SQL クエリのパフォーマンスが低い、または予期しない結果が返される場合、Hologres の EXPLAIN および EXPLAIN ANALYZE コマンドを使用してクエリの実行計画を分析できます。これらのコマンドは、Hologres がクエリをどのように実行するかを理解するのに役立ち、クエリやデータベース構造を調整してパフォーマンスを向上させることができます。このトピックでは、Hologres で EXPLAIN と EXPLAIN ANALYZE を使用して実行計画を表示する方法と、各オペレーターの意味について説明します。
実行計画の概要
Hologres では、クエリオプティマイザー (QO) がすべての SQL 文に対して実行計画を生成します。その後、クエリエンジン (QE) がこの計画を使用して最終的な計画を作成・実行し、クエリ結果を返します。実行計画には、統計情報、実行オペレーター、オペレーターの実行時間などの情報が含まれます。優れた実行計画は、より少ないリソースを使用しながら、より速く結果を返します。したがって、実行計画は SQL の問題を明らかにし、的を絞った最適化を導くことができるため、日々の開発に不可欠です。
Hologres は PostgreSQL と互換性があります。EXPLAIN および EXPLAIN ANALYZE 構文を使用して SQL の実行計画を理解できます。
-
EXPLAIN: SQL の特性に基づいて QO の推定実行計画を表示します。これは実際の実行計画ではありませんが、クエリパフォーマンスの有用な参考情報を提供します。
-
EXPLAIN ANALYZE: 実際の実行時計画を表示します。EXPLAIN と比較して、より多くのリアルタイム実行詳細が含まれており、実行オペレーターとその実行時間を正確に反映します。この情報を使用して、対象を絞った SQL 最適化を実行できます。
Hologres V1.3.4x 以降、EXPLAIN および EXPLAIN ANALYZE によって表示される実行計画は、より明確で読みやすくなっています。このドキュメントは V1.3.4x に基づいています。インスタンスを V1.3.4x 以降にアップグレードすることを推奨します。
EXPLAIN
-
構文
EXPLAINコマンドは、オプティマイザーの推定実行計画を表示します。構文は次のとおりです:EXPLAIN <sql>; -
例
次の例では、TPC-H クエリを使用します。
説明この例は TPC-H クエリを参照していますが、公式の TPC-H ベンチマーク結果を表すものではありません。
EXPLAIN SELECT l_returnflag, l_linestatus, sum(l_quantity) AS sum_qty, sum(l_extendedprice) AS sum_base_price, sum(l_extendedprice * (1 - l_discount)) AS sum_disc_price, sum(l_extendedprice * (1 - l_discount) * (1 + l_tax)) AS sum_charge, avg(l_quantity) AS avg_qty, avg(l_extendedprice) AS avg_price, avg(l_discount) AS avg_disc, count(*) AS count_order FROM lineitem WHERE l_shipdate <= date '1998-12-01' - interval '120' day GROUP BY l_returnflag, l_linestatus ORDER BY l_returnflag, l_linestatus; -
出力
QUERY PLAN Sort (cost=0.00..7795.30 rows=3 width=80) Sort Key: l_returnflag, l_linestatus -> Gather (cost=0.00..7795.27 rows=3 width=80) -> Project (cost=0.00..7795.27 rows=3 width=80) -> Project (cost=0.00..7794.27 rows=3 width=104) -> Final HashAggregate (cost=0.00..7793.27 rows=3 width=76) Group Key: l_returnflag, l_linestatus -> Redistribution (cost=0.00..7792.95 rows=1881 width=76) Hash Key: l_returnflag, l_linestatus -> Partial HashAggregate (cost=0.00..7792.89 rows=1881 width=76) Group Key: l_returnflag, l_linestatus -> Local Gather (cost=0.00..7791.81 rows=44412 width=76) -> Decode (cost=0.00..7791.80 rows=44412 width=76) -> Partial HashAggregate (cost=0.00..7791.70 rows=44412 width=76) Group Key: l_returnflag, l_linestatus -> Project (cost=0.00..3550.73 rows=584421302 width=33) -> Project (cost=0.00..2585.43 rows=584421302 width=33) -> Index Scan using Clustering_index on lineitem (cost=0.00..261.36 rows=584421302 width=25) Segment Filter: (l_shipdate <= '1998-08-03 00:00:00+08'::timestamp with time zone) Cluster Filter: (l_shipdate <= '1998-08-03 00:00:00+08'::timestamp with time zone) -
出力の説明
実行計画は下から上に読み取られます。各矢印 (->) はノードを表し、各子ノードは使用されたオペレーターや推定行数などの詳細を返します。主要なオペレーターは次のとおりです:
パラメータ
説明
cost
オペレーターの推定実行時間です。親ノードのコストには、その子ノードのコストが含まれます。
..で区切られた起動コストと合計コストの両方を示します。-
起動コスト:出力フェーズが始まる前のコスト。
-
合計コスト:オペレーターが完了まで実行された場合の推定合計コスト。
例えば、上記の Final HashAggregate ノードでは、起動コストは
0.00、合計コストは7793.27です。rows
推定される出力行数で、主に統計に基づいています。
スキャン操作の場合、デフォルトの推定値は
