このトピックでは、ジョブ実行エラーに関するよくある質問への回答を提供します。
Realtime Compute for Apache Flink の開発コンソールの右側にデータベース接続エラーを示すエラーメッセージが表示される場合はどうすればよいですか?
LocalGroupAggregate オペレーターでデータ出力が長時間停止しています。データ出力は生成されません。なぜですか?
アップストリーム Kafka コネクタのパーティションにデータが入力されていません。その結果、ウォーターマークが前進できず、ウィンドウ出力が遅延します。どうすればよいですか?
「INFO: org.apache.flink.fs.osshadoop.shaded.com.aliyun.oss」というエラーメッセージが表示される場合はどうすればよいですか?
「akka.pattern.AskTimeoutException」というエラーメッセージが表示される場合はどうすればよいですか?
「Task did not exit gracefully within 180 + seconds.」というエラーメッセージが表示される場合はどうすればよいですか?
「Can not retract a non-existent record. This should never happen.」というエラーメッセージが表示される場合はどうすればよいですか?
「The GRPC call timed out in sqlserver」というエラーメッセージが表示される場合はどうすればよいですか?
「Caused by: java.lang.NoSuchMethodError」というエラーメッセージが表示される場合はどうすればよいですか?
ジョブを開始できない場合はどうすればよいですか?
問題の説明
[アクション] 列の [開始] をクリックした後、ジョブのステータスが [開始中] から [失敗] に変化します。
解決策
ジョブ詳細ページの [イベント] タブで、ジョブの開始に失敗した時刻の左側にある
 アイコンをクリックします。次に、エラーメッセージに基づいて問題を特定します。
アイコンをクリックします。次に、エラーメッセージに基づいて問題を特定します。[ログ] タブの [起動ログ] サブタブで、エラーが存在するかどうかを確認します。次に、エラーメッセージに基づいて問題を特定します。
JobManager が想定どおりに開始された場合は、[ログ] タブの JobManager または実行中の TaskManager サブタブで、JobManager または TaskManager の詳細ログを表示できます。
一般的なエラーとトラブルシューティング
問題の説明
原因
解決策
ERROR:exceeded quota: resourcequota現在のキューのリソースが不足しています。
現在のキューのリソースを再構成するか、ジョブの起動に使用されるリソースを削減します。
ERROR:the vswitch ip is not enough現在の名前空間で使用可能な IP アドレスの数が、ジョブの開始によって生成される TaskManager の数よりも少なくなっています。
並列実行されるジョブの数を減らすか、ジョブに割り当てることができるスロットを再構成するか、ワークスペースの vSwitch を変更します。
ERROR: pooler: ***: authentication failedコードで指定されたアカウントの AccessKey ペアが無効であるか、アカウントにジョブを開始する権限がありません。
有効で権限を持つ AccessKey ペアを入力します。
Realtime Compute for Apache Flink の開発コンソールの右側にデータベース接続エラーを示すエラーメッセージが表示された場合はどうすればよいですか?
問題の説明

原因
登録済みのカタログが無効であり、正しく接続できません。
解決策
[カタログ] ページで全てのカタログを表示し、選択不可になっているカタログを削除してから、関連するカタログを再度登録します。
ジョブを実行してもタスクのデータが消費されない場合はどうすればよいですか。
ネットワーク接続のトラブルシューティング
アップストリームおよびダウンストリームストレージでデータが生成または消費されない場合は、[起動ログ] タブにエラーメッセージが報告されているかどうかを確認します。タイムアウトエラーが報告された場合は、ストレージ間のネットワーク接続で発生しているエラーのトラブルシューティングを行います。
タスク実行ステータスのトラブルシューティング
[構成] タブで、ソースからデータが読み取られ、シンクに書き込まれているかどうかを確認して、エラーの場所を特定します。

タスクのトラブルシューティング
トラブルシューティングのために、ジョブの各タスクに print シンクテーブルを追加します。
ジョブが実行された後に再起動される場合はどうすればよいですか?
