Elasticsearch マシンラーニングは、マシンラーニング技術に基づいて Elasticsearch のデータに対してインテリジェントな検出と予測を実行するために使用できるツールです。このツールは、データに発生するデータパターンと異常を自動的に識別し、新しい特徴量と集計結果を生成することで、データ分析とデータ活用をサポートできます。 Elasticsearch マシンラーニングは、データの可用性と価値を向上させ、よりインテリジェントで効率的なデータ分析と活用ソリューションを提供します。このトピックでは、教師なしマシンラーニングと教師ありマシンラーニングを実行する方法について説明します。
背景情報
Elasticsearch マシンラーニングは、教師なしマシンラーニングと教師ありマシンラーニングの 2 つの学習モードをサポートしています。
教師なしマシンラーニングは、単一メトリックベースの検出や母集団などのシナリオでデータに発生する異常を検出するために使用できます。教師なしマシンラーニングモードでは、異常とは何かを学習するためにタスクをトレーニングする必要はありません。マシンラーニングアルゴリズムは、データに発生する異常パターンや異常を自動的に検出できます。
教師ありマシンラーニングは、回帰や分類などのシナリオに適しており、回帰アルゴリズムと分類アルゴリズムに基づいて複雑な問題を解決できます。教師ありマシンラーニングでは、特定のデータを使用して予測タスクをトレーニングする必要があります。その後、そのタスクを使用して新しいデータを分類し、データに対して予測を実行できます。
シナリオカテゴリ | シナリオ | マシンラーニングのモード | 説明 |
異常検出 | 単一メトリックベースの検出 | 教師なし | このシナリオでは、単一の時系列でのみ異常が検出され、1 つのインデックスフィールドに対してのみデータ分析が実行されます。 |
複数メトリックベースの検出 | 教師なし | このシナリオでは、1 つ以上のメトリックに基づいて異常が検出され、ビジネス要件に基づいて分析のためにメトリックが分割される場合があります。データ分析は複数のインデックスフィールドに対して実行されます。 | |
母集団 | 教師なし | 実際の行動と母集団の行動を比較して、異常な行動を検出します。 母集団とは、特定の分野で研究される可能性のある個人、物、または現象の集合です。 | |
マシンラーニングタスクの高度な使用 | 教師なし | より多くのオプションと設定が提供されるため、マシンラーニングタスクをさまざまなシナリオやデータ型に合わせて調整し、高度なシナリオ向けにタスクを最適化できます。 | |
分類 | 教師なし | このシナリオでは、教師なしマシンラーニングを使用して、ログメッセージの特徴とパターンを識別および分析し、ログメッセージを分類し、ログメッセージの異常を検出できます。 | |
データフレーム分析 | 外れ値検出 | 教師なし | クラスタリングアルゴリズムと異常検出アルゴリズムを使用してタスクをトレーニングします。これらのタスクを使用して、データに発生する異常な行動や異常を迅速に識別できます。 |
回帰 | 教師あり | データセットのデータ値に対して回帰予測が実行されます。 | |
分類 | 教師あり | データセットのデータポイントに対して分類予測を実行して、データポイントのカテゴリを決定します。 |
準備
Alibaba Cloud Elasticsearch クラスタを作成します。この例では、Elasticsearch V8.5 クラスタが作成されます。詳細については、「Alibaba Cloud Elasticsearch クラスタの作成」をご参照ください。
