Spark Thrift Server は、JDBC または ODBC 接続による SQL クエリの実行をサポートする Apache Spark 提供のサービスであり、既存のビジネスインテリジェンス (BI) ツール、データ可視化ツール、その他のデータ分析ツールと Spark 環境を便利に統合できます。この Topic では、Spark Thrift Server の作成方法と接続方法について説明します。
前提条件
ワークスペースが作成されていること。詳細については、「ワークスペースの管理」をご参照ください。
Spark Thrift Server セッションの作成
Spark Thrift Server を作成すると、Spark SQL タスクを作成するときにこのセッションを選択できます。
セッションページに移動します。
EMR コンソール にログオンします。
左側のナビゲーションウィンドウで、 を選択します。
[Spark] ページで、管理するワークスペースの名前をクリックします。
[EMR Serverless Spark] ページの左側のナビゲーションウィンドウで、[オペレーションセンター] > [セッション] を選択します。
[セッションマネージャー] ページで、[Spark Thrift Server セッション] タブをクリックします。
[Spark Thrift Server セッションの作成] をクリックします。
[Spark Thrift Server セッションの作成] ページで、パラメーターを構成し、[作成] をクリックします。
パラメーター
説明
[名前]
新しい Spark Thrift Server の名前。
名前は 1 ~ 64 文字で、文字、数字、ハイフン(-)、アンダースコア(_)、およびスペースを含めることができます。
[デプロイメントキュー]
セッションをデプロイするための適切な開発キューを選択します。開発キュー、または開発環境と本番環境で共有されるキューのみを選択できます。
キューの詳細については、「リソースキューの管理」をご参照ください。
[エンジンバージョン]
現在のセッションで使用されるエンジンバージョン。エンジンバージョンの詳細については、「エンジンバージョンの紹介」をご参照ください。
[Fusion アクセラレーションの使用]
Fusion は、Spark ワークロードの実行を高速化し、タスクの総コストを削減できます。課金情報については、「課金」をご参照ください。Fusion エンジンの詳細については、「Fusion エンジン」をご参照ください。
[自動停止]
この機能はデフォルトで有効になっています。Spark Thrift Server セッションは、45 分間操作がないと自動的に停止します。
[ネットワーク接続]
Spark Thrift Server ポート
パブリックエンドポイントを使用してサーバーにアクセスする場合、ポート番号は 443 です。内部の同一リージョンエンドポイントを使用してサーバーにアクセスする場合、ポート番号は 80 です。
[アクセスクレデンシャル]
トークン方式のみがサポートされています。
spark.driver.cores
Spark アプリケーションのドライバープロセスで使用される CPU コアの数。デフォルト値は 1 CPU です。
spark.driver.memory
Spark アプリケーションのドライバープロセスが使用できるメモリ量。デフォルト値は 3.5 GB です。
spark.executor.cores
各 Executor プロセスが使用できる CPU コアの数。デフォルト値は 1 CPU です。
spark.executor.memory
各 Executor プロセスが使用できるメモリ量。デフォルト値は 3.5 GB です。
spark.executor.instances
Spark によって割り当てられる Executor の数。デフォルト値は 2 です。
[動的リソース割り当て]
デフォルトでは、この機能は無効になっています。この機能を有効にした後、次のパラメーターを構成する必要があります。
[Executor の最小数]: デフォルト値: 2。
[Executor の最大数]: [spark.executor.instances] パラメーターを構成しない場合、デフォルト値 10 が使用されます。