目的のジョブの [ログ] タブでエラーのトラブルシューティングを行います。
[例外情報] を表示します。
[JM 例外] タブで、報告されたエラーを表示し、トラブルシューティングを行います。
ジョブの JobManager および TaskManager のログを表示します。

ジョブの [失敗した TaskManager] のログを表示します。
一部の例外によって、TaskManager が失敗する可能性があります。その結果、スケジュールされている TaskManager ログは不完全になります。トラブルシューティングのために、最後の無効な TaskManager ログを表示できます。
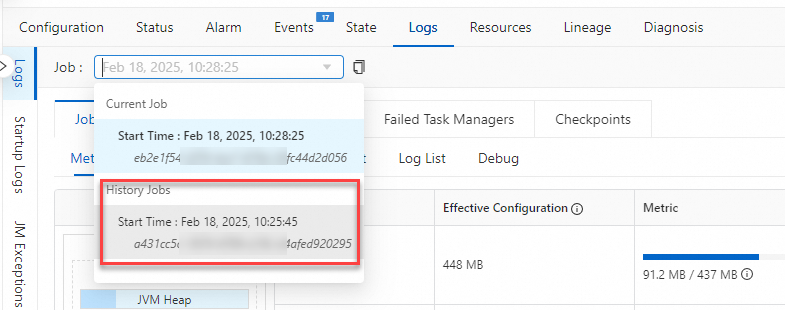
[履歴ジョブ] インスタンスの操作ログを表示します。
履歴ジョブインスタンスの操作ログを表示して、ジョブの失敗の理由を確認します。
LocalGroupAggregate オペレーターでデータ出力が長時間停止し、データ出力が生成されません。理由は何ですか?
コード
CREATE TEMPORARY TABLE s1 ( a INT, b INT, ts as PROCTIME(), PRIMARY KEY (a) NOT ENFORCED ) WITH ( 'connector'='datagen', 'rows-per-second'='1', 'fields.b.kind'='random', 'fields.b.min'='0', 'fields.b.max'='10' ); CREATE TEMPORARY TABLE sink ( a BIGINT, b BIGINT ) WITH ( 'connector'='print' ); CREATE TEMPORARY VIEW window_view AS SELECT window_start, window_end, a, sum(b) as b_sum FROM TABLE(TUMBLE(TABLE s1, DESCRIPTOR(ts), INTERVAL '2' SECONDS)) GROUP BY window_start, window_end, a; INSERT INTO sink SELECT count(distinct a), b_sum FROM window_view GROUP BY b_sum;問題の説明
LocalGroupAggregate オペレーターでのデータ出力が長時間中断されており、MiniBatchAssigner オペレーターはジョブのトポロジーに含まれていません。

原因
ジョブには、WindowAggregate オペレーターと GroupAggregate オペレーターの両方が含まれています。 WindowAggregate オペレーターの時間列は proctime で、これはイベント時間を示します。
table.exec.mini-batch.sizeパラメーターがジョブに構成されていない場合、または table.exec.mini-batch.size パラメーターが負の値に設定されている場合、管理メモリは miniBatch 処理モードでデータをキャッシュするために使用されます。MiniBatchAssigner オペレーターは生成に失敗し、ウォーターマークメッセージを計算オペレーターに送信して最終計算とデータ出力をトリガーすることができません。最終計算とデータ出力は、次の条件のいずれかが満たされた場合にのみトリガーされます。管理メモリがいっぱいになった場合、CHECKPOINT コマンドを受信し、チェックポイントが実行されていない場合、およびジョブがキャンセルされた場合。詳細については、「table.exec.mini-batch.size」をご参照ください。チェックポイント間隔が過度に大きな値に設定されています。 LocalGroupAggregate オペレーターは長時間データ出力をトリガーしません。
解決策
チェックポイントの間隔を短縮します。 これにより、LocalGroupAggregate オペレーターはチェックポイントが実行される前に自動的にデータ出力をトリガーできます。 チェックポイント間隔の設定の詳細については、「Tuning Checkpointing」をご参照ください。
ヒープメモリを使用してデータをキャッシュします。これにより、LocalGroupAggregate オペレーターにキャッシュされたデータ量が table.exec.mini-batch.size パラメーターの値に達すると、データ出力が自動的にトリガーされます。
table.exec.mini-batch.sizeパラメーターを正の値 N に設定します。詳細については、「ジョブのカスタムランタイムパラメーターを構成するにはどうすればよいですか?」をご参照ください。
アップストリーム Kafka コネクタのパーティションにデータが入力されていません。その結果、ウォーターマークが先に進めず、ウィンドウ出力が遅延します。どうすればよいですか?
たとえば、アップストリーム Kafka コネクタに 5 つのパーティションが存在し、Kafka に 1 分ごとに 2 つの新しいデータエントリが入力されるとします。ただし、一部のパーティションはリアルタイムでデータエントリを受信しません。タイムアウト期間内にパーティションが要素を受信しない場合、そのパーティションは一時的にアイドル状態としてマークされます。その結果、ウォーターマークが先に進めず、ウィンドウをできるだけ早く終了できず、結果をリアルタイムで生成できません。
この場合、パーティションにデータがないことを指定するためにタイムアウト期間を設定する必要があります。こうすることで、ウォーターマークの計算からパーティションを除外できます。パーティションにデータがあると識別された場合は、ウォーターマークの計算にパーティションを含めることができます。詳細については、「構成」をご参照ください。
[構成] タブの [パラメーター] セクションにある [その他の構成] フィールドに次のコードを追加します。詳細については、「ジョブのカスタムランタイムパラメーターを構成するにはどうすればよいですか?」をご参照ください。
table.exec.source.idle-timeout: 1sJobManager が実行されていない場合、エラーはどこで確認できますか?