説明Elasticsearch クラスタでのマシンラーニング技術の使用方法 はバージョンによって異なる場合があります。詳細については、「Elastic マシンラーニングとは」をご参照ください。
Elasticsearch クラスタの Kibana コンソールにログインします。詳細については、「Kibana コンソールへのログイン」をご参照ください。
サンプルデータを追加します。
Kibana コンソールのホームページで、[統合を追加して開始] セクションの [サンプルデータを試す] をクリックします。
表示されるページの [サンプルデータ] タブで、[その他のサンプルデータセット] をクリックします。
[サンプルフライトデータ] カードと [サンプル Web ログ] カードで、それぞれ [データの追加] をクリックします。
[データの追加] が [データの表示] に変わると、データセットが追加されます。データセットが追加されると、Kibana は kibana_sample_data_flights インデックスと kibana_sample_data_logs インデックスを自動的に作成します。
マシンラーニングタスクの作成
このセクションでは、教師なしマシンラーニングと教師ありマシンラーニングの実践について説明します。
単一メトリックに基づいてマシンラーニングタスクを作成する
この例では、Kibana によって提供されるサンプル Web ログデータセットのサンプルデータを分析するために、単一メトリックに基づいて教師なしマシンラーニングタスクが作成されます。このデータセットは、Web サーバーへのアクセスをシミュレートしたデータを提供します。このタスクを使用して、ユーザーのアクセス行動を分析し、Web サイトのパフォーマンスを最適化し、異常なアクセス行動を検出できます。
次のコードは、サンプル Web ログデータセットのデータレコードを示しています。
{
"_index": "kibana_sample_data_logs",
"_type": "_doc",
"_id": "n6GHI4gBmNQSVxOwNnPn",
"_version": 1,
"_score": null,
"_source": {
"agent": "Mozilla/5.0 (X11; Linux i686) AppleWebKit/534.24 (KHTML, like Gecko) Chrome/11.0.696.50 Safari/534.24",
"bytes": 847,
"clientip": "122.62.233.59",
"extension": "",
"geo": {
"srcdest": "CN:CO",
"src": "CN",
"dest": "CO",
"coordinates": {
"lat": 31.24905556,
"lon": -82.39530556
}
},
"host": "www.elastic.co",
"index": "kibana_sample_data_logs",
"ip": "122.62.233.59",
"machine": {
"ram": 4294967296,
"os": "win xp"
},
"memory": null,
"message": "122.62.233.59 - - [2018-08-21T02:34:54.901Z] \"GET /logging HTTP/1.1\" 200 847 \"-\" \"Mozilla/5.0 (X11; Linux i686) AppleWebKit/534.24 (KHTML, like Gecko) Chrome/11.0.696.50 Safari/534.24\"",
"phpmemory": null,
"referer": "http://twitter.com/success/paul-w-richards",
