このトピックでは、Realtime Compute for Apache Flink と EMR Serverless Spark を使用して Paimon データレイク分析パイプラインを構築する方法を説明します。このパイプラインには、OSS へのデータの書き込み、インタラクティブクエリの実行、オフラインデータ Compact 操作の実行が含まれます。EMR Serverless Spark は Paimon と完全に互換性があります。組み込みの DLF メタデータを使用して、Realtime Compute for Apache Flink などの他の Alibaba Cloud サービスと相互運用し、完全な統合ストリームおよびバッチ処理ソリューションを作成します。リアルタイム分析や本番スケジューリングのさまざまなニーズに対応するため、柔軟なジョブ実行メソッドとパラメーター構成をサポートしています。
背景情報
Realtime Compute for Apache Flink
Alibaba Cloud Realtime Compute for Apache Flink は、フルマネージド型のサーバーレス Flink クラウドサービスです。開発、運用保守 (O&M)、および管理のためのワンストップですぐに使えるプラットフォームであり、柔軟な課金を提供します。ジョブ開発、データデバッグ、実行とモニタリング、自動チューニング、インテリジェント診断など、完全なライフサイクル機能を提供します。詳細については、「Alibaba Cloud Realtime Compute for Apache Flink とは」をご参照ください。
Apache Paimon
Apache Paimon は、統合データレイクストレージフォーマットです。Flink と Spark を組み合わせて、ストリームおよびバッチ処理のためのリアルタイムデータレイクハウスアーキテクチャを構築します。Paimon は、レイクフォーマットと Log-structured merge-tree (LSM) 技術を革新的に組み合わせています。これにより、データレイクにリアルタイムのストリーム更新機能と完全なストリーム処理能力が提供されます。詳細については、「Apache Paimon」をご参照ください。
手順
ステップ 1: Realtime Compute for Apache Flink を使用して Paimon Catalog を作成する
Paimon Catalog を使用すると、同じウェアハウスディレクトリ内のすべての Paimon テーブルを簡単に管理し、他の Alibaba Cloud サービスと接続できます。Paimon Catalog の作成と使用については、「Paimon Catalog の管理」をご参照ください。
ターゲットワークスペースの [アクション] 列にある [コンソール] をクリックします。
Paimon Catalog を作成します。
左側のナビゲーションウィンドウで、 を選択します。
クエリスクリプトを作成し、SQL コードを入力します。
次のコードは、完全な Catalog 構成を提供します。
CREATE CATALOG `paimon` WITH ( 'type' = 'paimon', 'metastore' = 'dlf', 'warehouse' = '<warehouse>', 'dlf.catalog.id' = '<dlf.catalog.id>', 'dlf.catalog.accessKeyId' = '<dlf.catalog.accessKeyId>', 'dlf.catalog.accessKeySecret' = '<dlf.catalog.accessKeySecret>', 'dlf.catalog.endpoint' = '<dlf.catalog.endpoint>', 'dlf.catalog.region' = '<dlf.catalog.region>', );構成項目
説明
必須
注意
paimon
Paimon Catalog の名前。
はい
英語でカスタム名を入力します。
type
Catalog のタイプ。
はい
値を paimon に設定します。
metastore
メタストアのタイプ。
はい
この例では、メタストアのタイプは dlf に設定されています。DLF は、複数のエンジン間でシームレスな統合を確保するために、統合メタデータ管理に使用されます。
warehouse
データウェアハウスの実際の場所。
はい
必要に応じてこの値を変更します。
dlf.catalog.id
DLF データカタログの ID。
はい
Data Lake Formation コンソールでデータカタログ ID を表示します。
