このトピックでは、ANALYZE コマンドと、よりシンプルな AUTO ANALYZE メカニズムの使用方法について説明します。
ANALYZE
統計情報は、オプティマイザーが正確な実行計画を生成するために不可欠です。Hologres は、データ分布と特性、テーブル統計情報、カラム統計情報、行数、カラム数、フィールド幅、カーディナリティ、頻度、最大値、最小値、最頻値、バケット分布特性など、ご利用のデータに関するサンプリングされた統計情報を収集します。オプティマイザーは、この情報を使用して、オペレーターコスト見積もりの更新、検索空間のプルーニング、最適な結合順序の見積もり、メモリオーバーヘッドの見積もり、並列処理の次数の見積もりを行い、最終的に、より良い実行計画を生成します。
ANALYZE コマンドは、ご利用のデータベース内のテーブルコンテンツに関する統計情報を収集します。オプティマイザーは、これらの統計情報を使用して最適なクエリプランを生成し、クエリ効率を向上させます。
構文
-- 特定のテーブルの統計情報を更新します。デフォルトでは、テーブル内のすべてのカラムの統計情報が収集されます。 ANALYZE <tablename>; -- 特定のカラムの統計情報を更新します。これは、テーブル全体を更新するよりも多くのデータをサンプリングし、より高い精度を提供します。主にフィルター条件で使用されるカラムにこれを使用します。 ANALYZE <tablename>(<colname>, <colname>);パラメーター説明
tablename は、統計情報を更新するテーブルの名前です。colname は、統計情報を更新するカラムの名前です。
構文詳細
以下に、2 つの ANALYZE コマンドについて説明します。
類似点
カラム統計情報は、行数、カラム幅、最頻値 (MCV)、ヒストグラム、および個別値の数 (NDV) に関する情報を提供します。
両方のコマンドは、指定されたカラムの統計情報のみを上書きし、他のカラムは変更しません。たとえば、コマンド
ANALYZE <tablename>(<colname1>);は、以前に収集されたcolname1の統計情報を上書き (更新) しますが、colname2の統計情報には影響しません。
相違点
ANALYZE <tablename>;は、サンプリングデータに基づいて統計情報を計算します。ANALYZE <tablename>(<colname>, <colname>);は、APPROX_COUNT_DISTINCT を使用して NDV を計算します。多くの場合、これはサンプリングよりも正確な結果をもたらしますが、より高いオーバーヘッドが発生します。したがって、この形式は重要なカラムにのみ使用してください。ヒストグラムや幅などの統計情報は、引き続きサンプリングから導出されます。
2 つのカラムを持つテーブル
table (colname1, colname2)の場合、ANALYZE table;はANALYZE table(colname1, colname2);と完全に同等ではありません。一般的に使用される結合カラムまたは GROUP BY カラムの場合、
ANALYZE <tablename>(<colname>, <colname>);を使用して追加の統計情報を収集します。
ANALYZE を実行するタイミング
次の状況で
ANALYZE <tablename>;を実行します。データインポートなど、テーブルに対して多数の INSERT、UPDATE、または DELETE 操作を実行した後。
パフォーマンスが低下している場合に、複数テーブル結合クエリを実行する前。結合カラムと GROUP BY カラムに対して ANALYZE を実行します。
CREATE FOREIGN TABLEの実行後、ANALYZE を使用して外部テーブルの統計情報を収集します。IMPORT FOREIGN SCHEMAの実行後、クエリを計画しているテーブルに対して ANALYZE を実行します。CREATE EXTERNAL DATABASEの実行後、ANALYZE を使用して外部テーブルの統計情報を収集します。
注意事項
Hologres V0.10 および V1.1 では、親パーティションテーブルをクエリする場合、親テーブルに対して ANALYZE を実行します。子テーブルを直接クエリする場合、それらの子テーブルに対して ANALYZE を実行します。両方を行う場合は、統計情報の欠落を避けるために両方に対して ANALYZE を実行します。
次の問題が発生した場合、インポートタスクを開始する前に ANALYZE を実行して、効率を体系的に向上させます。
複数テーブル結合がメモリを超過する (OOM): これは通常、
Query executor exceeded total memory limitation xxxxx: yyyy bytes usedのようなエラーを生成します。インポート効率が低い: Hologres でのクエリまたはデータインポートの実行が遅く、タスクの完了に時間がかかります。
