制限事項
この機能は、以下の Serverless Spark エンジンバージョンでのみサポートされています。
-
esr-4.x:esr-4.2.0 以降
-
esr-3.x:esr-3.0.1 以降
-
esr-2.x:esr-2.4.1 以降
注意事項
Ranger は権限付与を担当しますが、ID 認証には LDAP などの別の認証サービスが必要です。詳細については、「Spark Thrift サーバーの LDAP 認証の設定と有効化」をご参照ください。
前提条件
Spark Thrift サーバーセッションが作成済みであること。詳細については、「Spark Thrift サーバーセッションの管理」をご参照ください。
操作手順
ステップ 1: ネットワークの準備
Serverless Spark がお使いの Virtual Private Cloud (VPC) と通信できるようにネットワークを設定します。これにより、Ranger プラグインが Ranger Admin に接続し、権限情報を取得できるようになります。詳細については、「EMR Serverless Spark と他の VPC 間のネットワーク接続の確立」をご参照ください。
ステップ 2: Ranger プラグインの設定
Spark Thrift サーバーセッションで Ranger 権限付与を有効にするには、まずセッションを停止します。Normal Network Connection ドロップダウンリストから、作成したネットワーク接続の名前を選択します。次に、Spark Configuration セクションで、次のプロパティを追加します。構成を編集した後、セッションを再起動して変更を適用します。
オプション 1:組み込み Ranger プラグイン
spark.ranger.plugin.enabled true
spark.jars /opt/ranger/ranger-spark.jar
ranger.plugin.spark.policy.rest.url http://<ranger_admin_ip>:<ranger_admin_port><ranger_admin_ip> と <ranger_admin_port> を、お使いの Ranger Admin サービスの内部 IP アドレスとポートに置き換えます。 EMR on ECS クラスター内の Ranger サービスに接続する場合、<ranger_admin_ip> にはマスターノードの内部 IP アドレスを、<ranger_admin_port> には 6080 を使用できます。
オプション 2:カスタム Ranger プラグイン
カスタム Ranger プラグインを使用する必要がある場合は、それを Object Storage Service (OSS) にアップロードし、以下のパラメーターを使用してカスタム JAR ファイルとクラス名を指定します。
spark.jars oss://<bucket>/path/to/user-ranger-spark.jar
spark.ranger.plugin.class <class_name>
spark.ranger.plugin.enabled true
ranger.plugin.spark.policy.rest.url http://<ranger_admin_ip>:<ranger_admin_port>以下のプレースホルダーを実際の情報に置き換えてください:
-
spark.jars:カスタム JAR ファイルの OSS パス。 -
spark.ranger.plugin.class:カスタム Ranger プラグイン内の Spark 拡張クラスの名前。 -
<ranger_admin_ip>と<ranger_admin_port>は、Ranger Admin サービスの内部 IP アドレスとポートです。 EMR on ECS クラスターの Ranger サービスに接続する場合、<ranger_admin_ip>にはマスターノードの内部 IP アドレスを、<ranger_admin_port>には 6080 を使用できます。
ステップ 3: (オプション) Ranger Audit の設定
Ranger は、監査レコード用に、Solr や Hadoop 分散ファイルシステム (HDFS) などのさまざまなストレージバックエンドをサポートしています。デフォルトでは、Serverless Spark の Ranger 監査機能は無効になっています。この機能が必要な場合は、Spark Configuration セクションに関連する Ranger 監査パラメーターを追加してください。
たとえば、EMR クラスター上の Solr への接続を設定するには、Spark Configuration セクションに次のプロパティを追加します。
xasecure.audit.is.enabled true
xasecure.audit.destination.solr true
xasecure.audit.destination.solr.urls http://<solr_ip>:<solr_port>/solr/ranger_audits
xasecure.audit.destination.solr.user <user>
xasecure.audit.destination.solr.password <password>パラメーターの説明は以下の通りです。
-
xasecure.audit.is.enabled:Ranger Audit を有効にするかどうかを指定します。 -
xasecure.audit.destination.solr:監査レコードを Solr サービスに保存するかどうかを指定します。 -
xasecure.audit.destination.solr.urls: Solr サービスの URL です。<solr_ip>と<solr_port>を、お使いの Solr サービスの IP アドレスとポートに置き換えます。URL の残りの部分は必要に応じて設定します。 -
