サードパーティの Python ライブラリは、ノートブックで実行されるインタラクティブな PySpark ジョブのデータ処理および分析機能を強化するためによく使用されます。このトピックでは、ノートブックにサードパーティの Python ライブラリをインストールする方法について説明します。
背景情報
対話型の PySpark ジョブを開発する際、サードパーティの Python ライブラリを使用することで、より柔軟で簡単なデータ処理と分析が可能になります。次の表は、ノートブックでサードパーティの Python ライブラリを使用する方法を説明しています。必要に応じて方法を選択できます。
方法 | シナリオ |
Spark によって計算された戻り値やカスタム変数など、ノートブック内の Spark に関連しない変数を処理します。 重要 ノートブックセッションを再起動した後、ライブラリを再インストールする必要があります。 | |
サードパーティの Python ライブラリを使用して PySpark ジョブのデータを処理し、ノートブックセッションが開始されるたびにサードパーティのライブラリをプリインストールする場合。 | |
サードパーティの Python ライブラリを使用して PySpark ジョブのデータを処理する場合。たとえば、サードパーティの Python ライブラリを使用して Spark 分散コンピューティングを実装します。 |
前提条件
ワークスペースが作成されていること。詳細については、「ワークスペースの作成」をご参照ください。
ノートブックセッションが作成されていること。詳細については、「ノートブックセッションの管理」をご参照ください。
ノートブックが開発されていること。詳細については、「ノートブックの開発」をご参照ください。
手順
方法 1:pip コマンドを実行して Python ライブラリをインストールする
ノートブックの構成タブに移動します。
E-MapReduce(EMR)コンソール にログインします。
左側のナビゲーションウィンドウで、 を選択します。
Spark ページで、目的のワークスペースを見つけ、ワークスペースの名前をクリックします。
[EMR Serverless Spark] ページの左側のナビゲーションウィンドウで、[データ開発] をクリックします。
開発したノートブックをダブルクリックします。
ノートブックの Python セルに、次のコマンドを入力して scikit-learn ライブラリをインストールし、
 アイコンをクリックします。
アイコンをクリックします。pip install scikit-learn新しい Python セルを追加し、セルに次のコマンドを入力して、
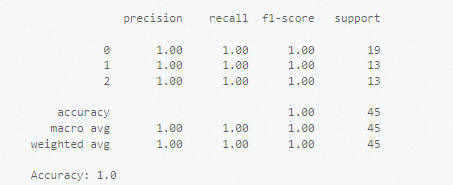
アイコンをクリックします。# scikit-learn ライブラリからデータセットをインポートします。 from sklearn import datasets # Iris データセットなどの組み込みデータセットを読み込みます。 iris = datasets.load_iris() X = iris.data # 特徴データ。 y = iris.tar get # タグ。 # データセットを分割します。 from sklearn.model_selection import train_test_split # データセットをトレーニングセットとテストセットに分割します。 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42) # サポートベクターマシン(SVM)モデルを使用してトレーニングします。 from sklearn.svm import SVC # 分類子インスタンスを作成します。 clf = SVC(kernel='linear') # 線形カーネルを使用します。 # モデルをトレーニングします。 clf.fit(X_train, y_train) # トレーニング済みモデルを使用して予測を行います。 y_pred = clf.predict(X_test) # モデルのパフォーマンスを評価します。 from sklearn.metrics import classification_report, accuracy_score print(classification_report(y_test, y_pred)) print("Accuracy:", accuracy_score(y_test, y_pred))次の図は結果を示しています。
方法 2:ランタイム環境を作成してカスタム Python 環境を定義する
ステップ 1:ランタイム環境を作成する
ランタイム環境ページに移動します。
EMR コンソール にログインします。
左側のナビゲーションウィンドウで、 を選択します。
Spark ページで、目的のワークスペースを見つけ、ワークスペースの名前をクリックします。
[EMR Serverless Spark] ページの左側のナビゲーションウィンドウで、[ランタイム環境] をクリックします。
[ランタイム環境の作成] をクリックします。
[ランタイム環境の作成] ページで、[名前] パラメーターを構成します。次に、[ライブラリ] セクションの [ライブラリの追加] をクリックします。
詳細については、「ランタイム環境の管理」をご参照ください。
[ライブラリの作成] ダイアログボックスで、[ソースの種類] パラメーターを [pypi] に設定し、[PyPI パッケージ] パラメーターを構成して、[OK] をクリックします。
[PyPI パッケージ] フィールドでライブラリ名とバージョンを指定します。バージョンを指定しない場合、最新バージョンのライブラリがインストールされます。例:
scikit-learn。[作成] をクリックします。
[作成] をクリックすると、システムはランタイム環境の初期化を開始します。
ステップ 2:ランタイム環境を使用する
セッションを変更する前に、セッションを停止する必要があります。
ノートブックセッションタブに移動します。
[EMR Serverless Spark] ページの左側のナビゲーションウィンドウで、 を選択します。
[ノートブックセッション] タブをクリックします。
目的のセッションを見つけ、[アクション] 列の [編集] をクリックします。
[ランタイム環境] ドロップダウンリストから作成したランタイム環境を選択し、[変更の保存] をクリックします。
ページの右上隅にある [開始] をクリックします。
ステップ 3:Scikit-learn ライブラリを使用してデータを分類する