[flink UI] ページは、JobManager が想定どおりに実行されていないために表示されません。エラーの原因を特定するには、次の手順を実行します。
Realtime Compute for Apache Flink の開発コンソールの左側のナビゲーションウィンドウで、 を選択します。 [デプロイメント] ページで、目的のジョブを見つけて、ジョブの名前をクリックします。
[イベント] タブをクリックします。
エラーを検索してエラー情報を取得するには、オペレーティングシステムのショートカットキーを使用します。
Windows: Ctrl+F
macOS: Command+F

エラーメッセージ「INFO: org.apache.flink.fs.osshadoop.shaded.com.aliyun.oss」が表示された場合はどうすればよいですか?
問題の説明

原因
データは [OSS バケット] に保存されます。 OSS がディレクトリを作成すると、OSS はディレクトリが存在するかどうかを確認します。ディレクトリが存在しない場合、「INFO: org.apache.flink.fs.osshadoop.shaded.com.aliyun.oss」というエラーメッセージが表示されます。 Realtime Compute for Apache Flink のジョブは影響を受けません。
解決策
<Logger level="ERROR" name="org.apache.flink.fs.osshadoop.shaded.com.aliyun.oss"/>をログテンプレートに追加します。詳細については、「ジョブログ出力を構成する」をご参照ください。
エラーメッセージ「akka.pattern.AskTimeoutException」が表示された場合はどうすればよいですか?
原因
JobManager または TaskManager のメモリが不足しているため、ガベージコレクション(GC)操作が頻繁に実行されます。その結果、JobManager と TaskManager 間のハートビートおよびリモートプロシージャコール(RPC)リクエストがタイムアウトします。
ジョブに多数の RPC リクエストが存在しますが、JobManager リソースが不足しています。その結果、RPC リクエストのバックログが発生します。これにより、JobManager と TaskManager 間のハートビートおよび RPC リクエストがタイムアウトします。
ジョブのタイムアウト期間が過度に小さい値に設定されています。 Realtime Compute for Apache Flink がサードパーティサービスにアクセスできない場合、Realtime Compute for Apache Flink はサービスにアクセスするために複数回再試行します。その結果、指定されたタイムアウト期間に達する前に、接続失敗のエラーは報告されません。
解決策
問題が GC 操作によって発生した場合、ジョブメモリと GC ログに基づいて GC の頻度と GC 操作に消費される時間を確認することをお勧めします。 GC の頻度が高い場合、または GC 操作に長時間かかる場合は、JobManager メモリと TaskManager メモリを増やす必要があります。
問題がジョブに多数の RPC リクエストが存在することによって発生した場合、JobManager の CPU コア数とメモリサイズを増やし、
akka.ask.timeoutパラメーターとheartbeat.timeoutパラメーターを大きな値に設定することをお勧めします。重要akka.ask.timeout パラメーターと heartbeat.timeout パラメーターの値は、ジョブに多数の RPC リクエストが存在する場合にのみ調整することをお勧めします。少数の RPC リクエストが存在するジョブでは、パラメーターの小さい値は問題を引き起こしません。
ビジネス要件に基づいてパラメーターを構成することをお勧めします。パラメーターを過度に大きな値に設定すると、TaskManager が予期せず終了した場合にジョブを再開するために必要な時間が長くなります。
問題がサードパーティサービスの接続エラーによって発生した場合は、次のパラメーターの値を増やして接続エラーが報告されるようにし、問題を解決します。
client.timeout: デフォルト値: 60。推奨値: 600。単位: 秒。akka.ask.timeout: デフォルト値: 10。推奨値: 600。単位: 秒。client.heartbeat.timeout: デフォルト値: 180000、推奨値: 600000、単位: 秒。説明エラーを防ぐため、値に単位を含めないでください。
heartbeat.timeout: デフォルト値: 50000。推奨値: 600000。単位: ミリ秒。説明エラーを防ぐため、値に単位を含めないでください。
たとえば、「
