このトピックでは、モニタリング、アラート、ログに関するよくある質問に回答します。
ワークスペースで使用されているモニタリングサービスタイプを確認するにはどうすればよいですか?
ワークスペースの作成時に、モニタリングサービスタイプを選択します。ワークスペースの作成後、 ページに移動し、ジョブ名をクリックします。[アラート設定] タブが表示される場合、ワークスペースは Application Real-Time Monitoring Service (ARMS) の一部である従量課金の Prometheus Service を使用します。タブが表示されない場合、ワークスペースは無料の CloudMonitor サービスを使用します。詳細については、「ジョブのモニタリングとアラート」をご参照ください。

ARMS と比較した場合の CloudMonitor アラートの制限事項は何ですか?
クエリ分析構文はサポートされていません。
サブタスク粒度での曲線は利用できません。複数のソースとサブタスクがあるシナリオでは、クラスタリング後にレイテンシーの問題を迅速に特定することが困難になります。
ユーザーコード内のカスタムイベントトラッキングから報告されたメトリックは表示できません。これにより、トラブルシューティングが困難になる場合があります。
アラート連絡先を構成または追加するにはどうすればよいですか?
CloudMonitor を使用する場合、または ARMS コンソールでアラートを構成する場合、対応するコンソールで連絡先を追加または構成する必要があります。アラート構成の詳細については、「モニタリングとアラートの構成」をご参照ください。
ワークスペースで ARMS モニタリングサービスを使用していて、Realtime Compute for Apache Flink 開発コンソールで直接、単一のジョブのメトリックまたはジョブ失敗アラートを設定する場合、次の手順に従ってアラート連絡先を追加または設定します。
アラート構成ページにアクセスします。
Realtime Compute for Apache Flink 管理コンソールにログインします。対象のワークスペースの[操作]列で、[コンソール]をクリックします。
[] ページで、対象のジョブ名をクリックします。
[アラート設定] タブをクリックします。
[アラートルール] タブで、 を選択して、ルール作成パネルを開きます。
アラート連絡先を構成または追加します。
追加
「通知の受信者パラメーター」の横にある [通知の受信者管理] をクリックして、連絡先、DingTalk ロボットなどを追加します。DingTalk ロボット、新しい Webhook、および Lark ロボット向けのアラート設定方法について詳しくは、「よくある質問」をご参照ください。
連絡先を追加した後、アラートの電話通知を使用する場合は、受信者の電話番号が検証済みであることを確認してください。そうでない場合、アラートは配信されません。連絡先タブで対象の連絡先の[電話]列に[未検証]ラベルが表示された場合は、そのラベルをクリックして検証を完了します。

構成
[通知の受信者] パラメーターについて、目的のアラート連絡先を選択します。目的の連絡先が利用できない場合は、上記の手順に従って追加してください。
自動的に有効になる Prometheus Service を無効にするにはどうすればよいですか?
ワークスペースの作成時に従量課金 Prometheus Service (ARMS) を選択した場合、ARMS サービスは自動的に有効になります。Realtime Compute for Apache Flink のモニタリングが不要になった場合は、次の手順に従って Prometheus Service をアンインストールします。
ワークスペースの Prometheus インスタンスをアンインストールすると、そのワークスペースのモニタリングデータ収集が停止し、ジョブモニタリングデータ曲線が失われます。ジョブが異常になった場合、異常の初期時刻を特定したり、モニタリングアラートを受信したりすることはできません。慎重に進めてください。
Prometheus コンソールにログインします。Prometheus コンソール。
左側のナビゲーションウィンドウで、[インスタンス一覧] をクリックして、インスタンス一覧ページに移動します。
「[タグ フィルタリング]」ドロップダウン リストから、対象ワークスペースの ID または名前を選択します。
「インスタンスタイプ」が「Prometheus for Flink Serverless」に設定されているインスタンスを見つけ、[操作] 列で [アンインストール] をクリックします。
表示されるダイアログボックスで、[確認] をクリックします。
アラートをトリガーしたジョブを見つけるにはどうすればよいですか?
