このトピックでは、Elastic Compute Service (ECS) インスタンスに Logstash をデプロイし、移行パイプラインを設定することで、セルフマネージド Elasticsearch クラスターから Alibaba Cloud Elasticsearch に完全データまたは増分データを移行する方法について説明します。
注意事項
-
Logstash をホストする ECS インスタンスは、Alibaba Cloud Elasticsearch クラスターと同じ VPC 内に存在し、ソースクラスターと移行先クラスターの両方にネットワークアクセスできる必要があります。
-
アプリケーションが継続的にデータを書き込みまたは更新する場合、まず完全移行を実行し、次にタイムスタンプまたは別の識別フィールドに基づいて増分移行を実行してください。そうしないと、古いデータが移行先クラスターの新しいデータを上書きする可能性があります。移行先に既存のデータがすべて存在する場合は、増分移行のみが必要です。
操作手順
-
Alibaba Cloud Elasticsearch クラスターを作成し、セルフマネージドの Elasticsearch と Logstash を ECS インスタンスにデプロイし、移行データを準備します。
-
ステップ2 (任意):インデックスメタデータ (設定とマッピング) の移行
ECS インスタンスで Python スクリプトを実行して、インデックスメタデータを移行します。
-
Logstash を使用して、セルフマネージドクラスターから Alibaba Cloud Elasticsearch にすべてのデータを移行します。
ステップ1:環境とインスタンスの準備
-
Alibaba Cloud Elasticsearch インスタンスを作成します。
Alibaba Cloud Elasticsearch インスタンスの作成。テスト環境では、次の構成を使用します。
パラメーター
説明
リージョン
中国 (杭州)。
エディション
Standard Edition 7.10.0。
インスタンス仕様
3つのゾーン、3つのデータノード。各ノードは 4 vCPU、16 GB のメモリ、100 GB の高性能 SSD (ESSD) を搭載しています。
-
セルフマネージド Elasticsearch、Kibana、Logstash インスタンス用の ECS インスタンスを作成します。
ウィザードを使用したインスタンスの作成。テスト環境では、次の構成を使用します。
パラメーター
説明
リージョン
中国 (杭州)。
インスタンスタイプ
4 vCPU、16 GiB のメモリ。
イメージ
パブリックイメージ、CentOS 7.9 64 ビット。
ストレージ
システムディスク、100 GiB 高性能 SSD (ESSD)。
ネットワーク
Alibaba Cloud Elasticsearch クラスターと同じ VPC (Virtual Private Cloud) を選択します。パブリック IPv4 の割り当て を選択し、課金方法をトラフィック課金に設定し、ピーク帯域幅を 100 Mbit/s に設定します。
セキュリティグループ
インバウンドルールを追加して、ポート 5601 (Kibana のデフォルトポート) へのアクセスを許可します。権限付与オブジェクトをクライアントの IP アドレスに設定します。
重要-
クライアントが自宅または会社のネットワーク上にある場合、お使いのコンピューターのプライベート IP アドレスではなく、ネットワークのパブリック出口 IP アドレスを使用してください。パブリック IP アドレスは https://www.whatismyip.com で確認できます。
-
権限付与オブジェクトとして 0.0.0.0/0 を設定すると、すべての IPv4 アドレスが許可されますが、ECS インスタンスがパブリックインターネットに公開されます。本番環境ではこの設定を避けてください。
-
-
セルフマネージド Elasticsearch クラスターをデプロイします。
このトピックでは、1つのデータノードを持つセルフマネージド Elasticsearch 7.6.2 クラスターを使用します。
-
