tbl2', 'distribution_key', 'a'); create table join_tbl3( a int not null, e text not null, f text not null, g text not null ); call set_table_property('join_tbl3', 'distribution_key', 'a'); commit; --3 テーブル結合クエリ SELECT * FROM join_tbl1 INNER JOIN join_tbl2 ON join_tbl2.a = join_tbl1.a INNER JOIN join_tbl3 ON join_tbl2.a = join_tbl3.a;
`EXPLAIN SQL` 文を実行して実行計画を表示します。実行計画の結果は次のことを示しています。
プランには
redistributionオペレーターが含まれていません。これは、データが再分散されず、Local Join が実行されることを示します。exchangeオペレーターは、データがファイルレベルからシャードレベルに集約されることを示します。これにより、対応するシャードのデータのみが必要となり、クエリ効率が向上します。
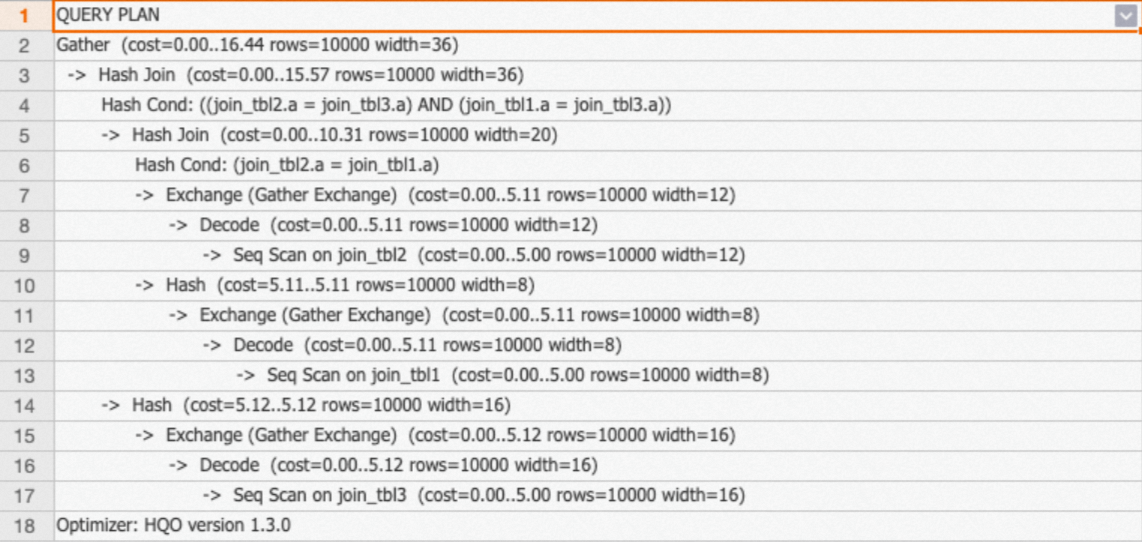
ケース 2:3 つのテーブルの JOIN フィールドが異なる
一部のビジネスシナリオでは、複数テーブルの結合における `JOIN` フィールドが異なる場合があります。この場合、次の原則に基づいて分散キーを設定できます。
コアとなる最適化の原則は、大きなテーブル間の `JOIN` を優先し、それらの `JOIN` フィールドを分散キーとして設定することです。小さなテーブルはデータ量が少ないため、最適化の重要度は低くなります。
テーブルのデータ量がほぼ同じ場合は、`GROUP BY` 句で頻繁に使用される `JOIN` フィールドを分散キーとして設定できます。
次の例では、3 つのテーブルが結合されますが、それらの `JOIN` フィールドはすべて同じではありません。この場合、最大のテーブルが関与する結合を最適化するために分散キーを設定する必要があります。
join_tbl_1テーブルには 1,000 万レコードがあり、join_tbl_2とjoin_tbl_3にはそれぞれ 100 万レコードがあります。主な最適化対象はjoin_tbl_1です。テーブル作成構文 (Hologres V2.1 以降でサポート):
BEGIN; -- join_tbl_1 には 1,000 万レコードが含まれています。 CREATE TABLE join_tbl_1 ( a int NOT NULL, b text NOT NULL ) WITH ( distribution_key = 'a' ); -- join_tbl_2 には 100 万レコードが含まれています。 CREATE TABLE join_tbl_2 ( a int NOT NULL, d text NOT NULL, e text NOT NULL ) WITH ( distribution_key = 'a' ); -- join_tbl_3 には 100 万レコードが含まれています。 CREATE TABLE join_tbl_3 ( a int NOT NULL, e text NOT NULL, f text NOT NULL, g text NOT NULL ); WITH ( distribution_key = 'a' ); COMMIT; --JOIN キーが異なる場合は、最大のテーブルの JOIN キーを分散キーとして選択します。 SELECT * FROM join_tbl_1 INNER JOIN join_tbl_2 ON join_tbl_2.a = join_tbl_1.a INNER JOIN join_tbl_3 ON join_tbl_2.d = join_tbl_3.f;テーブル作成構文 (すべてのバージョンでサポート):
begin; --join_tbl_1 には 1,000 万レコードが含まれています。 create table join_tbl_1( a int not null, b text not null ); call set_table_property('join_tbl_1', 'distribution_key', 'a'); --join_tbl_2 には 100 万レコードが含まれています。 create table join_tbl_2( a int not null, d text not null, e text not null ); call set_table_property('join_tbl_2', 'distribution_key', 'a'); --join_tbl_3 には 100 万レコードが含まれています。 