ご利用のテーブルに非常にワイドなカラム (Bitmap やその他の Bytea データ、または 1 KB を超える Text データなど) が含まれている場合、これらのカラムの統計情報はメリットがなく、サンプリング中のメモリ消費量が増加します。このようなテーブルの場合、
ANALYZE <tablename>;の実行を避けてください。代わりに、ANALYZE <tablename>(<colname>, <colname>);を使用してワイドなカラムをスキップし、必要なカラム (結合カラム、GROUP BY カラム、フィルターカラムなど) のみ分析します。説明1 KB は経験的しきい値です。ビジネス要件に基づいてこれを調整できます。
AUTO ANALYZE
繰り返しの手動 ANALYZE 操作を減らすために、Hologres V0.10 以降では AUTO ANALYZE がサポートされています。有効にすると、システムはテーブル作成、データ書き込み、および変更に基づいて、関連するテーブルに対してバックグラウンドで ANALYZE を実行するかどうかを自動的に決定します。これにより、手動 ANALYZE の必要がなくなり、運用上の複雑さが軽減され、見落としによる統計情報の欠落が防止されます。
構文
AUTO ANALYZE が有効になっているか確認する
SHOW hg_enable_start_auto_analyze_worker; -- V1.1 以降のバージョンで現在のステータスを確認するための構文 SHOW hg_experimental_enable_start_auto_analyze_worker; -- V0.10 で現在のステータスを確認するための構文有効化または無効化の構文は次のとおりです。このコマンドにはスーパーユーザー権限が必要です。
-- データベースレベルの設定。データベース全体に適用されます。V1.1 以降の構文。 ALTER DATABASE dbname SET hg_enable_start_auto_analyze_worker = ON; -- 有効化 (デフォルト) ALTER DATABASE dbname SET hg_enable_start_auto_analyze_worker = OFF; -- 無効化 -- データベースレベルの設定。データベース全体に適用されます。V0.10 の構文。 ALTER DATABASE dbname SET hg_experimental_enable_start_auto_analyze_worker = ON; -- 有効化 (デフォルト) ALTER DATABASE dbname SET hg_experimental_enable_start_auto_analyze_worker = OFF; -- 無効化 -- 外部データベースの AUTO ANALYZE を有効にする ALTER EXTERNAL DATABASE dbname WITH enable_auto_analyze 'true';
制限事項
Hologres の AUTO ANALYZE には次の制限があります。
AUTO ANALYZE は Hologres V0.10 以降でのみサポートされています。ご利用のインスタンスバージョンは、Hologres 管理コンソールのインスタンス詳細ページで確認できます。ご利用のインスタンスが V0.10 より前のバージョンを実行している場合、詳細については、「一般的なアップグレード準備の失敗エラー」をご参照いただくか、Hologres DingTalk グループに参加してサポートを受けてください。詳細については、「オンラインサポートをさらに受けるにはどうすればよいですか?」をご参照ください。
スーパーユーザーのみが AUTO ANALYZE を有効または無効にできます。
パーティションテーブルの制限:
パーティション子テーブルが変更され、AUTO ANALYZE が必要な場合、システムは親テーブルを分析します。
パーティションテーブルには行スキャン制限があります。デフォルトでは、サンプリングは最大 224 行 (16,777,216 行) をスキャンします。すべてのパーティションの合計行数がこの制限を超えると、システムはパーティションプルーニングを実行し、パーティションのサブセット (合計 16,777,216 行以下) のみをサンプリングします。
説明パーティションキーカラム統計情報は常に完全であり、プルーニングの影響を受けません。ただし、これにより、パーティションキーと共存するカラム (同一データを持つカラムなど) の統計情報に影響を与える可能性があります。そのような場合、一部の値が見落とされ、不正確な行数見積もりにつながる可能性があります。必要に応じて、DingTalk グループ 32314975 を検索して Hologres リアルタイムデータウェアハウスディスカッショングループに参加し、テクニカルサポートに連絡してください。エンジニアがご利用のインスタンスを評価し、最大スキャン行制限を調整できます。
AUTO ANALYZE は、デフォルトで最大 256 カラムの統計情報を収集します。256 を超えるカラムを持つテーブルの場合、最初の 256 を処理します。この制限は
