このトピックでは、Realtime Compute for Apache Flink でのデータの妥当性に関するよくある質問 (FAQ) に回答します。
シンクテーブルに出力がないのはなぜですか?
ジョブが開始された後、シンクテーブルにデータが表示されません。次のチェック項目を順番に確認してください。
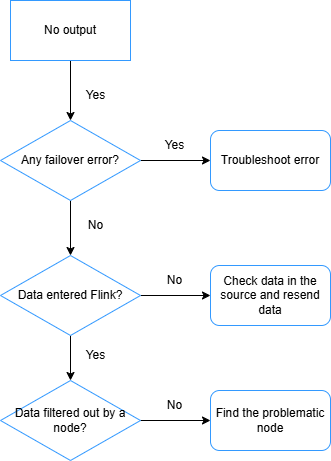
-
フェールオーバーの確認: ジョブがフェールオーバーした場合、エラーメッセージを分析して根本原因を特定し、問題を解決してジョブが期待どおりに実行されるようにしてください。
-
データが Realtime Compute for Apache Flink に到達しているかの検証: フェールオーバーが発生していないにもかかわらず、データレイテンシーが非常に高い場合は、モニタリングとアラートページで
numRecordsInOfSourceメトリックを確認してください。ソースのメトリックがゼロの場合、ソーステーブルから Flink にデータが送信されていません。アップストリームのデータソースを調査してください。 -
オペレーターがすべてのレコードをフィルタリングしていないかの確認: [Other Configuration] フィールドに
pipeline.operator-chaining: 'false'を追加してください (詳細については、「ジョブのカスタム実行パラメーターを設定する方法」をご参照ください)。これにより、オペレーターチェーンが分割され、各オペレーターの [Bytes Received] および [Bytes Sent] メトリックを個別に検査できます。入力はあるが出力がゼロのオペレーターが原因です。一般的な原因としては、JOIN、WINDOW、WHERE が考えられます。 -
ダウンストリームデータベースが書き込みバッファにデータを保持していないかの確認: ダウンストリームコネクタのバッチサイズを小さくして、データをより早くフラッシュしてください。
重要バッチサイズを極端に小さくすることは避けてください。バッチサイズが 1 の場合、Flink は処理されるレコードごとに個別のリクエストを送信するため、データ量が多い場合にはダウンストリームデータベースに過負荷をかける可能性があります。
-
ApsaraDB RDS for MySQL のデッドロックの確認: 「ApsaraDB RDS または TDDL コネクタを介して MySQL に書き込む際のデッドロック」をご参照ください。
問題を切り分けるには、プリントシンクテーブルを使用して中間結果をログに出力してください。「プリントコネクタの出力を表示する」をご参照ください。
CDC での MiniBatch 有効化と部分的な binlog 消費に起因する空の出力
-
現象
CDC ジョブが
latestまたは特定のオフセットを使用して binlog の途中から消費を開始し、MiniBatch が有効になっている場合に、シンクテーブルが部分的なデータしか受信しないか、まったく出力されなくなります。 -
原因
MiniBatch は、バッチ内で同じプライマリキーを持つ変更ログメッセージをマージし、相殺します。ジョブが binlog の途中から開始されると、対応する
UPDATE_BEFOREがないUPDATE_AFTER(またはその逆) を受信する可能性があります。これらの対になるメッセージがバッチ内で互いに相殺され、出力が生成されなくなるため、ダウンストリームのデータが不正確になります。 -