"Caused by: java.sql.SQLTransientConnectionException: connection-pool-xxx.mysql.rds.aliyuncs.com:3306 - Connection is not available, request timed out after 30000ms"」というエラーメッセージが表示された場合、MySQL 接続プールがいっぱいです。この場合、MySQL の WITH パラメーターで説明されているconnection.pool.sizeパラメーターの値を増やす必要があります。デフォルト値: 20。説明上記のエラーメッセージに基づいて、上記のパラメーターの最小値を決定できます。エラーメッセージの値は、上記のパラメーターの値を調整できる値を示しています。たとえば、「
"pattern.AskTimeoutException: Ask timed out on [Actor[akka://flink/user/rpc/dispatcher_1#1064915964]] after [60000 ms]."」というエラーメッセージの「 60000 ms 」は、client.timeoutパラメーターの値です。
エラーメッセージ「Task did not exit gracefully within 180 + seconds.」が表示された場合はどうすればよいですか。
問題の説明
Task did not exit gracefully within 180 + seconds. 2022-04-22T17:32:25.852861506+08:00 stdout F org.apache.flink.util.FlinkRuntimeException: Task did not exit gracefully within 180 + seconds. 2022-04-22T17:32:25.852865065+08:00 stdout F at org.apache.flink.runtime.taskmanager.Task$TaskCancelerWatchDog.run(Task.java:1709) [flink-dist_2.11-1.12-vvr-3.0.4-SNAPSHOT.jar:1.12-vvr-3.0.4-SNAPSHOT] 2022-04-22T17:32:25.852867996+08:00 stdout F at java.lang.Thread.run(Thread.java:834) [?:1.8.0_102] // ログレベル:エラー log_level:ERROR原因
エラーメッセージは、ジョブ例外の根本原因を示していません。タスクが終了するまでのタイムアウト期間は、
task.cancellation.timeoutパラメーターで指定されます。パラメーターのデフォルト値は 180 秒です。ジョブがフェールオーバーを実行する場合、またはジョブ内のタスクが終了しようとすると、特定の理由によりタスクがブロックされ、終了できない場合があります。タスクがブロックされている期間がタスクの終了タイムアウト期間に達すると、Realtime Compute for Apache Flink はタスクがスタックしており、再開できないと判断します。次に、Realtime Compute for Apache Flink は、タスクが属する TaskManager を自動的に停止して、ジョブがフェールオーバーを実行したり、タスクが終了したりできるようにします。その結果、ジョブのログにエラーメッセージが表示されます。タイムアウトの問題は、ジョブで使用されているユーザー定義関数 (UDF) が原因である可能性があります。たとえば、ジョブで close メソッドを使用すると、ジョブ内のタスクが長時間ブロックされて終了できないか、長時間値が返されません。
解決策
task.cancellation.timeoutパラメーターを 0 に設定します。このパラメーターの構成方法の詳細については、「ジョブのカスタムランタイムパラメーターを構成するにはどうすればよいですか?」をご参照ください。このパラメーターを 0 に設定すると、タスクがブロックされている場合、タスクは終了するまで待機します。この場合、タイムアウトは発生しません。ジョブを再起動した後にジョブが再びフェールオーバーを実行する場合、またはタスクが終了しようとするときにジョブ内のタスクが長時間ブロックされている場合は、CANCELLING 状態のタスクを見つけてタスクのスタックを確認し、問題の根本原因を特定してから、根本原因に基づいて問題を解決する必要があります。重要task.cancellation.timeoutパラメーターはジョブのデバッグに使用されます。本番環境のジョブでは、このパラメーターを 0 に設定しないことをお勧めします。
「存在しないレコードを格納できません。これは発生しないはずです。」というエラーメッセージが表示された場合はどうすればよいですか?
