Spark は、次のいずれかの方法を使用して JindoFileSystem(JindoFS)のデータを処理します。メソッドを呼び出す、Spark SQL を使用して JindoFS に格納されているテーブルからデータを読み取る。
JindoFS の構成
たとえば、emr-jfs という名前のネームスペースは、次の構成で作成されます。
- jfs.namespaces=emr-jfs
- jfs.namespaces.emr-jfs.oss.uri=oss://oss-bucket/oss-dir
- jfs.namespaces.emr-jfs.mode=block
JindoFS でのデータ処理
- メソッドの呼び出し
JindoFS で Spark によって実行される読み取りおよび書き込み操作は、他のファイルシステムでの操作と似ています。たとえば、JindoFS のデータにアクセスするには、次の Resilient Distributed Dataset(RDD)操作で jfs プレフィックスが付いたディレクトリを使用します。
val a = sc.textFile("jfs://emr-jfs/README.md")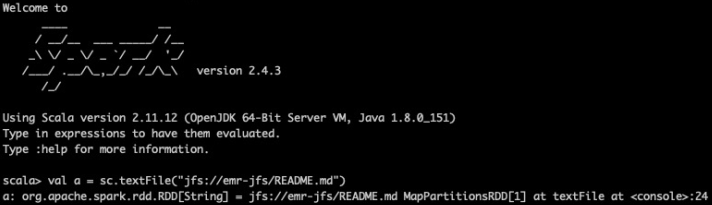
JindoFS にデータを書き込むには、次のメソッドを呼び出します。
scala> a.collect().saveAsTextFile("jfs://emr-jfs/output") - Spark SQL の使用
データベース、テーブル、またはパーティションを作成するときに、ストレージの場所を JindoFS のディレクトリに設定するパラメーターを構成します。詳細については、「Hive を使用して JindoFS のデータをクエリする」をご参照ください。その後、JindoFS に格納されているテーブルからデータをクエリできます。