[その他のメモリ構成]
[spark.driver.memoryOverhead]: 各ドライバーが使用できる非ヒープメモリのサイズ。このパラメーターを空のままにすると、Spark は次の式に基づいてこのパラメーターに値を自動的に割り当てます:
max(384 MB, 10% × spark.driver.memory)。[spark.executor.memoryOverhead]: 各 Executor が使用できる非ヒープメモリのサイズ。このパラメーターを空のままにすると、Spark は次の式に基づいてこのパラメーターに値を自動的に割り当てます:
max(384 MB, 10% × spark.executor.memory)。[spark.memory.offHeap.size]: Spark アプリケーションが使用できるオフヒープメモリのサイズ。デフォルト値: 1 GB。
このパラメーターは、
spark.memory.offHeap.enabledパラメーターをtrueに設定した場合にのみ有効です。デフォルトでは、Fusion エンジンを使用する場合、spark.memory.offHeap.enabled パラメーターは true に設定され、spark.memory.offHeap.size パラメーターは 1 GB に設定されます。
[Spark 構成]
Spark 構成情報を入力します。デフォルトでは、パラメーターはスペースで区切られます。例:
spark.sql.catalog.paimon.metastore dlf。エンドポイント情報を取得します。
[Spark Thrift Server セッション] タブで、新しい Spark Thrift Server の名前をクリックします。
[概要] タブで、エンドポイント情報をコピーします。
ネットワーク環境に基づいて、次のエンドポイントのいずれかを選択できます。
パブリックエンドポイント: ローカル開発マシン、外部ネットワーク、またはクラウド間の環境など、インターネット経由で EMR Serverless Spark にアクセスする必要があるシナリオに適しています。この方法では、トラフィック料金が発生する場合があります。必要なセキュリティ対策を講じていることを確認してください。
内部の同一リージョンエンドポイント: 同じリージョンにある Alibaba Cloud ECS インスタンスが内部ネットワーク経由で EMR Serverless Spark にアクセスするシナリオに適しています。内部ネットワークアクセスは無料でより安全ですが、同じリージョンにある Alibaba Cloud 内部ネットワーク環境に限定されます。
トークンの作成
[Spark Thrift Server セッション] タブで、新しい Spark Thrift Server セッションの名前をクリックします。
[トークン管理] タブをクリックします。
[トークンの作成] をクリックします。
[トークンの作成] ダイアログボックスで、パラメーターを構成し、[OK] をクリックします。
パラメーター
説明
[名前]
新しいトークンの名前。
[有効期限]
トークンの有効期限。日数は 1 以上である必要があります。この機能はデフォルトで有効になっており、トークンは 365 日後に有効期限切れになります。
トークン情報をコピーします。
重要トークンが作成されたら、すぐに新しいトークンの情報をコピーする必要があります。後でトークン情報を表示することはできません。トークンの有効期限が切れた場合、またはトークンを紛失した場合は、新しいトークンを作成するか、トークンをリセットできます。
Spark Thrift Server への接続
Spark Thrift Server に接続する場合は、実際の状況に合わせて以下の情報を置き換えてください。
<endpoint>: [エンドポイント(パブリック)] または [エンドポイント(内部)] 情報。これは [概要] タブで取得しました。内部の同一リージョンエンドポイントを使用する場合、Spark Thrift Server へのアクセスは同じ VPC 内のリソースに制限されます。