ECS インスタンスに接続します。
-
root ユーザーとして、`elastic` という名前の新しいユーザーを作成します。
useradd elastic -
`elastic` ユーザーのパスワードを設定します。
passwd elasticプロンプトに従って、新しいパスワードを入力し、確認します。
-
`elastic` ユーザーに切り替えます。
su -l elastic -
Elasticsearch インストールパッケージをダウンロードして展開します。
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.6.2-linux-x86_64.tar.gz tar -zvxf elasticsearch-7.6.2-linux-x86_64.tar.gz -
Elasticsearch を起動します。
Elasticsearch のインストールディレクトリに移動し、サービスをバックグラウンドで起動します。
cd elasticsearch-7.6.2 ./bin/elasticsearch -d -
Elasticsearch サービスが実行中であることを確認します。
cd ~ curl localhost:9200成功すると、Elasticsearch のバージョン番号とタグライン
"You Know, for Search"を含む応答が返されます。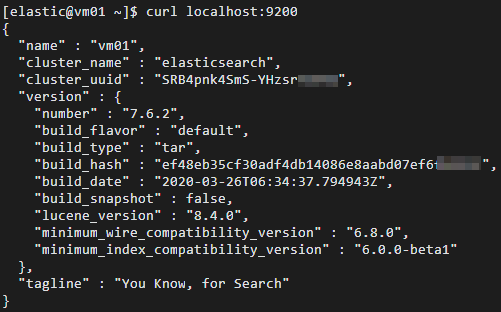
-
-
セルフマネージド Kibana インスタンスをデプロイし、サンプルデータを準備します。
このトピックでは、セルフマネージド Kibana 7.6.2 インスタンスを使用します。
-
ECS インスタンスに接続します。
Workbench を使用して Linux インスタンスに接続。
説明このトピックの手順は、特に指定がない限り、非 root ユーザーとしてコマンドを実行していることを前提としています。
-
Kibana インストールパッケージをダウンロードして展開します。
wget https://artifacts.elastic.co/downloads/kibana/kibana-7.6.2-linux-x86_64.tar.gz tar -zvxf kibana-7.6.2-linux-x86_64.tar.gz -
Kibana 設定ファイル config/kibana.yml を編集し、
server.host: "0.0.0.0"を追加してリモートアクセスを有効にします。Kibana のインストールディレクトリに移動し、kibana.yml を編集します。
cd kibana-7.6.2-linux-x86_64 vi config/kibana.yml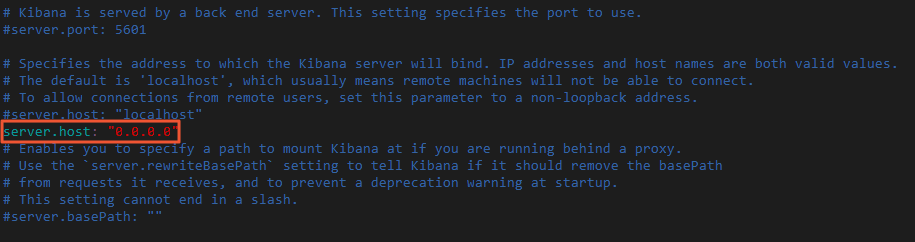
-
非 root ユーザーとして Kibana を起動します。
sudo nohup ./bin/kibana & -
Kibana コンソールにログインし、サンプルデータを追加します。
-
ECS インスタンスのパブリック IP アドレスを使用して Kibana コンソールにアクセスします。
URL の形式は次のとおりです:http://<your_ecs_instance_public_ip>:5601/app/kibana#/home
-
Kibana のホームページで、[サンプルデータをお試しください] をクリックします。
-
[サンプルデータ] ページで、サンプル Web ログカードを見つけ、[データを追加] をクリックします。
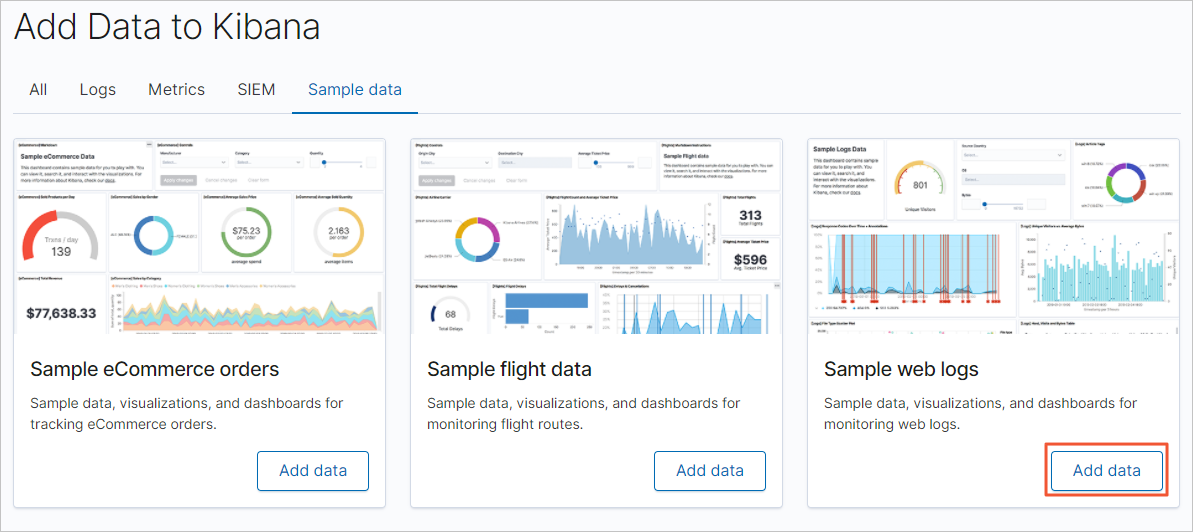
-
-
-
セルフマネージド Logstash インスタンスをデプロイします。
このトピックでは、1つのノードを持つセルフマネージド Logstash 7.10.0 インスタンスを使用します。
-
ECS インスタンスに接続します。
Workbench を使用して Linux インスタンスに接続。
説明このトピックの手順は、非 root ユーザーとしてコマンドを実行していることを前提としています。
-
ホームディレクトリに戻り、Logstash インストールパッケージをダウンロードして展開します。