解決策
-
binlog を最初から消費してください。
latestや指定されたオフセットなどの部分的な消費モードを避けることで、すべてのレコードの完全な変更シーケンスが保持されます。 -
MiniBatch を無効にし、ジョブがレコードを 1 つずつ処理するようにしてください。このオプションは、正確性のためにスループットの一部を犠牲にします。
-
Flink のソース読み取りに関する問題のトラブルシューティング
Realtime Compute for Apache Flink がソースから読み取りできない場合は、以下を確認してください。
ネットワーク接続性
デフォルトでは、Realtime Compute for Apache Flink は同じリージョンおよび仮想プライベートクラウド (VPC) 内のサービスにのみアクセスできます。クロスネットワークアクセスについては、以下をご参照ください:
-
VPC 間:「VPC をまたいで他のサービスにアクセスする方法」
-
インターネットアクセス:「インターネットにアクセスする方法」
アップストリームサービスのホワイトリスト
Kafka や Elasticsearch などのサービスから読み取るには、Flink ワークスペースをそれらのホワイトリストに追加してください:
-
Flink ワークスペースの vSwitch の CIDR ブロックを取得してください。「ホワイトリストを設定する方法」をご参照ください。
-
その CIDR ブロックをアップストリームサービスのホワイトリストに追加してください。コネクタドキュメントの「前提条件」セクションをご参照ください。例:Kafka。
Flink テーブルと物理テーブル間のフィールドの一貫性
フィールド定義の不一致は、読み取り失敗の一般的な原因です。Flink ソーステーブルの DDL を記述する際は、以下にご注意ください:
-
フィールドの順序: 物理テーブルのフィールド順序と完全に一致させてください。
-
フィールド名の大文字/小文字: 物理テーブルと同じ大文字/小文字を使用してください。
-
フィールドの型: マッピングされた同等の型を使用してください。関連するコネクタドキュメントの「データ型マッピング」セクションを確認してください。例:Simple Log Service。
TaskManager ログの例外
ソーステーブルの TaskManager ログに例外メッセージが含まれているかどうかを確認してください:
-
左側メニューで、[O&M] > [Deployment] に移動します。
-
デプロイメント名をクリックします。
-
[Status] タブをクリックし、DAG 内のソース頂点をクリックします。
-
右側のパネルで、[SubTasks] タブをクリックします。
-
[More] 列で、
 アイコンをクリックし、[Open TaskManager Log Page] を選択します。
アイコンをクリックし、[Open TaskManager Log Page] を選択します。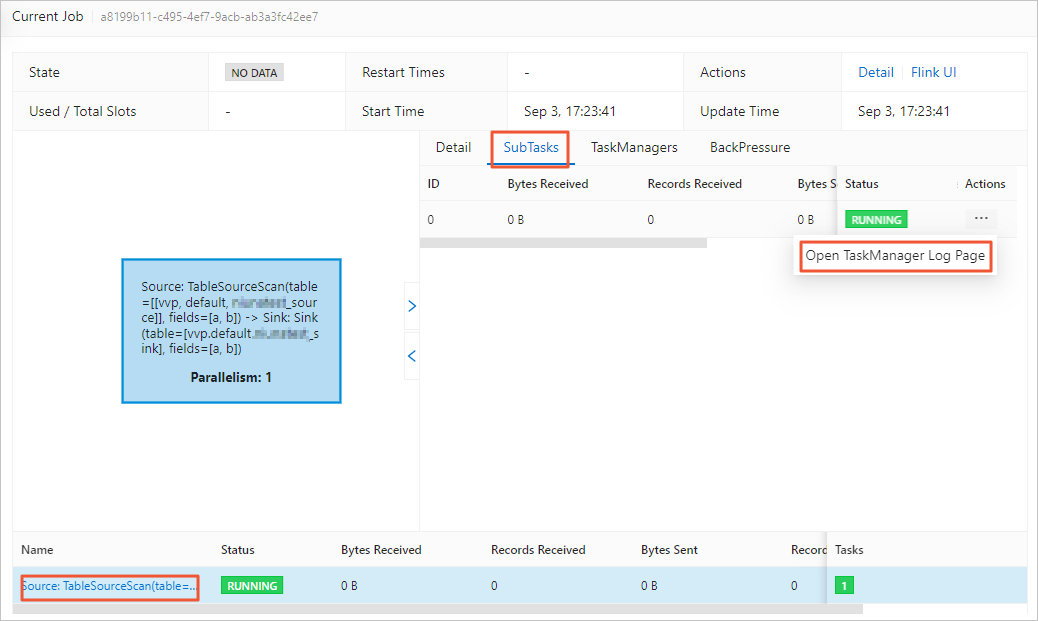
-
[Logs] タブで、「Caused by」を含む最も古いエントリを探してください。これが通常、根本原因を示しています。
ダウンストリームシステムに出力がない場合のトラブルシューティング
次のチェック項目を確認してください。
ネットワーク接続性
デフォルトでは、Realtime Compute for Apache Flink は同じリージョンおよび VPC 内のサービスにのみアクセスできます。クロスネットワークアクセスについては、以下をご参照ください:
-
VPC 間:「VPC をまたいで他のサービスにアクセスする方法」
-
インターネットアクセス:「インターネットにアクセスする方法」
ダウンストリームシステムのホワイトリスト
ApsaraDB RDS for MySQL、Kafka、Elasticsearch、AnalyticDB for MySQL 3.0、Apache HBase、Redis、ClickHouse などのサービスに書き込むには、Flink ワークスペースをそれらのホワイトリストに追加してください:
-
Flink ワークスペースの vSwitch の CIDR ブロックを取得してください。「ホワイトリストを設定する方法」をご参照ください。
-
その CIDR ブロックをダウンストリームサービスのホワイトリストに追加してください。コネクタドキュメントの「前提条件」セクションをご参照ください。例:ApsaraDB RDS for MySQL。
Flink テーブルと物理テーブル間のフィールドの一貫性
「Flink のソース読み取りに関する問題のトラブルシューティング」で説明されているのと同じチェックを行ってください: フィールドの順序、フィールド名の大文字/小文字、およびフィールド型のマッピングを確認してください。
オペレーターによってフィルタリングされたデータ
ジョブ DAG 内の各頂点の入力数と出力数を確認してください。WHERE などの頂点で入力が 5、出力が 0 と表示されている場合、そのオペレーターがすべてのレコードを破棄しています。
シンクコネクタのバッファしきい値が高すぎる
入力量が少ない場合、デフォルトのバッファしきい値が高いと、データがダウンストリームシステムにフラッシュされないことがあります。これは、バッファが書き込みをトリガーするほど満たされないためです。必要に応じて、関連するオプションを減らしてください:
| オプション | 説明 | 関連するダウンストリームサービス |
|---|---|---|
batchSize |
一度に書き込まれるデータのサイズ | DataHub、Tablestore、MongoDB、ApsaraDB RDS for MySQL、AnalyticDB for MySQL V3.0、ApsaraDB for ClickHouse、TSDB for InfluxDB |
batchCount |
一度に書き込まれるレコードの最大数 | DataHub |
flushIntervalMs |
MaxCompute Tunnel Writer バッファのフラッシュ間隔 | MaxCompute |
sink.buffer-flush.max-size |
HBase に書き込む前にメモリにバッファリングされるデータのサイズ (バイト単位) | ApsaraDB for HBase |
sink.buffer-flush.max-rows |
HBase に書き込む前にメモリにバッファリングされるレコードの数 | ApsaraDB for HBase |
sink.buffer-flush.interval |
バッファリングされたデータが定期的に HBase にフラッシュされる間隔 | ApsaraDB for HBase |
jdbcWriteBatchSize |
JDBC ドライバー使用時に Hologres ストリーミングシンクノードが一度に処理する最大行数 | Hologres |
イベント時間ウィンドウ内の順序が乱れたデータ