<port>: ポート番号。パブリックエンドポイントを使用してサーバーにアクセスする場合、ポート番号は 443 です。内部の同一リージョンエンドポイントを使用してサーバーにアクセスする場合、ポート番号は 80 です。<username>: [トークン管理] タブで作成したトークンの名前。<token>: [トークン管理] タブでコピーしたトークン情報。
Python を使用して Spark Thrift Server に接続する
次のコマンドを実行して、PyHive パッケージと Thrift パッケージをインストールします。
pip install pyhive thriftSpark Thrift Server に接続するための Python スクリプトを作成します。
以下は、Hive に接続してデータベースのリストを表示する方法を示す Python スクリプトの例です。ネットワーク環境(パブリックまたは内部)に基づいて、適切な接続方法を選択できます。
パブリックエンドポイントを使用して接続する
from pyhive import hive if __name__ == '__main__': # <endpoint>、<username>、および <token> を実際の情報に置き換えます。 cursor = hive.connect('<endpoint>', port=443, scheme='https', username='<username>', password='<token>').cursor() cursor.execute('show databases') print(cursor.fetchall()) cursor.close()内部の同一リージョンエンドポイントを使用して接続する
from pyhive import hive if __name__ == '__main__': # <endpoint>、<username>、および <token> を実際の情報に置き換えます。 cursor = hive.connect('<endpoint>', port=80, scheme='http', username='<username>', password='<token>').cursor() cursor.execute('show databases') print(cursor.fetchall()) cursor.close()
Java を使用して Spark Thrift Server に接続する
次の Maven 依存関係を
pom.xmlファイルに追加します。<dependencies> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>3.0.0</version> </dependency> <dependency> <groupId>org.apache.hive</groupId> <artifactId>hive-jdbc</artifactId> <version>2.1.0</version> </dependency> </dependencies>説明Serverless Spark の組み込み Hive バージョンは 2.x です。したがって、hive-jdbc 2.x バージョンのみがサポートされています。
Spark Thrift Server に接続するための Java コードを作成します。
以下は、Spark Thrift Server に接続してデータベースリストを照会する Java コードのサンプルです。
パブリックエンドポイントを使用して接続する
import java.sql.Connection; import java.sql.DriverManager; import java.sql.ResultSet; import java.sql.ResultSetMetaData; import org.apache.hive.jdbc.HiveStatement; public class Main { public static void main(String[] args) throws Exception { String url = "jdbc:hive2://<endpoint>:443/;transportMode=http;httpPath=cliservice/token/<token>"; Class.forName("org.apache.hive.jdbc.HiveDriver"); Connection