cd ~ wget https://artifacts.elastic.co/downloads/logstash/logstash-7.10.0-linux-x86_64.tar.gz tar -zvxf logstash-7.10.0-linux-x86_64.tar.gz -
Logstash のヒープサイズを調整します。
デフォルトのヒープサイズは 1 GB です。移行性能を向上させるために、ECS インスタンスの仕様に基づいて調整します。
Logstash のインストールディレクトリに移動し、`config/jvm.options` を編集して、初期ヒープサイズと最大ヒープサイズの両方を 8 GB (
-Xms8gと-Xmx8g) に設定します。cd logstash-7.10.0 sudo vi config/jvm.options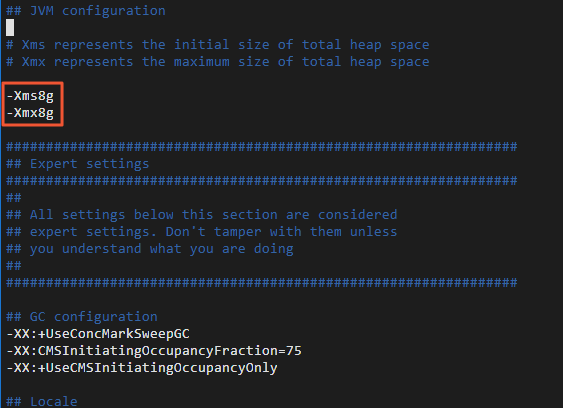
-
Logstash のバッチサイズを変更します。
5 MB から 15 MB のバッチでデータを書き込むと、データ移行が高速化されます。
config/pipelines.yml を編集し、
pipeline.batch.sizeを 125 から 5000 に変更します。vi config/pipelines.yml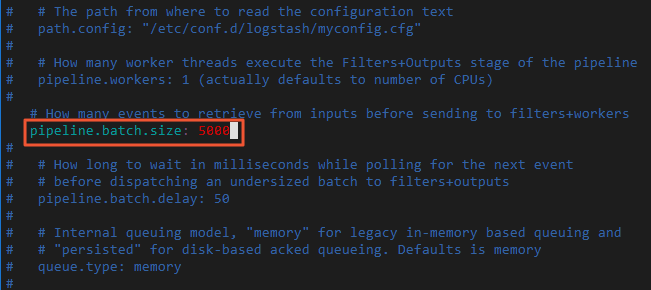
-
Logstash が正しく機能していることを確認します。
-
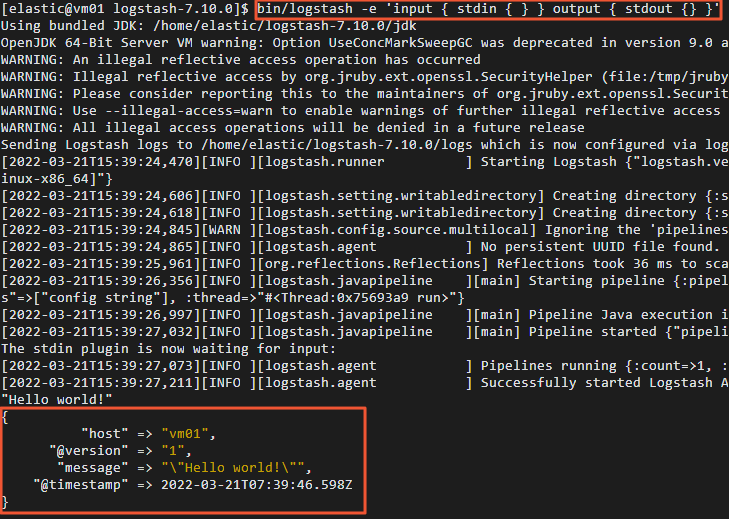
標準入力を受け取り、標準出力に送信する簡単なパイプラインを実行します。
bin/logstash -e 'input { stdin { } } output { stdout {} }' -
パイプラインが開始したら、"Hello world!" と入力して Enter キーを押します。
Logstash が正常に動作している場合、"Hello world!" を含む構造化されたログメッセージがコンソールに出力されます。
-
-
ステップ2 (任意):インデックスメタデータの移行
Logstash は、移行先クラスターにインデックスが存在しない場合、自動的にインデックスを作成しますが、自動作成された設定とマッピングはソースと異なる場合があります。一貫したインデックス構造を確保するために、移行前に手動で移行先インデックスを作成します。
次の Python スクリプトを使用して、移行先インデックスを作成します。
-
ECS インスタンスに接続します。
Workbench を使用して Linux インスタンスに接続。
説明このトピックの手順は、非 root ユーザーとしてコマンドを実行していることを前提としています。
-
Python スクリプトファイルを作成して開きます。このトピックでは、ファイル名として
indiceCreate.pyを使用します。sudo vi indiceCreate.py -
次のコードを Python スクリプトファイルにコピーし、クラスターエンドポイント、ユーザー名、パスワードのプレースホルダー値を実際の認証情報に置き換えます。
#!/usr/bin/python # -*- coding: UTF-8 -*- # Filename: indiceCreate.py import sys import base64 import time import httplib import json ## ソースクラスターのホスト。 oldClusterHost = "localhost:9200" ## ソースクラスターのユーザー名。空にすることができます。 oldClusterUserName = "elastic" ## ソースクラスターのパスワード。空にすることができます。 oldClusterPassword = "xxxxxx" ## 移行先クラスターのホスト。これは Alibaba Cloud Elasticsearch インスタンスの基本情報ページで確認できます。 newClusterHost = "es-cn-zvp2m4bko0009****.elasticsearch.aliyuncs.com:9200" ## 移行先クラスターのユーザー名。 