xasecure.audit.destination.solr.userとxasecure.audit.destination.solr.password:Solr のユーザー名とパスワードです。基本認証が有効な場合に必要です。EMR on ECS クラスターの Ranger に接続する場合、
xasecure.audit.destination.solr.urls、xasecure.audit.destination.solr.user、およびxasecure.audit.destination.solr.passwordの値は、 Ranger-plugin サービスの ranger-spark-audit.xml 設定ファイルにあります。
設定が完了すると、EMR Serverless Spark でジョブを送信し、Ranger Web UI の [Access] タブでユーザーアクセスの監査レコードを表示できます。Ranger Web UI へのアクセス方法の詳細については、「コンソールでオープンソースコンポーネントの Web UI にアクセスする」をご参照ください。
HDFS やその他のサポートされていないバックエンドを使用する場合、これらのレコードは Ranger Web UI に表示されません。
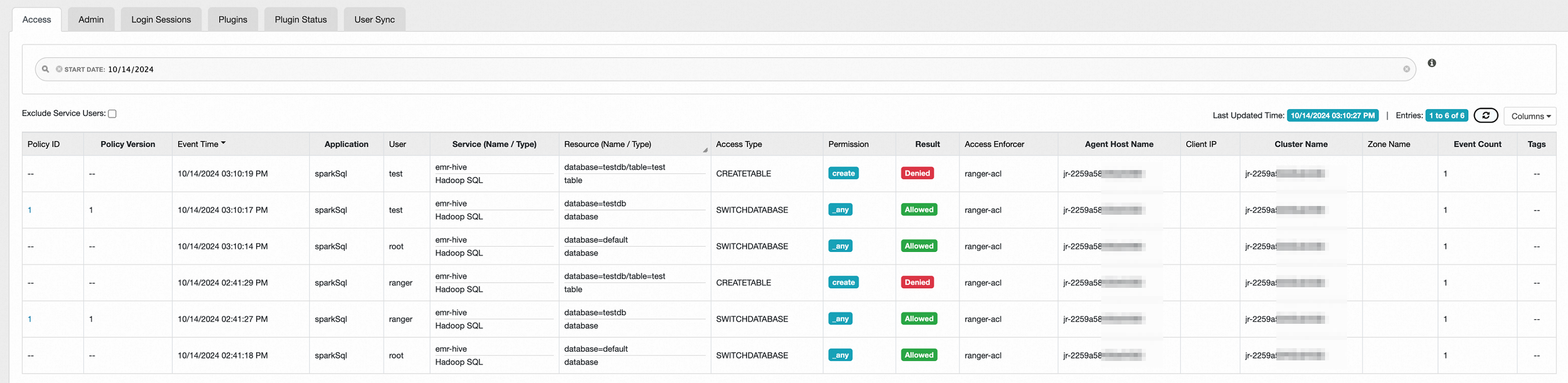
ステップ 4: 接続性のテスト
Beeline で接続する際に、権限のないデータベース、テーブル、またはその他のリソースにアクセスしようとすると、権限エラーがトリガーされます。
0: jdbc:hive2://pre-emr-spark-gateway-cn-hang> create table test(id int);
Error: org.apache.hive.service.cli.HiveSQLException: Error running query: org.apache.kyuubi.plugin.spark.authz.AccessControlException: Permission denied: user [test] does not have [create] privilege on [database=testdb/table=test]
at org.apache.spark.sql.hive.thriftserver.HiveThriftServerErrors$.runningQueryError(HiveThriftServerErrors.scala:44)
at org.apache.spark.sql.hive.thriftserver.SparkExecuteStatementOperation.org$apache$spark$sql$hive$thriftserver$SparkExecuteStatementOperation$$execute(SparkExecuteStatementOperation.scala:325)
at org.apache.spark.sql.hive.thriftserver.SparkExecuteStatementOperation$$anon$2$$anon$3.$anonfun$run$2(SparkExecuteStatementOperation.scala:230)
at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23)
at org.apache.spark.sql.hive.thriftserver.SparkOperation.withLocalProperties(SparkOperation.scala:79)
at org.apache.spark.sql.hive.thriftserver.SparkOperation.withLocalProperties$(SparkOperation.scala:63)
at org.apache.spark.sql.hive.thriftserver.SparkExecuteStatementOperation.withLocalProperties(SparkExecuteStatementOperation.scala:43)
at org.apache.spark.sql.hive.thriftserver.SparkExecuteStatementOperation$$anon$2$$anon$3.run(SparkExecuteStatementOperation.scala:230)
at org.apache.spark.sql.hive.thriftserver.SparkExecuteStatementOperation$$anon$2$$anon$3.run(SparkExecuteStatementOperation.scala:225)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1730)
at org.apache.spark.sql.hive.thriftserver.SparkExecuteStatementOperation$$anon$2.run(SparkExecuteStatementOperation.scala:239)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:750)-
権限をテストする際は、Ranger のデフォルトの権限ポリシーにご注意ください。たとえば、デフォルトでは、すべてのユーザーがデータベースを切り替えて作成でき、リソースの所有者はそのリソースに対するすべての権限を持ちます。有効なテストを実施するには、ユーザー A としてデータベースやテーブルなどのリソースを作成し、その後ユーザー B としてそれらにアクセスして権限を確認することを推奨します。単一のユーザーでテストすると、所有者権限ポリシーにより、権限設定が有効でないと誤って結論付けてしまう可能性があります。
-
Ranger Admin の設定が誤っている場合、SQL ステートメントが権限エラーを返さずに成功することがあります。これは、権限付与が適用されていないことを意味します。