1000です。説明rows=1000が表示される場合、テーブル統計が古い可能性があります。analyze <tablename>を実行して統計を更新してください。width
推定される平均出力行の幅 (バイト単位) です。値が大きいほど、列の幅が広いことを示します。
-
EXPLAIN ANALYZE
-
構文
EXPLAIN ANALYZEコマンドは、実際の実行計画とオペレーターの実行時間を表示し、SQL のパフォーマンス問題を診断するのに役立ちます。構文は次のとおりです:EXPLAIN ANALYZE <sql>; -
例
次の例では、TPC-H クエリを使用します。
EXPLAIN ANALYZE SELECT l_returnflag, l_linestatus, sum(l_quantity) AS sum_qty, sum(l_extendedprice) AS sum_base_price, sum(l_extendedprice * (1 - l_discount)) AS sum_disc_price, sum(l_extendedprice * (1 - l_discount) * (1 + l_tax)) AS sum_charge, avg(l_quantity) AS avg_qty, avg(l_extendedprice) AS avg_price, avg(l_discount) AS avg_disc, count(*) AS count_order FROM lineitem WHERE l_shipdate <= date '1998-12-01' - interval '120' day GROUP BY l_returnflag, l_linestatus ORDER BY l_returnflag, l_linestatus; -
出力
QUERY PLAN Sort (cost=0.00..7795.30 rows=3 width=80) Sort Key: l_returnflag, l_linestatus [id=21 dop=1 time=2427/2427/2427ms rows=4(4/4/4) mem=3/3/3KB open=2427/2427/2427ms get_next=0/0/0ms] -> Gather (cost=0.00..7795.27 rows=3 width=80) [20:1 id=100003 dop=1 time=2426/2426/2426ms rows=4(4/4/4) mem=1/1/1KB open=0/0/0ms get_next=2426/2426/2426ms] -> Project (cost=0.00..7795.27 rows=3 width=80) [id=19 dop=20 time=2427/2426/2425ms rows=4(1/0/0) mem=87/87/87KB open=2427/2425/2425ms get_next=1/0/0ms] -> Project (cost=0.00..7794.27 rows=0 width=104) -> Final HashAggregate (cost=0.00..7793.27 rows=3 width=76) Group Key: l_returnflag, l_linestatus [id=16 dop=20 time=2427/2425/2424ms rows=4(1/0/0) mem=574/570/569KB open=2427/2425/2424ms get_next=1/0/0ms] -> Redistribution (cost=0.00..7792.95 rows=1881 width=76) Hash Key: l_returnflag, l_linestatus [20:20 id=100002 dop=20 time=2427/2424/2423ms rows=80(20/4/0) mem=3528/1172/584B open=1/0/0ms get_next=2426/2424/2423ms] -> Partial HashAggregate (cost=0.00..7792.89 rows=1881 width=76) Group Key: l_returnflag, l_linestatus [id=12 dop=20 time=2428/2357/2256ms rows=80(4/4/4) mem=574/574/574KB open=2428/2357/2256ms get_next=1/0/0ms] -> Local Gather (cost=0.00..7791.81 rows=44412 width=76) [id=11 dop=20 time=2427/2356/2255ms rows=936(52/46/44) mem=7/6/6KB open=0/0/0ms get_next=2427/2356/2255ms pull_dop=9/9/9] -> Decode (cost=0.00..7791.80 rows=44412 width=76) [id=8 dop=234 time=2435/1484/5ms rows=936(4/4/4) mem=0/0/0B open=2435/1484/5ms get_next=4/0/0ms] -> Partial HashAggregate (cost=0.00..7791.70 rows=44412 width=76) Group Key: l_returnflag, l_linestatus [id=5 dop=234 time=2435/1484/3ms rows=936(4/4/4) mem=313/312/168KB open=2435/1484/3ms get_next=0/0/0ms] -> Project (cost=0.00..3550.73 rows=584421302 width=33) [id=4 dop=234 time=2145/1281/2ms rows=585075720(4222846/2500323/3500) mem=142/141/69KB open=10/1/0ms get_next=2145/1280/2ms] -> Project (cost=0.00..2585.43 rows=584421302 width=33) [id=3 dop=234 time=582/322/2ms rows=585075720(4222846/2500323/3500) mem=142/142/69KB open=10/1/0ms get_next=582/320/2ms] -> Index Scan using Clustering_index on lineitem (cost=0.00..261.36 rows=584421302 width=25) Segment Filter: (l_shipdate <= '1998-08-03 00:00:00+08'::timestamp with time zone) Cluster Filter: (l_shipdate <= '1998-08-03 00:00:00+08'::timestamp