newClusterUser = "elastic" ## 移行先クラスターのパスワード。 newClusterPassword = "xxxxxx" DEFAULT_REPLICAS = 0 def httpRequest(method, host, endpoint, params="", username="", password=""): conn = httplib.HTTPConnection(host) headers = {} if (username != "") : 'Hello {name}, your age is {age} !'.format(name = 'Tom', age = '20') base64string = base64.encodestring('{username}:{password}'.format(username = username, password = password)).replace('\n', '') headers["Authorization"] = "Basic %s" % base64string; if "GET" == method: headers["Content-Type"] = "application/x-www-form-urlencoded" conn.request(method=method, url=endpoint, headers=headers) else : headers["Content-Type"] = "application/json" conn.request(method=method, url=endpoint, body=params, headers=headers) response = conn.getresponse() res = response.read() return res def httpGet(host, endpoint, username="", password=""): return httpRequest("GET", host, endpoint, "", username, password) def httpPost(host, endpoint, params, username="", password=""): return httpRequest("POST", host, endpoint, params, username, password) def httpPut(host, endpoint, params, username="", password=""): return httpRequest("PUT", host, endpoint, params, username, password) def getIndices(host, username="", password=""): endpoint = "/_cat/indices" indicesResult = httpGet(oldClusterHost, endpoint, oldClusterUserName, oldClusterPassword) indicesList = indicesResult.split("\n") indexList = [] for indices in indicesList: if (indices.find("open") > 0): indexList.append(indices.split()[2]) return indexList def getSettings(index, host, username="", password=""): endpoint = "/" + index + "/_settings" indexSettings = httpGet(host, endpoint, username, password) print (index + " 元の設定:\n" + indexSettings) settingsDict = json.loads(indexSettings) ## シャード数はデフォルトでソースインデックスと一致します。 