hg_experimental_auto_analyze_max_columns_countを調整することで変更できます。AUTO ANALYZE は、ワーカーあたりのメモリ使用量をデフォルトで 4 GB に制限します。非常にワイドなカラムを持つテーブルは、この制限を超える可能性があり、ANALYZE の失敗を引き起こす可能性があります。
auto_analyze_work_memory_mbパラメーターを調整してこの制限を増やすことができますが、システムメモリへの影響を考慮してください。より大きなインスタンスタイプは、より多くのワーカーとより高い合計メモリ制限を AUTO ANALYZE にサポートします。Hologres V3.1.0 以降、ANALYZE と AUTO ANALYZE は、外部データベース内の外部テーブルの統計情報収集をサポートしています。
ANALYZE と AUTO ANALYZE は、HMS 外部テーブルをサポートしていません。
AUTO ANALYZE の仕組み
AUTO ANALYZE を有効にすると、システムはバックグラウンドで定期的に ANALYZE が必要なテーブルをチェックします。
標準テーブル (非パーティションテーブルおよびパーティションテーブルを含む内部テーブル)
毎分、システムは最近のテーブルアクティビティ (主にデータ量を変更する可能性のある INSERT、UPDATE、または DELETE などの DML 操作) をチェックします。次のいずれかの条件が満たされた場合、システムは ANALYZE をトリガーして統計情報を収集します。
DML 操作が完了し、テーブルの現在の行数の 10% 以上が変更された場合。パーティション子テーブルの場合、これはそのパーティションの行数の 10% を超える変更を意味します。
TRUNCATE TABLE はテーブルを空にします。
CREATE TABLE や ALTER TABLE など、テーブルスキーマを変更する DDL 変更が発生した場合。これには、テーブルプロパティを変更するための CALL SET_TABLE_PROPERTY は含まれません。
10 分ごと、システムはすべての内部テーブルのデータ変更をチェックします。テーブルの行数が最後のチェック以降に 10% 以上変更された場合、システムは ANALYZE をトリガーします。
説明このステップは、非明示的な DML 操作 (Flink を介したリアルタイム書き込み、Data Integration、または HoloClient など) によって更新されたデータを検出します。
外部テーブル
4 時間ごと、システムは外部テーブルのメタデータまたはデータ変更のスケジュールされた検査を実行します。次の条件が満たされた場合、システムはバックグラウンドでテーブルに対して ANALYZE をトリガーして統計情報を収集します。
外部テーブルに対応する外部テーブル (MaxCompute 外部テーブルや DLF 外部テーブルなど) が 2 回の検査間 (4 時間以内など) で変更された場合。変更は、対応する MaxCompute テーブルの
last_modify_timeが検査間隔内にあるかどうかによって決定されます。
説明検査と実行は同じスケジューリングタスク内で発生します。次の検査は、現在の ANALYZE が完了した後にのみ開始されます。最後の検査開始からの時間がスケジューリングサイクルを満たしている限り、次の検査が開始されます。
設定パラメーター
AUTO ANALYZE を有効にすると、システムはテーブルを定期的に自動検査し、ANALYZE が必要なテーブルを決定し、サンプリングを実行して統計情報を収集します。これはシステムリソースを消費します。
一部のビジネスシナリオでは、デフォルトの動作がご利用の要件に合わない場合があります。たとえば、データ更新が頻繁でないシナリオでは、デフォルトパラメーターを調整することで AUTO ANALYZE の頻度を減らすことができます。パフォーマンスチューニングのために、必要に応じてこれらのパラメーターを変更できます。
説明スーパーユーザーのみが AUTO ANALYZE の動作を調整できます。すべての設定はデータベースレベルで適用され、1 分以内に有効になります。
構文
-- AUTO ANALYZE パラメーターのデフォルトを変更するためのスーパーユーザー構文 ALTER DATABASE <dbname> SET <GUC>=<values>;dbname はデータベース名です。GUC はパラメーター名です。values はパラメーター値です。
パラメーターリスト
パラメーター
パラメーター説明
サポートされているバージョン
デフォルト値
例
autovacuum_naptime
最近のテーブルアクティビティのチェック間隔 (秒単位)。
V1.1.0 以降
説明バックエンド調整が必要です。変更をリクエストするには、DingTalk グループ 32314975 を検索して Hologres リアルタイムデータウェアハウスディスカッショングループに参加してください。
60 秒
