このトピックでは、特定のシナリオでJindo DistCpを使用する方法について説明します。
前提条件
- 必要なバージョンのE-MapReduce(EMR)クラスターが作成されていること。詳細については、クラスターの作成をご参照ください。
- Java Development Kit(JDK) 1.8がインストールされていること。
- jindo-distcp-<version>.jar がHadoopバージョンに基づいてダウンロードされていること。
- Hadoop 2.7以降の2.Xバージョンには、jindo-distcp-3.0.0.jar をダウンロードします。
- Hadoop 3.Xには、jindo-distcp-3.0.0.jar をダウンロードします。
ユースケース
Jindo DistCpの一般的なユースケース:
- シナリオ 1:大量のHDFSデータまたは多数のファイル(数百万または数千万)をOSSにインポートする場合、最適化に必要なパラメーターは何ですか?
- シナリオ 2:Jindo DistCpを使用してデータをOSSにインポートした後、データの整合性をどのように検証しますか?
- シナリオ 3:HDFSデータをOSSにインポートするときに、DistCpタスクの失敗時に再開可能なアップロードをサポートするために必要なパラメーターは何ですか?
- シナリオ 4:Jindo DistCpを使用してHDFSデータをOSSにインポートするときに、新しく生成される可能性のあるファイルを処理するために必要なパラメーターは何ですか?
- シナリオ 5:Jindo DistCpタスクが存在するYARNキューと、タスクに割り当てられる使用可能な帯域幅を指定するために必要なパラメーターは何ですか?
- シナリオ 5:Jindo DistCpタスクが存在するYARNキューと、タスクに割り当てられる使用可能な帯域幅を指定するために必要なパラメーターは何ですか?
- シナリオ 6:OSS IAまたはアーカイブストレージにデータを書き込むときに必要なパラメーターは何ですか?
- シナリオ 7:小さなファイルの割合と特定のファイルサイズに基づいてファイル転送を高速化するために必要なパラメーターは何ですか?
- シナリオ 8:Amazon S3をデータソースとして使用する場合、必要なパラメーターは何ですか?
- シナリオ 9:ファイルをOSSにコピーし、コピーしたファイルをLZOまたはGZ形式で圧縮する場合、必要なパラメーターは何ですか?
- シナリオ 10:特定のルールに一致するファイル、または同じ親ディレクトリのいくつかのサブディレクトリにあるファイルをコピーする場合、必要なパラメーターは何ですか?
- シナリオ 11:ファイル数を減らすために、特定のルールに一致するファイルをマージする場合、必要なパラメーターは何ですか?
- シナリオ 12:コピー操作後に元のファイルを削除する場合、必要なパラメーターは何ですか?
- シナリオ 13:CLIでOSSのAccessKeyペアとエンドポイント情報を指定したくない場合はどうすればよいですか?
シナリオ 1:大量のHDFSデータまたは多数のファイル(数百万または数千万)をOSSにインポートする場合、最適化に必要なパラメーターは何ですか?
EMRを使用していない場合、HDFSデータをオブジェクトストレージサービス(OSS)にインポートするには、次の条件を満たす必要があります。
- HDFSからデータを読み取ることができる。
- OSSのAccessKey ID、AccessKeyシークレット、およびエンドポイントを取得している。宛先OSSバケットにデータを書き込むことができる。
- OSSバケットのストレージクラスがアーカイブではない。
- MapReduceタスクを送信できる。
- Jindo DistCpのJARパッケージがダウンロードされている。
例:
hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://yang-hhht/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --parallelism 10説明 パラメーターの詳細については、Jindo DistCpの使用をご参照ください。
数百万または数千万のファイルなど、大量のデータまたは多数のファイルをOSSにインポートするには、並列処理(parallelism)を大きな値に設定して同時実行性を高めることができます。また、最適化のために
enableBatch をtrueに設定することもできます。最適化コマンド:hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://yang-hhht/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --parallelism 500 --enableBatchシナリオ 2:Jindo DistCpを使用してデータをOSSにインポートした後、データの整合性をどのように検証しますか?