問題の説明
java.lang.RuntimeException: Can not retract a non-existent record. This should never happen. at org.apache.flink.table.runtime.operators.rank.RetractableTopNFunction.processElement(RetractableTopNFunction.java:196) at org.apache.flink.table.runtime.operators.rank.RetractableTopNFunction.processElement(RetractableTopNFunction.java:55) at org.apache.flink.streaming.api.operators.KeyedProcessOperator.processElement(KeyedProcessOperator.java:83) at org.apache.flink.streaming.runtime.tasks.OneInputStreamTask$StreamTaskNetworkOutput.emitRecord(OneInputStreamTask.java:205) at org.apache.flink.streaming.runtime.io.AbstractStreamTaskNetworkInput.processElement(AbstractStreamTaskNetworkInput.java:135) at org.apache.flink.streaming.runtime.io.AbstractStreamTaskNetworkInput.emitNext(AbstractStreamTaskNetworkInput.java:106) at org.apache.flink.streaming.runtime.io.StreamOneInputProcessor.processInput(StreamOneInputProcessor.java:66) at org.apache.flink.streaming.runtime.tasks.StreamTask.processInput(StreamTask.java:424) at org.apache.flink.streaming.runtime.tasks.mailbox.MailboxProcessor.runMailboxLoop(MailboxProcessor.java:204) at org.apache.flink.streaming.runtime.tasks.StreamTask.runMailboxLoop(StreamTask.java:685) at org.apache.flink.streaming.runtime.tasks.StreamTask.executeInvoke(StreamTask.java:640) at org.apache.flink.streaming.runtime.tasks.StreamTask.runWithCleanUpOnFail(StreamTask.java:651) at org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:624) at org.apache.flink.runtime.taskmanager.Task.doRun(Task.java:799) at org.apache.flink.runtime.taskmanager.Task.run(Task.java:586) at java.lang.Thread.run(Thread.java:877)原因と解決策
シナリオ
原因
解決策
シナリオ 1
問題は、コード内の
now()関数が原因です。TopN アルゴリズムでは、非決定性フィールドを ORDER BY 句または PARTITION BY 句のフィールドとして使用することはできません。非決定性フィールドが ORDER BY 句または PARTITION BY 句のフィールドとして使用されている場合、
now()関数から返される出力値は異なります。その結果、メッセージで前の値が見つかりません。ORDER BY 句または PARTITION BY 句のフィールドとして、決定性フィールドを使用します。
シナリオ 2
table.exec.state.ttlパラメーターが過度に小さい値に設定されています。状態データは有効期限が切れているため削除されます。その結果、メッセージでキー状態データが見つかりません。table.exec.state.ttlパラメーターの値を増やします。このパラメーターの構成方法の詳細については、「ジョブのカスタムランタイムパラメーターを構成するにはどうすればよいですか?」をご参照ください。
エラーメッセージ「sqlserver で GRPC 呼び出しがタイムアウトしました」が表示された場合はどうすればよいですか?
問題の説明
org.apache.flink.table.sqlserver.utils.ExecutionTimeoutException: The GRPC call timed out in sqlserver, please check the thread stacktrace for root cause: // sqlserver で GRPC 呼び出しがタイムアウトしました。根本原因については、スレッドスタックトレースを確認してください。 Thread name: sqlserver-operation-pool-thread-4, thread state: TIMED_WAITING, thread stacktrace: // スレッド名:sqlserver-operation-pool-thread-4、スレッド状態:TIMED_WAITING、スレッドスタックトレース: at java.lang.Thread.sleep0(Native Method) at java.lang.Thread.sleep(Thread.java:360) at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.processWaitTimeAndRetryInfo(RetryInvocationHandler.java:130) at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invokeOnce(RetryInvocationHandler.java:107) at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:359) at com.sun.proxy.$Proxy195.getFileInfo(Unknown Source) at org.apache.hadoop.hdfs.DFSClient.getFileInfo(DFSClient.java:1661) at org.apache.hadoop.hdfs.DistributedFileSystem$29.doCall(DistributedFileSystem.java:1577) at org.apache.hadoop.hdfs.DistributedFileSystem$29.doCall(DistributedFileSystem.java:1574) at org.apache.hadoop.fs.FileSystemLinkResolver.resolve(FileSystemLinkResolver.java:81) at org.apache.hadoop.hdfs.DistributedFileSystem.getFileStatus(DistributedFileSystem.java:1589) at org.apache.hadoop.fs.FileSystem.exists(FileSystem.java:1683) at org.apache.flink.connectors.hive.HiveSourceFileEnumerator.getNumFiles(HiveSourceFileEnumerator.java:118) at org.apache.flink.connectors.hive.HiveTableSource.lambda$getDataStream$0(HiveTableSource.java:209) at org.apache.flink.connectors.hive.HiveTableSource$$Lambda$972/1139330351.get(Unknown Source) at org.apache.flink.connectors.hive.HiveParallelismInference.logRunningTime(HiveParallelismInference.java:118) at org.apache.flink.connectors.hive.HiveParallelismInference.infer(HiveParallelismInference.java:100) at org.apache.flink.connectors.hive.HiveTableSource.getDataStream(HiveTableSource.java:207) at org.apache.flink.connectors.hive.HiveTableSource$1.produceDataStream(HiveTableSource.java:123) at