dlf.catalog.accessKeyId
DLF サービスへのアクセスに必要な AccessKey ID。
はい
AccessKey ID の取得方法の詳細については、「AccessKey の作成」をご参照ください。
dlf.catalog.accessKeySecret
DLF サービスへのアクセスに必要な AccessKey Secret。
はい
AccessKey Secret の取得方法の詳細については、「AccessKey の作成」をご参照ください。
dlf.catalog.endpoint
DLF サービスのエンドポイント。
はい
詳細については、「リージョンとエンドポイント」をご参照ください。
説明Flink と DLF が同じリージョンにある場合は、VPC エンドポイントを使用します。それ以外の場合は、パブリックエンドポイントを使用します。
dlf.catalog.region
DLF が配置されているリージョン。
はい
詳細については、「リージョンとエンドポイント」をご参照ください。
説明このリージョンが dlf.catalog.endpoint に選択したものと同じであることを確認してください。
セッションクラスターを選択または作成します。
ページの右下隅で、[実行環境] をクリックし、必要なバージョンのセッションクラスターを選択します。エンジンバージョンは Ververica Runtime (VVR) 8.0.4 以降である必要があります。セッションクラスターがない場合、詳細については、「ステップ 1: セッションクラスターの作成」をご参照ください。
ターゲットコードスニペットを選択し、コード行の左側にある [実行] をクリックします。
Paimon テーブルを作成します。
[クエリスクリプト] エディターで、次のコマンドを入力します。次に、コードを選択して [実行] をクリックします。
CREATE TABLE IF NOT EXISTS `paimon`.`test_paimon_db`.`test_append_tbl` ( id STRING, data STRING, category INT, ts STRING, dt STRING, hh STRING ) PARTITIONED BY (dt, hh) WITH ( 'write-only' = 'true' );ストリームジョブを作成します。
ジョブを作成します。
左側のナビゲーションウィンドウで、 を選択します。
ストリームジョブを作成します。[ジョブドラフトの作成] ダイアログボックスで、ジョブパラメーターを構成します。
ジョブパラメーター
説明
ファイル名
ジョブの名前。
説明ジョブ名は現在のプロジェクト内で一意である必要があります。
エンジンバージョン
現在のジョブで使用される Flink エンジンバージョン。エンジンバージョン番号、バージョンマッピング、および重要なライフサイクル日付の詳細については、「エンジンバージョン」をご参照ください。
[作成] をクリックします。
コードを記述します。
新しいジョブドラフトで、次のコードを入力して datagen コネクタを使用し、Paimon テーブルにデータを継続的に生成して書き込みます。
CREATE TEMPORARY TABLE datagen ( id string, data string, category int ) WITH ( 'connector' = 'datagen', 'rows-per-second' = '100', 'fields.category.kind' = 'random', 'fields.category.min' = '1', 'fields.category.max' = '10' ); INSERT INTO `paimon`.`test_paimon_db`.`test_append_tbl` SELECT id, data, category, cast(LOCALTIMESTAMP as string) as ts, cast(CURRENT_DATE as string) as dt, cast(hour(LOCALTIMESTAMP) as string) as hh FROM datagen;[デプロイ] をクリックして、データを本番環境に公開します。
[ジョブ O&M] ページでジョブを開始します。詳細については、「ジョブの開始」をご参照ください。
ステップ 2: EMR Serverless Spark を使用して SQL セッションを作成する
SQL 開発およびクエリ用の SQL セッションを作成します。セッションの詳細については、「セッションマネージャー」をご参照ください。