次のいずれかの方法を使用して、データの整合性を検証できます。
- Jindo DistCpカウンターMapReduceタスクのカウンター情報でDistCpカウンターを確認します。
Distcp Counters Bytes Destination Copied=11010048000 Bytes Source Read=11010048000 Files Copied=1001 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0ここで:- Bytes Destination Copiedは、宛先ディレクトリにコピーするファイルのサイズをバイト単位で指定します。
- Bytes Source Readは、ソースディレクトリから読み取るファイルのサイズをバイト単位で指定します。
- Files Copiedは、コピーされたファイルの数を指定します。
- Jindo DistCp --diff
--diffを使用して、ソースディレクトリと宛先ディレクトリにあるファイルの情報を比較します。情報には、ファイル名とファイルサイズが含まれます。見つからないファイルとコピーに失敗したファイルは、マニフェストファイルに記録されます。マニフェストファイルは、比較を実行するディレクトリに生成されます。シナリオ 1で説明されているコマンドに--diffを追加します。例:シナリオ 1hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://yang-hhht/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --diffすべてのファイルがコピーされると、次の情報が返されます:INFO distcp.JindoDistCp: distcp has been done completely
シナリオ 3:HDFSデータをOSSにインポートするときに、DistCpタスクの失敗時に再開可能なアップロードをサポートするために必要なパラメーターは何ですか?
DistCpタスクが失敗し、コピーに失敗したファイルのみをコピーするために再開可能なアップロードを実行する場合は、シナリオ 1で説明されているコマンドに基づいて、次の操作を実行します。
--diffを追加して、すべてのファイルがコピーされたかどうかを確認します。hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://yang-hhht/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --diffすべてのファイルがコピーされると、次の情報が返されます。そうでない場合は、マニフェストファイルが生成されます。この場合は、次の手順に進みます。INFO distcp.JindoDistCp: distcp has been done completely.--copyFromManifestと--previousManifestを使用して、残りのファイルをコピーします。例:hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://yang-hhht/hourly_table --dest oss://yang-hhht/hourly_table --previousManifest=file:///opt/manifest-2020-04-17.gz --copyFromManifest --parallelism 20file:///opt/manifest-2020-04-17.gzは、マニフェストファイルが格納されているパスです。
シナリオ 4:Jindo DistCpを使用してHDFSデータをOSSにインポートするときに、新しく生成される可能性のあるファイルを処理するために必要なパラメーターは何ですか?
- 前回コピーされたファイルの情報が生成されていない場合は、コピーされるファイルに関する情報を記録するマニフェストファイルを生成するパラメーターを指定します。シナリオ 1で説明されているコマンドに
--outputManifest=manifest-2020-04-17.gzと--requirePreviousManifest=falseを追加します。例:シナリオ 1hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://yang-hhht/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --outputManifest=manifest-2020-04-17.gz --requirePreviousManifest=false --parallelism 20ここで:--outputManifestは、名前をカスタマイズできるマニフェストファイルを生成します。ファイル名の拡張子はgzである必要があります(例:manifest-2020-04-17.gz)。このファイルは、--destで指定されたディレクトリに格納されます。--requirePreviousManifestは、以前のマニフェストファイルが必要かどうかを指定します。
- DistCpタスクが完了したら、ソースディレクトリに新しく生成される可能性のあるファイルをコピーします。シナリオ 1で説明されているコマンドに
--outputManifest=manifest-2020-04-17.gzと--previousManifest=oss://yang-hhht/hourly_table/manifest-2020-04-17.gzを追加します。例:シナリオ 1hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://yang-hhht/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --outputManifest=manifest-2020-04-17.gz --requirePreviousManifest=false --parallelism 20hadoop jar jindo-distcp-2.7.3.jar --src /data/incoming/hourly_table --dest oss://yang-hhht/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --outputManifest=manifest-2020-04-18.gz --previousManifest=oss://yang-hhht/hourly_table/manifest-2020-04-17.gz --parallelism 10 - 手順 2を繰り返して、増分ファイルを継続的にコピーします。
シナリオ 5:Jindo DistCpタスクが存在するYARNキューと、タスクに割り当てられる使用可能な帯域幅を指定するために必要なパラメーターは何ですか?