ウォーターマークは、ウィンドウがどのレコードを受け入れるかを制御します。最初のレコードのタイムスタンプが 2100 で、ウォーターマークが 2100 に設定された場合、2100 より前のタイムスタンプを持つ後続のレコード (2021 など) は遅延と見なされ、破棄されます。ウィンドウは、2100 より大きいタイムスタンプを持つレコードが到着するまで閉じることができません。
順序が乱れたレコードを検出するには、プリントシンクテーブルを使用するか、Log4j ログを確認してください。「プリントシンクテーブルの作成」および「ログ出力の設定」をご参照ください。遅延レコードが確認された場合は、それらをフィルタリングするか、ウォーターマーク戦略を設定して遅延到着のための猶予期間を設けてください。
入力がないソースサブタスク
ソースサブタスクがデータを受信しない場合、そのウォーターマークはエポックのデフォルト (1970-01-01T00:00:00Z) のままとなり、これがオペレーター全体のウォーターマークになります。これにより、イベント時間ウィンドウが閉じられなくなります。
ジョブ DAG を確認し、すべてのソースサブタスクが入力を受信していることを確認してください。アイドル状態のサブタスクがある場合は、ジョブの並列度をアップストリームテーブルのシャード数に合わせて減らし、すべてのサブタスクにデータが割り当てられるようにしてください。
空の Kafka パーティション
空の Kafka パーティションは、ウォーターマークの生成を停止させる可能性があります。「Kafka ソーステーブルからのイベント時間ウィンドウがなぜ出力を生成しないのか?」をご参照ください。
データ損失のトラブルシューティング
データ量の減少は通常、WHERE 句、JOIN、またはウィンドウ操作に起因します。原因不明の損失については、以下を確認してください。
ディメンションテーブルのキャッシュポリシー
不適切なキャッシュポリシーは、ルックアップ結合の失敗を引き起こし、レコードがサイレントにドロップされる原因となる可能性があります。コネクタドキュメントのキャッシュ関連オプションを使用して、適切なキャッシュポリシーを設定してください。例:ApsaraDB for HBase の「ディメンションテーブル固有 (キャッシュパラメーターなど)」セクション。
関数の使用法
to_timestamp_tz や date_format などの関数の不適切な使用は、データ変換の失敗を引き起こし、レコードがサイレントに破棄される原因となる可能性があります。プリントシンクテーブルまたは Log4j ログを使用して、関数の動作を確認してください。「Print」および「ログ出力の設定」をご参照ください。
順序が乱れたデータ
遅延イベントは、そのタイムスタンプが現在のウィンドウの受け入れ範囲外にある場合に破棄されます。たとえば、タイムスタンプが 11 秒のイベントが 15~20 秒のウィンドウに入ると、そのウォーターマークが 11 (ウィンドウの下限未満) であるため破棄されます。
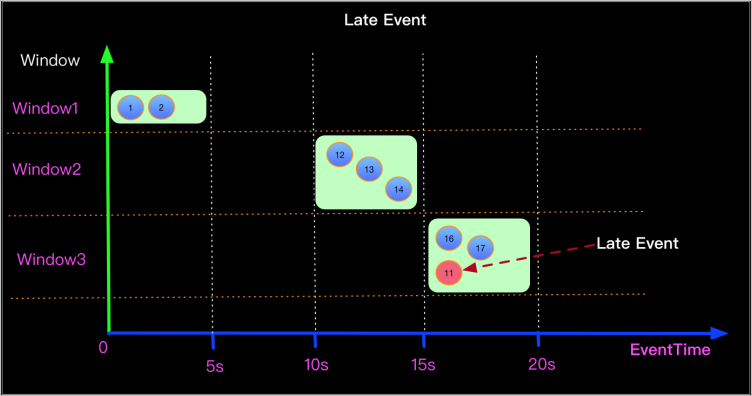
この原因による損失は、通常、単一のウィンドウに集中します。プリントシンクテーブルまたは Log4j を使用して、順序が乱れたデータが存在することを確認してください。
順序の乱れによる損失を最小限に抑えるには、猶予期間を持つウォーターマーク生成戦略を設定してください (例: ウォーターマーク = イベント時間 - 5秒)。ウィンドウを正確な日、時、または分の境界に合わせてください。これにより、ウィンドウの動作が予測可能になり、適切な猶予期間と組み合わせることで、エッジケースでの破棄を減らすことができます。