org.apache.flink.table.planner.plan.nodes.exec.common.CommonExecTableSourceScan.translateToPlanInternal(CommonExecTableSourceScan.java:127) at org.apache.flink.table.planner.plan.nodes.exec.ExecNodeBase.translateToPlan(ExecNodeBase.java:226) at org.apache.flink.table.planner.plan.nodes.exec.ExecEdge.translateToPlan(ExecEdge.java:290) at org.apache.flink.table.planner.plan.nodes.exec.ExecNodeBase.lambda$translateInputToPlan$5(ExecNodeBase.java:267) at org.apache.flink.table.planner.plan.nodes.exec.ExecNodeBase$$Lambda$949/77002396.apply(Unknown Source) at java.util.stream.ReferencePipeline$3$1.accept(ReferencePipeline.java:193) at java.util.stream.ReferencePipeline$2$1.accept(ReferencePipeline.java:175) at java.util.ArrayList$ArrayListSpliterator.forEachRemaining(ArrayList.java:1374) at java.util.stream.AbstractPipeline.copyInto(AbstractPipeline.java:481) at java.util.stream.AbstractPipeline.wrapAndCopyInto(AbstractPipeline.java:471) at java.util.stream.ReduceOps$ReduceOp.evaluateSequential(ReduceOps.java:708) at java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:234) at java.util.stream.ReferencePipeline.collect(ReferencePipeline.java:499) at org.apache.flink.table.planner.plan.nodes.exec.ExecNodeBase.translateInputToPlan(ExecNodeBase.java:268) at org.apache.flink.table.planner.plan.nodes.exec.ExecNodeBase.translateInputToPlan(ExecNodeBase.java:241) at org.apache.flink.table.planner.plan.nodes.exec.stream.StreamExecExchange.translateToPlanInternal(StreamExecExchange.java:87) at org.apache.flink.table.planner.plan.nodes.exec.ExecNodeBase.translateToPlan(ExecNodeBase.java:226) at org.apache.flink.table.planner.plan.nodes.exec.ExecEdge.translateToPlan(ExecEdge.java:290) at org.apache.flink.table.planner.plan.nodes.exec.ExecNodeBase.lambda$translateInputToPlan$5(ExecNodeBase.java:267) at org.apache.flink.table.planner.plan.nodes.exec.ExecNodeBase$$Lambda$949/77002396.apply(Unknown Source) at java.util.stream.ReferencePipeline$3$1.accept(ReferencePipeline.java:193) at java.util.stream.ReferencePipeline$2$1.accept(ReferencePipeline.java:175) at java.util.ArrayList$ArrayListSpliterator.forEachRemaining(ArrayList.java:1374) at java.util.stream.AbstractPipeline.copyInto(AbstractPipeline.java:481) at java.util.stream.AbstractPipeline.wrapAndCopyInto(AbstractPipeline.java:471) at java.util.stream.ReduceOps$ReduceOp.evaluateSequential(ReduceOps.java:708) at java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:234) at java.util.stream.ReferencePipeline.collect(ReferencePipeline.java:499) at org.apache.flink.table.planner.plan.nodes.exec.ExecNodeBase.translateInputToPlan(ExecNodeBase.java:268) at org.apache.flink.table.planner.plan.nodes.exec.ExecNodeBase.translateInputToPlan(ExecNodeBase.java:241) at org.apache.flink.table.planner.plan.nodes.exec.stream.StreamExecGroupAggregate.translateToPlanInternal(StreamExecGroupAggregate.java:148) at org.apache.flink.table.planner.plan.nodes.exec.ExecNodeBase.translateToPlan(ExecNodeBase.java:226) at org.apache.flink.table.planner.plan.nodes.exec.ExecEdge.translateToPlan(ExecEdge.java:290) at org.apache.flink.table.planner.plan.nodes.exec.ExecNodeBase.lambda$translateInputToPlan$5(ExecNodeBase.java:267) at org.apache.flink.table.planner.plan.nodes.exec.ExecNodeBase$$Lambda$949/77002396.apply(Unknown Source) at java.util.stream.ReferencePipeline$3$1.accept(ReferencePipeline.java:193) at java.util.stream.ReferencePipeline$2$1.accept(ReferencePipeline.java:175) at java.util.ArrayList$ArrayListSpliterator.forEachRemaining(ArrayList.java:1374) at java.util.stream.AbstractPipeline.copyInto(AbstractPipeline.java:481) at java.util.stream.AbstractPipeline.wrapAndCopyInto(AbstractPipeline.java:471) at java.util.stream.ReduceOps$ReduceOp.evaluateSequential(ReduceOps.java:708) at java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:234) at java.util.stream.ReferencePipeline.collect(ReferencePipeline.java:499) at org.apache.flink.table.planner.plan.nodes.exec.ExecNodeBase.translateInputToPlan(ExecNodeBase.java:268) at org.apache.flink.table.planner.plan.nodes.exec.ExecNodeBase.translateInputToPlan(ExecNodeBase.java:241) at