"request": "/logging",
"response": 200,
"tags": [
"success",
"info"
],
"timestamp": "2023-06-06T02:34:54.901Z",
"url": "https://www.elastic.co/solutions/logging",
"utc_time": "2023-06-06T02:34:54.901Z",
"event": {
"dataset": "sample_web_logs"
}
},
"fields": {
"@timestamp": [
"2023-06-06T02:34:54.901Z"
],
"utc_time": [
"2023-06-06T02:34:54.901Z"
],
"hour_of_day": [
2
],
"timestamp": [
"2023-06-06T02:34:54.901Z"
]
},
"sort": [
1686018894901
]
}Transform を使用して、入力データを統計またはより高いレベルのメトリックに集約し、集約結果を新しいインデックスに保存できます。これは、クエリパフォーマンスの向上、応答時間の短縮、後続の分析とマシンラーニングのための基礎データの提供に役立ちます。
Kibana コンソールの左上隅にある
 アイコンをクリックします。左側のナビゲーションペインで、[分析] > [マシンラーニング] を選択します。
アイコンをクリックします。左側のナビゲーションペインで、[分析] > [マシンラーニング] を選択します。表示されるページの左側のナビゲーションペインで、 を選択します。
[異常検出ジョブ] ページで、[ジョブの作成] をクリックします。
[kibana_sample_data_logs] インデックスを選択します。
[データビュー Kibana サンプルデータログからジョブを作成] ページの [ウィザードを使用] セクションで、[単一メトリック] をクリックして単一メトリックジョブを作成します。
単一メトリックジョブを構成します。
[時間範囲] ステップで、[全データを使用] をクリックし、[次へ] をクリックします。
説明サンプルデータセットは少量のデータのみを提供します。この例では、kibana_sample_data_logs インデックスのすべてのデータが使用されます。
[フィールドの選択] ステップで、ドロップダウンリストから [カウント (イベントレート)] を選択し、[バケットスパン] パラメータと [スパースデータ] パラメータを構成して、[次へ] をクリックします。
説明カウント (イベントレート) は、単一メトリックビューのメトリックです。このメトリックの値は、サーバーが 1 秒ごとにリクエストに応答する回数を反映しています。このメトリックは、異常検出の目的として使用できます。
バケットスパン: 時系列分析の間隔を定義します。このパラメータは、時系列データを後続の分析と予測のために異なる部分に分割するために使用されます。ビジネス要件に基づいてこのパラメータを構成できます。
スパースデータ: 値のないデータを例外と見なすかどうかを指定します。マシンラーニングでは、スパースデータとは、値のないデータ、または値が欠落しているデータのことです。
[ジョブの詳細] ステップで、[ジョブ ID] フィールドに ID を入力し、[ジョブの説明] フィールドに説明を入力します。次に、[次へ] をクリックします。
[検証] ステップで、時間範囲とタスクメモリ制限の検証に合格した場合は、[次へ] をクリックします。
[概要] ステップで、ページの下部にある [ジョブの作成] をクリックします。