conn = DriverManager.getConnection(url); HiveStatement stmt = (HiveStatement) conn.createStatement(); String sql = "show databases"; System.out.println("Running " + sql); ResultSet res = stmt.executeQuery(sql); ResultSetMetaData md = res.getMetaData(); String[] columns = new String[md.getColumnCount()]; for (int i = 0; i < columns.length; i++) { columns[i] = md.getColumnName(i + 1); } while (res.next()) { System.out.print("Row " + res.getRow() + "=["); for (int i = 0; i < columns.length; i++) { if (i != 0) { System.out.print(", "); } System.out.print(columns[i] + "='" + res.getObject(i + 1) + "'"); } System.out.println(")]"); } conn.close(); } }内部の同一リージョンエンドポイントを使用して接続する
import java.sql.Connection; import java.sql.DriverManager; import java.sql.ResultSet; import java.sql.ResultSetMetaData; import org.apache.hive.jdbc.HiveStatement; public class Main { public static void main(String[] args) throws Exception { String url = "jdbc:hive2://<endpoint>:80/;transportMode=http;httpPath=cliservice/token/<token>"; Class.forName("org.apache.hive.jdbc.HiveDriver"); Connection conn = DriverManager.getConnection(url); HiveStatement stmt = (HiveStatement) conn.createStatement(); String sql = "show databases"; System.out.println("Running " + sql); ResultSet res = stmt.executeQuery(sql); ResultSetMetaData md = res.getMetaData(); String[] columns = new String[md.getColumnCount()]; for (int i = 0; i < columns.length; i++) { columns[i] = md.getColumnName(i + 1); } while (res.next()) { System.out.print("Row " + res.getRow() + "=["); for (int i = 0; i < columns.length; i++) { if (i != 0) { System.out.print(", "); } System.out.print(columns[i] + "='" + res.getObject(i + 1) + "'"); } System.out.println(")]"); } conn.close(); } }
Spark Beeline を使用して Spark Thrift Server に接続する
セルフビルドクラスタを使用している場合は、最初に Spark の