with time zone) [id=2 dop=234 time=259/125/1ms rows=585075720(4222846/2500323/3500) mem=1418/886/81KB open=10/1/0ms get_next=253/124/0ms] ADVICE: [node id : 1000xxx] distribution key miss match! table lineitem defined distribution keys : l_orderkey; request distribution columns : l_returnflag, l_linestatus; shuffle data skew in different shards! max rows is 20, min rows is 0 Query id:[300200511xxxx] ======================cost====================== Total cost:[2505] ms Optimizer cost:[47] ms Init gangs cost:[4] ms Build gang desc table cost:[2] ms Start query cost:[18] ms - Wait schema cost:[0] ms - Lock query cost:[0] ms - Create dataset reader cost:[0] ms - Create split reader cost:[0] ms Get the first block cost:[2434] ms Get result cost:[2434] ms ====================resource==================== Memory: 921(244/230/217) MB, straggler worker id: 72969760xxx CPU time: 149772(38159/37443/36736) ms, straggler worker id: 72969760xxx Physical read bytes: 3345(839/836/834) MB, straggler worker id: 72969760xxx Read bytes: 41787(10451/10446/10444) MB, straggler worker id: 72969760xxx DAG instance count: 41(11/10/10), straggler worker id: 72969760xxx Fragment instance count: 275(70/68/67), straggler worker id: 72969760xxx -
出力の説明
EXPLAIN ANALYZEコマンドは、実際の実行パスをオペレーターのツリーとして表示し、各ステージの詳細な実行時情報を含みます。出力には、QUERY PLAN、ADVICE、コストの内訳、リソース消費の 4 つの主要セクションが含まれます。
QUERY PLAN
QUERY PLAN セクションには、各オペレーターの詳細な実行情報が表示されます。EXPLAIN と同様に、EXPLAIN ANALYZE のクエリ計画は下から上に読み取ります。各矢印 (->) はノードを表します。
例 | 説明 |
(cost=0.00..2585.43 rows=584421302 width=33) |
これらの値は、実際の測定値ではなく、オプティマイザーの推定値を表します。意味は EXPLAIN と同じです。
|
[20:20 id=100002 dop=20 time=2427/2424/2423ms rows=80(20/4/0) mem=3528/1172/584B open=1/0/0ms get_next=2426/2424/2423ms] |
これらの値は、実際の実行時の測定値を表します。
|
単一の SQL 文には複数のオペレーターが含まれる可能性があるため、次のセクションでは各オペレーターの詳細な説明を提供します。詳細については、「オペレーターの意味」をご参照ください。
time、rows、mem の値については、次の点にご注意ください:
-
オペレーターの時間値には、その子オペレーターからの累積時間が含まれます。オペレーターの実際の時間を特定するには、子オペレーターの時間を差し引くことができます。
-
rows と mem の値は各オペレーターで独立しており、累積されません。
ADVICE
ADVICE セクションには、現在の EXPLAIN ANALYZE の結果に基づいた自動チューニングの提案が含まれています:
-
分散キー、クラスタリングキー、またはビットマップインデックスを設定するための提案。例:
Table xxx misses bitmap index。 -
テーブル統計の欠落:
Table xxx Miss Stats! please run 'analyze xxx';。 -
データスキューの可能性:
shuffle data xxx in different shards! max rows is 20, min rows is 0。
このアドバイスは、現在の EXPLAIN ANALYZE の結果のみに基づいており、常に適用できるとは限りません。アクションを実行する前に、特定のビジネスシナリオを分析する必要があります。
コストと時間消費
コストセクションでは、クエリの合計時間と各フェーズの詳細なタイミングが表示されます。この情報を使用して、パフォーマンスのボトルネックを特定できます。
Total cost:クエリの総実行時間 (ミリ秒) です。これには以下のコストが含まれます:
-
Optimizer cost:QO が実行計画の生成に費やす時間 (ミリ秒) です。
-
Build gang desc table cost:QO の実行計画を実行エンジンが必要とするデータ構造に変換するために必要な時間 (ミリ秒) です。
-
Init gangs cost:クエリが開始される前に、QO の実行計画を前処理し、実行エンジンにリクエストを送信するために必要な時間 (ミリ秒) です。
-
Start query cost:Init gangs が完了してから実際のクエリ実行が始まるまでの初期化時間です。これには、スキーマの整合、ロック、その他のセットアッププロセスが含まれます:
-
Wait schema cost:ストレージエンジン (SE) とフロントエンド (FE) がスキーマバージョンを整合させるために必要な時間です。特にパーティション化された親テーブルでデータ定義言語 (DDL) 操作が頻繁に行われる場合、SE の処理が遅いと高遅延が発生します。これにより、データ書き込みやクエリが遅くなる可能性があります。DDL の頻度を最適化することを検討できます。
-
Lock query cost:クエリロックの取得に費やされた時間です。値が高い場合は、ロックの競合を示します。
-