セッションページに移動します。
EMR コンソールにログインします。
左側のナビゲーションウィンドウで、 を選択します。
[Spark] ページで、管理するワークスペースの名前をクリックします。
[EMR Serverless Spark] ページの左側のナビゲーションウィンドウで、[オペレーションセンター] > [セッション] を選択します。
SQL セッションを作成します。
[SQL セッション] タブで、[SQL セッションの作成] をクリックします。
[SQL セッションの作成] ページで、次のパラメーターを構成し、他のパラメーターはデフォルト設定のままにして、[作成] をクリックします。
パラメーター
説明
名前
SQL セッションのカスタム名。例: paimon_compute。
Spark 構成
Paimon に接続するには、次の Spark 構成を入力します。
spark.sql.extensions org.apache.paimon.spark.extensions.PaimonSparkSessionExtensions spark.sql.catalog.paimon org.apache.paimon.spark.SparkCatalog spark.sql.catalog.paimon.metastore dlf spark.sql.catalog.paimon.warehouse <warehouse> spark.sql.catalog.paimon.dlf.catalog.id <dlf.catalog.id>必要に応じて、次の情報を置き換えます:
<warehouse>: データウェアハウスの実際の場所。必要に応じてこの値を変更します。<dlf.catalog.id>: DLF データカタログの ID。必要に応じてこの値を変更します。
[アクション] 列で、[開始] をクリックします。
ステップ 3: EMR Serverless Spark を使用してインタラクティブクエリを実行するか、タスクをスケジュールする
EMR Serverless Spark は、インタラクティブクエリとタスクスケジューリングという 2 つの操作モードを提供して、さまざまなニーズに対応します。インタラクティブクエリモードは、迅速なクエリとデバッグに適しています。タスクスケジューリングモードは、完全なライフサイクル管理のためのタスクの開発、公開、および O&M をサポートします。
データ書き込みプロセス中に、EMR Serverless Spark を使用していつでも Paimon テーブルに対してインタラクティブクエリを実行できます。これにより、リアルタイムのデータステータスを取得し、迅速な分析を実行できます。さらに、開発したジョブを公開し、ワークフローを作成してタスクをオーケストレーションおよび公開できます。スケジューリングポリシーを構成してタスクを定期的に実行することで、自動化された効率的なデータ処理と分析が保証されます。
インタラクティブクエリ
SQL 開発ジョブを作成します。
[EMR Serverless Spark] ページで、左側のナビゲーションウィンドウにある [データ開発] をクリックします。
[開発フォルダー] タブで、[作成] をクリックします。
表示されるダイアログボックスで、[名前] (paimon_compact など) を入力します。[タイプ] を [SparkSQL] に設定し、[OK] をクリックします。
右上隅で、データカタログ、データベース、および前のステップで開始した SQL セッションを選択します。
新しいジョブエディターで、SQL 文を入力します。
例 1:
test_append_tblテーブルの最初の 10 行のデータをクエリします。SELECT * FROM paimon.test_paimon_db.test_append_tbl limit 10;次の図は、サンプル結果を示しています。
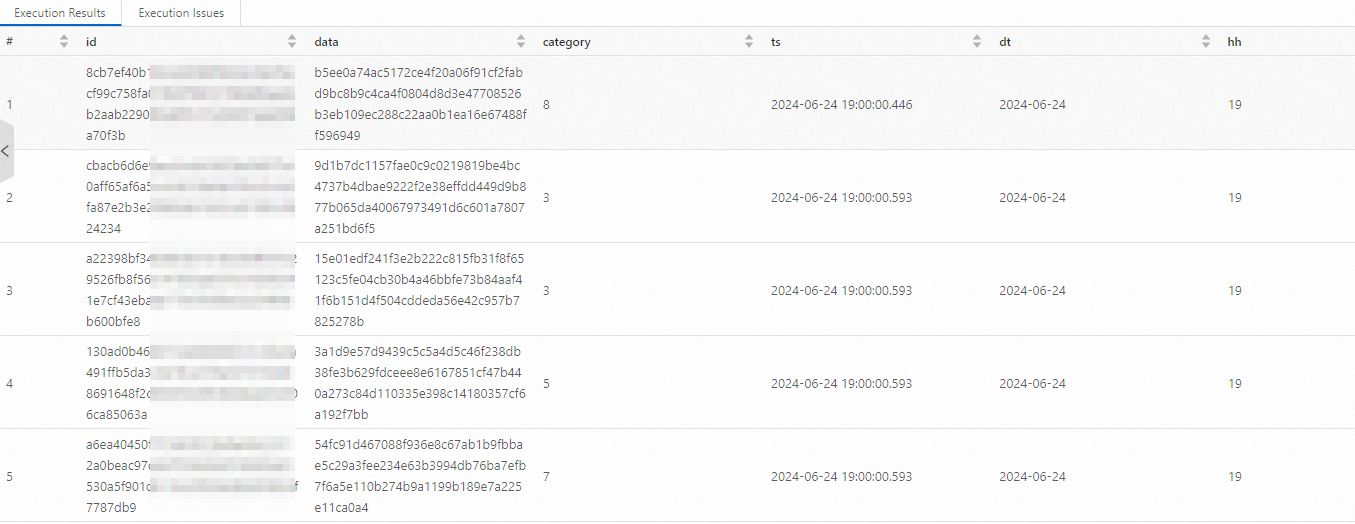
例 2:
test_append_tblテーブルで特定の条件を満たす行の数をカウントします。SELECT COUNT(*) FROM paimon.test_paimon_db.test_append_tbl WHERE dt = '2024-06-24' AND hh = '19';次の図は、サンプル結果を示しています。
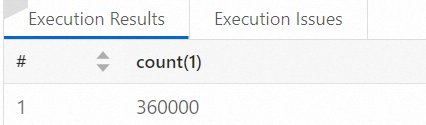
ジョブを実行して公開します。
[実行] をクリックします。
結果は下の [実行結果] タブで表示できます。エラーが発生した場合は、[実行に関する問題] タブで詳細を表示できます。