binディレクトリに移動してから、beeline を使用して Spark Thrift Server に接続する必要があります。パブリックエンドポイントを使用して接続する
cd /opt/apps/SPARK3/spark-3.4.2-hadoop3.2-1.0.3/bin/ ./beeline -u "jdbc:hive2://<endpoint>:443/;transportMode=http;httpPath=cliservice/token/<token>"内部の同一リージョンエンドポイントを使用して接続する
cd /opt/apps/SPARK3/spark-3.4.2-hadoop3.2-1.0.3/bin/ ./beeline -u "jdbc:hive2://<endpoint>:80/;transportMode=http;httpPath=cliservice/token/<token>"説明このコードは、ECS クラスタ上の EMR の Spark インストールパスの例として
/opt/apps/SPARK3/spark-3.4.2-hadoop3.2-1.0.3を使用しています。クライアントの実際の Spark インストールパスに基づいてパスを調整する必要があります。Spark インストールパスがわからない場合は、env | grep SPARK_HOMEコマンドを使用してパスを見つけることができます。ECS クラスタ上の EMR を使用している場合は、Spark Beeline クライアントを直接使用して Spark Thrift Server に接続できます。
パブリックエンドポイントを使用して接続する
spark-beeline -u "jdbc:hive2://<endpoint>:443/;transportMode=http;httpPath=cliservice/token/<token>"内部の同一リージョンエンドポイントを使用して接続する
spark-beeline -u "jdbc:hive2://<endpoint>:80/;transportMode=http;httpPath=cliservice/token/<token>"
Hive Beeline を使用して Serverless Spark Thrift Server に接続するときに次のエラーが発生した場合、通常は Hive Beeline のバージョンが Spark Thrift Server と互換性がないことが原因です。したがって、Hive Beeline 2.x を使用することをお勧めします。
24/08/22 15:09:11 [main]: ERROR jdbc.HiveConnection: Error opening session
org.apache.thrift.transport.TTransportException: HTTP Response code: 404Apache Superset を構成して Spark Thrift Server に接続する
Apache Superset は、シンプルな折れ線グラフから非常に詳細な地理空間グラフまで、豊富なグラフ形式を備えた最新のデータ探索および 可視化 プラットフォームです。Superset の詳細については、Superset をご覧ください。
依存関係をインストールします。
thriftパッケージバージョン 0.20.0 をインストール済みであることを確認します。インストールされていない場合は、次のコマンドを使用してインストールできます。pip install thrift==0.20.0Superset を起動し、Superset インターフェースに移動します。
Superset の起動方法の詳細については、Superset ドキュメント をご覧ください。
ページの右上隅にある [DATABASE] をクリックして、[Connect A Database] ページに移動します。
[Connect A Database] ページで、[Apache Spark SQL] を選択します。
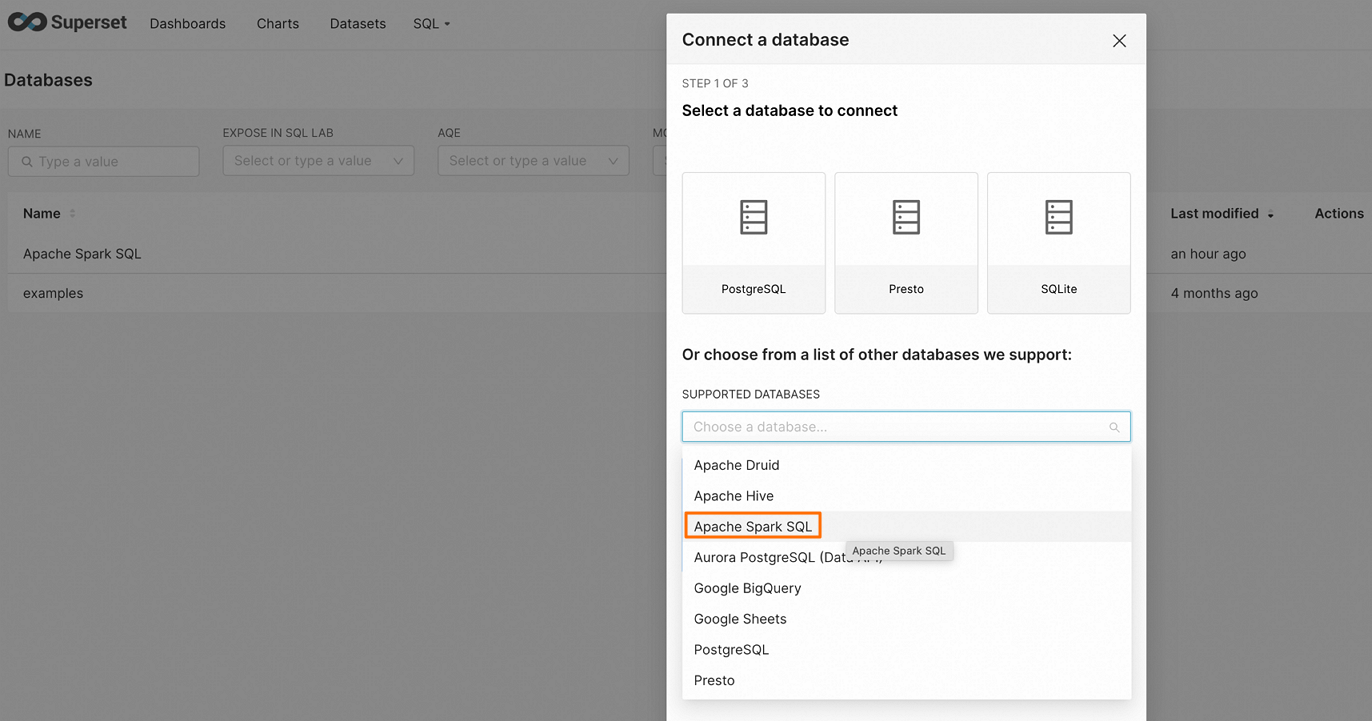
接続文字列を入力し、関連するデータソースパラメーターを構成します。
パブリックエンドポイントを使用して接続する