ALTER DATABASE <dbname> SET autovacuum_naptime = 60;ALTER DATABASE <dbname> SET autovacuum_naptime = '60s';ALTER DATABASE <dbname> SET autovacuum_naptime = '10min';
hg_auto_check_table_changes_interval
すべての内部テーブルのデータ変更をチェックする間隔 (秒単位)。
V1.1.0 以降
600秒 (10分)
-- V1.1 以降の構文 ALTER DATABASE <dbname> SET hg_auto_check_table_changes_interval = '600s'; -- V0.10 の構文 ALTER DATABASE <dbname> SET hg_experimental_auto_check_table_changes_interval = '600s';hg_auto_check_foreign_table_changes_interval
すべての外部テーブルのデータ変更をチェックする間隔 (秒単位)。
V1.1.0 以降
14400秒 (4時間)
-- V1.1 以降の構文 ALTER DATABASE <dbname> SET hg_auto_check_foreign_table_changes_interval = '14400s'; -- V0.10 の構文 ALTER DATABASE <dbname> SET hg_experimental_auto_check_foreign_table_changes_interval = '14400s';hg_experimental_auto_analyze_max_columns_count
統計情報が自動的に収集されるカラムの最大数。
V1.1.0 以降
256
ALTER DATABASE <dbname> SET hg_experimental_auto_analyze_max_columns_count = 300;auto_analyze_work_memory_mb
AUTO ANALYZE のテーブルあたりのメモリ制限 (MB 単位)。
V1.1.54 以降
デフォルト: ワーカーあたり 4096 MB (4 GB)。より大きなインスタンスタイプは、より多くのワーカーとより高い合計メモリ制限をサポートします。
テーブルあたりのメモリ制限を 9 GB に設定します。
ALTER DATABASE <dbname> SET auto_analyze_work_memory_mb = 9216;hg_experimental_auto_analyze_start_time
AUTO ANALYZE の日次開始時刻。
説明end_time と同じタイムゾーンを使用する必要があり、開始時刻は終了時刻以下である必要があります。
V1.1.54 以降
00:00 +0800
内部テーブルと外部テーブルのデータが日中に変更されない場合、AUTO ANALYZE を 00:00 から 06:00 の間のみ実行するように設定します。
ALTER DATABASE <dbname> SET hg_experimental_auto_analyze_start_time = '00:00 +0800';ALTER DATABASE <dbname> SET hg_experimental_auto_analyze_end_time = '06:00 +0800';
hg_experimental_auto_analyze_end_time
AUTO ANALYZE の日次終了時刻。
V1.1.54 以降
23:59 +0800
autovacuum_enabled
テーブルでの AUTO ANALYZE の有効化ステータス。
V1.1.54 以降
true (すべてのテーブルでデフォルトで有効)。
特定のテーブルの AUTO ANALYZE を無効にします。将来の ANALYZE 操作はこのテーブルをスキップします。
説明Hologres 内部テーブルの AUTO ANALYZE は、次のコマンドを使用してのみ無効にできます。
ALTER TABLE <tablename> SET (autovacuum_enabled = false);
追加の最適化
Hologres V3.1 以降、Fast Rows 機能が利用可能です。Hologres は、クエリ内のテーブルに統計情報が欠落していることを検出すると、ストレージエンジンからテーブルの行数を直接取得します。この操作には約 10 ミリ秒かかります。次のコマンドを使用します。
-- データベースレベルの設定。データベース全体に適用されます。
ALTER DATABASE dbname SET hg_experimental_get_fast_num_of_rows = ON; -- 有効化 (デフォルトで無効)
-- データベースレベルの設定。データベース全体に適用されます。
ALTER DATABASE dbname SET hg_experimental_get_fast_num_of_rows = OFF; -- 無効化 (デフォルトで無効)Fast Rows が無効の場合、次のシナリオは不正確なプランの可能性を減らすのに役立ちます。