Elasticsearch は時系列に基づいてデータを表示し、データを分析および調査し、データに基づいてタスクを作成し、後続のデータを評価します。
説明ジョブを作成するときは、検証を実行するために特定の時間がかかります。実際に消費される時間は、関連インデックスのデータサイズによって異なります。
ジョブの作成後、ページの左下隅にある [結果を表示] をクリックして結果を表示します。
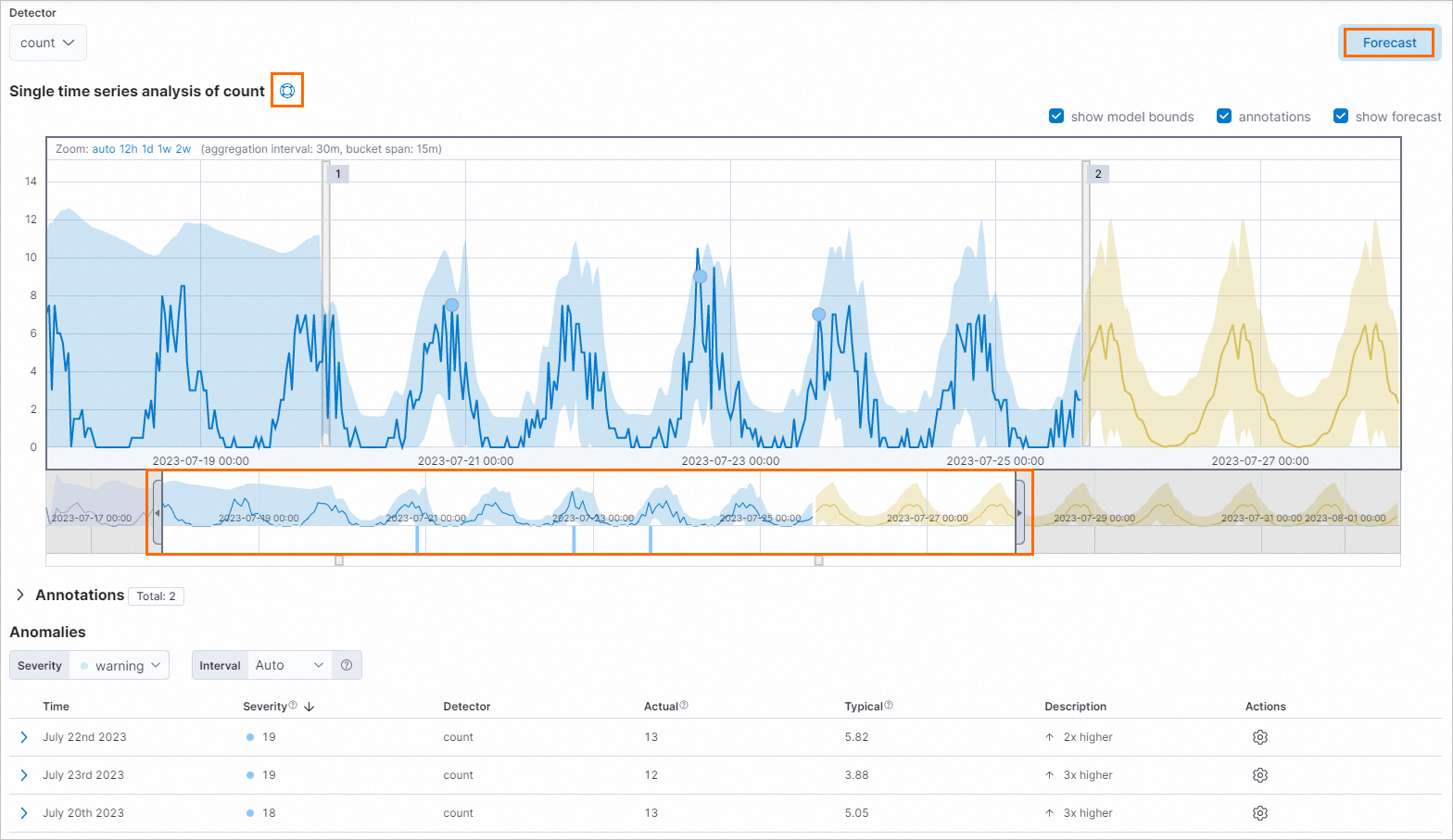
[単一メトリックビューア] ページで、
 [カウントの単一時系列分析] の横にある . アイコンをクリックして、単一時系列分析の説明を表示します。
[カウントの単一時系列分析] の横にある . アイコンをクリックして、単一時系列分析の説明を表示します。タイムラインの左端または右端をドラッグするか、タイムラインを移動して、異常検出を実行する時間範囲を選択します。
[単一メトリックビューア] ページで [予測] をクリックして、後続のデータの予測を実行します。
推論マシンラーニングタスクを作成する
フライト遅延予測タスクのトレーニング
この例では、Kibana によって提供されるサンプルデータセットの特定の履歴データに基づいて、回帰アルゴリズムを使用して、フライト遅延予測の教師あり機械学習タスクをトレーニングします。 サンプルデータセットは Sample flight data という名前で、シミュレートされたフライトデータを提供します。 このタスクは、航空会社と乗客に重要な参考情報を提供し、乗客が旅程とフライトのスケジュールをより適切に計画するのに役立ちます。
次のコードは、サンプルフライトデータデータセットのデータレコードを示しています。
{
"_index": "kibana_sample_data_flights",
"_type": "_doc",
"_id": "7b0aeogBmNQSVxOwslB_",
"_version": 1,
"_score": null,
"_source": {
"FlightNum": "QYX9S3I",
"DestCountry": "CH",
"OriginWeather": "Cloudy",
"OriginCityName": "Chicago",
"AvgTicketPrice": 824.8516378170061,
"DistanceMiles": 4442.909325899777,
"FlightDelay": false,
"DestWeather": "Thunder & Lightning",
"Dest": "Zurich Airport",
"FlightDelayType": "No Delay",
"OriginCountry": "US",
"dayOfWeek": 4,
"DistanceKilometers": 7150.1694661808515,
"timestamp": "2023-06-02T07:28:15",
"DestLocation": {
"lat": "47.464699",
"lon": "8.54917"
},
"DestAirportID": "ZRH",
"Carrier": "Logstash Airways",
"Cancelled": false,
"FlightTimeMin": 420.59820389299125,
"Origin": "Chicago O'Hare International Airport",
"OriginLocation": {
"lat": "41.97859955",
"lon": "-87.90480042"
},
"DestRegion": "CH-ZH",
"OriginAirportID": "ORD",
"OriginRegion": "US-IL",