hive+https://<username>:<token>@<endpoint>:443/<db_name>内部の同一リージョンエンドポイントを使用して接続する
hive+http://<username>:<token>@<endpoint>:80/<db_name>[FINISH] をクリックして、接続と検証が成功したことを確認します。
Hue を構成して Spark Thrift Server に接続する
Hue は、Hadoop エコシステムと対話するための一般的なオープンソース Web インターフェースです。Hue の詳細については、Hue 公式ドキュメント をご覧ください。
依存関係をインストールします。
thriftパッケージバージョン 0.20.0 をインストール済みであることを確認します。インストールされていない場合は、次のコマンドを使用してインストールできます。pip install thrift==0.20.0Spark SQL 接続文字列を Hue 構成ファイルに追加します。
Hue 構成ファイル(通常は
/etc/hue/hue.confにあります)を見つけて、次の内容をファイルに追加します。パブリックエンドポイントを使用して接続する
[[[sparksql]]] name = Spark Sql interface=sqlalchemy options='{"url": "hive+https://<username>:<token>@<endpoint>:443/"}'内部の同一リージョンエンドポイントを使用して接続する
[[[sparksql]]] name = Spark Sql interface=sqlalchemy options='{"url": "hive+http://<username>:<token>@<endpoint>:80/"}'Hue を再起動します。
構成を変更した後、次のコマンドを実行して Hue サービスを再起動し、変更を有効にする必要があります。
sudo service hue restart接続を確認します。
Hue が正常に再起動されたら、Hue インターフェースにアクセスして、Spark SQL オプションを見つけます。構成が正しい場合は、Spark Thrift Server に正常に接続して SQL クエリを実行できるはずです。
DataGrip を使用して Spark Thrift Server に接続する
DataGrip は、開発者向けのデータベース管理環境であり、データベースのクエリ、作成、および管理を容易にするように設計されています。データベースは、ローカル、サーバー、またはクラウドで実行できます。 DataGrip の詳細については、DataGrip をご覧ください。
DataGrip をインストールします。詳細については、DataGrip のインストール をご覧ください。
この例で使用されている DataGrip のバージョンは 2025.1.2 です。
DataGrip クライアントを開き、DataGrip インターフェースに移動します。
プロジェクトを作成します。
 をクリックし、 を選択します。
をクリックし、 を選択します。
[New Project] ダイアログボックスで、
Sparkなどのプロジェクト名を入力し、[OK] をクリックします。
[Database Explorer]
 メニューバーのアイコンをクリックします。 を選択します。
メニューバーのアイコンをクリックします。 を選択します。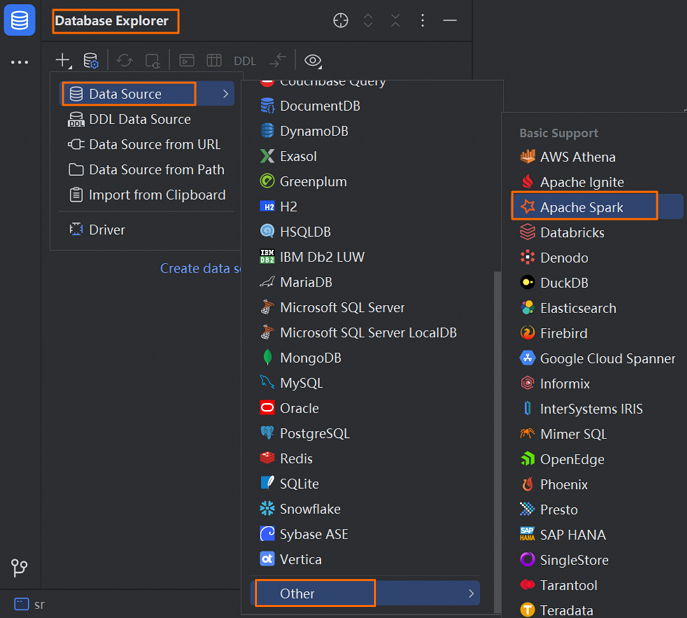
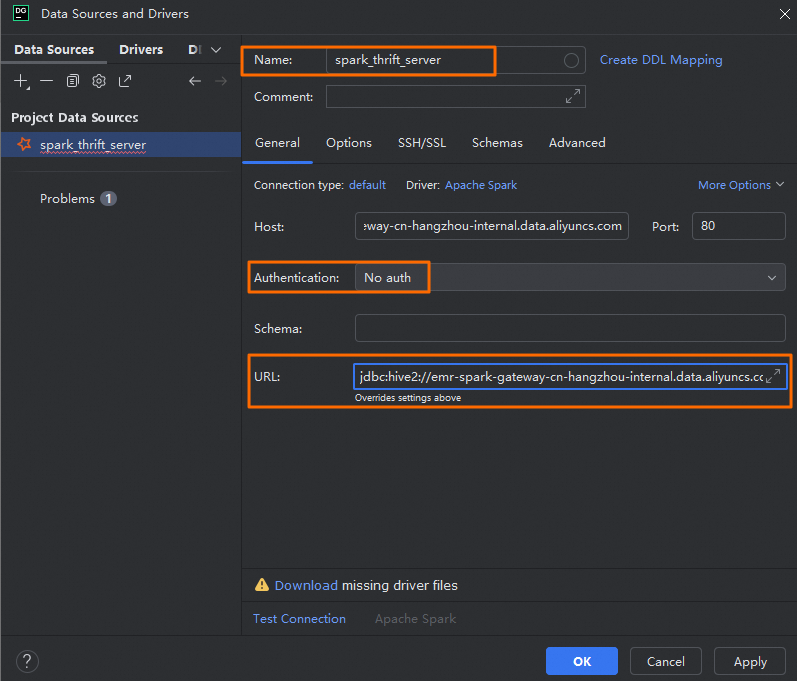
[Data Sources And Drivers] ダイアログボックスで、次のパラメーターを構成します。
タブ
パラメーター
説明
[General]
名前
カスタム接続名。例: spark_thrift_server。
[Authentication]
認証方法。この例では、[No Auth] が選択されています。
本番環境では、[User & Password] を選択して、承認されたユーザーのみが SQL タスクを送信できるようにします。これにより、システムのセキュリティが向上します。
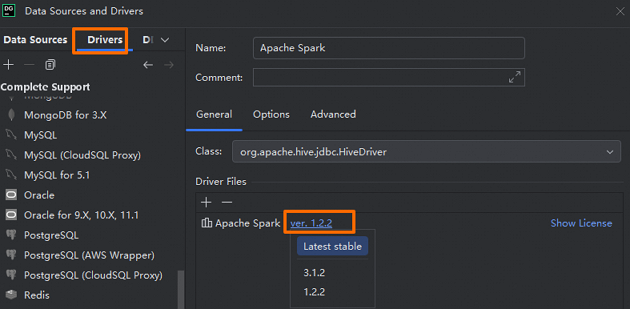
[Driver]