シナリオ 1で説明されているコマンドに、次の2つのパラメーターを追加します。これらの2つのパラメーターは、一緒に使用することも、個別に使用することもできます。
--queue:YARNキューの名前。--bandwidth:指定された帯域幅のサイズ(MB)。
例:
hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://yang-hhht/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --queue yarnqueue --bandwidth 6 --parallelism 10シナリオ 6:OSS IAまたはアーカイブストレージにデータを書き込むときに必要なパラメーターは何ですか?
- OSSアーカイブストレージにデータを書き込むには、シナリオ 1で説明されているコマンドに
--archiveを追加します。例:hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://yang-hhht/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --archive --parallelism 20 - OSS低頻度アクセス(IA)ストレージにデータを書き込むには、シナリオ 1で説明されているコマンドに
--iaを追加します。例:hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://yang-hhht/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --ia --parallelism 20
シナリオ 7:小さなファイルの割合と特定のファイルサイズに基づいてファイル転送を高速化するために必要なパラメーターは何ですか?
- 多数の小さなファイルと、単一の大きなファイルの大きなデータ量
コピーするファイルのほとんどが小さなファイルで、単一の大きなファイルのデータ量が大きい場合、一般的な解決策は、コピーするファイルをランダムに割り当てることです。この場合、ジョブ割り当てプランを最適化しないと、少数の大きなファイルと多数の小さなファイルが同じコピープロセスに割り当てられる可能性があります。これでは、優れたコピーパーフォーマンスを実現できません。
シナリオ 1で説明されているコマンドに--enableDynamicPlanを追加して、最適化を有効にします。 --enableDynamicPlanは、シナリオ 1--enableBalancePlanと一緒に使用することはできません。例:hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://yang-hhht/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --enableDynamicPlan --parallelism 10次の図は、プランを最適化する前後のデータコピーを示しています。
- ファイルサイズの大きな違いがないコピーするファイル間でサイズに大きな違いがない場合は、
--enableBalancePlanを使用してジョブ割り当てプランを最適化します。例:hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://yang-hhht/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --enableBalancePlan --parallelism 10次の図は、プランを最適化する前後のデータコピーを示しています。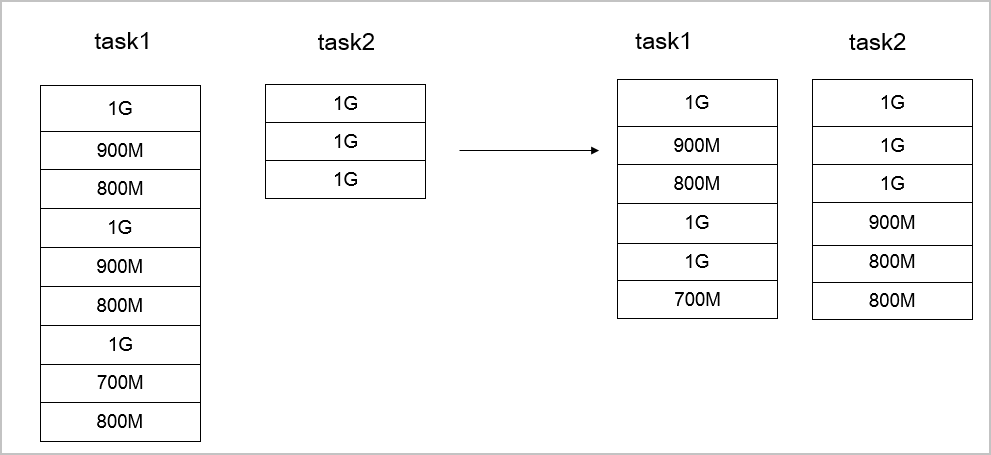
シナリオ 8:Amazon S3をデータソースとして使用する場合、必要なパラメーターは何ですか?
シナリオ 1で説明されているコマンドのOSSのAccessKey ID、AccessKeyシークレット、およびエンドポイントを指定するパラメーターを、次のAmazon S3のパラメーターに置き換えます。
--s3Key:Amazon S3のAccessKey ID--s3Secret:Amazon S3のAccessKeyシークレット--s3EndPoint:Amazon S3のエンドポイント
例:
hadoop jar jindo-distcp-<version>.jar --src s3a://yourbucket/ --dest oss://yang-hhht/hourly_table --s3Key yourkey --s3Secret yoursecret --s3EndPoint s3-us-west-1.amazonaws.com --parallelism 10シナリオ 9:ファイルをOSSにコピーし、コピーしたファイルをLZOまたはGZ形式で圧縮する場合、必要なパラメーターは何ですか?