"DestCityName": "Zurich",
"FlightTimeHour": 7.009970064883188,
"FlightDelayMin": 0
}
}Kibana コンソールの左上隅にある
 アイコンをクリックします。左側のナビゲーションペインで、[分析] > [機械学習] を選択します。
アイコンをクリックします。左側のナビゲーションペインで、[分析] > [機械学習] を選択します。表示されるページの左側のナビゲーションペインで、 を選択します。
[データフレーム分析ジョブ] ページで、[ジョブの作成] をクリックします。
[新しい分析ジョブ] / [ソースデータビューの選択] ページで、kibana_sample_data_logs インデックスを選択します。
[ジョブの作成] ページの [構成] ステップで、ジョブの基本情報を構成します。
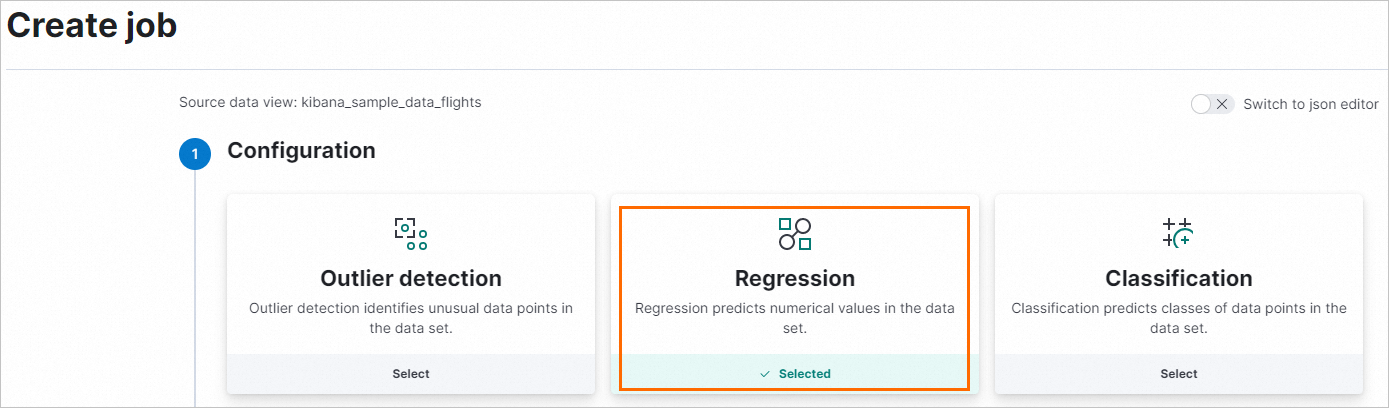
[回帰] を選択します。
[従属変数] ドロップダウンリストから FlightDelayMin を選択します。従属変数は、予測を実行する必要がある変数です。
[含まれるフィールド] セクションの [フィールド名] 列で、Cancelled、FlightDelay、および FlightDelayType をクリアします。
Cancelled、FlightDelay、および FlightDelayType フィールドは、遅延予測には役に立ちません。タスクが不要な要因の影響を受けないようにし、予測精度を向上させるために、これらのフィールドを除外することをお勧めします。
[トレーニングパーセント] セクションで、ノブをスライドさせて、トレーニングに使用するデータのパーセンテージを変更します。
ビジネス要件に基づいてパーセンテージを変更できます。この例では、パーセンテージは 90% に設定されています。
説明トレーニングに大量のデータを使用する場合、タスクのトレーニングに必要な時間に注意する必要があります。データ量が多いほど、トレーニング期間が長くなります。データ量が多い場合は、50% 以下などの小さいパーセンテージを指定することをお勧めします。次に、ビジネス要件に基づいてパーセンテージを変更して、適切な精度を得ることができます。
[続行] をクリックします。[追加オプション] ステップで設定を構成します。
[特徴量の重要度の値] を 5 に設定します。これにより、予測結果に最も大きく影響する上位 5 つの特徴量が決定されます。これは、予測結果に最も影響を与える特徴を特定し、最も適切な特徴を選択してタスクを最適化するのに役立ちます。
[予測フィールド名] を FlightDelayMin_prediction に設定します。このパラメーターは、予測を実行する変数の名前を指定します。
[推定モデルメモリ制限を使用する] を無効にし、[モデルメモリ制限] を 500 MB に設定します。[モデルメモリ制限] パラメーターは、機械学習タスクで使用できるメモリのサイズの上限を指定します。データセットのデータサイズが大きく、機械学習タスクが複雑な場合、大量のメモリが消費される可能性があります。使用されるメモリのサイズが上限を超えると、機械学習タスクのトレーニングが失敗したり、タスクのパフォーマンスが低下したりする可能性があります。データセットのデータサイズと機械学習タスクの複雑さに基づいて、適切な上限を指定する必要があります。
[最大スレッド数] を 1 に設定します。このパラメーターは、機械学習タスクのトレーニングに使用できる最大スレッド数を指定します。多数のスレッドを指定すると、メモリが不足したり、システムが応答しなくなる可能性があります。