Create dataset reader cost:インデックスデータリーダーの作成に必要な時間です。値が高い場合は、キャッシュミスを示している可能性があります。
-
Create split reader cost:ファイルを開くために必要な時間です。値が高い場合は、メタデータキャッシュのミスと高い I/O オーバーヘッドを示唆します。
-
-
Get result cost:Start query フェーズが完了してからすべての結果が返されるまでの時間 (ミリ秒) です。これには、Get the first block cost が含まれます。
-
Get the first block cost:Start query フェーズが完了してから最初のレコードバッチが返されるまでの時間です。このメトリックは、Hash Agg などのトップオペレーターが、出力を生成する前に完全な下流データを必要とする場合、Get result cost とほぼ一致します。ストリーミング結果を伴うフィルタリングされたクエリの場合、この値は通常、データ量に応じて Get result cost よりもはるかに低くなります。
-
リソース消費
リソースセクションでは、クエリのリソース使用量が total(max/avg/min) 形式で表示されます。これには、総リソース消費量と、ワーカーごとの最大、平均、最小値が含まれます。
Hologres は複数のワーカーノードを持つ分散エンジンであるため、各ワーカーが処理を完了した後に結果がマージされます。リソース消費量は total(max worker/avg worker/min worker) として報告されます:
-
total:クエリの総リソース消費量。
-
max:単一のワーカーノードによる最大消費量。
-
avg:ワーカーノードあたりの平均消費量。総消費量をワーカー数で割った値です。
-
min:単一のワーカーノードによる最小消費量。
次のセクションでは、リソースメトリックの詳細な説明を提供します:
メトリック | 説明 |
Memory |
クエリ実行中に消費された合計メモリ。合計メモリに加えて、ワーカーノードごとの最大、平均、最小値が含まれます。 |
CPU time |
SQL クエリ ステートメントによって消費される合計 CPU 時間。これは正確ではありません。 単位: ミリ秒。 SQL クエリ文によって消費された合計 CPU 時間ですが、これは正確ではありません。単位:ミリ秒。クエリ実行中に消費された合計 CPU 時間 (ミリ秒、概算) です。すべてのコアにわたる累積 CPU 時間を表し、おおよそクエリの複雑さを示します。 |
Physical read bytes |
ディスクから読み取られたデータ (バイト単位) です。クエリ結果がキャッシュされていない場合に発生します。 |
Read bytes |
クエリ実行中に読み取られた合計バイト数 (バイト単位) で、物理読み取りとキャッシュデータの両方を含みます。処理された合計データを反映します。 |
Affected rows |
DML 操作によって影響を受けた行数です。DML 文の場合にのみ表示されます。 |
Dag instance count |
クエリ計画内の DAG インスタンスの数です。値が高いほど、クエリの複雑さと並列性が高いことを示します。 |
Fragment instance count |
クエリ計画内のフラグメントインスタンスの数です。値が高いほど、実行計画とファイルが多いことを示します。 |
straggler_worker_id |
このメトリックで最大のリソース消費量を持つワーカーノードの ID です。 |
オペレーターの意味
SCAN
-
seq scan
Seq Scan オペレーターは、テーブルからデータを順次読み取り、全表スキャンを実行します。テーブル名は
onキーワードの後に続きます。例:通常の内部テーブルをクエリすると、実行計画に Seq Scan オペレーターが表示されます。
EXPLAIN SELECT * FROM public.holo_lineitem_100g;出力:
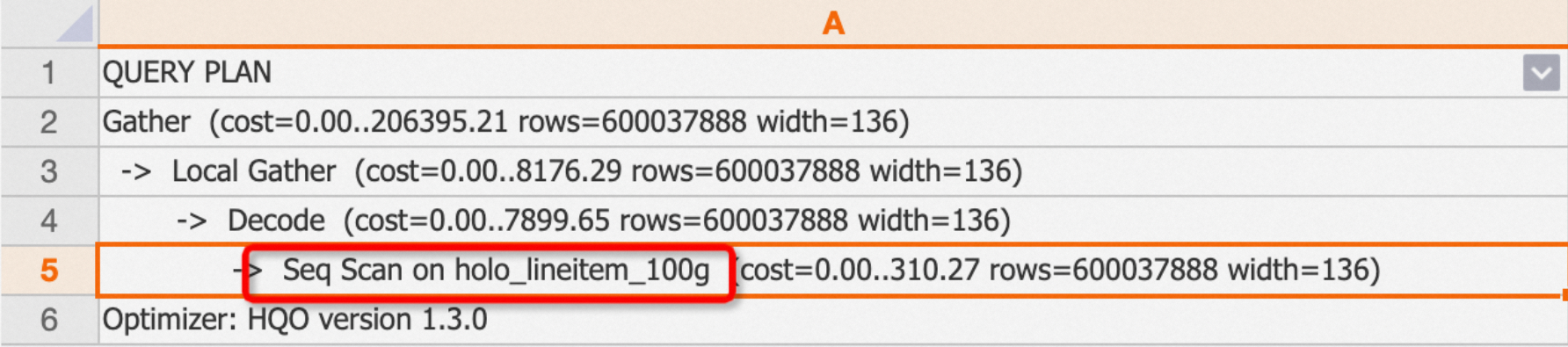
-
パーティションテーブルのクエリ
パーティションテーブルの場合、計画には
Seq Scan on Partitioned Tableオペレーターが表示され、「Partitions selected: x out of y」を使用してスキャンされたパーティションの数を示します。例:パーティション化された親テーブルをクエリし、1 つのパーティションのみがスキャンされる場合。
EXPLAIN SELECT * FROM public.hologres_parent;出力:

-
外部テーブルのクエリ
外部テーブルの場合、計画にはソースを示すために
Foreign Table Typeオペレーターが含まれます。タイプには MaxCompute、OSS、Hologres があります。例:MaxCompute 外部テーブルのクエリ。
EXPLAIN SELECT * FROM public.odps_lineitem_100;出力:

-
-
Index Scan および Index Seek
テーブルスキャンがインデックスにヒットすると、Hologres は行指向または列指向のストレージ形式に基づいて、異なる基盤となるインデックスを使用します。2 つの主要なインデックスタイプは、Clustering_index と Index Seek (pk_index とも呼ばれます) です:
-
Clustering_index:これは、セグメントやクラスタリングなどの機能を持つ列指向テーブルに使用されます。このオペレーターは、クエリがインデックスにヒットするたびに表示されます。
Seq Scan Using Clustering_indexオペレーターは通常、クラスタリングフィルター、セグメントフィルター、ビットマップフィルターなど、一致したインデックスをリストする Filter サブノードと共に表示されます。詳細については、「列ストアの原則」をご参照ください。-
例 1:クエリがインデックスにヒットした場合。
BEGIN; CREATE TABLE column_test ( "id" bigint not null , "name" text not null , "age" bigint not null ); CALL set_table_property('column_test', 'orientation', 'column'); CALL set_table_property('column_test', 'distribution_key', 'id'); CALL set_table_property('column_test', 'clustering_key', 'id'); COMMIT; INSERT INTO column_test VALUES(1,'tom',10),(2,'tony',11),(3,'tony',12); EXPLAIN SELECT * FROM column_test WHERE id>2;出力:
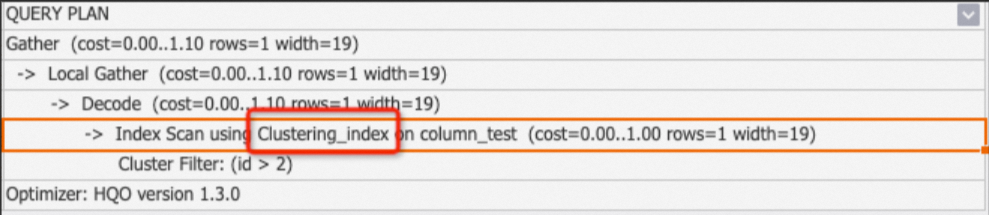
