ジョブのデバッグ機能を使用すると、ジョブの実行をシミュレートし、出力結果を確認し、SELECT 文または INSERT 文のビジネスロジックを検証できます。この機能により、開発効率が向上し、データ品質のリスクが軽減されます。このトピックでは、Flink SQL ジョブをデバッグする方法について説明します。
背景情報
Flink 開発コンソールでジョブのデバッグ機能を使用すると、ジョブのロジックをローカルで検証できます。このプロセスでは、結果テーブルの種類に関係なく、本番環境のダウンストリームシンクにデータは書き込まれません。ジョブをデバッグする際には、ライブアップストリームデータを使用するか、テストデータを指定できます。複数の SELECT 文または INSERT 文を含む複雑なジョブもデバッグできます。この機能は、count(*) のような更新操作を含む文を実行できる UPSERT クエリもサポートしています。
制限事項
ジョブのデバッグ機能には、セッションクラスターが必要です。
デバッグは SQL ジョブでのみサポートされています。
CREATE TABLE AS SELECT (CTAS) 文および CREATE DATABASE AS (CDAS) 文のデバッグはサポートされていません。
デフォルトでは、Flink は最大 1,000 レコードを読み取った後に自動的に一時停止します。
セッションクラスター内の各デバッグセッションは、最大 3 分に制限されます。この制限により、クラスターの安定性が確保され、クラスターのライフサイクル管理に役立ちます。
注意事項
セッションクラスターを作成すると、クラスターリソースが消費されます。消費されるリソースの量は、作成時に選択するリソース構成によって異なります。
本番環境ではセッションクラスターを使用しないでください。セッションクラスターは開発およびテストを目的としています。セッションクラスターを使用してジョブをデバッグすると、JobManager (JM) のリソース使用率を向上させることができます。本番環境でセッションクラスターを使用すると、JM の再利用メカニズムがジョブの安定性に悪影響を及ぼす可能性があります。詳細は次のとおりです:
JobManager の単一障害点 (SPOF) は、クラスター内のすべてのジョブに影響します。
TaskManager の SPOF は、その上でタスクが実行されているジョブに影響します。
同じ TaskManager 内で、タスク間にプロセス分離がない場合、互いに干渉する可能性があります。
セッションクラスターがデフォルトの構成を使用する場合、次の推奨事項に注意してください:
単一の並列度の小規模なジョブの場合、クラスター内のジョブの総数は 100 を超えないようにしてください。
複雑なジョブの場合、単一ジョブの最大並列度は 512 を超えないようにしてください。単一のクラスターでは、並列度が 64 の中間規模のジョブを 32 以上実行しないでください。そうしないと、ハートビートのタイムアウトなどの問題が発生し、クラスターの安定性に影響を与える可能性があります。この場合、ハートビート間隔とタイムアウトを増やしてください。
より多くのタスクを同時に実行するには、セッションクラスターのリソース構成を増やしてください。
操作手順
ステップ 1:セッションクラスターの作成
セッション管理ページに移動します。
リアルタイムコンピューティングプラットフォームコンソールにログインします。
対象のワークスペースの[操作]列で、[コンソール]をクリックします。
左側のナビゲーションウィンドウで、 を選択します。
[セッションクラスターを作成] をクリックします。
構成情報を入力します。
次の表にパラメーターを示します。
モジュール
構成
説明
基本構成
名前
セッションクラスターの名前。
デプロイメントターゲット
ターゲットリソースキューを選択します。リソースキューの作成方法の詳細については、「リソースキューの管理」をご参照ください。
状態
クラスターの望ましい状態を設定します:
RUNNING:構成後、クラスターは実行を継続します。
STOPPED:構成後、クラスターは停止します。セッションクラスターにデプロイされているすべてのジョブも停止します。
スケジュールされたセッション管理
長時間実行されるセッションクラスターによるリソースの浪費を防ぐために、指定された期間ジョブが実行されていない場合にクラスターが自動的にシャットダウンするように構成できます。
タグ名
ジョブにタグを追加できます。これにより、概要ページでジョブをすばやく見つけることができます。
タグ値
なし。
構成
エンジンバージョン
エンジンバージョンの詳細については、「エンジンバージョン」および「ライフサイクルポリシー」をご参照ください。推奨または安定バージョンを使用することを推奨します。バージョンタグの説明は次のとおりです:
推奨:最新のメジャーバージョンの最新のマイナーバージョン。
安定:サービス期間中のメジャーバージョンの最新のマイナーバージョン。以前のバージョンのバグはこのバージョンで修正されています。
通常:サービス期間中のその他のマイナーバージョン。
EOS:サービス終了日を過ぎたバージョン。
Flink 再起動戦略
このパラメーターには次の値を設定できます:
失敗率:失敗率に基づいて再起動します。
このオプションを選択した場合は、失敗率の間隔、間隔あたりの最大失敗数、および 再起動間の遅延も指定する必要があります。
固定遅延:固定間隔で再起動します。
このオプションを選択した場合は、再起動試行回数と 再起動間の遅延も指定する必要があります。
再起動なし:タスクが失敗した場合、ジョブは再起動しません。