number_of_shards = settingsDict[index]["settings"]["index"]["number_of_shards"] ## デフォルトのレプリカ数は 0 です。 number_of_replicas = DEFAULT_REPLICAS newSetting = "\"settings\": {\"number_of_shards\": %s, \"number_of_replicas\": %s}" % (number_of_shards, number_of_replicas) return newSetting def getMapping(index, host, username="", password=""): endpoint = "/" + index + "/_mapping" indexMapping = httpGet(host, endpoint, username, password) print (index + " 元のマッピング:\n" + indexMapping) mappingDict = json.loads(indexMapping) mappings = json.dumps(mappingDict[index]["mappings"]) newMapping = "\"mappings\" : " + mappings return newMapping def createIndexStatement(oldIndexName): settingStr = getSettings(oldIndexName, oldClusterHost, oldClusterUserName, oldClusterPassword) mappingStr = getMapping(oldIndexName, oldClusterHost, oldClusterUserName, oldClusterPassword) createstatement = "{\n" + str(settingStr) + ",\n" + str(mappingStr) + "\n}" return createstatement def createIndex(oldIndexName, newIndexName=""): if (newIndexName == "") : newIndexName = oldIndexName createstatement = createIndexStatement(oldIndexName) print ("新しいインデックス " + newIndexName + " の設定とマッピング:\n" + createstatement) endpoint = "/" + newIndexName createResult = httpPut(newClusterHost, endpoint, createstatement, newClusterUser, newClusterPassword) print ("新しいインデックス " + newIndexName + " の作成結果: " + createResult) ## main indexList = getIndices(oldClusterHost, oldClusterUserName, oldClusterPassword) systemIndex = [] for index in indexList: if (index.startswith(".")): systemIndex.append(index) else : createIndex(index, index) if (len(systemIndex) > 0) : for index in systemIndex: print (index + " はシステムインデックスの可能性があるため、再作成されません。必要な場合は、別途処理してください。") -
Python スクリプトを実行して、移行先インデックスを作成します。
sudo /usr/bin/python indiceCreate.py -
移行先クラスターの Kibana コンソールにログインし、インデックスが作成されたことを確認します。
GET /_cat/indices?v
