このトピックでは、EMR Serverless Spark に関するよくある質問 (FAQ) に回答します。
EMR Serverless Spark に関するよくある質問を、互換性のエリアごとに以下にまとめます。
質問
DLF の互換性
DLF データの読み取り時に java.net.UnknownHostException エラーが発生した場合はどうすればよいですか?
このエラーは、[開発環境] で SQL クエリを実行して Data Lake Formation (DLF) 1.0 のデータテーブルからデータを読み取る際に、EMR Serverless Spark がテーブルの location パス内のホストを解決できない場合に発生します。修正方法は、Hadoop 分散ファイルシステム (HDFS) クラスターが高可用性 (HA) を使用しているかどうかによって異なります。
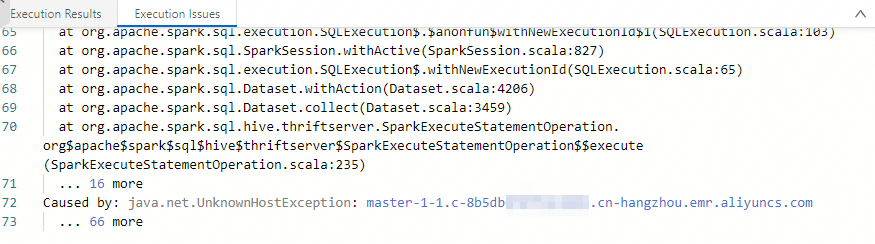
HA を使用しない HDFS
テーブルの location に記載されたドメイン名がアクセス可能であることを確認してください。デフォルトでは、master-1-1.<cluster-id>.<region>.emr.aliyuncs.com が直接アクセス可能です。その他のドメイン名については、必要なマッピングを追加してください。詳細については、「ドメイン名の管理」をご参照ください。
HA を使用する HDFS
ドメイン名のマッピングを設定します。「ドメイン名の管理」を参照してください。
ファイルを作成します。ファイル名は
hdfs-site.xmlで、場所は/etc/spark/confです。内容は、ECS 上の EMR クラスターから取得したhdfs-site.xmlを基にします。ファイルのアップロード方法については、「カスタム構成の管理」をご参照ください。以下はhdfs-site.xmlのサンプルです。NameNode アドレスおよびポート番号を、お客様のクラスターの値に置き換えてください。<?xml version="1.0"?> <configuration> <property> <name>dfs.nameservices</name> <value>hdfs-cluster</value> </property> <property> <name>dfs.ha.namenodes.hdfs-cluster</name> <value>nn1,nn2,nn3</value> </property> <property> <name>dfs.namenode.rpc-address.hdfs-cluster.nn1</name> <value>master-1-1.<cluster-id>.<region-id>.emr.aliyuncs.com:<port></value> </property> <property> <name>dfs.namenode.rpc-address.hdfs-cluster.nn2</name> <value>master-1-2.<cluster-id>.<region-id>.emr.aliyuncs.com:<port></value> </property> <property> <name>dfs.namenode.rpc-address.hdfs-cluster.nn3</name> <value>master-1-3.<cluster-id>.<region-id>.emr.aliyuncs.com:<port></value> </property> <property> <name>dfs.client.failover.proxy.provider.hdfs-cluster</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> </configuration>ファイルが配置されると、Java ランタイムまたは Fusion ランタイムが HA クラスターを解決し、データにアクセスできるようになります。
OSS の互換性
アカウント間で OSS リソースにアクセスするにはどうすればよいですか?