[続行] をクリックし、[ジョブの詳細] ステップでパラメーターを構成します。ジョブ ID を flightdelaymin_job に設定します。
[続行] をクリックします。システムはタスクを検証します。
検証に合格した場合は、[続行] をクリックします。
[作成] ステップで、[作成] をクリックします。
ジョブを生成するには、一定の時間がかかります。実際に消費される時間は、トレーニングに使用されるデータ量によって決まります。
ジョブの作成後、[結果の表示] をクリックして、ジョブの実行結果を表示します。
表示されるページの [モデル評価] セクションで、タスクの信頼性を示すメトリックを表示します。
汎化誤差: タスクの汎化能力を反映する新しいデータでのタスクのパフォーマンスを測定します。汎化誤差が小さいほど、汎化能力が高いことを示します。汎化能力が高いタスクは、新しいデータに対してより正確な予測を実行できます。
トレーニング誤差: データセットベースのトレーニングでのタスクのパフォーマンスと、タスクの学習プロセス中に生成された誤差を反映します。値が小さいほど、データセットベースのトレーニングでのタスクのパフォーマンスが向上します。
評価メトリックの説明:
平均二乗誤差: 回帰タスクのパフォーマンスを測定する重要なメトリックです。値が小さいほど、予測結果がより正確になります。この値は、実際の値と回帰タスクによって提供される予測値の差の二乗平均を計算することによって得られます。
決定係数 (R 2 乗): 回帰タスクのパフォーマンスを測定する重要なメトリックです。1 に近い値は、タスクが実際の値によりよく適合していることを示します。0.8 を超える値は、タスクの適合度が高いことを示します。
平均二乗対数誤差: 値が小さいほど、予測効果が向上します。この値は、予測値と実際の値の対数を返した後、二乗誤差の合計の平均値を計算することによって得られます。
説明複数の回帰タスクを比較する場合、平均二乗誤差メトリックの値と決定係数メトリックの値に注意する必要があります。これは、最適なタスクまたは特定のデータセットに適したタスクを決定するのに役立ちます。
ほとんどの場合、平均二乗誤差メトリックの値が 0 になることはなく、決定係数メトリックの値が 1 になることはありません。その理由は、タスクの予測結果が複数の要因の影響を受けるためです。これらの要因すべてを考慮してエラーを排除することはできない場合があります。
平均二乗対数誤差メトリックの値 NaN は、予測結果または実際の値が負の数または 0 であることを示します。
詳細については、「データフレーム分析の評価」をご参照ください。
フライト遅延予測タスクを使用する
Kibana によって提供される推論プロセッサに基づいて、フライト遅延予測タスクを使用できます。
Kibana コンソールの左上隅にある
アイコンをクリックします。左側のナビゲーションペインで、[管理] > [開発ツール] を選択します。[コンソール] タブで、次のコマンドを実行して model_id パラメータの値を表示および記録します。
GET _ml/inference/flightdelaymin_job*?human=trueこのコマンドは、ID が flightdelaymin_job のジョブのすべての推論と分析結果をクエリし、結果を人間が読める形式で返すために使用されます。コマンドの flightdelaymin_job は、回帰と推論タスクのトレーニングのために作成されたジョブの ID を指定します。
回帰と推論タスク、および推論プロセッサに基づいてパイプラインを作成します。
説明次のコマンドの model_id パラメータの値を、前の手順で取得した値に置き換える必要があります。