重要このパラメーターを構成しない場合、デフォルトの Apache Flink 再起動戦略が使用されます。タスクが失敗し、チェックポイントが無効になっている場合、JobManager プロセスは再起動しません。チェックポイントが有効になっている場合、JobManager プロセスは再起動します。
その他の構成
ここでさらに Flink の構成を設定します。例:
taskmanager.numberOfTaskSlots: 1。リソース構成
TaskManager の数
デフォルトでは、この値は並列度と同じです。
JobManager CPU コア
デフォルト値は 1 です。
JobManager メモリ
最小値は 1 GiB です。推奨値は 4 GiB です。単位として GiB または MiB を使用することを推奨します。例:1024 MiB または 1.5 GiB。
TaskManager CPU コア
デフォルト値は 2 です。
TaskManager メモリ
最小値は 1 GiB です。推奨値は 8 GiB です。単位として GiB または MiB を使用することを推奨します。例:1024 MiB または 1.5 GiB。
推奨される TaskManager の構成には、TaskManager あたりのスロット数 (taskmanager.numberOfTaskSlots) と TaskManager のリソースサイズが含まれます。詳細は次のとおりです:
単一の並列度を持つ小規模なジョブの場合、スロットごとに 1:4 の CPU 対メモリ比が推奨されます。少なくとも 1 コアと 2 GiB のメモリを使用してください。
複雑なジョブの場合、スロットごとに少なくとも 1 コアと 4 GiB のメモリを使用してください。デフォルトのリソース構成では、各 TaskManager に 2 つのスロットを構成できます。
TaskManager のリソースは小さすぎても大きすぎてもいけません。デフォルトのリソース構成を使用し、スロット数を 2 に設定することを推奨します。
重要単一の TaskManager のリソースが不足している場合、その上で実行されているジョブの安定性が影響を受ける可能性があります。また、スロット数が少ないため、TaskManager のオーバーヘッドを効果的に共有できず、リソース使用率が低下します。
単一の TaskManager のリソースが過剰な場合、多くのジョブがその上で実行されます。TaskManager で単一障害点が発生した場合、影響は広範囲に及びます。
ログ構成
ルートログレベル
次のログレベルは、重要度の低い順にリストされています:
TRACE:DEBUG よりも詳細な情報。
DEBUG:システムの実行状態に関する情報。
INFO:重要または興味深い情報。
WARN:潜在的なシステムエラーに関する情報。
ERROR:システムエラーと例外に関する情報。
クラスログレベル
ログ名とレベルを入力します。
ログテンプレート
システムテンプレートまたはカスタムテンプレートを選択できます。
説明Kubernetes や Yarn などのリソースオーケストレーションフレームワークと Flink の統合に関連するオプションの詳細については、「リソースオーケストレーションフレームワーク」をご参照ください。
[セッションクラスターの作成] をクリックします。
セッションクラスターが作成された後、ジョブのデバッグページまたはデプロイメントページで選択できます。
ステップ 2:ジョブのデバッグ
ジョブの SQL コードを記述します。詳細については、「ジョブ開発マップ」をご参照ください。
[ETL] ページで、[デバッグ] をクリックし、[デバッグクラスター] を選択し、[次へ] をクリックします。
テストデータを構成します。
ライブデータを使用する場合、[OK] をクリックします。
テストデータを使用する場合は、[データテンプレートのダウンロード] をクリックし、テンプレートにテストデータを入力して、データファイルをアップロードします。

このページの各機能について説明します。
パラメーター
説明
データテンプレートのダウンロード
編集を容易にするために、ソーステーブルのデータ構造に適合したデータテンプレートをダウンロードできます。
テストデータのアップロード
ローカルテストデータを使用してデバッグするには、データテンプレートをダウンロードし、ローカルでデータを編集してファイルをアップロードしてから、[テストデータを使用]を選択します。
テストデータファイルには次の制限があります:
アップロードされるファイルは CSV 形式のみがサポートされています。
CSV ファイルには、id(INT) などのテーブルヘッダーが含まれている必要があります。
CSV テストデータファイルは、最大 1 MB のサイズまたは最大 1,000 レコードまでです。
データプレビュー
テストデータをアップロードした後、ソーステーブル名の左にある
 アイコンをクリックして、テストデータをプレビューおよびダウンロードします。
アイコンをクリックして、テストデータをプレビューおよびダウンロードします。デバッグコードのプレビュー
デバッグ機能は、ソーステーブルと結果テーブルの DDL コードを自動的に変更しますが、ジョブ内の実際のコードは変更しません。コードの詳細は以下でプレビューできます。
テストデータを設定した後、[OK] をクリックします。
[OK] をクリックすると、SQL エディターの下にデバッグ結果が表示されます。
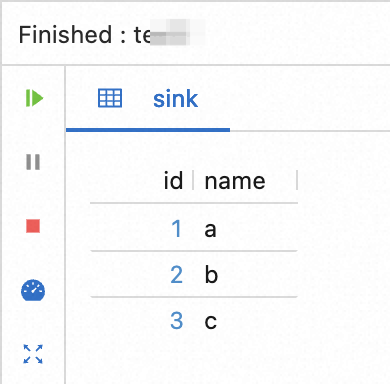
関連ドキュメント
ジョブを開発またはデバッグした後にオンラインでデプロイするには、「ジョブのデプロイ」をご参照ください。
ジョブをデプロイした後、「ジョブの開始」をご参照ください。
Flink SQL ジョブの操作フローの完全な例については、「Flink SQL ジョブのクイックスタート」をご参照ください。