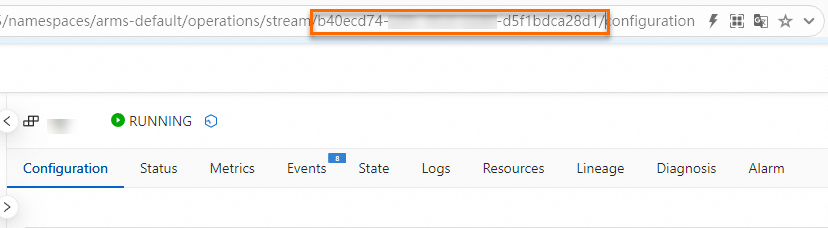
アラートイベントには JobID と Deployment ID が含まれています。ただし、ジョブフェールオーバー後、JobID は変更されます。したがって、Deployment ID を使用して、エラーを報告した特定のジョブを見つけます。Deployment ID は、次のいずれかの方法で表示できます。
Realtime Compute for Apache Flink 開発コンソールで、[デプロイメント詳細] タブの [基本設定] セクションで Deployment ID を確認します。
ジョブの URL で Deployment ID を表示します。
Flink ジョブの再起動に対するモニタリングとアラートを設定する方法は?
Realtime Compute for Apache Flink 開発コンソールでは、Flink メトリックに基づいてアラートルールを設定します。したがって、ジョブのフェールオーバー後は、メトリック曲線が表示されず、アラートがトリガーされません。ジョブの再起動などの重大なイベントを処理するには、ARMS コンソールで flink_jobmanager_job_numRestarts メトリックの瞬間的な増加率に基づくカスタムルールを設定できます。これにより、ジョブマネージャー (JM) のフェールオーバーイベントに対するアラートを実現できます。以下の手順はその一例です:
対象のワークスペースの [操作] 列で、 をクリックして、Application Real-Time Monitoring Service (ARMS) コンソールに移動します。
[アラートルール] ページで、[Prometheus アラートルールの作成] をクリックします。
検出タイプを [カスタム PromQL] に設定し、アラート送信対象のインスタンスを選択します。
カスタム Prometheus クエリ言語 (PromQL) 文を記述します。
たとえば、
irate(flink_jobmanager_job_numRestarts{jobId=~"$jobId",deploymentId=~"$deploymentId"}[1m])>0は、直近 1 分間の `flink_jobmanager_job_numRestarts` データをクエリし、瞬間的な変化率が 0 より大きい場合にアラートをトリガーします。[完了] をクリックします。
単一クラスのログレベルパラメーターを設定するにはどうすればよいですか?
たとえば、log4j.logger.org.apache.kafka.clients.consumer=trace(ソーステーブル用)およびlog4j.logger.org.apache.kafka.clients.producer=trace(結果テーブル用)などの Kafka コネクタ関連のパラメーターを設定するには、[ログレベル] で設定する必要があります。[その他の設定] では設定しないでください。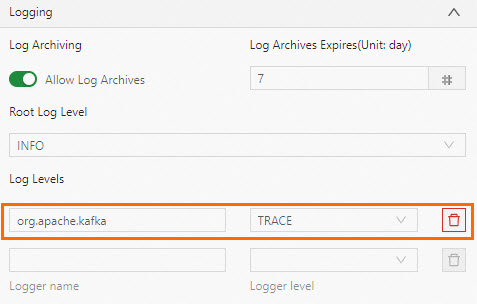
GC ログパラメーターを有効にするにはどうすればよいですか?