ステップ3:完全なデータ移行
-
ECS インスタンスに接続します。
-
config ディレクトリで、Logstash 設定ファイルを作成して開きます。
cd logstash-7.10.0/config vi es2es_all.conf -
ファイルに次の構成を追加します。
説明-
Logstash 設定パラメーターはバージョン 8.5 で変更されました。このトピックでは、バージョン 7.10.0 とバージョン 8.5.1 の両方の構成例を示します。
-
データの精度を確保するために、個別の Logstash パイプライン設定ファイルを作成し、データをバッチで移行してください。
バージョン 7.10.0
input{ elasticsearch{ # ソース Elasticsearch クラスターのエンドポイント。 hosts => ["http://localhost:9200"] # ソースクラスターのユーザー名とパスワード。 user => "xxxxxx" password => "xxxxxx" # 移行するインデックスのリスト。複数のインデックスはカンマ (,) で区切ります。 index => "kibana_sample_data_*" # 以下の 3 つの項目はデフォルトのままにすることができます。これらはスレッド数、移行データサイズ、Logstash JVM 構成に関連します。 docinfo=>true slices => 5 size => 5000 } } filter { # Logstash によって追加されたメタデータフィールドを削除します。 mutate { remove_field => ["@timestamp", "@version"] } } output{ elasticsearch{ # 移行先クラスターのエンドポイント。これは Alibaba Cloud Elasticsearch インスタンスの基本情報ページで確認できます。 hosts => ["http://es-cn-zvp2m4bko0009****.elasticsearch.aliyuncs.com:9200"] # 移行先クラスターのユーザー名とパスワード。 user => "elastic" password => "xxxxxx" # 移行先インデックスの名前。この構成では、インデックス名はソースと同じになります。 index => "%{[@metadata][_index]}" # 移行先インデックスのタイプ。この構成では、インデックスタイプはソースと同じになります。 document_type => "%{[@metadata][_type]}" # 移行先クラスターのデータの ID。元のドキュメント ID を保持する必要がない場合は、この行を削除してパフォーマンスを向上させることができます。 document_id => "%{[@metadata][_id]}" ilm_enabled => false manage_template => false } }バージョン 8.5.1
input{ elasticsearch{ # ソース Elasticsearch クラスターのエンドポイント。 hosts => ["http://es-cn-uqm3811160002***.elasticsearch.aliyuncs.com:9200"] # ソースクラスターのユーザー名とパスワード。 user => "elastic" password => "" # 移行するインデックスのリスト。複数のインデックスはカンマ (,) で区切ります。 index => "test_ecommerce" # 以下の項目はデフォルトのままにすることができます。これらはスレッド数、移行データサイズ、Logstash JVM 構成に関連します。 docinfo => true size => 10000 docinfo_target => "[@metadata]" } } filter { # Logstash によって追加されたメタデータフィールドを削除します。 mutate { remove_field => ["@timestamp","@version"] } } output{ elasticsearch{ # 移行先クラスターのエンドポイント。