-
例 2:クエリがインデックスにヒットしなかったため、clustering_index は使用されません。
EXPLAIN SELECT * FROM column_test WHERE age>10;出力:

-
-
Index Seek (pk_index とも呼ばれる):これは、主キーインデックスを持つ行指向テーブルに使用されます。主キーを持つ行指向テーブルでのポイントクエリは、通常 Fixed Plan を使用します。ただし、Fixed Plan を使用しないが主キーを持つクエリは pk_index を使用します。詳細については、「行ストアの原則」をご参照ください。
例:行指向テーブルのクエリ。
BEGIN; CREATE TABLE row_test_1 ( id bigint not null, name text not null, class text , PRIMARY KEY (id) ); CALL set_table_property('row_test_1', 'orientation', 'row'); CALL set_table_property('row_test_1', 'clustering_key', 'name'); COMMIT; INSERT INTO row_test_1 VALUES ('1','qqq','3'),('2','aaa','4'),('3','zzz','5'); BEGIN; CREATE TABLE row_test_2 ( id bigint not null, name text not null, class text , PRIMARY KEY (id) ); CALL set_table_property('row_test_2', 'orientation', 'row'); CALL set_table_property('row_test_2', 'clustering_key', 'name'); COMMIT; INSERT INTO row_test_2 VALUES ('1','qqq','3'),('2','aaa','4'),('3','zzz','5'); --primary key index EXPLAIN SELECT * FROM (SELECT id FROM row_test_1 WHERE id = 1) t1 JOIN row_test_2 t2 ON t1.id = t2.id;出力:

-
Filter
Filter オペレーターは、SQL 条件をデータに適用します。通常、seq scan オペレーターの子ノードとして表示され、テーブルスキャン中にフィルターが適用されたかどうか、およびそれらがインデックスにヒットしたかどうかを示します。フィルタータイプは次のとおりです:
-
Filter
計画に「Filter」のみが表示される場合、条件はどのインデックスにもヒットしていません。テーブルのインデックスを確認し、適切なインデックスを追加してクエリのパフォーマンスを向上させることができます。
説明計画に
One-Time Filter: falseが表示される場合、結果セットは空です。例:
BEGIN; CREATE TABLE clustering_index_test ( "id" bigint not null , "name" text not null , "age" bigint not null ); CALL set_table_property('clustering_index_test', 'orientation', 'column'); CALL set_table_property('clustering_index_test', 'distribution_key', 'id'); CALL set_table_property('clustering_index_test', 'clustering_key', 'age'); COMMIT; INSERT INTO clustering_index_test VALUES (1,'tom',10),(2,'tony',11),(3,'tony',12); EXPLAIN SELECT * FROM clustering_index_test WHERE id>2;出力:

-
Segment Filter
Segment Filter は、クエリがセグメントインデックスにヒットしたことを示します。このオペレーターは index_scan と共に表示されます。詳細については、「イベント時間列 (セグメントキー)」をご参照ください。
-
Cluster Filter
Cluster Filter は、クエリがクラスタリングインデックスにヒットしたことを示します。詳細については、「クラスタリングキー」をご参照ください。
-
Bitmap Filter
Bitmap Filter は、クエリがビットマップインデックスにヒットしたことを示します。詳細については、「ビットマップインデックス」をご参照ください。
-
Join Filter
結合操作の後に追加のフィルタリングを適用します。
Decode
Decode オペレーターは、テキストや同様のデータ型の計算を高速化するために、データのデコードまたはエンコードを実行します。
Local Gather および Gather
Hologres では、データはシャード内のファイルとして保存されます。Local Gather オペレーターは、複数のファイルからのデータを単一のシャードにマージします。Gather オペレーターは、複数のシャードからのデータを最終結果にマージします。
例:
EXPLAIN SELECT * FROM public.lineitem;出力:実行計画は、データがスキャンされ、次に Local Gather オペレーターによってシャードレベルでマージされ、最後に Gather オペレーターによって結合されることを示しています。
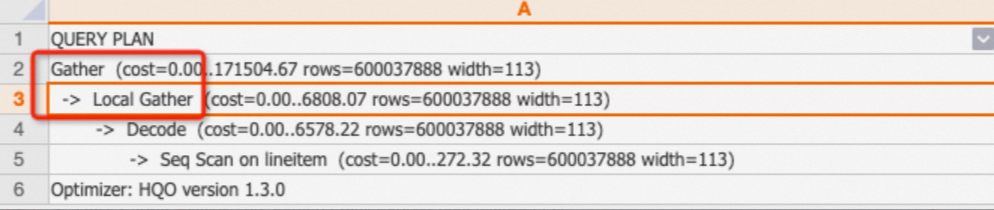
Redistribution
Redistribution オペレーターは、クエリ中にハッシュまたはランダム分布を使用して、シャード間でデータをシャッフルします。
-
Redistribution オペレーターは、次の一般的なシナリオで使用されます:
-
このオペレーターは通常、分散キーが設定されていないか、誤って設定されている場合の join、count distinct (本質的に join)、および group by 操作で表示されます。これにより、データがシャード間でシャッフルされます。複数テーブルの結合では、Redistribution オペレーターはローカル結合機能が利用されなかったことを示し、パフォーマンスの低下につながります。
-
このオペレーターは、結合キーまたは group by キーに、元のフィールドタイプを変更する式 (キャストなど) が含まれている場合に発生し、ローカル結合の使用を妨げます。
-
-
例:
-
例 1:分散キーが一致しない 2 つのテーブルの結合により、Redistribution が発生します。