「」ページで、対象のジョブ名をクリックします。「[デプロイメント詳細]」タブの「[パラメータ設定]」セクションで、「[その他の設定]」に次のコードを追加し、変更を適用するために保存します。
env.java.opts: >-
-XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:/flink/log/gc.log
-XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=2 -XX:GCLogFileSize=50M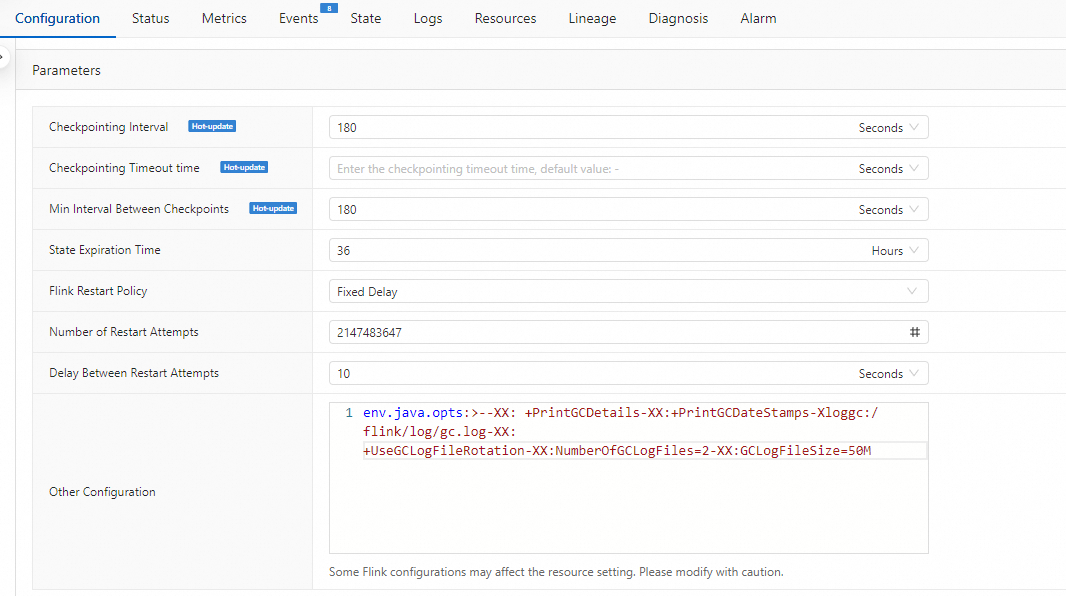
SLS のログを構成した後、ジョブの起動に失敗します
問題の詳細
ジョブを Simple Log Service (SLS) にログを出力するように変更した後、ジョブの起動に失敗し、「ジョブの起動に失敗しました。再試行してください。」というメッセージと次のエラーが報告されます。
Unknown ApiException {exceptionType=com.ververica.platform.appmanager.controller.domain.TemplatesRenderException, exceptionMessage=Failed to render {userConfiguredLoggers={}, jobId=3fd090ea-81fc-4983-ace1-0e0e7b******, rootLoggerLogLevel=INFO, clusterName=f7dba7ec27****, deploymentId=41529785-ab12-405b-82a8-1b1d73******, namespace=flinktest-default, priorityClassName=flink-p5, deploymentName=test}} 029999 202312121531-8SHEUBJUJU原因