org.apache.flink.table.planner.plan.nodes.exec.stream.StreamExecSink.translateToPlanInternal(StreamExecSink.java:108) at org.apache.flink.table.planner.plan.nodes.exec.ExecNodeBase.translateToPlan(ExecNodeBase.java:226) at org.apache.flink.table.planner.delegation.StreamPlanner$$anonfun$1.apply(StreamPlanner.scala:74) at org.apache.flink.table.planner.delegation.StreamPlanner$$anonfun$1.apply(StreamPlanner.scala:73) at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:234) at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:234) at scala.collection.Iterator$class.foreach(Iterator.scala:891) at scala.collection.AbstractIterator.foreach(Iterator.scala:1334) at scala.collection.IterableLike$class.foreach(IterableLike.scala:72) at scala.collection.AbstractIterable.foreach(Iterable.scala:54) at scala.collection.TraversableLike$class.map(TraversableLike.scala:234) at scala.collection.AbstractTraversable.map(Traversable.scala:104) at org.apache.flink.table.planner.delegation.StreamPlanner.translateToPlan(StreamPlanner.scala:73) at org.apache.flink.table.planner.delegation.StreamExecutor.createStreamGraph(StreamExecutor.java:52) at org.apache.flink.table.planner.delegation.PlannerBase.createStreamGraph(PlannerBase.scala:610) at org.apache.flink.table.planner.delegation.StreamPlanner.explainExecNodeGraphInternal(StreamPlanner.scala:166) at org.apache.flink.table.planner.delegation.StreamPlanner.explainExecNodeGraph(StreamPlanner.scala:159) at org.apache.flink.table.sqlserver.execution.OperationExecutorImpl.validate(OperationExecutorImpl.java:304) at org.apache.flink.table.sqlserver.execution.OperationExecutorImpl.validate(OperationExecutorImpl.java:288) at org.apache.flink.table.sqlserver.execution.DelegateOperationExecutor.lambda$validate$22(DelegateOperationExecutor.java:211) at org.apache.flink.table.sqlserver.execution.DelegateOperationExecutor$$Lambda$394/1626790418.run(Unknown Source) at org.apache.flink.table.sqlserver.execution.DelegateOperationExecutor.wrapClassLoader(DelegateOperationExecutor.java:250) at org.apache.flink.table.sqlserver.execution.DelegateOperationExecutor.lambda$wrapExecutor$26(DelegateOperationExecutor.java:275) at org.apache.flink.table.sqlserver.execution.DelegateOperationExecutor$$Lambda$395/1157752141.run(Unknown Source) at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) at java.util.concurrent.FutureTask.run(FutureTask.java:266) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1147) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:622) at java.lang.Thread.run(Thread.java:834) at org.apache.flink.table.sqlserver.execution.DelegateOperationExecutor.wrapExecutor(DelegateOperationExecutor.java:281) at org.apache.flink.table.sqlserver.execution.DelegateOperationExecutor.validate(DelegateOperationExecutor.java:211) at org.apache.flink.table.sqlserver.FlinkSqlServiceImpl.validate(FlinkSqlServiceImpl.java:786) at org.apache.flink.table.sqlserver.proto.FlinkSqlServiceGrpc$MethodHandlers.invoke(FlinkSqlServiceGrpc.java:2522) at io.grpc.stub.ServerCalls$UnaryServerCallHandler$UnaryServerCallListener.onHalfClose(ServerCalls.java:172) at io.grpc.internal.ServerCallImpl$ServerStreamListenerImpl.halfClosed(ServerCallImpl.java:331) at io.grpc.internal.ServerImpl$JumpToApplicationThreadServerStreamListener$1HalfClosed.runInContext(ServerImpl.java:820) at io.grpc.internal.ContextRunnable.run(ContextRunnable.java:37) at io.grpc.internal.SerializingExecutor.run(SerializingExecutor.java:123) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1147) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:622) at java.lang.Thread.run(Thread.java:834) Caused by: java.util.concurrent.TimeoutException // タイムアウトの例外 at java.util.concurrent.FutureTask.get(FutureTask.java:205) at org.apache.flink.table.sqlserver.execution.DelegateOperationExecutor.wrapExecutor(DelegateOperationExecutor.java:277) ... 11 more原因
ドラフトで複雑な SQL 文が使用されています。その結果、リモートプロシージャコール ( RPC ) の実行がタイムアウトします。
解決策
[構成] タブの [パラメーター] セクションにある [その他の構成] フィールドに次のコードを追加して、RPC 実行のタイムアウト期間を増やします。デフォルトのタイムアウト期間は 120 秒です。詳細については、「デプロイメント実行のカスタムパラメーターを構成するにはどうすればよいですか?」をご参照ください。
flink.sqlserver.rpc.execution.timeout: 600s
エラーメッセージ「RESOURCE_EXHAUSTED: gRPC message exceeds maximum size 41943040: 58384051」が表示された場合はどうすればよいですか?