BEGIN; CREATE TABLE tbl1( a int not null, b text not null ); CALL set_table_property('tbl1', 'distribution_key', 'a'); CREATE TABLE tbl2( c int not null, d text not null ); CALL set_table_property('tbl2', 'distribution_key', 'd'); COMMIT; EXPLAIN SELECT * FROM tbl1 JOIN tbl2 ON tbl1.a=tbl2.c;出力:実行計画には、分散キーが一致しないため Redistribution オペレーターが表示されます。結合条件は
tbl1.a=tbl2.cですが、分散キーは a と d です。これにより、データシャッフルが発生します。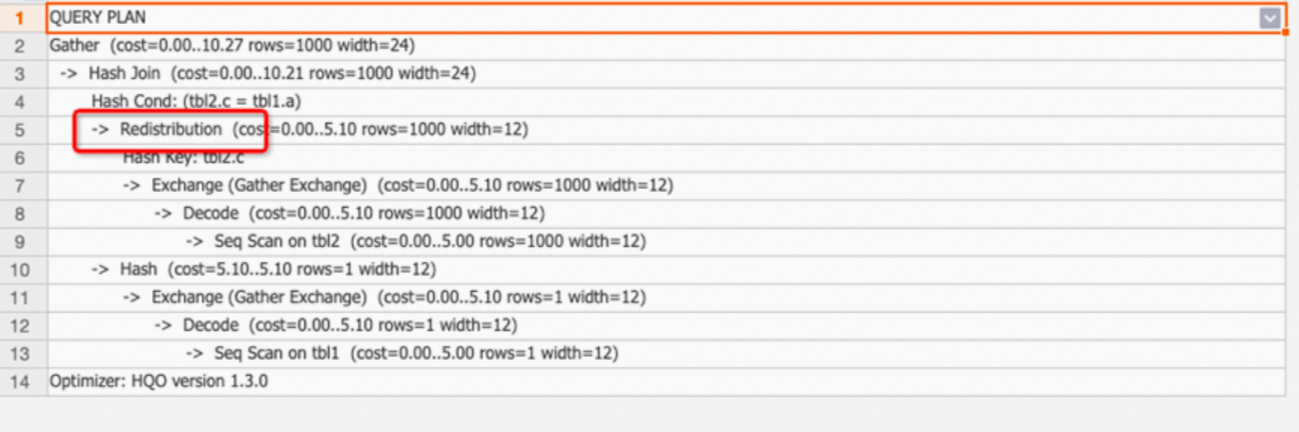
チューニングの提案:Redistribution オペレーターが表示された場合は、分散キーが適切に設定されているかどうかを確認してください。シナリオとガイダンスの詳細については、「分散キー」をご参照ください。
-
例 2:結合キーにフィールドタイプを変更する式が含まれているため、実行計画に Redistribution オペレーターが表示されます。これにより、ローカル結合の使用が妨げられます。

パフォーマンスチューニングのため、式の使用は避けてください。
-
Join
標準的なデータベースと同様に、結合オペレーターは複数のテーブルを結合します。SQL 構文に基づいて、結合はハッシュ結合、ネストされたループ、またはマージ結合に分類されます。
-
Hash Join
ハッシュ結合は、通常は小さい方のテーブルからメモリ内にハッシュテーブルを構築し、結合列の値をハッシュ化します。次に、ハッシュ結合はもう一方のテーブルを行ごとに読み取り、ハッシュ値を計算し、ハッシュテーブルでそれらを検索して一致するデータを返します。ハッシュ結合のタイプは次のとおりです:
タイプ
説明
Hash Left Join
複数テーブルの結合で、システムは左側のテーブルのすべての行を返し、右側のテーブルの対応する行と照合します。左側のテーブルの行に一致が見つからない場合、右側のテーブルの列には null 値が含まれます。
Hash Right Join
右側のテーブルのすべての行と、左側のテーブルの一致する行を返します。一致しない左側のテーブルの行は null を返します。
Hash Inner Join
結合条件を満たす行のみを返します。
Hash Full Join
両方のテーブルのすべての行を返します。一致しない行は、一致しないテーブルに対して null を返します。
Hash Anti Join
一致しない行のみを返し、一般的に NOT EXISTS 条件に使用されます。
Hash Semi Join
一致するものがあれば 1 行を返し、通常は EXISTS 条件から生じます。結果に重複は含まれません。
ハッシュ結合の実行計画を分析する際には、これらの子ノードも確認する必要があります:
-
hash cond:結合条件。例:
hash cond (tmp.a=tmp1.b)。 hash key:複数のシャードでハッシュ計算に使用されるキー。ほとんどの場合、キーは GROUP BY 句のキーを示します。
ハッシュ結合が表示された場合、データ量が少ない方のテーブルがハッシュテーブルとして使用されていることを確認する必要があります。これは次のように確認できます:
-
実行計画では、hash という単語を含むテーブルがハッシュテーブルです。
実行計画を下から上に表示すると、一番下のテーブルがハッシュテーブルです。
チューニングの提案:
-
統計の更新
ハッシュ結合の主要なチューニング原則は、小さい方のテーブルをハッシュテーブルとして使用することです。大きいテーブルをハッシュテーブルとして使用すると、過剰なメモリを消費します。これは通常、テーブルの統計情報が古いために、QO が誤って大きい方のテーブルを選択してしまう場合に発生します。
例:統計情報が古い (rows=1000) ため、100万行を持つ大きいテーブル hash_join_test_2 が、1万行を持つ小さいテーブル hash_join_test_1 の代わりにハッシュテーブルとして使用されます。これにより、クエリの効率が低下します。
BEGIN ; CREATE TABLE public.hash_join_test_1 ( a integer not null, b text not null ); CALL set_table_property('public.hash_join_test_1', 'distribution_key', 'a'); CREATE TABLE public.hash_join_test_2 ( c integer not null, d text not null ); CALL set_table_property('public.hash_join_test_2', 'distribution_key', 'c'); COMMIT ; INSERT INTO hash_join_test_1 SELECT i, i+1 FROM generate_series(1, 10000) AS s(i); INSERT INTO hash_join_test_2 SELECT i, i::text FROM generate_series(10, 1000000) AS s(i); EXPLAIN SELECT * FROM hash_join_test_1 tbl1 JOIN hash_join_test_2 tbl2 ON tbl1.a=tbl2.c;実行計画は、大きい方のテーブル hash_join_test_2 がハッシュテーブルとして使用されていることを示しています:

統計が更新されていない場合は、手動で
analyze <tablename>コマンドを実行できます。例:ANALYZE hash_join_test_1; ANALYZE hash_join_test_2;更新された計画では、正確な行数推定で小さい方のテーブル hash_join_test_1 が正しくハッシュテーブルとして使用されます。

-
結合順序の調整
統計の更新はほとんどの結合問題を解決します。しかし、5 つ以上のテーブルが関わる複雑な複数テーブルの結合では、Hologres の QO は最適な実行計画を選択するためにかなりの時間を費やします。次の Grand Unified Configuration (GUC) パラメーターを使用して、結合順序を制御し、QO のオーバーヘッドを削減できます:
SET optimizer_join_order = '<value>';値のオプション:
値
説明
exhaustive (デフォルト)
アルゴリズムを使用して結合順序を変換し、最適な計画を生成しますが、複数テーブルの結合ではオプティマイザーのオーバーヘッドが増加します。
query