--outputCodec を使用して、コピーしたファイルをLZOやGZなどの形式で圧縮し、ファイルの格納に使用されるスペースを削減できます。
シナリオ 1で説明されているコマンドに
--outputCodec を追加します。例:シナリオ 1hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://yang-hhht/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --outputCodec=gz --parallelism 10--outputCodecは、gzip、gz、lzo、lzop、snappy、none、またはkeepに設定できます。デフォルト値:keep。 noneとkeepの説明:
- none:Jindo DistCpは、コピーされたファイルを圧縮しません。ファイルが圧縮されている場合、Jindo DistCpはファイルを解凍します。
- keep:Jindo DistCpは、圧縮を変更せずにファイルをコピーします。
説明 オープンソースのHadoopクラスターでLZOコーデックを使用する場合は、gplcompressionのネイティブライブラリとhadoop-lzoパッケージをインストールする必要があります。
シナリオ 10:特定のルールに一致するファイル、または同じ親ディレクトリのいくつかのサブディレクトリにあるファイルをコピーする場合、必要なパラメーターは何ですか?
- 特定のルールに一致するファイルをコピーする場合は、シナリオ 1で説明されているコマンドに
--srcPatternを追加します。例:シナリオ 1hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://yang-hhht/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --srcPattern .*\.log --parallelism 10--srcPattern:コピープロセス用にファイルをフィルタリングする正規表現を指定します。 - 同じ親ディレクトリのいくつかのサブディレクトリに格納されているファイルをコピーする場合は、シナリオ 1で説明されているコマンドに
--srcPrefixesFileを追加します。シナリオ 1hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://yang-hhht/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --srcPrefixesFile file:///opt/folders.txt --parallelism 20--srcPrefixesFile:Jindo DistCpが同じ親ディレクトリにある複数のフォルダー内のファイルを一度にコピーできるようにします。folders.txt ファイルの内容:hdfs://emr-header-1.cluster-50466:9000/data/incoming/hourly_table/2017-02-01 hdfs://emr-header-1.cluster-50466:9000/data/incoming/hourly_table/2017-02-02
シナリオ 11:ファイル数を減らすために、特定のルールに一致するファイルをマージする場合、必要なパラメーターは何ですか?
シナリオ 1で説明されているコマンドに、次のパラメーターを追加します。
--targetSize:マージされたファイルの最大サイズ(MB)--groupBy:マージルール。正規表現です。
例:
hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://yang-hhht/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --targetSize=10 --groupBy='.*/([a-z]+).*.txt' --parallelism 20シナリオ 12:コピー操作後に元のファイルを削除する場合、必要なパラメーターは何ですか?
シナリオ 1で説明されているコマンドに
--deleteOnSuccess を追加します。例:シナリオ 1hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://yang-hhht/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --deleteOnSuccess --parallelism 10シナリオ 13:CLIでOSSのAccessKeyペアとエンドポイント情報を指定したくない場合はどうすればよいですか?
Jindo DistCpでは、OSSのAccessKey ID、AccessKeyシークレット、およびエンドポイントを core-site.xml ファイルに保存できるため、情報を繰り返し指定する必要はありません。
- OSSのAccessKey ID、AccessKeyシークレット、およびエンドポイントを保存する場合は、次の情報を core-site.xml ファイルに保存します。
<configuration> <property> <name>fs.jfs.cache.oss-accessKeyId</name> <value>xxx</value> </property> <property> <name>fs.jfs.cache.oss-accessKeySecret</name> <value>xxx</value> </property> <property> <name>fs.jfs.cache.oss-endpoint</name> <value>oss-cn-xxx.aliyuncs.com</value> </property> </configuration> - Amazon S3のAccessKey ID、AccessKeyシークレット、およびエンドポイントを保存する場合は、次の情報を core-site.xml ファイルに保存します。
<configuration> <property> <name>fs.s3a.access.key</name> <value>xxx</value> </property> <property> <name>fs.s3a.secret.key</name> <value>xxx</value> </property> <property> <name>fs.s3.endpoint</name> <value>s3-us-west-1.amazonaws.com</value> </property> </configuration>