問題の説明
Caused by: io.grpc.StatusRuntimeException: RESOURCE_EXHAUSTED: gRPC message exceeds maximum size 41943040: 58384051 at io.grpc.stub.ClientCalls.toStatusRuntimeException(ClientCalls.java:244) at io.grpc.stub.ClientCalls.getUnchecked(ClientCalls.java:225) at io.grpc.stub.ClientCalls.blockingUnaryCall(ClientCalls.java:142) at org.apache.flink.table.sqlserver.proto.FlinkSqlServiceGrpc$FlinkSqlServiceBlockingStub.generateJobGraph(FlinkSqlServiceGrpc.java:2478) at org.apache.flink.table.sqlserver.api.client.FlinkSqlServerProtoClientImpl.generateJobGraph(FlinkSqlServerProtoClientImpl.java:456) at org.apache.flink.table.sqlserver.api.client.ErrorHandlingProtoClient.lambda$generateJobGraph$25(ErrorHandlingProtoClient.java:251) at org.apache.flink.table.sqlserver.api.client.ErrorHandlingProtoClient.invokeRequest(ErrorHandlingProtoClient.java:335) ... 6 more Cause: RESOURCE_EXHAUSTED: gRPC message exceeds maximum size 41943040: 58384051)原因
複雑なドラフトロジックのため、JobGraph のサイズが過度に大きくなっています。その結果、ドラフトの検証中にエラーが発生するか、ドラフトのジョブの開始またはキャンセルに失敗します。
解決策
[構成] タブの [パラメーター] セクションにある [その他の構成] フィールドに次のコードを追加します。詳細については、「ジョブのカスタムランタイムパラメーターを構成するにはどうすればよいですか?」をご参照ください。
table.exec.operator-name.max-length: 1000
エラーメッセージ「Caused by: java.lang.NoSuchMethodError」が表示された場合はどうすればよいですか?
問題の説明
エラーメッセージ: Caused by: java.lang.NoSuchMethodError: org.apache.flink.table.planner.plan.metadata.FlinkRelMetadataQuery.getUpsertKeysInKeyGroupRange(Lorg/apache/calcite/rel/RelNode;[I)Ljava/util/Set;原因
開発中のドラフトが Apache Flink コミュニティによって提供される内部 API を呼び出し、その内部 API が Alibaba Cloud によって最適化されている場合、パッケージの競合などの例外が発生する可能性があります。
解決策
Apache Flink のソースコードで @Public または @PublicEvolving と明示的にマークされているメソッドのみを呼び出すようにドラフトを設定します。Alibaba Cloud は、Realtime Compute for Apache Flink がこれらのメソッドと互換性があることのみを保証します。
「java.lang.ClassCastException: org.codehaus.janino.CompilerFactory cannot be cast to org.codehaus.commons.compiler.ICompilerFactory」というエラーメッセージが表示された場合の対処方法
問題の説明
Causedby:java.lang.ClassCastException:org.codehaus.janino.CompilerFactorycannotbecasttoorg.codehaus.commons.compiler.ICompilerFactory atorg.codehaus.commons.compiler.CompilerFactoryFactory.getCompilerFactory(CompilerFactoryFactory.java:129) atorg.codehaus.commons.compiler.CompilerFactoryFactory.getDefaultCompilerFactory(CompilerFactoryFactory.java:79) atorg.apache.calcite.rel.metadata.JaninoRelMetadataProvider.compile(JaninoRelMetadataProvider.java:426) ...66more原因
JAR パッケージに、競合を引き起こす Janino 依存関係が含まれています。
Flink-で始まる特定の JAR パッケージ (flink-table-planner、flink-table-runtime など) が、ユーザー定義関数 (UDF) またはコネクタの JAR パッケージに追加されます。
解決策
JAR パッケージに org.codehaus.janino.CompilerFactory が含まれているかどうかを確認します。 マシンによってクラスのロード順序が異なるため、クラスの競合が発生する可能性があります。 この問題を解決するには、次の手順を実行します。
Realtime Compute for Apache Flink の開発コンソールの左側のナビゲーションウィンドウで、 を選択します。 [デプロイメント] ページで、目的のジョブを見つけて、ジョブの名前をクリックします。
ジョブ詳細ページの [構成] タブで、[パラメーター] セクションの右上隅にある [編集] をクリックします。
[その他の構成] フィールドに次のコードを追加し、[保存] をクリックします。
classloader.parent-first-patterns.additional: org.codehaus.janinoclassloader.parent-first-patterns.additional パラメーターの値を競合クラスに置き換えます。
Apache Flink 依存関係に
<scope>provided</scope>を指定します。flink-で始まるorg.apache.flinkグループの非コネクタ依存関係が主に必要です。