SQL に書かれたとおりに計画を生成し、オプティマイザーによる変更は行いません。QO のオーバーヘッドを削減するために、小規模なテーブル (1億行未満) との複数テーブル結合にのみ適しています。他の結合に影響を与えるため、データベースレベルで設定しないでください。
greedy
貪欲アルゴリズムを使用して、中程度のオプティマイザーオーバーヘッドで結合順序を生成します。
-
-
Nested Loop Join と Materialize
Nested Loop オペレーターは、ネストされたループ結合を実行します。一方のテーブル (外部テーブル) からデータを読み取り、各外部行に対してもう一方のテーブル (内部テーブル) を反復処理します。これにより、事実上デカルト積が計算されます。内部テーブルは通常、実行計画に Materialize オペレーターを表示します。
チューニングの提案:
-
Nested Loop 結合では、内部テーブルは外部テーブルによって駆動されます。各外部行は内部テーブルで一致を検索します。外部の結果セットを小さく保つことで、過剰なリソース消費を避けることができます。
-
非等値結合は通常、Nested Loop 結合を生成します。SQL で非等値結合の使用を避けることができます。
-
Nested Loop 結合の例:
BEGIN; CREATE TABLE public.nestedloop_test_1 ( a integer not null, b integer not null ); CALL set_table_property('public.nestedloop_test_1', 'distribution_key', 'a'); CREATE TABLE public.nestedloop_test_2 ( c integer not null, d text not null ); CALL set_table_property('public.nestedloop_test_2', 'distribution_key', 'c'); COMMIT; INSERT INTO nestedloop_test_1 SELECT i, i+1 FROM generate_series(1, 10000) AS s(i); INSERT INTO nestedloop_test_2 SELECT i, i::text FROM generate_series(10, 1000000) AS s(i); EXPLAIN SELECT * FROM nestedloop_test_1 tbl1,nestedloop_test_2 tbl2 WHERE tbl1.a>tbl2.c;実行計画には Materialize と Nested Loop オペレーターが表示され、Nested Loop 結合パスが確認されます。

-
-
Cross Join
V3.0 以降、Cross Join オペレーターは、小規模テーブルとの非等値結合などのシナリオで Nested Loop Join を最適化します。一度に 1 つの外部行をフェッチし、内部テーブル全体をスキャンして内部状態をリセットする Nested Loop Join とは異なり、Cross Join は小規模テーブル全体をメモリにロードし、大規模テーブルからのストリーミングデータと結合します。これにより、パフォーマンスが大幅に向上します。ただし、Cross Join は Nested Loop Join よりも多くのメモリを使用します。
クエリ計画で Cross Join オペレーターを確認して、その使用状況を確認できます。
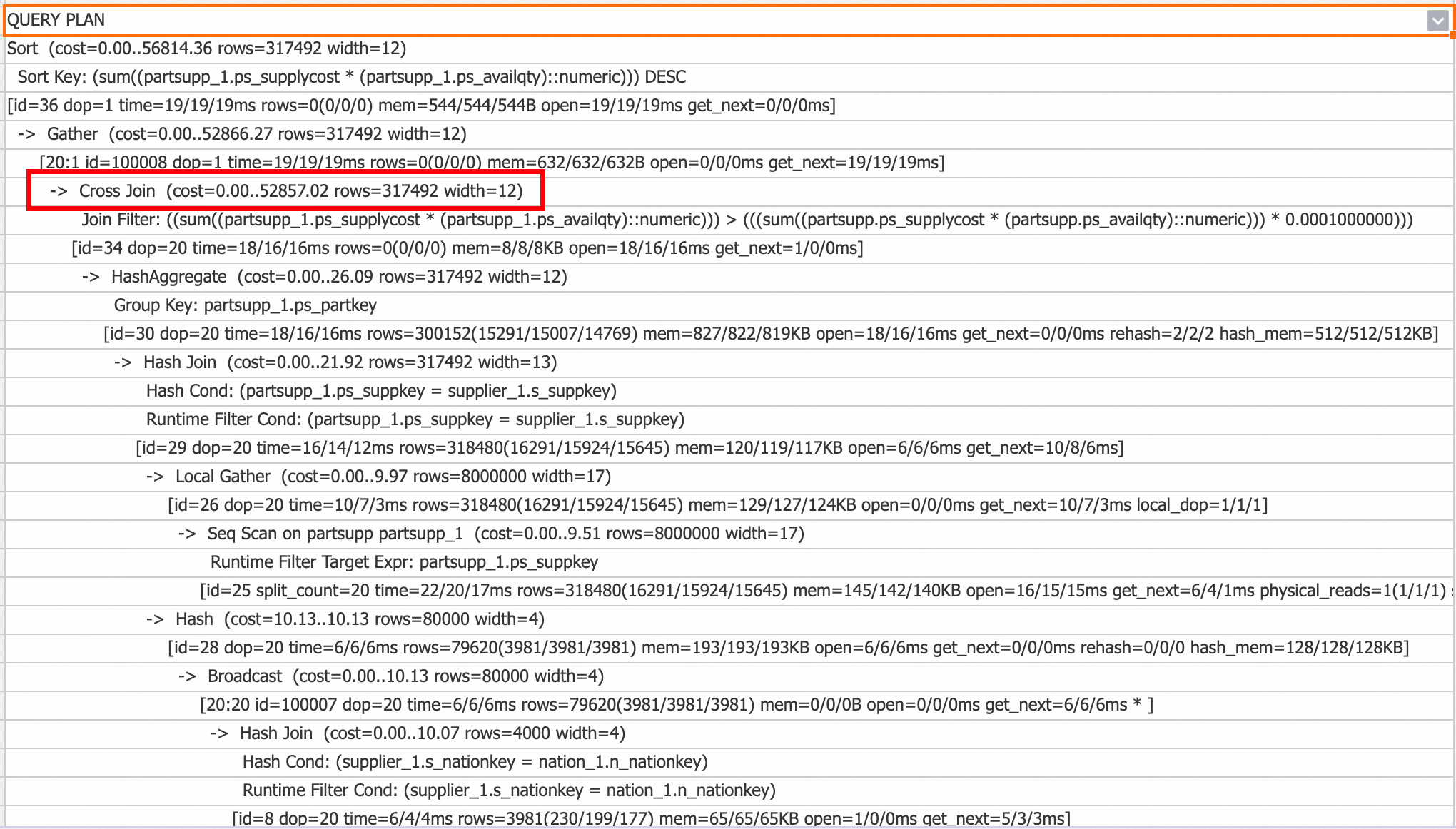
Cross Join を無効にするには、次のコマンドを実行します:
-- セッションレベルで無効化 SET hg_experimental_enable_cross_join_rewrite = off; -- データベースレベルで無効化 (新しい接続に対して有効) ALTER database <database name> hg_experimental_enable_cross_join_rewrite = off;
Broadcast
Broadcast オペレーターは、すべてのシャードにデータを配布し、通常、小規模テーブルが大規模テーブルと結合される Broadcast Join シナリオで使用されます。QO は、再配布とブロードキャストのコストを比較して、最適な実行計画を生成します。
チューニングの提案:
-
Broadcast は、テーブルが小さく、インスタンスのシャード数が少ない場合 (例えば、シャード数が 5) にコスト効率が高くなります。
例:テーブルサイズが大幅に異なる 2 つのテーブルの結合。
BEGIN; CREATE TABLE broadcast_test_1 ( f1 int, f2 int); CALL set_table_property('broadcast_test_1','distribution_key','f2'); CREATE TABLE broadcast_test_2 ( f1 int, f2 int); COMMIT; INSERT INTO broadcast_test_1 SELECT i AS f1, i AS f2 FROM generate_series(1, 30)i; INSERT INTO broadcast_test_2 SELECT i AS f1, i AS f2 FROM generate_series(1, 30000)i; ANALYZE broadcast_test_1; ANALYZE broadcast_test_2; EXPLAIN SELECT * FROM broadcast_test_1 t1, broadcast_test_2 t2 WHERE t1.f1=t2.f1;出力:

-
小さくないテーブルに対して Broadcast オペレーターが表示される場合、統計情報が古いことが原因である可能性が高いです。例えば、統計では 1,000 行と表示されているが、実際のスキャンは 100 万行である場合などです。
analyze <tablename>コマンドを実行して統計を更新できます。
シャードの枝刈りおよび選択シャード
-
Shard prune
これはシャードの選択方法を示します:
-
lazily:関連するシャードはまずシャード ID でマークされ、計算中に選択されます。
-
eagerly:一致に基づいて関連するシャードのみが即座に選択され、不要なシャードはスキップされます。
オプティマイザーは適切な Shard prune メソッドを自動的に選択します。手動での調整は不要です。
-
-
Shards selected
これは選択されたシャードの数を示します。例えば、1 out of 20 は、合計 20 のシャードから 1 つのシャードが選択されたことを意味します。
ExecuteExternalSQL