ジョブログを構成する際、`namespace` や `deploymentId` などの Twig 変数を変更していないか確認してください。
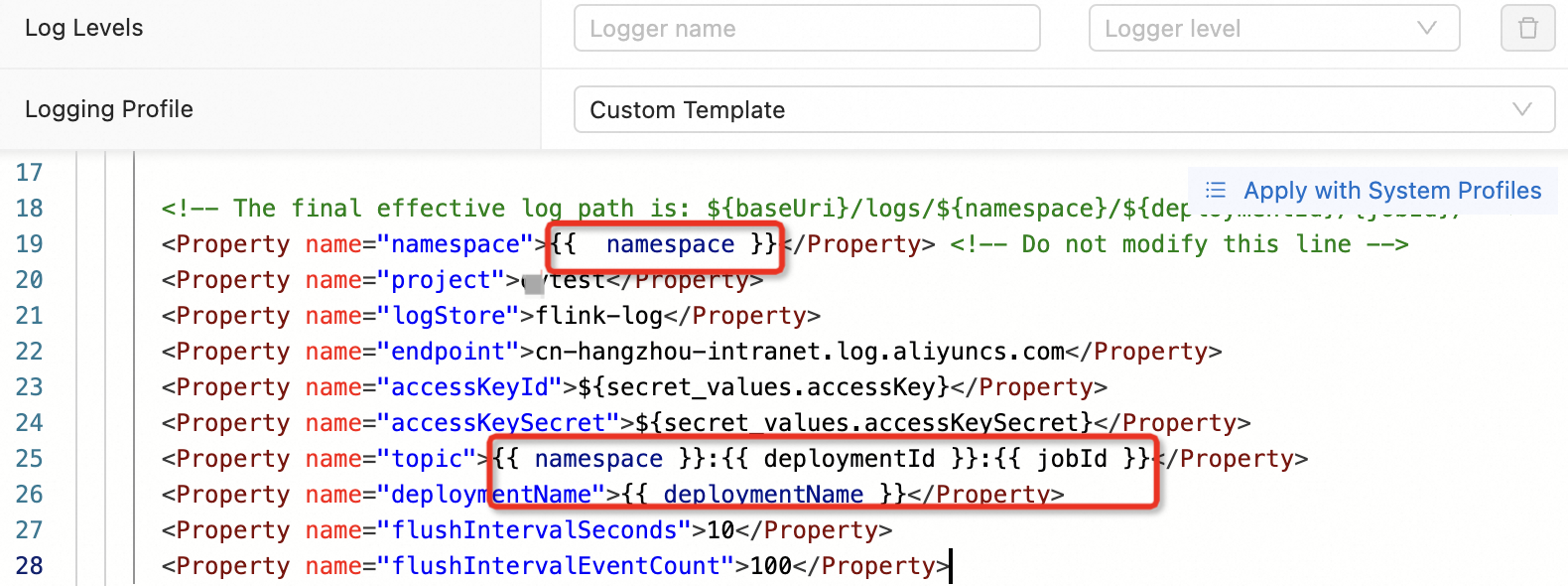
解決策
「ジョブログ出力の構成」の手順に従って設定を再構成します。必要に応じて、表に記載されているパラメーターを変更します。
Flink の履歴運用ログを表示、検索、分析するにはどうすればよいですか?
Realtime Compute for Apache Flink は、開発コンソールまたは外部ストレージで履歴運用ログの表示と分析をサポートしています。
開発コンソールのジョブログインターフェイスで表示および分析します。
[デプロイメント詳細] タブでは、[ログアーカイブ] 機能を有効にできます。この機能はデフォルトで有効になっており、[ログアーカイブの保存期間] も設定できます。デフォルトの保存期間は 7 日間で、最新の 5 MB の運用ログが保存されます。
外部ストレージで表示および分析します。
ジョブログを OSS、SLS、Kafka などの外部ストレージに送信するように構成できます。また、出力のログレベルを構成することもできます。詳細については、「ジョブログ出力の構成」をご参照ください。
非静的メソッドからのログが SLS に出力されない問題を解決するにはどうすればよいですか?
問題の詳細
SLS Logger Appender の実装ロジックにより、非静的メソッドからのログは SLS に出力されません。
解決策
標準定義を使用します。
private static final Logger LOG = LoggerFactory.getLogger(xxx.class);
データは正しく書き込まれますが、Flink ジョブステータス概要に 0 データと表示されます。どうすればよいですか?
問題の詳細
ジョブにノードが 1 つしかない場合、ジョブトポロジーグラフには読み書きされるデータ量は表示されません。これは、ソースが出力のみを持ち、sink が入力のみを持つ場合に発生します。
解決策