これは Alibaba Cloud Elasticsearch インスタンスの基本情報ページで確認できます。 hosts => ["http://es-cn-nwy38aixp0001****.elasticsearch.aliyuncs.com:9200"] # 移行先クラスターのユーザー名とパスワード。 user => "elastic" password => "" # 移行先インデックスの名前。この構成では、インデックス名はソースと同じになります。 index => "%{[@metadata][_index]}" # 移行先クラスターのデータの ID。元のドキュメント ID を保持する必要がない場合は、この行を削除してパフォーマンスを向上させることができます。 document_id => "%{[@metadata][_id]}" ilm_enabled => false manage_template => false } }Elasticsearch 入力プラグインは、すべてのデータを読み取った後に停止します。一部の環境では、Logstash が自動的に再起動し、重複書き込みが発生する可能性があります。これを防ぐには、
scheduleパラメーターと cron 式を使用して、特定の時間にタスクを実行します (スケジューリング)。たとえば、3月5日午後1時20分にタスクを実行する場合:
schedule => "20 13 5 3 *" -
-
Logstash ディレクトリに移動します。
cd ~/logstash-7.10.0 -
完全なデータ移行タスクを開始します。
nohup bin/logstash -f config/es2es_all.conf >/dev/null 2>&1 &
ステップ4:増分データ移行
-
ECS インスタンスに接続します。config ディレクトリで、増分移行用の新しい Logstash 設定ファイルを作成して開きます。
cd config vi es2es_kibana_sample_data_logs.conf説明このトピックの手順は、非 root ユーザーとしてコマンドを実行していることを前提としています。
-
ファイルに次の構成を追加します。
以下は、バージョン 7.10.0 のサンプル構成です。
説明-
Logstash 8.5 以降では、ドキュメントタイプが非推奨になったため、
document_type => "%{[@metadata][_type]}"行を削除する必要があります。 -
ファイルを設定した後、スケジュールされた Logstash タスクを開始すると、増分移行がトリガーされます。
input{ elasticsearch{ # ソース Elasticsearch クラスターのエンドポイント。 hosts => ["http://localhost:9200"] # ソースクラスターのユーザー名とパスワード。 user => "xxxxxx" password => "xxxxxx" # 移行するインデックスのリスト。複数のインデックスはカンマ (,) で区切ります。 index => "kibana_sample_data_logs" # 時間範囲内の増分データをクエリします。以下の設定では、過去 5 分間のデータをクエリします。 query => '{"query":{"range":{"@timestamp":{"gte":"now-5m","lte":"now/m"}}}}' # スケジュールされたタスク。以下の設定では、タスクを毎分実行します。 schedule => "* * * * *" scroll => "5m" docinfo=>true size => 5000 } } filter { # Logstash によって追加されたメタデータフィールドを削除します。 mutate { remove_field => ["@timestamp", "@version"] } } output{ elasticsearch{ # 移行先クラスターのエンドポイント。これは Alibaba Cloud Elasticsearch インスタンスの基本情報ページで確認できます。 