Hologres のサービスアーキテクチャで説明されているように、コンピュートエンジンには Hologres クエリエンジン (HQE)、PostgreSQL クエリエンジン (PQE)、および Shard クエリエンジン (SQE) コンポーネントが含まれます。PQE はネイティブの PostgreSQL エンジンです。Hologres 独自の HQE が特定のオペレーターや関数をサポートしていない場合、それらは PQE によって実行されますが、これは HQE よりも効率が低くなります。実行計画内の ExecuteExternalSQL オペレーターは、関数またはオペレーターが PQE を使用したことを示します。
-
例 1:PQE を使用する SQL。
CREATE TABLE pqe_test(a text); INSERT INTO pqe_test VALUES ('2023-01-28 16:25:19.082698+08'); EXPLAIN SELECT a::timestamp FROM pqe_test;実行計画は次のとおりです。ExecuteExternalSQL オペレーターの存在は、
::timestampオペレーターが PQE によって処理されることを示します。
-
例 2:
::timestampをto_timestampに書き換えると、代わりに HQE が使用されます。EXPLAIN SELECT to_timestamp(a,'YYYY-MM-DD HH24:MI:SS') FROM pqe_test;実行計画は次のとおりです:結果に ExecuteExternalSQL が含まれていないため、PQE が使用されなかったことを示します。

チューニングの提案:実行計画で PQE を使用する関数やオペレーターを特定し、それらを書き換えて HQE を使用することでパフォーマンスを向上させることができます。一般的な書き換え例の詳細については、「クエリパフォーマンスの最適化」をご参照ください。
Hologres は、各バージョンでより多くの PQE 操作を HQE にプッシュダウンすることで、PQE サポートを継続的に改善しています。一部の関数は、バージョンをアップグレードすると自動的に HQE を使用する場合があります。詳細については、「関数リリースノート」をご参照ください。
Aggregate
Aggregate オペレーターは、1 つ以上の集計関数を使用してデータを結合します。SQL 構文に基づいて、集計は HashAggregate、GroupAggregate などに分類されます。
-
GroupAggregate:データは group by キーによって事前にソートされます。
-
HashAggregate (最も一般的):データはハッシュ化され、集計のためにシャード間で分散され、その後 Gather オペレーターを使用して結合されます。
EXPLAIN SELECT l_orderkey,count(l_linenumber) FROM public.holo_lineitem_100g GROUP BY l_orderkey; -
多段階 HashAggregate:データはシャード内のファイルに保存されるため、大規模なデータセットでは複数の集計ステージが必要です。主要なサブオペレーターは次のとおりです:
-
Partial HashAggregate:ファイル内およびシャード内で集計を実行します。
-
Final HashAggregate:複数のシャードからの集計データを結合します。
例:多段階 HashAggregate を使用する TPC-H Q6 クエリ。
EXPLAIN SELECT sum(l_extendedprice * l_discount) AS revenue FROM lineitem WHERE l_shipdate >= date '1996-01-01' AND l_shipdate < date '1996-01-01' + interval '1' year AND l_discount BETWEEN 0.02 - 0.01 AND 0.02 + 0.01 AND l_quantity < 24;出力:

チューニングの提案: オプティマイザーは、データボリュームに基づいて、シングルステージまたはマルチステージの HashAggregate を自動的に選択します。EXPLAIN ANALYZE で Aggregate オペレーターの時間が高い値を示している場合、データボリュームが大きいにもかかわらず、オプティマイザーはファイルレベルの集約を行わず、シャードレベルの集約のみを実行したと考えられます。次のコマンドを実行することで、マルチステージの HashAggregate を強制できます。
SET optimizer_force_multistage_agg = on; -
Sort
Sort オペレーターは、データを昇順 (ASC) または降順 (DESC) に並べ替えます。このオペレーターは通常、ORDER BY 句から生じます。
例:TPC-H の lineitem テーブルを l_shipdate でソートする。
EXPLAIN SELECT l_shipdate FROM public.lineitem ORDER BY l_shipdate;出力:
チューニングの提案:大規模なソート操作はかなりのリソースを消費します。可能な限り、大規模なデータセットのソートは避けてください。
Limit
Limit オペレーターは、SQL 文によって返される行の最大数を指定します。Limit オペレーターは最終的な出力行のみを制御し、実際にスキャンされた行は制御しないことに注意してください。Limit オペレーターが Seq Scan ノードにプッシュダウンされているかどうかを確認することで、実際にスキャンされた行数を確認できます。
例:次の SQL 文では、LIMIT 1 が Seq Scan オペレーターにプッシュダウンされるため、1 行のみがスキャンされます。
EXPLAIN SELECT * FROM public.lineitem limit 1;出力: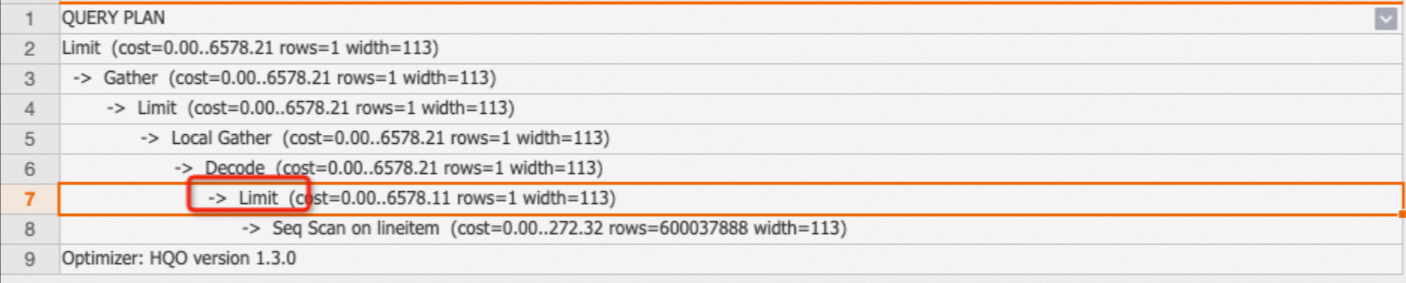
チューニングの提案:
-
すべての Limit オペレーターがプッシュダウンされるわけではありません。全表スキャンを避けるために、より多くのフィルター条件を追加できます。
-
数十万や数百万といった極端に大きな LIMIT 値の使用は避けてください。プッシュダウンされてもスキャン時間が増加するためです。
Append
サブクエリの結果は通常、Union All 操作を使用してマージされます。
Exchange
データはシャード内で交換されます。アクションは不要です。
Forward
Forward オペレーターは、HQE と PQE または SQE の間でオペレーターデータを転送します。このオペレーターは通常、HQE+PQE または HQE+SQE の組み合わせで表示されます。
Project
Project オペレーターは、サブクエリと外部クエリの間のマッピング関係を表します。このオペレーターは特別な注意を必要としません。
参考資料
HoloWeb で実行計画を視覚的に表示するには、「実行計画の表示」をご参照ください。