ROW_NUMBER を使用して CDC モードで Hologres から取り込んだデータを重複排除すると、結果が不正確になるのはなぜですか?
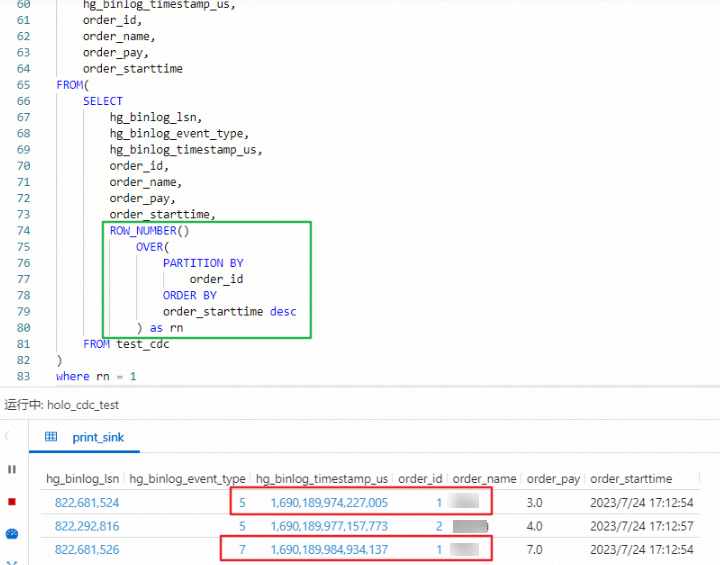
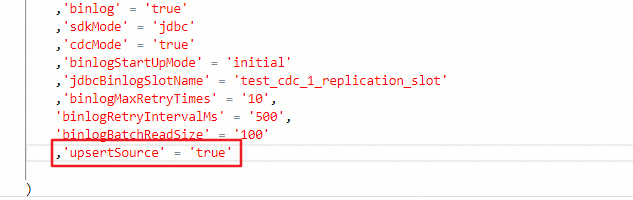
ダウンストリームでは撤回オペレーター (例:重複排除のための ROW_NUMBER OVER WINDOW) を使用していますが、Hologres ソースがアップサートモードでデータを出力するように設定されていません。アップサートモードがないと、ソースは挿入専用のイベントのみを出力するため、撤回オペレーターはそれらを正しく処理できません。
ソーステーブルの DDL ステートメントの WITH 句に 'upsertSource' = 'true' を追加してください。
不正確な結果のトラブルシューティング
-
ジョブのロジックを変更せずに中間結果を検査するために、オペレータープロファイリングを有効にしてください。
-
実行時ログを分析してください:
-
デプロイメント名をクリックし、[Status] タブをクリックします。
-
DAG で、誤った結果を生成しているオペレーターの名前をコピーします。
-
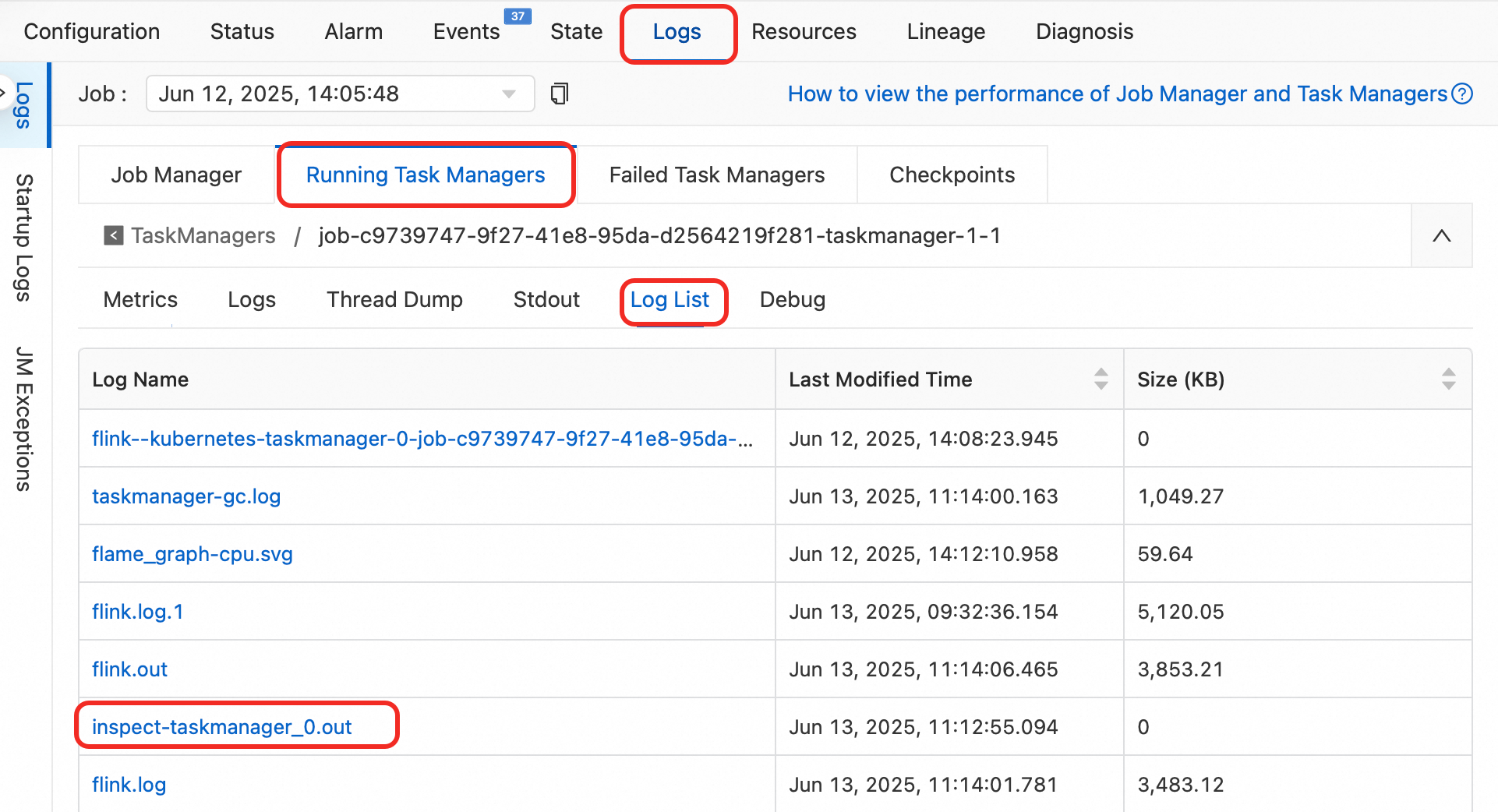
ログリストで、[Log Name] の下にある
inspect-taskmanager_0.outをクリックし、オペレーター名を検索してください。
-
-
根本原因を特定した後、オペレーターのロジックを修正し、ジョブを再起動して、データの正確性を確認してください。
「doesn't support consuming update and delete changes which is produced by node TableSourceScan」エラーの修正
エラーメッセージは次のようになります:
Table sink 'vvp.default.***' doesn't support consuming update and delete changes which is produced by node TableSourceScan(table=[[vvp, default, ***]], fields=[id,b, content])
at org.apache.flink.table.sqlserver.execution.DelegateOperationExecutor.wrapExecutor(DelegateOperationExecutor.java:286)
at org.apache.flink.table.sqlserver.execution.DelegateOperationExecutor.validate(DelegateOperationExecutor.java:211)
at org.apache.flink.table.sqlserver.FlinkSqlServiceImpl.validate(FlinkSqlServiceImpl.java:741)
at org.apache.flink.table.sqlserver.proto.FlinkSqlServiceGrpc$MethodHandlers.invoke(FlinkSqlServiceGrpc.java:2522)