PUT _ingest/pipeline/flight_flightDelayMin_predict { "description": "各フライトの遅延時間 (分) を予測する", "processors": [ { "inference": { "model_id": "flightDelayMin_job-168609891****", "inference_config": { "regression": {} }, "field_map": {}, "tag": "flightDelayMin_prediction" } } ] }kibana_sample_data_flightsインデックスのデータに基づいて、FlightDelayMin 変数に対してデータ分析と予測を実行します。
POST _ingest/pipeline/flight_flightDelayMin_predict/_simulate { "docs": [ { "_source": { "FlightNum": "EDGSV3T", "DestCountry": "CN", "OriginWeather": "Damaging Wind", "OriginCityName": "Durban", "AvgTicketPrice": 1065.7037805199147, "DistanceMiles": 7273.460817641552, "FlightDelay": true, "DestWeather": "Rain", "Dest": "Shanghai Pudong International Airport", "FlightDelayType": "Carrier Delay", "OriginCountry": "ZA", "dayOfWeek": 5, "DistanceKilometers": 11705.500526106527, "timestamp": "2023-06-03T09:34:00", "DestLocation": { "lat": "31.14340019", "lon": "121.8050003" }, "DestAirportID": "PVG", "Carrier": "Kibana Airlines", "Cancelled": false, "FlightTimeMin": 881.1071804361806, "Origin": "King Shaka International Airport", "OriginLocation": { "lat": "-29.61444444", "lon": "31.11972222" }, "DestRegion": "SE-BD", "OriginAirportID": "DUR", "OriginRegion": "SE-BD", "DestCityName": "Shanghai", "FlightTimeHour": 14.685119673936343, "FlightDelayMin": 45 } } ] }次の図は結果を示しています。
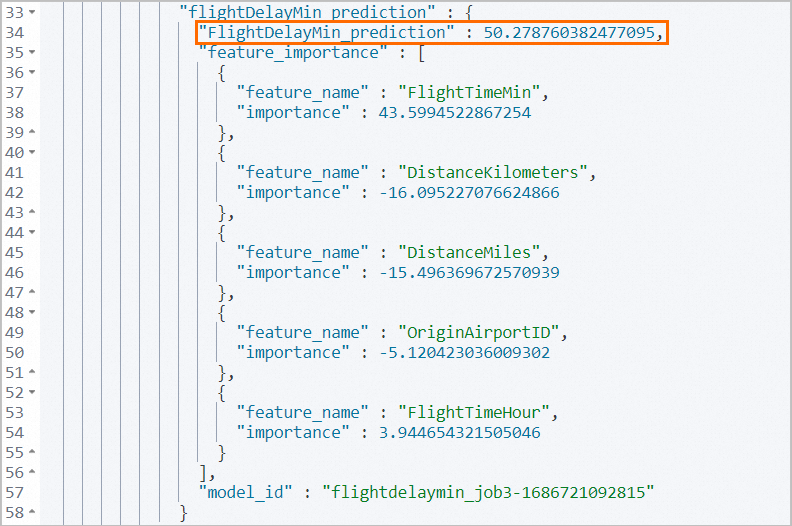
FlightDelayMin 変数の実際の値は 45 分です。予測で得られた FlightDelayMin_prediction 変数の値は 50.28 分で、実際の値に近いです。
feature_importance パラメータは、フライト遅延の予測結果に最も大きく影響する上位 5 つの要因を返します: FlightTimeMin、DistanceKilometers、DistanceMiles、OriginAirportID、および FlightTimeHour。これらの要因の値を変更して、異なる予測結果を得ることができます。これにより、タスクは各フライトの遅延時間をより正確に予測できます。