テーブルに統計情報がない場合、クエリプランでは行数が 1000 と表示されます (統計情報の欠落を示し、プランは 1000 行に基づいて推定されます)。
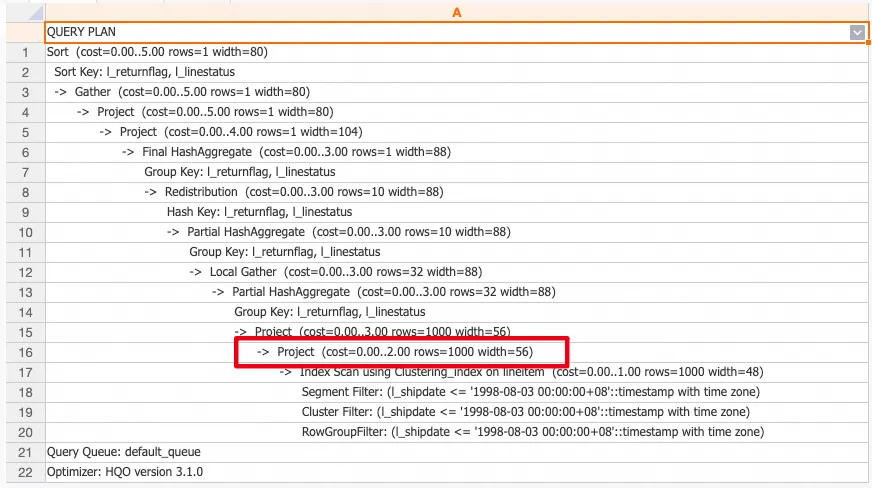
Fast Rows が有効でテーブルに統計情報がない場合、クエリプランの行数は 1000 ではありません (システムはストレージエンジンを呼び出して実際の行数を取得します)。
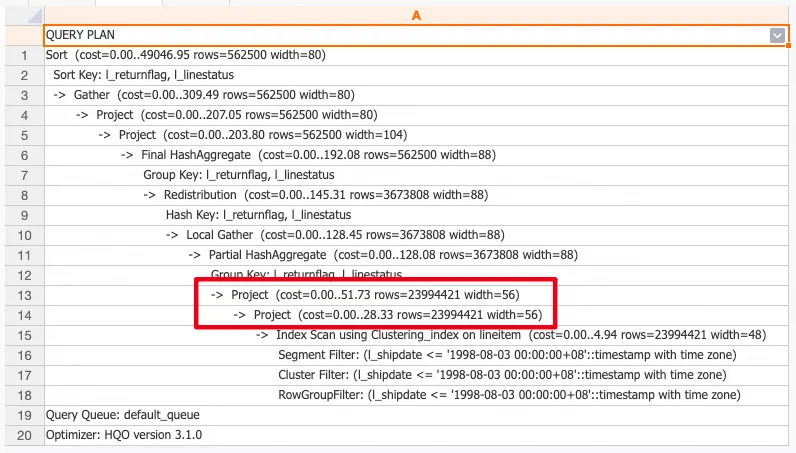
クエリの統計
テーブル統計情報は hologres_statistic.hg_table_statistic テーブルに保存されます。このテーブルをチェックして ANALYZE ステータスを監視できます。次のコマンドを使用します。
最新の ANALYZE 情報を見つけるには、analyze_timestamp でソートします。
SELECT schema_name, -- テーブルのスキーマ
table_name, -- テーブル名
schema_version, -- テーブルスキーマバージョン
statistic_version, -- 最新の ANALYZE 統計情報のバージョン
total_rows, -- 最新の ANALYZE からの行数
analyze_timestamp -- 最新の ANALYZE の終了時刻
FROM hologres_statistic.hg_table_statistic
WHERE table_name = '<tablename>'
ORDER BY analyze_timestamp DESC;各テーブルには
0–n個の hologres_statistic.hg_table_statistic レコードがあります。レコードがゼロの場合、ANALYZE は一度も実行されていないことを意味します。1 つ以上のレコードがある場合、ANALYZE が実行されたことを意味します。複数のレコードが存在する場合、テーブルスキーマが変更されたため (たとえば、
ADD COLUMNの実行時に新しいバージョンが作成されるなど)、それらの schema_version 値は異なります。古い schema_version を持つ古いレコードは使用されなくなります。同じテーブルの 2 つのレコードを示すクエリ結果の例。2 番目のレコードは schema_version が低く、廃止されています。無視してよいです。
schema_name | table_name | schema_version | statistic_version | total_rows | analyze_timestamp -------------+------------------+----------------+-------------------+------------+--------------------- public | tbl_name_example | 13 | 8580 | 10002 | 2022-04-29 16:03:18 public | tbl_name_example | 10 | 8576 | 10002 | 2022-04-29 15:41:20 (2 rows)Hologres V0.10 および V1.1 は、hg_table_statistic 内の期限切れの履歴レコードをクリーンアップしません。古いデータは安全に無視できます。
統計情報が欠落しているテーブルの表示
HG_STATS_MISSING ビューを使用して、ご利用のデータベース内で統計情報が欠落しているテーブルを特定できます。詳細については、「HG_STATS_MISSING ビュー」をご参照ください。
よくある質問
次のいずれかの状況が発生した場合、AUTO ANALYZE は正常に動作していません。提供されているソリューションに従ってください。
テーブル統計情報がゼロレコードを表示する
問題: hologres_statistic.hg_table_statistic をクエリしてもテーブルのデータが返されません。
考えられる原因:
AUTO ANALYZE が実行されていないか、テーブルが AUTO ANALYZE のトリガー条件を満たしていません。
問題は AUTO ANALYZE 機能自体にある可能性があります。詳細なトラブルシューティングについては、か、チケットを送信してください。
ソリューション: 手動で ANALYZE を一度トリガーできます。
analyze_timestampが小さすぎる問題: クエリ結果の
analyze_timestampが現在の時刻よりもかなり古く、ANALYZE が長期間実行されていないことを示しています。考えられる原因:
何らかの理由で AUTO ANALYZE の実行に失敗しました。
AUTO ANALYZE が手動で無効にされました。
ソリューション: まず、手動で ANALYZE をトリガーします。次に、か、チケットを送信して原因を調査してください。