at io.grpc.stub.ServerCalls$UnaryServerCallHandler$UnaryServerCallListener.onHalfClose(ServerCalls.java:172)
at io.grpc.internal.ServerCallImpl$ServerStreamListenerImpl.halfClosed(ServerCallImpl.java:331)
at io.grpc.internal.ServerImpl$JumpToApplicationThreadServerStreamListener$1HalfClosed.runInContext(ServerImpl.java:820)
at io.grpc.internal.ContextRunnable.run(ContextRunnable.java:37)
at io.grpc.internal.SerializingExecutor.run(SerializingExecutor.java:123)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1147)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:622)
at java.lang.Thread.run(Thread.java:834)シンクテーブルが追記専用モードになっており、ソースからの更新または削除イベントを消費できません。これを、Upsert Kafka のようなアップサートをサポートするシンクに置き換えてください。
Lindorm コネクタ使用時の予期しないデータの上書きまたは削除の修正
デフォルトでは、Lindorm コネクタは upsert materialize オペレーター (デフォルト: AUTO) を使用して書き込み順序を管理します。このオペレーターは、同じプライマリキーに対して DELETE の後に INSERT を生成します。Lindorm の 2 つの特性により、これが問題となります:
-
ミリ秒精度のタイムスタンプ: Lindorm はミリ秒単位のタイムスタンプを使用してデータをバージョニングします。単一のミリ秒内に書き込まれた同じプライマリキーを持つ複数のレコードが順序通りに到着しない可能性があり、バージョンの競合を引き起こします。
-
ネイティブな DELETE サポートの欠如: Lindorm は UPSERT セマンティクスのみをサポートしており、削除は元に戻せません。そのため、
upsert materializeの順序維持ロジックは効果がなく、DELETE + INSERT シーケンスからデータの異常を引き起こす可能性があります。
同時書き込みが同じミリ秒内に発生すると、DELETE および INSERT 操作によって不正確なデータやサイレントなデータ損失が引き起こされる可能性があります。
解決策: ジョブの実行時パラメーター設定または SQL コードに以下を追加して、upsert materialize オペレーターを明示的に無効にしてください:
SET 'table.exec.sink.upsert-materialize' = 'NONE';この設定は、Flink を介して Lindorm に書き込むすべてのジョブに適用されます。
このオペレーターを無効にすると、結果整合性のみが保証されます。この変更を適用する前に、ユースケースで結果整合性が許容できることを確認してください。