トポロジーグラフで特定のデータトラフィックを表示するには、オペレーターを分割する必要があります。ソースおよびシンク演算子を独立した演算子に分割し、それらを他の演算子に個別に接続して新しいトポロジーを形成します。そうすることで、トポロジーグラフでデータフローとトラフィックを表示できます。
「」ページで、対象のジョブ名をクリックします。「デプロイメントの詳細」タブの「パラメーター設定」セクションで、演算子分割パラメーター構成
pipeline.operator-chaining: 'false'を「その他の設定」に追加します。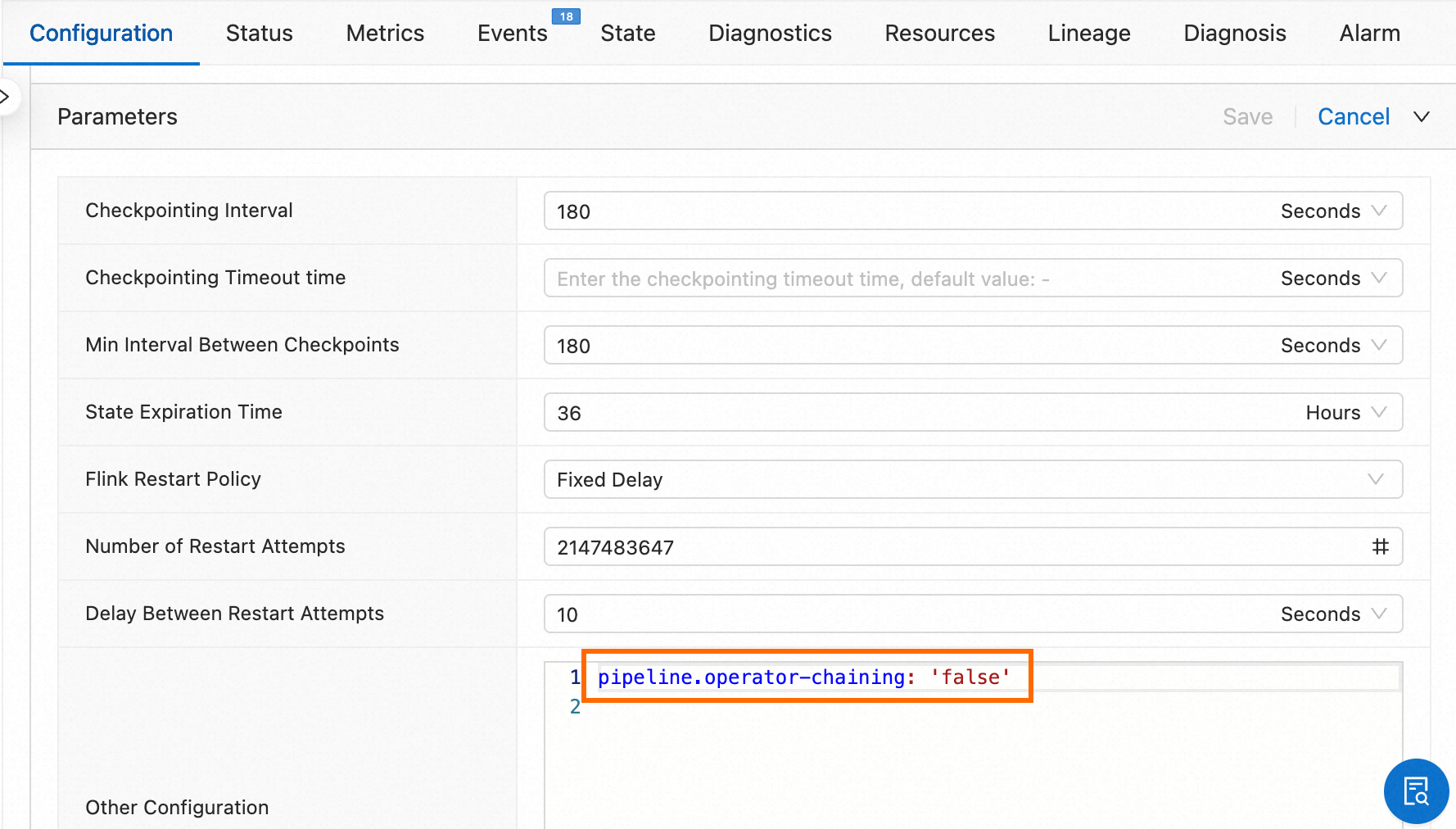
Datastream ジョブに遅延がないのに、出力曲線に遅延が表示される場合はどうすればよいですか?
問題の説明
ソーステーブルは継続的に Flink にデータを供給し、Kafka 物理テーブルの各パーティションも連続データストリームです。ただし、Datastream ジョブの Kafka ソースの `CurrentEmitEventTimeLag` および `CurrentFetchEventTimeLag` メトリックは 52 年の遅延を示します。
原因
Datastream の Kafka 依存関係はコミュニティコネクタであり、Flink 組み込みコネクタではありません。コミュニティコネクタは曲線レポートのロジックを実装していません。その結果、入出力遅延などのメトリックの曲線が異常に見えます。
解決策
Flink 組み込みコネクタの依存関係を使用します。詳細については、「Maven Repository」をご参照ください。
詳細なスタックトレースなしで Datastream ジョブの TM ログに NullPointerException がスローされる場合はどうすればよいですか?
「」ページで、対象のジョブ名をクリックします。[デプロイメントの詳細] タブの[パラメーター設定] セクションで、次のコードを[その他の設定]に追加します。
env.java.opts: "-XX:-OmitStackTraceInFastThrow"