目的のノートブックの構成タブに移動します。
[EMR Serverless Spark] ページの左側のナビゲーションウィンドウで、[データ開発] をクリックします。
開発したノートブックをダブルクリックします。
新しい Python セルを追加し、セルに次のコマンドを入力して、
アイコンをクリックします。# scikit-learn ライブラリからデータセットをインポートします。 from sklearn import datasets # Iris データセットなどの組み込みデータセットを読み込みます。 iris = datasets.load_iris() X = iris.data # 特徴データ。 y = iris.tar get # タグ。 # データセットを分割します。 from sklearn.model_selection import train_test_split # データセットをトレーニングセットとテストセットに分割します。 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42) # SVM モデルを使用してトレーニングします。 from sklearn.svm import SVC # 分類子インスタンスを作成します。 clf = SVC(kernel='linear') # 線形カーネルを使用します。 # モデルをトレーニングします。 clf.fit(X_train, y_train) # トレーニング済みモデルを使用して予測を行います。 y_pred = clf.predict(X_test) # モデルのパフォーマンスを評価します。 from sklearn.metrics import classification_report, accuracy_score print(classification_report(y_test, y_pred)) print("Accuracy:", accuracy_score(y_test, y_pred))次の図は結果を示しています。
方法 3:Spark 構成を追加してカスタム Python 環境を作成する
この方法を使用する場合は、ipykernel 6.29 以降がインストールされ、jupyter_client 8.6 以降がインストールされていることを確認してください。Python のバージョンは 3.8 以降である必要があり、環境は Linux (x86 アーキテクチャ) でパッケージ化する必要があります。
ステップ 1:Conda 環境を作成してデプロイする
次のコマンドを実行して、Miniconda をインストールします。
wget https://repo.continuum.io/miniconda/Miniconda3-latest-Linux-x86_64.sh chmod +x Miniconda3-latest-Linux-x86_64.sh ./Miniconda3-latest-Linux-x86_64.sh -b source miniconda3/bin/activatePython 3.8 と NumPy を使用する Conda 環境を作成します。
# Conda 環境を作成し、環境をアクティブ化します。 conda create -y -n pyspark_conda_env python=3.8 conda activate pyspark_conda_env # サードパーティライブラリをインストールします。 pip install numpy \ ipykernel~=6.29 \ jupyter_client~=8.6 \ jieba \ conda-pack # 環境をパッケージ化します。 conda pack -f -o pyspark_conda_env.tar.gz
ステップ 2:リソースファイルを OSS にアップロードする
pyspark_conda_env.tar.gz パッケージを Object Storage Service (OSS) にアップロードし、パッケージの完全な OSS パスをコピーします。詳細については、「簡易アップロード」をご参照ください。
ステップ 3:ノートブックセッションを構成して開始する
セッションを変更する前に、セッションを停止する必要があります。
ノートブックセッションタブに移動します。
[EMR Serverless Spark] ページの左側のナビゲーションウィンドウで、 を選択します。
[ノートブックセッション] タブをクリックします。
目的のセッションを見つけ、[アクション] 列の [編集] をクリックします。
[ノートブックセッションの変更] ページで、[spark 構成] フィールドに次の構成を追加し、[変更の保存] をクリックします。
spark.archives oss://<yourBucket>/path/to/pyspark_conda_env.tar.gz#env spark.pyspark.python ./env/bin/python説明コード内の
<yourBucket>/path/toを、前のステップでコピーした OSS パスに置き換えてください。ページの右上隅にある [開始] をクリックします。
ステップ 4:Jieba ツールを使用してテキストデータを処理する
Jieba は、中国語のテキストセグメンテーション用のサードパーティの Python ライブラリです。ライセンスについては、LICENSE をご参照ください。
目的のノートブックの構成タブに移動します。
[EMR Serverless Spark] ページの左側のナビゲーションウィンドウで、[データ開発] をクリックします。
開発したノートブックをダブルクリックします。
新しい Python セルで、次のコマンドを入力して Jieba ツールを使用して中国語のテキストをセグメント化し、
アイコンをクリックします。import jieba strs = ["EMR Serverless Spark は、大規模データ処理と分析のためのフルマネージドサーバーレスサービスです。", "EMR Serverless Spark は、タスク開発、デバッグ、スケジューリング、O&M などの効率的なエンドツーエンドサービスをサポートしています。", "EMR Serverless Spark は、ジョブの負荷に基づいたリソーススケジューリングと動的スケーリングをサポートしています。"] sc.parallelize(strs).flatMap(lambda s: jieba.cut(s, use_paddle=True)).collect()次の図は結果を示しています。