hosts => ["http://es-cn-zvp2m4bko0009****.elasticsearch.aliyuncs.com:9200"] # 移行先クラスターのユーザー名とパスワード。 user => "elastic" password => "xxxxxx" # 移行先インデックスの名前。この構成では、インデックス名はソースと同じになります。 index => "%{[@metadata][_index]}" # 移行先インデックスのタイプ。この構成では、インデックスタイプはソースと同じになります。 document_type => "%{[@metadata][_type]}" # 移行先クラスターのデータの ID。元のドキュメント ID を保持する必要がない場合は、この行を削除してパフォーマンスを向上させることができます。 document_id => "%{[@metadata][_id]}" ilm_enabled => false manage_template => false } }重要-
Logstash は協定世界時 (UTC) タイムスタンプを使用します。ソースデータが異なるタイムゾーンを使用している場合は、それに応じてクエリ範囲を調整してください。
@timestampフィールドのnow-5mは、サーバーの UTC 時計に基づいています。 -
増分同期を行うには、ソースインデックスに時間フィールドが含まれている必要があります。含まれていない場合は、ingest パイプラインで
_ingest.timestampメタデータフィールドを使用して、インデックス作成時にドキュメントに@timestampを追加します。
-
-
Logstash ディレクトリに移動します。
cd ~/logstash-7.10.0 -
増分データ移行タスクを開始します。
sudo nohup bin/logstash -f config/es2es_kibana_sample_data_logs.conf >/dev/null 2>&1 & -
移行先 Elasticsearch クラスターの Kibana コンソールで、最新のレコードをクエリして、増分データが同期されていることを確認します。
次のクエリは、
kibana_sample_data_logsインデックスから過去 5 分間のレコードを検索します。GET kibana_sample_data_logs/_search { "query": { "range": { "@timestamp": { "gte": "now-5m", "lte": "now/m" } } }, "sort": [ { "@timestamp": { "order": "desc" } } ] }
ステップ5:移行結果の検証
-
完全なデータ移行を検証します。
-
セルフマネージドのソースクラスターでインデックスとドキュメント数の情報を確認します。
GET _cat/indices?v次の結果は一例です。

-
移行前に Alibaba Cloud の移行先クラスターでインデックスとドキュメント数を確認します。
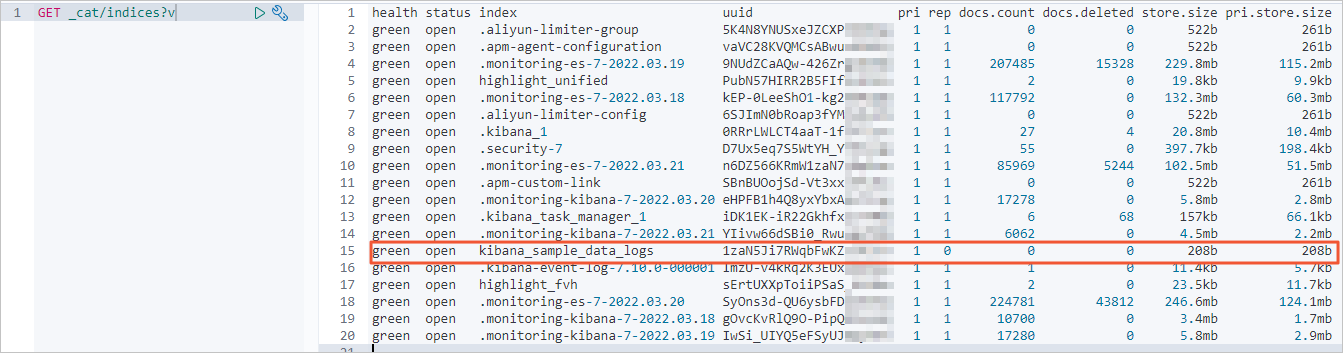
-
完全なデータ移行後、Alibaba Cloud の移行先クラスターでインデックスとドキュメント数の情報を再度確認します。
ドキュメント数がソースクラスターの数と一致するはずです。
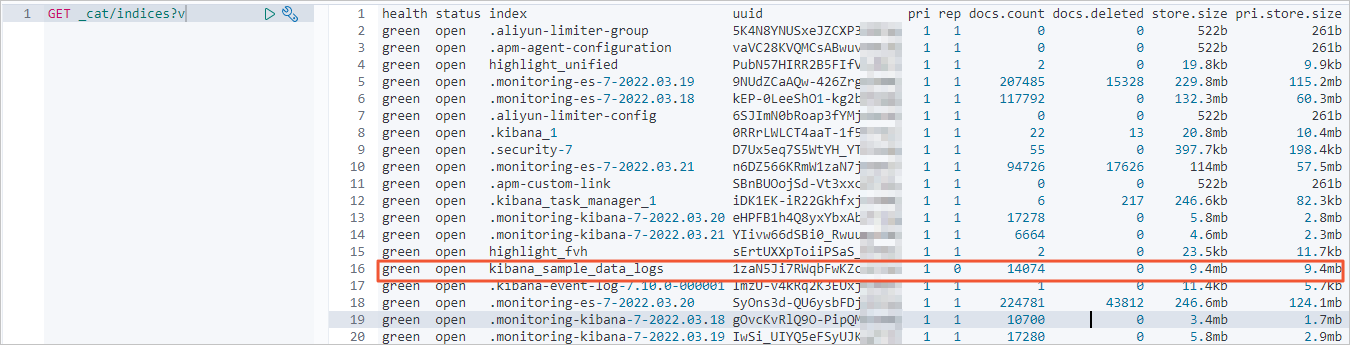
-
-
増分データ移行を検証します。
セルフマネージドのソースクラスターで最新のレコードを確認します。
GET kibana_sample_data_logs/_search { "query": { "range": { "@timestamp": { "gte": "now-5m", "lte": "now/m" } } }, "sort": [ { "@timestamp": { "order": "desc" } } ] }次の結果は一例です。
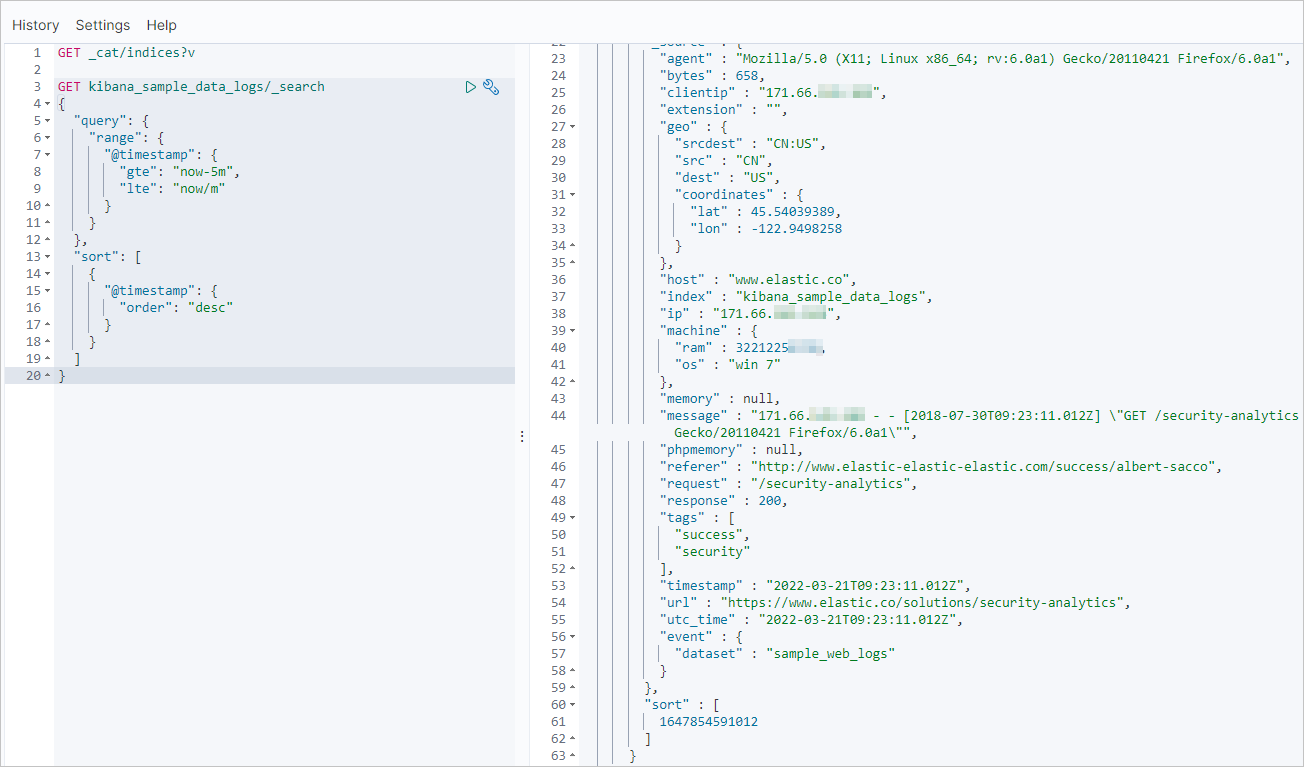
移行先クラスターの Kibana コンソールで同じクエリを実行します。結果が一致すれば、増分同期が成功したことになります。