ジョブが正しく実行されることを確認したら、右上隅の [公開] をクリックします。
[公開] ダイアログボックスで、リリースの説明を入力し、[OK] をクリックします。
タスクスケジューリング
Compact 操作の前にファイル情報をクエリします。
[データ開発] ページで、SQL 開発ジョブを作成して Paimon ファイルシステムテーブルをクエリします。これにより、Compact 操作の前にファイルに関するデータをすばやく取得できます。SQL 開発ジョブの作成方法の詳細については、「SparkSQL 開発」をご参照ください。
SELECT file_path, record_count, file_size_in_bytes FROM paimon.test_paimon_db.test_append_tbl$files WHERE partition='[2024-06-24, 19]';
[データ開発] ページで、Paimon Compact SQL (paimon_compact など) を記述し、公開します。
SQL 開発ジョブの作成方法の詳細については、「SparkSQL 開発」をご参照ください。
CALL paimon.sys.compact ( table => 'test_paimon_db.test_append_tbl', partitions => 'dt=\"2024-06-24\",hh=\"19\"', order_strategy => 'zorder', order_by => 'category' );ワークフローを作成します。
[EMR Serverless Spark] ページで、左側のナビゲーションウィンドウにある [タスクオーケストレーション] をクリックします。
[タスクオーケストレーション] ページで、[ワークフローの作成] をクリックします。
[ワークフローの作成] パネルで、[ワークフロー名] (paimon_workflow_task など) を入力し、[次へ] をクリックします。
[その他の設定] セクションのパラメーターを必要に応じて構成します。パラメーターの詳細については、「ワークフローの管理」をご参照ください。
新しいノードキャンバスで、[ノードの追加] をクリックします。
[ソースファイルパス] ドロップダウンリストから、公開された SQL 開発ジョブ (paimon_compact) を選択します。[Spark 構成] を入力し、[保存] をクリックします。
パラメーター
説明
名前
SQL セッションのカスタム名。例: paimon_compute。
Spark 構成
Paimon に接続するには、次の Spark 構成を入力します。
spark.sql.extensions org.apache.paimon.spark.extensions.PaimonSparkSessionExtensions spark.sql.catalog.paimon org.apache.paimon.spark.SparkCatalog spark.sql.catalog.paimon.metastore dlf spark.sql.catalog.paimon.warehouse <warehouse> spark.sql.catalog.paimon.dlf.catalog.id <dlf.catalog.id>必要に応じて、次の情報を置き換えます:
<warehouse>: データウェアハウスの実際の場所。必要に応じてこの値を変更します。<dlf.catalog.id>: DLF データカタログの ID。必要に応じてこの値を変更します。
新しいノードキャンバスで、[ワークフローの公開] をクリックし、次に [OK] をクリックします。
ワークフローを実行します。
[タスクオーケストレーション] ページで、新しいワークフローの [ワークフロー名] (paimon_workflow_task など) をクリックします。
[ワークフローインスタンスリスト] ページで、[手動で実行] をクリックします。
[実行のトリガー] ダイアログボックスで、[OK] をクリックします。
Compact 操作の結果を検証します。
ワークフローが正常にスケジュールおよび実行された後、同じ SQL クエリを再度実行します。Compact 操作の前後のファイル数、レコード数、およびファイルサイズを比較して、操作の結果を検証します。
SELECT file_path, record_count, file_size_in_bytes FROM paimon.test_paimon_db.test_append_tbl$files WHERE partition='[2024-06-24, 19]';