create table join_tbl_3( a int not null, e text not null, f text not null, g text not null ); --call set_table_property('join_tbl_3', 'distribution_key', 'a'); commit; --JOIN キーが異なる場合は、最大のテーブルの JOIN キーを分散キーとして選択します。 SELECT * FROM join_tbl_1 INNER JOIN join_tbl_2 ON join_tbl_2.a = join_tbl_1.a INNER JOIN join_tbl_3 ON join_tbl_2.d = join_tbl_3.f;
`EXPLAIN SQL` 文を実行して実行計画を表示します。実行計画は次のことを示しています。
プランには、
join_tbl_2テーブルとjoin_tbl_3テーブルの間にredistributionオペレーターが含まれています。これは、join_tbl_3が小さなテーブルであり、その `JOIN` フィールドが分散キーと異なるためです。したがって、そのデータは再分散される必要があります。プランには、
join_tbl_1テーブルとjoin_tbl_2テーブルの間にredistributionオペレーターが含まれていません。これは、各テーブルの `JOIN` フィールドがその分散キーとして設定されているためです。これにより、データの再分散なしで Local Join を実行できます。

使用例
テーブル作成構文 (Hologres V2.1 以降でサポート):
--単一テーブルに分散キーを設定します。 CREATE TABLE tbl ( a int NOT NULL, b text NOT NULL ) WITH ( distribution_key = 'a' ); --複数の分散キーを設定します。 CREATE TABLE tbl ( a int NOT NULL, b text NOT NULL ) WITH ( distribution_key = 'a,b' ); --JOIN シナリオでは、JOIN キーを分散キーとして設定します。 BEGIN; CREATE TABLE tbl1 ( a int NOT NULL, b text NOT NULL ) WITH ( distribution_key = 'a' ); CREATE TABLE tbl2 ( c int NOT NULL, d text NOT NULL ) WITH ( distribution_key = 'c' ); COMMIT; SELECT b, count(*) FROM tbl1 JOIN tbl2 ON tbl1.a = tbl2.c GROUP BY b;テーブル作成構文 (すべてのバージョンでサポート):
--1 つの分散キーを設定します。 begin; create table tbl (a int not null, b text not null); call set_table_property('tbl', 'distribution_key', 'a'); commit; --複数の分散キーを設定します。 begin; create table tbl (a int not null, b text not null); call set_table_property('tbl', 'distribution_key', 'a,b'); commit; --JOIN シナリオでは、JOIN キーを分散キーとして設定します。 begin; create table tbl1(a int not null, b text not null); call set_table_property('tbl1', 'distribution_key', 'a'); create table tbl2(c int not null, d text not null); call set_table_property('tbl2', 'distribution_key', 'c'); commit; select b, count(*) from tbl1 join tbl2 on tbl1.a = tbl2.c group by b;
参考資料
クエリシナリオに基づいて適切なテーブルプロパティを設定する方法のガイダンスについては、「テーブル作成とチューニングのためのシナリオベースのガイド」をご参照ください。
Hologres 内部テーブルのパフォーマンスをチューニングするためのベストプラクティスの詳細については、「クエリパフォーマンスの最適化」をご参照ください。