[Apache Spark] をクリックし、次に [Go To Driver] をクリックして、ドライバーのバージョンが
ver. 1.2.2であることを確認します。説明現在の Serverless Spark エンジンバージョンは 3.x であるため、システムの安定性と機能の互換性を確保するには、ドライバーのバージョンを 1.2.2 にする必要があります。
[URL]
Spark Thrift Server に接続するための URL。ネットワーク環境(パブリックまたは内部)に基づいて、適切な接続方法を選択できます。
パブリックエンドポイントを使用して接続する
jdbc:hive2://<endpoint>:443/;transportMode=http;httpPath=cliservice/token/<token>内部の同一リージョンエンドポイントを使用して接続する
jdbc:hive2://<endpoint>:80/;transportMode=http;httpPath=cliservice/token/<token>
[Options]
[Run Keep-alive Query]
このパラメーターはオプションです。タイムアウトによる自動切断を防ぐには、このパラメーターを選択します。
[Test Connection] をクリックして、データソースが正常に構成されていることを確認します。
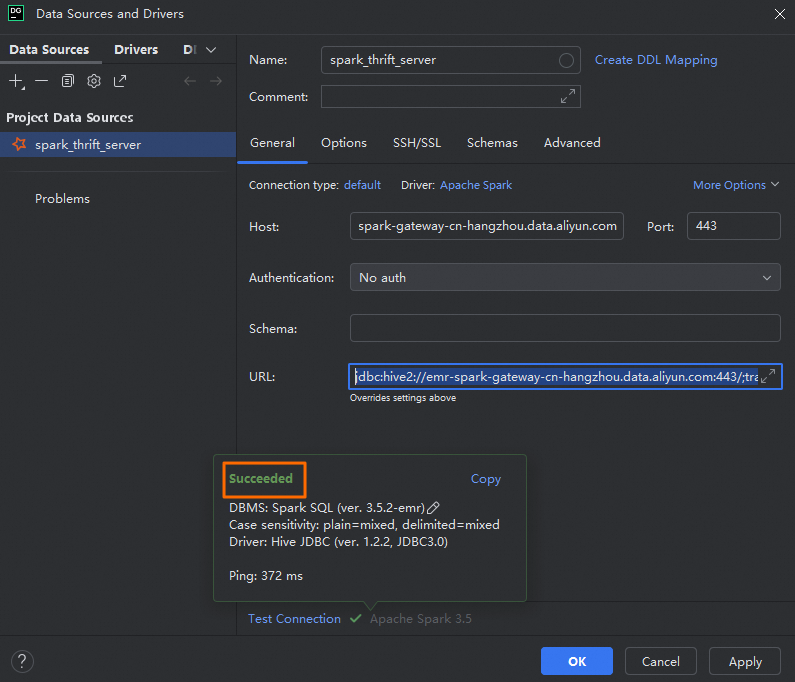
[OK] をクリックして構成を完了します。
DataGrip を使用して Spark Thrift Server を管理します。
DataGrip が Spark Thrift Server に正常に接続した後、データ開発を実行できます。詳細については、「DataGrip ヘルプ」をご参照ください。
たとえば、作成された接続で、ターゲットテーブルを右クリックし、 を選択します。次に、右側の SQL エディターで SQL スクリプトを作成して実行し、テーブルデータ情報を表示できます。

Redash を Spark Thrift Server に接続する
Redash は、Web ベースのデータベースクエリとデータ可視化機能を提供するオープンソースの BI ツールです。
Redash をインストールします。インストール手順については、「Redash インスタンスのセットアップ」をご参照ください。
依存関係をインストールします。バージョン 0.20.0 の
thriftパッケージがインストールされていることを確認します。インストールされていない場合は、次のコマンドを実行します。pip install thrift==0.20.0Redash にログオンします。
左側のナビゲーションウィンドウで、[設定] をクリックします。[データソース] タブで、[+ 新しいデータソース] をクリックします。
ダイアログボックスで、次のパラメーターを設定し、[作成] をクリックします。

パラメーター | 説明 | |
種類の選択 | データソースの種類。[Hive (HTTP)] を選択します。 | |
構成 | 名前 | データソースのカスタム名を入力します。 |
ホスト | Spark Thrift Server のエンドポイントを入力します。[概要] タブでパブリックエンドポイントまたは内部エンドポイントを確認できます。 | |
ポート | パブリックドメイン名経由でアクセスする場合は 443 を使用し、内部ドメイン名の場合は 80 を使用します。 | |
HTTP パス |
| |
ユーザー名 |
| |
パスワード | 作成したトークン値を入力します。 | |
HTTP スキーム | パブリックドメイン名を使用する場合は | |
ページ上部で、 を選択します。エディターで SQL 文を記述できます。

特定のセッションを使用して実行されたジョブを表示する
セッションページで、特定のセッションを使用して実行されたジョブを表示できます。手順:
[セッション] ページで、目的のセッションの名前をクリックします。
表示されたページで、[実行レコード] タブをクリックします。
[実行レコード] タブで、実行 ID や開始時刻など、ジョブの詳細を表示し、[Spark UI] 列のリンクをクリックして Spark UI にアクセスできます。