2 つのメソッドが利用可能です。アクセスを共有する必要がある範囲に応じて選択してください:
| メソッド | スコープ | 使用する状況 |
|---|---|---|
| ワークスペースレベル | ワークスペース内のすべてのジョブ | ワークスペースが同じバケットへのアクセスを必要とする多くのジョブを実行し、単一の永続的な構成が必要な場合。 |
| タスクおよびセッションレベル | 特定のタスクまたはセッション | アクセスが一時的またはタスク固有である場合、またはワークスペース構成を変更する権限がない場合。 |
ワークスペースレベル
ターゲットの Object Storage Service (OSS) バケットのバケットポリシーを構成して、ワークスペースの実行ロールに読み取りおよび書き込みアクセスを許可します。
OSS コンソールにログインします。左側のナビゲーションウィンドウで [バケット] をクリックし、ターゲットのバケットをクリックします。
左側のナビゲーションウィンドウで、[権限管理] > [バケットポリシー] を選択します。
[バケットポリシー] ページで、[GUI で追加] タブをクリックし、[承認] をクリックします。
[承認] パネルで、以下のパラメーターを設定し、[OK] をクリックします。他のすべてのパラメーターについては、「GUI を使用してバケットポリシーを構成する」をご参照ください。
パラメーター 値 適用対象 バケット全体 承認されたユーザー [他のアカウント] を選択します。[プリンシパル] を arn:sts::<uid>:assumed-role/<role-name>/*に設定します。<uid>を Alibaba Cloud アカウント ID に、<role-name>を実行ロール名 (大文字と小文字を区別) に置き換えます。デフォルトのロールは AliyunEMRSparkJobRunDefaultRole です。実行ロールを見つけるには、ワークスペースリストページに移動し、[操作] 列の [詳細] をクリックします。
タスクおよびセッションレベル
タスクまたはセッションを作成する際に、[Spark 構成] セクションに以下のプロパティを追加します。プレースホルダーをご利用のバケットの詳細に置き換えてください。
spark.hadoop.fs.oss.bucket.<bucketName>.endpoint <endpoint>
spark.hadoop.fs.oss.bucket.<bucketName>.credentials.provider com.aliyun.jindodata.oss.auth.SimpleCredentialsProvider
spark.hadoop.fs.oss.bucket.<bucketName>.accessKeyId <accessID>
spark.hadoop.fs.oss.bucket.<bucketName>.accessKeySecret <accessKey>| プレースホルダー | 説明 |
|---|---|
<bucketName> | OSS バケットの名前 |
<endpoint> | OSS エンドポイント |
<accessID> | OSS データへのアクセスに使用される Alibaba Cloud アカウントの AccessKey ID |
<accessKey> | OSS データへのアクセスに使用される Alibaba Cloud アカウントの AccessKey Secret |
S3 の互換性
S3 にアクセスするにはどうすればよいですか?
タスクまたはセッションを作成する際に、[Spark 構成] セクションに以下のプロパティを追加します。プレースホルダーをご利用のバケットの詳細に置き換えてください。
spark.hadoop.fs.s3.impl com.aliyun.jindodata.s3.JindoS3FileSystem
spark.hadoop.fs.AbstractFileSystem.s3.impl com.aliyun.jindodata.s3.S3
spark.hadoop.fs.s3.bucket.<bucketName>.accessKeyId <accessID>
spark.hadoop.fs.s3.bucket.<bucketName>.accessKeySecret <accessKey>
spark.hadoop.fs.s3.bucket.<bucketName>.endpoint <endpoint>
spark.hadoop.fs.s3.credentials.provider com.aliyun.jindodata.s3.auth.SimpleCredentialsProvider| プレースホルダー | 説明 |
|---|---|
<bucketName> | S3 バケットの名前 |
<endpoint> | S3 エンドポイント |
<accessID> | S3 へのアクセスに使用されるアカウントの AccessKey ID |
<accessKey> | S3 へのアクセスに使用されるアカウントの AccessKey Secret |
OBS の互換性
OBS にアクセスするにはどうすればよいですか?
タスクまたはセッションを作成する際に、[Spark 構成] セクションに以下のプロパティを追加します。プレースホルダーをご利用のバケットの詳細に置き換えてください。
spark.hadoop.fs.obs.impl com.aliyun.jindodata.obs.JindoObsFileSystem
spark.hadoop.fs.AbstractFileSystem.obs.impl com.aliyun.jindodata.obs.OBS
spark.hadoop.fs.obs.bucket.<bucketName>.accessKeyId <accessID>
spark.hadoop.fs.obs.bucket.<bucketName>.accessKeySecret <accessKey>
spark.hadoop.fs.obs.bucket.<bucketName>.endpoint <endpoint>
spark.hadoop.fs.obs.credentials.provider com.aliyun.jindodata.obs.auth.SimpleCredentialsProvider| プレースホルダー | 説明 |
|---|---|
<bucketName> | OBS バケットの名前 |
<endpoint> | OBS エンドポイント |
<accessID> | OBS へのアクセスに使用されるアカウントの AccessKey ID |
<accessKey> | OBS へのアクセスに使用されるアカウントの AccessKey Secret |